[toc]
廖雪峰
知识点
基础
在Python中,代码不是越多越好,而是越少越好。代码不是越复杂越好,而是越简单越好。
可变对象和不可变对象:可变指存在某项操作可以改变本身如list
set里都是key,set可以做&和|操作
tuple里的不变指“指向对象不变”,指向的对象自身可以变(如list)
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”
占位符pass什么都不做
函数可以同时返回多个值,但其实就是一个tuple,多个变量可以同时接收一个tuple,按位置赋给对应的值
定义默认参数要牢记一点:默认参数必须指向不变对象!如果指向可变对象如一个list,默认参数则指向这个list,且内容会被记住,每次调用都有继承,通过妙用不变对象来规避
def add_end(L=None): if L is None: L = [] L.append('END') return L 因为Python函数在定义的时候,默认参数
L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。参数前加*可以接受list和tuple并组装成tuple,加**则自动组装成dict,不过此时的key不用加引号
命名关键字参数需要一个特殊分隔符
*,*后面的参数被视为命名关键字参数。如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符
*了:def person(name, age, *args, city, job): print(name, age, args, city, job)
函数参数规则:
- 参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
- 所以,对于任意函数,都可以通过类似
func(*args, **kw)的形式调用它,无论它的参数是如何定义的。 - 虽然可以组合多达5种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
```python
a, b = b, a + b #这个挺诡异的,记录了初始值12. 切片可用于str,list,tuple 13. 判断一个对象是可迭代对象:通过collections模块的Iterable类型判断 ```python >>> from collections import Iterable >>> isinstance('abc', Iterable) # str是否可迭代列表解析:
- 可以使用两层循环,可以生成全排列:
>>> [m + n for m in 'ABC' for n in 'XYZ'] ['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']for后面的
if是一个筛选条件,不能带elsefor前面的部分是一个表达式,它必须根据
x计算出一个结果,必须加上else,如:[x if x % 2 == 0 else -x for x in range(1, 11)]
生成器generator:
第一种方法很简单,只要把一个列表生成式的
[]改成()二:如果一个函数定义中包含
yield关键字,那么这个函数就不再是一个普通函数,而是一个generator 变成generator的函数,在每次调用
next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。generator函数的“调用”实际返回一个generator对象:
但是用
for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:>>> g = fib(6) >>> while True: ... try: ... x = next(g) ... print('g:', x) ... except StopIteration as e: ... print('Generator return value:', e.value) ... break
凡是可作用于
for循环的对象都是Iterable类型;凡是可作用于
next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;集合数据类型如
list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。因为不同地方都指向同一个对象,多处修改
装饰器详解functools.wraps(func)
偏函数:
functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。其实也可以传入其他值,会自动加到左侧max2 = functools.partial(max, 10)max2(5, 6, 7) = max(10,5,6,7)
类
在Python中,实例的变量名如果以
__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,如:self.__name有些时候,你会看到以一个下划线开头的实例变量名,比如
_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。双下划线开头的实例变量是不是一定不能从外部访问呢?其实也不是。不能直接访问
__name是因为Python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量:在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类。但是,反过来就不行
对于一个变量,我们只需要知道它是
Animal类型,无需确切地知道它的子类型,就可以放心地调用run()方法,而具体调用的run()方法是作用在Animal、Dog、Cat还是Tortoise对象上,由运行时该对象的确切类型决定,这就是 多态真正的威力:调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:对扩展开放:允许新增
Animal子类;对修改封闭:不需要修改依赖
Animal类型的run_twice()等函数。动态语言的“鸭子类型”,它并不要求严格的继承体系,只要同样能进行操作,并不会检查它的类型,即使你要求的参数是animal类
千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
可以给实例动态绑定属性(直接)
A是类,a=A()
a.name=’darren’ del(a.name)可以直接操作
print(a.attribute)要是没有特殊的,就打印A的
还可以动态绑定方法:
>>> def set_age(self, age): #定义一个函数作为实例方法 ... self.age = age ... >>> from types import MethodType >>> s.set_age = MethodType(set_age, s) # 给实例绑定一个方法 >>> s.set_age(25) # 调用实例方法 >>> s.age # 测试结果 25可以直接给类动态绑定方法
A.set_age=set_age
函数对象有一个
__name__属性,可以拿到函数的名字为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的
__slots__变量,来限制该class实例能添加的属性:class Student(object): __slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称使用
__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的除非在子类中也定义
__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。(怪怪的)
@property @method_name.setter将方法变成类
定制类:
--len--:len函数自动调用的计算长度工具 --name--:获得当前函数的名族(functions.wraps(fun)) --str--:返回用户信息 --repr--:返回开发者信息 --iter--:返回迭代对象,使一个类可以被for in使用 --next--:迭代将调用--next--方法 --getitem--:实现下标访问[](切片要分类。。。不懂) --setitem--:把对象视作list/dict来赋值 --delitem--:删除某元素 --getattr--:在没有找到属性/方法时返回定义好的,可实现动态调用! --call--:直接对实例进行调用!可调用对象是Callable Python的官方文档: https://docs.python.org/3/reference/datamodel.html#special-method-names枚举:
from enum import Enum,unique Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))value默认从1开始!!!!
用@unique精确控制Enum衍生
@unique class Weekday(Enum): Sun = 0 # Sun的value被设定为0 Mon = 1 Tue = 2 Wed = 3 Thu = 4 Fri = 5 Sat = 6 day1=Weekday.Mon day1==Weekday(1) day1.value==1用.value获得对应的值
动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的,而创建class的方法就是使用
type()函数,所以类的类型是‘type’。object是python的默认类,有很多的方法,python种默认的list,str,dict等等都是继承了object类的方法,继承了object的类属于新式类 ,没有继承属于经典类,在python3种默认都是新式类,也即是所有的自定义类,基类都会继承object类!
type也可创建新类
- class的名称;
- 继承的父类集合
- class的方法名称与函数绑定,
先定义metaclass,就可以创建类,最后创建实例。
所以,metaclass允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”,它可以改变类创建时的行为。
metaclass是Python面向对象里最难理解,也是最难使用的魔术代码。。。
按照默认习惯,metaclass的类名总是以Metaclass结尾
(写法着实奇怪。。不放了。。希望这辈子碰不到!听说ORM要用。。)
错误&异常
错误衍生:
The class hierarchy for built-in exceptions is:
BaseException +-- SystemExit +-- KeyboardInterrupt +-- GeneratorExit +-- Exception +-- StopIteration +-- StopAsyncIteration +-- ArithmeticError | +-- FloatingPointError | +-- OverflowError | +-- ZeroDivisionError +-- AssertionError +-- AttributeError +-- BufferError +-- EOFError +-- ImportError | +-- ModuleNotFoundError +-- LookupError | +-- IndexError | +-- KeyError +-- MemoryError +-- NameError | +-- UnboundLocalError +-- OSError | +-- BlockingIOError | +-- ChildProcessError | +-- ConnectionError | | +-- BrokenPipeError | | +-- ConnectionAbortedError | | +-- ConnectionRefusedError | | +-- ConnectionResetError | +-- FileExistsError | +-- FileNotFoundError | +-- InterruptedError | +-- IsADirectoryError | +-- NotADirectoryError | +-- PermissionError | +-- ProcessLookupError | +-- TimeoutError +-- ReferenceError +-- RuntimeError | +-- NotImplementedError | +-- RecursionError +-- SyntaxError | +-- IndentationError | +-- TabError +-- SystemError +-- TypeError +-- ValueError | +-- UnicodeError | +-- UnicodeDecodeError | +-- UnicodeEncodeError | +-- UnicodeTranslateError +-- Warning +-- DeprecationWarning +-- PendingDeprecationWarning +-- RuntimeWarning +-- SyntaxWarning +-- UserWarning +-- FutureWarning +-- ImportWarning +-- UnicodeWarning +-- BytesWarning +-- ResourceWarningtry .. except.. excepy…else…finally
使用
try...except捕获错误还有一个巨大的好处,就是可以跨越多层调用,比如函数main()调用bar(),bar()调用foo(),结果foo()出错了,这时,只要main()捕获到了,就可以处理如果错误没有被捕获,它就会一直往上抛,最后被Python解释器捕获,打印一个错误信息,然后程序退出.
顺着错误信息一路向下就可以找到根源
logging可以记录错误信息,要配置。。。python logging模块使用教程 -
import logging try:// except: Excerption as e: logging.excerption(e)这样,在抛出错误信息后继续运行
当前函数不知道应该怎么处理该错误,所以,最恰当的方式是继续往上抛,让顶层调用者去处理,raise不带参数则原样抛出
assert … , ‘decleration’可以在解释时
python -O file.py来终止调用assert关闭后,你可以把所有的
assert语句当成pass来看logging.info()输出一段文本
在import logging后加
logging.basicConfig(level=logging.INFO)指定记录信息的级别error>warning>info>debug,上面规定INFO后,logging.debug就失效了
PDB我不想学。。不如IDE自带
测试unittest参见《入门》
$ python -m unittest mydict_test可以直接启用测试,常用的assetRaises,Equal,NotEqual,True,False,In,NotIn
在单元测试中编写两个特殊的
setUp()和tearDown()方法。这两个方法会分别在每调用一个测试方法的前后分别被执行Python内置的“文档测试”(doctest)模块可以直接提取注释中的代码并执行测试。
doctest严格按照Python交互式命令行的输入和输出来判断测试结果是否正确。只有测试异常的时候,可以用
...表示中间一大段烦人的输出。if __name__=='__main__': import doctest doctest.testmod()
IO
异步的理解
read(size)读取size
readline()读一行
readlines()一次读取并按行返回list
清理每行结尾自动加的\n
有个
read()方法的对象,在Python中统称为file-like Object。除了file外,还可以是内存的字节流,网络流,自定义流等等。file-like Object不要求从特定类继承,只要写个read()方法就行StringIO就是在内存中创建的file-like Object,常用作临时缓冲open(url,encoding=’gbk’,errors=’igone’)默认编码UTF-8,在出现非法字符时,由errors决定解决方式,直接‘igone’。。。
StringIO在内存中读写str
from io import StringIO f= StringIO('initial') >>> while True: ... s = f.readline() ... if s == '': ... break ... print(s.strip())getvalue()获得写入后的str
BytesIO操作的是二进制
>>> from io import BytesIO >>> f = BytesIO() >>> f.write('中文'.encode('utf-8')) 6 >>> print(f.getvalue()) b'\xe4\xb8\xad\xe6\x96\x87'写入的是utf-8编码的bytes,也可以初始化,其他读取方式和文件一样
操作文件和目录
import os os.name posix nt os.uname()不适用于windows os.environ os.environ.get('key') os.path.abspath('.')#查看绝对路径 '/Users/michael' #创建目录 >>> os.path.join('/Users/michael', 'testdir') '/Users/michael/testdir' # 然后创建一个目录: >>> os.mkdir('/Users/michael/testdir') # 删掉一个目录: >>> os.rmdir('/Users/michael/testdir') #合成路径不要拼接字符串,才能正确处理不同操作系统的路径分隔符 os.path.split()函数,这样可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名 os.path.splitext()可以直接让你得到文件扩展名 os.rename()重命名 os.remove()删除 shutil模块提供了copyfile()的函数,你还可以在shutil模块中找到很多实用函数,它们可以看做是os模块的补充 Python的os模块封装了操作系统的目录和文件操作,要注意这些函数有的在os模块中,有的在os.path模块中。 还有很多操作,需要用到时去找os库吧!
序列化
序列化指把变量从内存中变成可存储或传输的过程称之为序列化 pickling
比起pickle库,json库更好,更通用
| JSON类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| “string” | str |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
Python内置的json模块提
json.dump() json.dumps(d,f)
json.load() json.loads(f)
加了s是序列化和反序列化,没加则是操作文件同时序列化和反序列化。UTF-8
很多时候json不够智能,需要我们加上很多自定义参数来辅助,default是dumps用的,object_hook是loads用的,json好复杂啊
https://docs.python.org/3/library/json.html#json.dumps
https://www.json.org/json-en.html
正则表达式
强烈建议使用Python的
r前缀,就不用考虑转义的问题了```python
import re
test = ‘用户输入的字符串’
if re.match(r’正则表达式’, test):print('ok')else:
print('failed')3. 可用于切分字符串 ```python >>> re.split(r'\s+', 'a b c') ['a', 'b', 'c']提取字串!
m=re.match(r'正则表达式', string) m.group(0)=string m.group(n)是第n个如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
>>> import re # 编译: >>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$') # 使用: >>> re_telephone.match('010-12345').groups() ('010', '12345') >>> re_telephone.match('010-8086').groups() ('010', '8086')
功能函数
str.replace('a','A') 把字符串里的a替换成Aabs()绝对值,max()返回最大值
help(function_name)放到print里克查看帮助信息
int,float,str,bool 内置数据类型转换
hex()函数把一个整数转换成十六进制表示的字符串
内置函数
isinstance()用于数据类型检查,如:isinstance(x, (int, float)) >>> isinstance([1, 2, 3], (list, tuple)) True >>> isinstance((1, 2, 3), (list, tuple)) Truemap()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)filter()接收一个函数和一个序列,把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素,并返回的是一个Iteratorsorted(列表,映射函数,reverse=True)
比较对每一项使用映射函数后的新列表!
基本类型都可以用
type()判断,返回相应class可以使用
types模块中定义的常量:>>> import types >>> def fn(): ... pass ... >>> type(fn)==types.FunctionType True >>> type(abs)==types.BuiltinFunctionType True >>> type(lambda x: x)==types.LambdaType True >>> type((x for x in range(10)))==types.GeneratorType Truedir()函数,它返回一个包含字符串的list获得一个对象的所有属性和方法```python
getattr()、setattr()以及hasattr()可以分别验证,设置,得到某个instance的属性和方法 如果试图获取不存在的属性,会抛出AttributeError的错误: ```python >>> getattr(obj, 'z') # 获取属性'z' Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'MyObject' object has no attribute 'z'可以传入一个default参数,如果属性不存在,就返回默认值:
>>> getattr(obj, 'z', 404) # 获取属性'z',如果不存在,返回默认值404```python
raise ValueError(‘score must be an integer!’)15. eval()解析字符串为指令 ## 常用内建模块 还是看廖雪峰吧 1. datetime----datetime里有个datetime包! `datetime.now()`返回当前日期和时间,其类型是`datetime`。 ```python from datetime import datetime >>> dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime >>> print(dt) 2015-04-19 12:20:00 dt.timestamp() # 把datetime转换为timestamp 1429417200.0 datetime.(时区如utc)fromtimestamp(dt) >>>2015-04-19 12:20:00
我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。对应的北京时间是:
timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00str转换为datetime用datetime.strptime(‘time’,’格式参数’)具体参考Python文档此处得到的datetime无时区信息
datetime转str用strftime
datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
>>> from datetime import datetime, timedelta
>>> now = datetime.now()
>>> now
datetime.datetime(2015, 5, 18, 16, 57, 3, 540997)
>>> now + timedelta(hours=10)
datetime.datetime(2015, 5, 19, 2, 57, 3, 540997)
>>> now - timedelta(days=1)
datetime.datetime(2015, 5, 17, 16, 57, 3, 540997)
>>> now + timedelta(days=2, hours=12)
datetime.datetime(2015, 5, 21, 4, 57, 3, 540997)规范
参考PEP8
正常的函数和变量名是公开的(public),可以被直接引用,比如:
abc,x123,PI等;类似
__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的__author__,__name__就是特殊变量,hello模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名;类似
_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;运算符的空格要看出运算顺序,
x = 3*4 + 5y = 3 + 5每行代码应该不超过 80 个字符,虽然在某些使用情况下,99 个字符也可以
以后再学
思科补充
print(“..”,end=”分隔符”)分隔符用于指示结尾,默认为换行、
print(“a”,”b”,sep=”在句号间的分割标志”)
None可以安全使用的情况只有两种:
- 当您将其分配给变量(或将其作为函数的结果返回)时
- 当您将其与变量进行比较以诊断其内部状态时。
它不能参与任何表达式。
列表和元组可以用*操作符“繁殖”
python3函数先定义再调用
Udacity
任何专业人士都无法记住所有方法,因此知道如何通过文档查询答案非常重要。掌握扎实的编程基础使你能够利用这些基础知识查询文档,并且构建的程序比死记硬背所有 python 可用函数的人士构建的程序强大得多。
区分函数和方法的概念
下图显示了任何字符串都可以使用的方法。
https://www.w3school.com.cn/python/python_ref_string.asp
还有Udacity的文档教材
基本
mutability 可变性

包含可变对象和不可变对象的变量行为不同
把字符串赋给另一个变量就是复制一份,但如果是列表就类似引用
orderd 有序性

有序性的容器可以使用索引,在 python 中,所有有序容器(例如列表,字符串)的起始索引都是 0。
还可以使用切片
列表函数
max等函数在比较不能比的类型时,并不会自动转换!直接出错
支持 in
min len sorted(小心字符串没有列表的len方法,要用len(string))
join字符串函数,注意python的字符串字面量间如果不加分隔符,会被视为连在一起
new_str = "\n".join(["fore", "aft", "starboard", "port"])
print(new_str)输出:
fore
aft
starboard
port该函数同样在遇到非字符串类型时直接出错
小心一些方法或者函数没有返回值,比如append,这时默认返回None
tuple
这下有定义了,元组是 不可变 的 有序 数据结构
所以不能更改,但可以使用索引和切片,元组适合确定后不变的数据们,可以用来表示始终不变的对应数据
元组还可以用来以紧凑的方式为多个变量赋值。
dimensions = 52, 40, 100
length, width, height = dimensions
print("The dimensions are {} x {} x {}".format(length, width, height))在定义元组时,小括号是可选的,如果小括号并没有对解释代码有影响,程序员经常会忽略小括号。
在第二行,我们根据元组 dimensions 的内容为三个变量赋了值。这叫做元组解包。你可以通过元组解包将元组中的信息赋值给多个变量,而不用逐个访问这些信息,并创建多个赋值语句。
如果我们不需要直接使用 dimensions,可以将这两行代码简写为一行,一次性为三个变量赋值!
length, width, height = 52, 40, 100
print("The dimensions are {} x {} x {}".format(length, width, height))集合
{1,2,3}
无序,所以不存在最后一个元素这一说,pop方法如果无参数则会随机弹出
可变,支持in
但是不能使用append,要使用add方法
不能往无序的里面使用某些带有有序意义的方法如append,
对set可以进行数学上集合的操作,union() intersection() difference(),并且与其他容器相比,速度快了很多。
字典
字典是无序的!
字典的键可以是任何不可变类型!一个字典的每个键也并非必须具有相同的类型
get()用来查找值!默认返回None,也可以自定义,如果可能出错,就使用get方法而不是方括号,免得崩溃
>>> elements.get('kryptonite', 'There\'s no such element!')
"There's no such element!"恒等运算符is 和 is not 与 == 和 != 是有区别的
首先要知道Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
== 比较的是值 is比较的是id 可以用id()查看id
只有数值型和字符串型的情况下,a is b才为True,当a和b是tuple,list,dict或set型时,a is b为False。
小整数导致的bug
**大家自己试试看a=257,b=257时它们的id还是否会相等。事实上Python 为了优化速度,使用了小整数对象池,避免为整数频繁申请和销毁内存空间。而Python 对小整数的定义是 [-5, 257),只有数字在-5到256之间它们的id才会相等,超过了这个范围就不行了,同样的道理,字符串对象也有一个类似的缓冲池,超过区间范围内自然不会相等了。**
**总的来说,只有数值型和字符串型,并且在通用对象池中的情况下,a is b才为True,否则当a和b是int,str,tuple,list,dict或set型时,a is b均为False。**推荐样式
>>> population = {'Shanghai': 17.8,
'Istanbul': 13.3,
'Karachi': 13.0,
'Mumbai': 12.5}复合结构
我们可以在其他容器中包含容器,以创建复合数据结构。例如,下面的字典将键映射到也是字典的值!
elements = {"hydrogen": {"number": 1,
"weight": 1.00794,
"symbol": "H"},
"helium": {"number": 2,
"weight": 4.002602,
"symbol": "He"}}我们可以如下所示地访问这个嵌套字典中的元素。
helium = elements["helium"] # get the helium dictionary
hydrogen_weight = elements["hydrogen"]["weight"] # get hydrogen's weight*逻辑
基本
- 逻辑运算符
and、or和not具有特定的含义,与字面英文意思不太一样。确保布尔表达式的结果和你预期的一样。
# Bad example
if weather == "snow" or "rain":
print("Wear boots!")这段代码在 Python 中是有效的,但不是布尔表达式,虽然读起来像。原因是 or 运算符右侧的表达式 "rain" 不是布尔表达式,它是一个字符串。稍后我们将讨论当你使用非布尔型对象替换布尔表达式时,会发生什么。
- 请勿使用
== True或== False比较布尔变量
以下是在 Python 中被视为 False 的大多数内置对象:
- 定义为 false 的常量:
None和False - 任何数字类型的零:
0、0.0、0j、Decimal(0)、Fraction(0, 1) - 空序列和空集合:
””、()、[]、{}、set()、range(0)
在Python中and的优先级是大于or的,而且and和or都是会返回值的并且不转换为True和False。当not和and及or在一起运算时,优先级为是not>and>or
短路
短路求值
如果a = False,对于a and b求值时,将直接得到结果为False,不会再对b的值做考核,不论它是True或False。
如果a = True,对于a or b求值时,将直接得到结果为True,不会再对b的值做考核,不论它是True或False。
python的if这些语句会提取表达式的真假,但并不是把表达式改了值!
短路输出
记住,所有被短路的表达式均不会被输出
短路规则如下
表达式从左至右运算,若 or 的左侧逻辑值为 True ,则短路 or 后所有的表达式(不管是 and 还是 or),直接输出 or 左侧表达式 。 // 若 or 的左侧逻辑值为 False ,则输出or右侧的表达式,不论其后表达式是真是假,整个表达式结果即为其后表达式的结果
表达式从左至右运算,若 and 的左侧逻辑值为 False ,则短路其后所有 and 表达式,直到有 or 出现,输出 and 左侧表达式到 or 的左侧,参与接下来的逻辑运算。 // 若 and 的左侧逻辑值为 True,则输出其后的表达式,不论其后表达式是真是假,整个表达式结果即为其后表达式的结果
若 or 的左侧为 False ,或者 and 的左侧为 True 则不能使用短路逻辑。
三元运算操作符
在python2.5 之前,python 是没有三元操作符的,Guido Van Rossum 认为它并不能帮助 python 更加简洁,但是那些习惯了 c 、 c++ 和 java 编程的程序员却尝试着用 and 或者 or 来模拟出三元操作符,而这利用的就是python的短路逻辑。
三元运算操作符 bool ? a : b ,若 bool 为真则 a ,否则为 b 。
转化为 python 语言为:
**bool and a or b **
如何理解呢? 首先 a , b 都为真,这是默认的。如果 bool 为真, 则 bool and a 为真,输出 a ,短路 b 。如果 bool 为假,短路 a,直接 bool or b ,输出 b 。
换一种更简单的写法:
return a if bool else b
for和迭代
iterable 也是一个很重要的属性!

字符串,列表,元组等序列结构,
字典,文件等非序列类型
iter()方法定义对象,使其为可迭代
for用于可迭代对象!!!!!习惯用单复数分别作为迭代变量名,和迭代对象名
range(star,stop,step) 默认start -0 step-1 只能是整数,小心stop表示到xx停止,所以不会包含
漂亮用法👇

只会返回一个可迭代的range对象。。得用list转化或for遍历
while
For 循环是一种“有限迭代”,意味着循环主体将运行预定义的次数。这与“无限迭代”循环不同,无限迭代循环是指循环重复未知次数,并在满足某个条件时结束,while 循环正是这种情况
break和continue
format
ps: 格式化字符串函数.format
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
也可以设置参数:
# 关键字参数
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
# 仅列表
for point in zip(labels, x_coord, y_coord, z_coord):
points.append("{}: {}, {}, {}".format(*point))
此外我们可以使用大括号 {} 来转义大括号
print ("{} 对应的位置是 {{0}}".format("runoob"))
runoob 对应的位置是 {0}
数字则在前面加上:
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d}(顺着读:在x左边) | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d}(没写用啥补,就是空的) | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | '{:b}'.format(11) '{:d}'.format(11) '{:o}'.format(11) '{:x}'.format(11) '{:#x}'.format(11) '{:#X}'.format(11) |
1011 11 13 b 0xb 0XB |
进制 |
Zip &Enumerate
zip 返回一个将多个可迭代对象组合成一个元组序列的迭代器。每个元组都包含所有可迭代对象中该位置的元素。例如,
list(zip(['a', 'b', 'c'], [1, 2, 3])) 将输出 [('a', 1), ('b', 2), ('c', 3)].
正如 range() 一样,我们需要将其转换为列表或使用循环进行遍历以查看其中的元素。
你可以如下所示地用 for 循环拆分每个元组。
letters = ['a', 'b', 'c']
nums = [1, 2, 3]
for letter, num in zip(letters, nums):
print("{}: {}".format(letter, num))
这个是两个参数依次匹配,字典的items是用了这个原理()items原理(转化为一个元组列表):

除了可以将两个列表组合到一起之外,还可以使用星号拆分列表。
some_list = [('a', 1), ('b', 2), ('c', 3)]
letters, nums = zip(*some_list)这样可以创建正如之前看到的相同 letters 和 nums 列表,巧妙👇

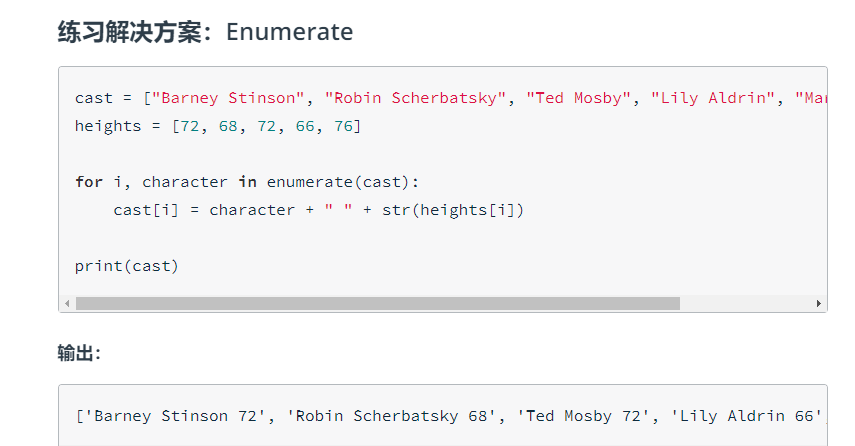
enumerate 是一个会返回元组迭代器的内置函数,这些元组包含列表的索引和值。当你需要在循环中获取可迭代对象的每个元素及其索引时,将经常用到该函数。
letters = ['a', 'b', 'c', 'd', 'e']
for i, letter in enumerate(letters):
print(i, letter)这段代码将输出:
0 a
1 b
2 c
3 d
4 e例子



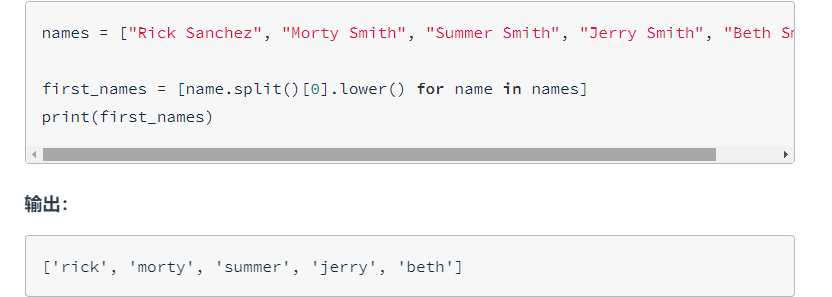
这个技巧很诡异,tuple可以将列表,区间,字符串,zip等(可迭代对象?)等转换为元组
但在转化字典时,只会保留键。这边就是把zip迭代对象转化为元组,
这样就直接可以使用索引了!
列表解析
终于知道SyntaxError原来是语法错误
你还可以向列表推导式添加条件语句。在可迭代对象之后,你可以使用关键字 if 检查每次迭代中的条件。
squares = [x**2 for x in range(9) if x % 2 == 0]上述代码将 squares 设为等于列表 [0, 4, 16, 36, 64],因为仅在 x 为偶数时才评估 x 的 2 次幂。如果你想添加 else,将遇到语法错误。
squares = [x**2 for x in range(9) if x % 2 == 0 else x + 3]如果你要添加 else,则需要将条件语句移到列表推导式的开头,直接放在表达式后面,如下所示。
squares = [x**2 if x % 2 == 0 else x + 3 for x in range(9)]列表推导式并没有在其他语言中出现,但是在 python 中很常见。
例子
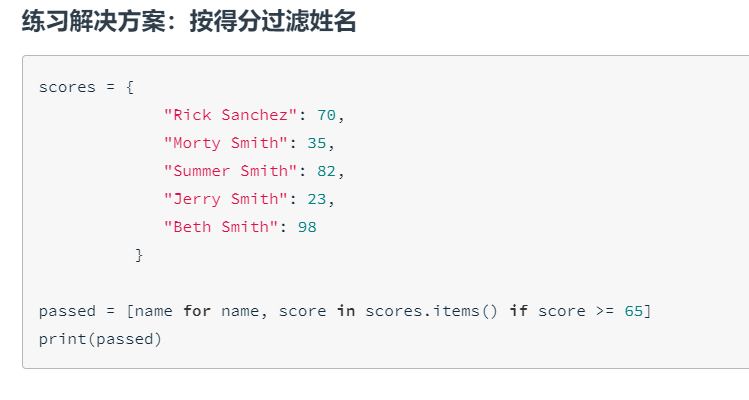
这个课程总有一些奇怪的知识藏在题解里面卧槽,split是个很重要的工具
函数
- 仅在函数名称中使用普通字母、数字和下划线。不能有空格,需要以字母或下划线开头。
- 不能使用在 Python 中具有重要作用的保留字或内置标识符,我们将在这门课程中学习这方面的知识。要了解 python 保留字列表,请参阅此处。
- 尝试使用可以帮助读者了解函数作用的描述性名称
python变量
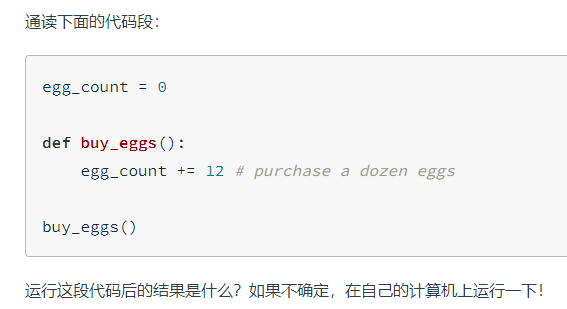

你发现在函数内,我们可以成功地输出外部变量的值。因为我们只是访问该变量的值。当我们尝试将此变量的值更改或重新赋值为另一个值时,我们将遇到错误。Python 不允许函数修改不在函数作用域内的变量。
但是上面的原则仅适用于整数和字符串,列表、字典、集合、类中可以在子程序(子函数)中通过修改局部变量达到修改全局变量的目的。
打包和解包
通用写法是*arg **kwargs
*args就是就是传递一个可变参数列表给函数实参,这个参数列表的数目未知,甚至长度可以为0。
打包后成为元组tuple
**kwargs则是将一个可变的关键字参数的字典传给函数实参,同样参数列表长度可以为0或为其他值
打包后是一个字典
args 必须放在 kwargs 前面
打包就是zip
解包可以是之前介绍的写法,一个变量对应一项,对应不上就报错
可以用*var 代替任意项
函数定义时,我们用的*和**其实也是压包解包过程
>>> def myfun(*num):
... print(num)
...
>>> myfun(1,2,5,6)
(1, 2, 5, 6)参数用*num表示,num变量就可以当成元组调用了。
其实这个过程相当于*num, = 1,2,5,6
但是在传递参数时,是解包过程
这个应用牛啊
可以看看原文
文档字符串
docstrings,文档字符串是一种注释,用于解释函数的作用以及使用方式。
文档字符串用三个引号引起来,第一行简要解释了函数的作用。如果你觉得信息已经足够了,可以在文档字符串中只提供这么多的信息;
如果你觉得需要更长的句子来解释函数,可以在一行摘要后面添加更多信息
对函数的参数进行了解释,描述了每个参数的作用和类型。我们经常还会对函数输出进行说明
Lambda
你可以使用 Lambda 表达式创建匿名函数,即没有名称的函数。lambda 表达式非常适合快速创建在代码中以后不会用到的函数。尤其对高阶函数或将其他函数作为参数的函数来说,非常实用。
Lambda 函数的组成部分
- 关键字
lambda表示这是一个 lambda 表达式。 lambda之后是该匿名函数的一个或多个参数(用英文逗号分隔),然后是一个英文冒号:。和函数相似,lambda 表达式中的参数名称是随意的。- 最后一部分是被评估并在该函数中返回的表达式,和你可能会在函数中看到的 return 语句很像。
鉴于这种结构,lambda 表达式不太适合复杂的函数,但是非常适合简短的函数。
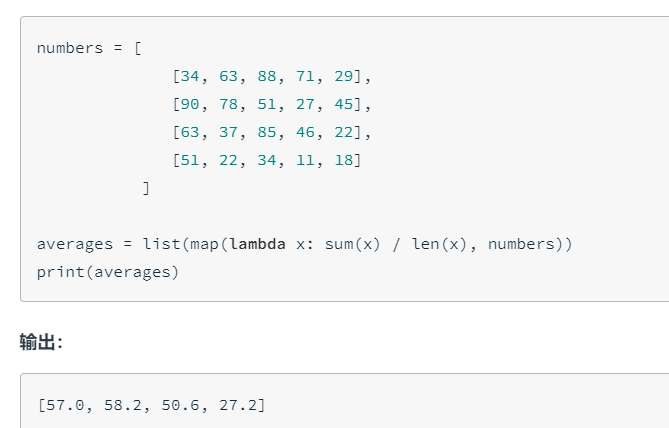
迭代器和生成器
Iterator and generator
迭代器是每次可以返回一个对象元素的对象,例如返回一个列表。我们到目前为止使用的很多内置函数(例如 enumerate)都会返回一个迭代器。
迭代器是一种表示数据流的对象。这与列表不同,列表是可迭代对象,但不是迭代器,因为它不是数据流。
第一种方法很简单,只要把一个列表解析式的[]改成()
生成器是使用函数创建迭代器的简单方式。也可以使用类定义迭代器,更多详情请参阅此处
def my_range(x):
i = 0
while i < x:
yield i
i += 1注意,该函数使用了 yield 而不是关键字 return。这样使函数能够一次返回一个值,并且每次被调用时都从停下的位置继续。关键字 yield 是将生成器与普通函数区分开来的依据。调用该函数返回一个迭代器


妙啊!用size指定间距,用切片进行范围切取
python和c的思维方式是不一样的!
C要利用有限的工具进行微操,而python要巧妙利用已有的强大工具进行组合!
这些工具组合起来太巧妙了
tuple,list,dict,zip,enumerate,压包解包,列表解析,lambda,range,iterator还有封装好的函数
脚本
Python 是一种“脚本语言”。脚本,对应的英文是:script。一般人看到script这个英文单词,或许想到的更多的是:电影的剧本,就是一段段的脚本,所组成的。电影剧本的脚本,决定了电影中的人和物,都做哪些事情,怎么做。而计算机中的脚本,决定了:计算机中的操作系统和各种软件工具,要做哪些事情,以及具体怎么做。
学完更全面的Anaconda和Jupyter Notebook 我们继续脚本
运行python文件得先输入python(理解为执行python命令,毕竟python没有c那么底层)
输入python进入环境,C + Z退出,或者exit()
input(‘xx’) 注意返回的是字符串
内置函数 eval 将用户输入解析为 Python 表达式,感觉非常危险!
result = eval(input("Enter an expression: "))
print(result)如果用户输入 2 * 3,输出为 6。
ps:
split
str = "Line1-abcdef \nLine2-abc \nLine4-abcd";
print str.split( ); # 以空格为分隔符,包含 \n
print str.split(' ', 1 ); # 以空格为分隔符,分隔成两个以上实例输出结果如下:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']下面看一个神奇的例子
names = input("Enter names separated by commas: ").title().split(",")
assignments = input("Enter assignment counts separated by commas: ").split(",")
grades = input("Enter grades separated by commas: ").split(",")
message = "Hi {},\n\nThis is a reminder that you have {} assignments left to \
submit before you can graduate. You're current grade is {} and can increase \
to {} if you submit all assignments before the due date.\n\n"
for name, assignment, grade in zip(names, assignments, grades):
print(message.format(name, assignment, grade, int(grade) + int(assignment)*2))错误和异常
SyntaxError 语法异常
Exception就是语法正常但是出错

Try 语句
我们可以使用 try 语句处理异常。你可以使用 4 个子句(除了视频中显示的子句之外还有一个子句)。
try:这是try语句中的唯一必需子句。该块中的代码是 Python 在try语句中首先运行的代码。except:如果 Python 在运行try块时遇到异常,它将跳到处理该异常的except块。可以明确指明异常种类 except ValueError: 话说竟然C+C是KeyboardInterrupt异常
也可以用逗号分割来指定多种(实质是转化成一个元组,也可以直接写一个元组上去)
或者写多条except语句来分别不同情况
else:如果 Python 在运行try块时没有遇到异常,它将在运行try块后运行该块中的代码。finally:在 Python 离开此try语句之前,在任何情形下它都将运行此finally块中的代码,即使要结束程序,例如:如果 Python 在运行except或else块中的代码时遇到错误,在停止程序之前,依然会执行此finally块。
可用于清理代码比如关闭文件之类的👆
注意一下顺序
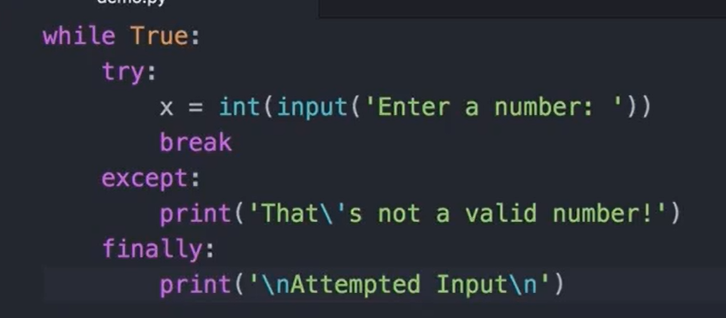
在这里,当执行了x = xx 时,抛出异常,直接到except里面,而不是执行break!
访问错误信息
在处理异常时,依然可以如下所示地访问其错误消息:
try:
# some code
except ZeroDivisionError as e:
# some code
print("ZeroDivisionError occurred: {}".format(e))应该会输出如下所示的结果:
ZeroDivisionError occurred: division by zero因此依然可以访问错误消息,即使已经处理异常以防止程序崩溃!
如果没有要处理的具体错误,依然可以如下所示地访问消息:
try:
# some code
except Exception as e:
# some code
print("Exception occurred: {}".format(e))Exception 是所有内置异常的基础类。你可以在此处详细了解 Python 的异常。
文件
文件其实是一堆数字符号编码
其他的文件打开应用其实就是解读特定的编码并显示出来的GUI
在python中打开文件会出现一个公用程序接口
文件对象时python与文件交互的接口,智能按顺序一次查看一个字符
open打开,参数w,a,r之类的,write(返回输入的字符数)
read会从当前位置读取所有字符放进一个字符串,一定要close噢!小心耗尽文件句柄
如果向 .read() 传入整型参数,它将读取长度是这么多字符的内容,输出所有内容,并使 ‘window’ 保持在该位置以准备继续读取。
Python 提供了一个特殊的语法with,该语法会在你使用完文件后自动关闭该文件。
with open('my_path/my_file.txt', 'r') as f:
file_data = f.read()该 with 关键字使你能够打开文件,对文件执行操作,并在缩进代码(在此示例中是读取文件)执行之后自动关闭文件。现在,我们不需要调用 f.close() 了!你只能在此缩进块中访问文件对象 f。
实质是利用作用域
请参阅 Python 文档的相关部分
readline() 会读取一行
f.tell() returns an integer giving the file object’s current position in the file represented as number of bytes from the beginning of the file when in binary mode and an opaque number when in text mode.
鬼知道这个不透明数字是个啥玩意
To change the file object’s position, use f.seek(offset, whence). The position is computed from adding offset to a reference point; the reference point is selected by the whence argument. A whence value of 0 measures from the beginning of the file, 1 uses the current file position, and 2 uses the end of the file as the reference point. whence can be omitted and defaults to 0, using the beginning of the file as the reference point.
在文本文件中(那些b在模式字符串中不带a开头的文件),仅允许相对于文件开头的查找(查找到以结尾的文件末尾为例外),并且唯一有效的偏移值是从零返回的偏移量值。。任何其他偏移值都会产生不确定的行为。seek(0, 2)``f.tell() 这个和c语言一样
很方便的是,Python 将使用语法 for line in file 循环访问文件中的各行内容。 我可以使用该语法创建列表中的行列表。因为每行依然包含换行符,因此我使用 .strip() 删掉换行符。也可以rstrip()
camelot_lines = []
with open("camelot.txt") as f:
for line in f:
camelot_lines.append(line.strip())
print(camelot_lines)输出:
["We're the knights of the round table", "We dance whenever we're able"]比如提取每行的信息,前提是你知道怎么分离的
def create_cast_list(filename):
cast_list = []
# use with to open the file filename
with open(filename) as f:
# use the for loop syntax to process each line
# and add the actor name to cast_list
for line in f:
line_data = line.split(',')
cast_list.append(line_data[0])
return cast_list库
只能在导入语句之后使用相应python代码,所以习惯放在顶部
模块是具有python定义和语句的文件
import xxx as xx
还有python里面的main函数 if __name__ == “__main__“
这样的结构不错:
# useful_functions.py
def mean(num_list):
return sum(num_list) / len(num_list)
def add_five(num_list):
return [n + 5 for n in num_list]
def main():
print("Testing mean function")
n_list = [34, 44, 23, 46, 12, 24]
correct_mean = 30.5
assert(mean(n_list) == correct_mean)
print("Testing add_five function")
correct_list = [39, 49, 28, 51, 17, 29]
assert(add_five(n_list) == correct_list)
print("All tests passed!")
if __name__ == '__main__':
main()datetime 用来处理日期和时间
os可以用来处理操作系统相关的,还有当前目录
直接导入
from module_name import object_name
from module_name import object_name,object_name2
只获取所需要的对象,所以说函数其实也是一个对象
廖雪峰教材里确实有提到:函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”
总结:
要从模块中导入单个函数或类:
from module_name import object_name要从模块中导入多个单个对象:
from module_name import first_object, second_object要重命名模块:
import module_name as new_name要从模块中导入对象并重命名:
from module_name import object_name as new_name要从模块中单个地导入所有对象(请勿这么做):
from module_name import *如果你真的想使用模块中的所有对象,请使用标准导入 module_name 语句并使用点记法访问每个对象。
import module_name
为了更好地管理代码,Standard 标准库中的模块被拆分成了子模块并包含在软件包中。软件包是一个包含子模块的模块。子模块使用普通的点记法指定。
子模块的指定方式是软件包名称、点,然后是子模块名称。你可以如下所示地导入子模块。
import package_name.submodule_namepython的标准库非常庞大,但即使这样,仍有成千上万的第三方库
pip和conda下载这些库的的软件包,这样你可以使用与导入标准库相同的语法来导入第三方软件包
conda据说专门针对数据科学!pip是内置,也是一般情况
按照规范,最好把第三方库放在导入标准库的语句后面
使用 requirements.txt 文件
大型 Python 程序可能依赖于十几个第三方软件包。为了更轻松地分享这些程序,程序员经常会在叫做 requirements.txt 的文件中列出项目的依赖项。下面是一个 requirements.txt 文件示例。
beautifulsoup4==4.5.1
bs4==0.0.1
pytz==2016.7
requests==2.11.1该文件的每行包含软件包名称和版本号。版本号是可选项,但是通常都会包含。不同版本的库之间可能变化不大,可能截然不同,因此有必要使用程序作者在写程序时用到的库版本。
你可以使用 pip 一次性安装项目的所有依赖项,方法是在命令行中输入 pip install -r requirements.txt。
实用的第三方软件包
能够安装并导入第三方库很有用,但是要成为优秀的程序员,还需要知道有哪些库可以使用。大家通常通过在线推荐或同事介绍了解实用的新库。如果你是一名 Python 编程新手,可能没有很多同事,因此为了帮助你了解入门信息,下面是优达学城工程师很喜欢使用的软件包列表。(可能部分网站在国内网络中无法打开)
- IPython - 更好的交互式 Python 解释器
- requests - 提供易于使用的方法来发出网络请求。适用于访问网络 API。
- Flask - 一个小型框架,用于构建网络应用和 API。
- Django - 一个功能更丰富的网络应用构建框架。Django 尤其适合设计复杂、内容丰富的网络应用。
- Beautiful Soup - 用于解析 HTML 并从中提取信息。适合网页数据抽取。
- pytest - 扩展了 Python 的内置断言,并且是最具单元性的模块。
- PyYAML - 用于读写 YAML 文件。
- NumPy - 用于使用 Python 进行科学计算的最基本软件包。它包含一个强大的 N 维数组对象和实用的线性代数功能等。
- pandas - 包含高性能、数据结构和数据分析工具的库。尤其是,pandas 提供 dataframe!
- matplotlib - 二维绘制库,会生成达到发布标准的高品质图片,并且采用各种硬拷贝格式和交互式环境。
- ggplot - 另一种二维绘制库,基于 R’s ggplot2 库。
- Pillow - Python 图片库可以向你的 Python 解释器添加图片处理功能。
- pyglet - 专门面向游戏开发的跨平台应用框架。
- Pygame - 用于编写游戏的一系列 Python 模块。
- pytz - Python 的世界时区定义。
IPython
通过在终端里输入 python 启动 python 交互式解释器。你可以接着输入内容,直接与 Python 交互。这是每次实验和尝试一段 Python 代码的很棒工具。只需输入 Python 代码,输出将出现在下一行。
>>> type(5.23)
<class 'float'>在解释器中,提示符窗口中最后一行的值将自动输出。如果有多行代码需要输出值,依然需要使用 print。
如果你开始定义函数,你将在提示符窗口中看到变化,表示这是可以继续的行。在定义函数时,你需要自己添加缩进。
>>> def cylinder_volume(height, radius):
... pi = 3.14159
... return height * pi * radius ** 2解释器的不足之处是修改代码比较麻烦。如果你在输入该函数时出现了拼写错误,或者忘记缩进函数的主体部分,无法使用鼠标将光标点到要点击的位置。需要使用箭头键在代码行中来回移动。有必要了解一些实用的快捷方式,例如移到一行的开头或结尾。
注意,我可以引用我在解释器中之前定义的任何对象!
实际上有一个代替默认 python 交互式解释器的强大解释器 IPython,它具有很多其他功能。
在命令行输入ipython就可以打开
- Tab 键补充完整
?:关于对象的详细信息!:执行系统 shell 命令- 语法突出显示
你可以在此处查看更多其他功能!
快速查询
要想成为熟练的程序员,需要掌握大量知识。需要了解库、记住语法以及其他细节。此外,让这一切更具挑战的是,技术在不断革新,因为新的技巧和工具会不断出现。
对于编程新手来说,学习所有这些细节并及时获悉新的发展动态似乎是一项不可能完成的任务。的确是这样!具有多年经验的编程专业人士实际上并不是在脑中记下百科全书一样的知识,而是掌握了快速查找信息的技巧。
下面是高效网络搜索的一些技巧:
- 在查询时,尝试使用 Python 或要使用的库的名称作为第一个字词。这样会告诉搜索引擎优先显示与你要使用的工具明确相关的结果。
- 创建良好的搜索查询需要多次尝试。如果第一次尝试时没有找到有用的结果,再试一遍。
- 尝试使用在一开始搜索时发现的网页上发现的关键字,使搜索引擎在后续搜索中转到更好的资源。
- 复制粘贴错误消息作为搜索字词。这样会出现错误解释性信息和潜在原因。错误消息可能包括你所写的特定行号引用。只在搜索中包含这些信息之前的错误消息部分。
- 如果找不到问题答案,自己提出问题!StackOverflow 等社区有一些行为规则,如果你要加入该社区,必须了解这些规则,但是别因为这些规则而不愿意使用这些资源。
虽然有很多关于编程的在线资源,但是并非所有资源都是同等水平的。下面的资源列表按照大致的可靠性顺序排序。
- Python 教程 - 这部分官方文档给出了 Python 的语法和标准库。它会举例讲解,并且采用的语言比主要文档的要浅显易懂。确保阅读该文档的 Python 3 版本!
- Python 语言和库参考资料 - 语言参考资料和库参考资料比教程更具技术性,但肯定是可靠的信息来源。当你越来越熟悉 Python 时,应该更频繁地使用这些资源。
- 第三方库文档 - 第三方库会在自己的网站上发布文档,通常发布于 https://readthedocs.org/ 。你可以根据文档质量判断第三方库的质量。如果开发者没有时间编写好的文档,很可能也没时间完善库。
- 非常专业的网站和博客 - 前面的资源都是主要资源,他们是编写相应代码的同一作者编写的文档。主要资源是最可靠的资源。次要资源也是非常宝贵的资源。次要资源比较麻烦的是需要判断资源的可信度。Doug Hellmann 等作者和 Eli Bendersky 等开发者的网站很棒。不出名作者的博客可能很棒,也可能很糟糕。
- StackOverflow - 这个问答网站有很多用户访问,因此很有可能有人之前提过相关的问题,并且有人回答了!但是,答案是大家自愿提供的,质量参差不齐。在将解决方案应用到你的程序中之前,始终先理解解决方案。如果答案只有一行,没有解释,则值得怀疑。你可以在此网站上查找关于你的问题的更多信息,或发现替代性搜索字词。
- Bug 跟踪器 - 有时候,你可能会遇到非常罕见的问题或者非常新的问题,没有人在 StackOverflow 上提过。例如,你可能会在 GitHub 上的 bug 报告中找到关于你的错误的信息。这些 bug 报告很有用,但是你可能需要自己开展一些工程方面的研究,才能解决问题。
- 随机网络论坛 - 有时候,搜索结果可能会生成一些自 2004 年左右就不再活跃的论坛。如果这些资源是唯一解决你的问题的资源,那么你应该重新思考下寻找解决方案的方式。
Anaconda
再看看这里的Anaconda和Jupyterbook
- Anaconda发行版中的可用软件包
conda专注于数据科学,而这些软件包pip通常用于一般用途。Conda安装预编译的软件包。例如,Anaconda发行版随附使用MKL库编译的Numpy,Scipy和Scikit-learn ,从而加快了各种数学运算的速度。但是,有时候,您可能需要除Anaconda发行版中列出的软件包以外的软件包。 - Pip可以安装Python软件包和非Python软件包。Pip可以安装Python软件包索引(PyPI)上列出的任何软件包。
conda list 列出安装的所有包
conda env list 检查环境列表
为了避免以后出现错误,最好在默认环境中更新所有软件包。打开终端/ Anaconda Prompt应用程序。在提示符下,运行以下命令:
conda upgrade conda
conda upgrade --all #千万不要!!!!!!!不然会带来一堆兼容性错误并在询问是否要安装软件包时回答是。最初安装时附带的软件包往往已过时,因此立即更新它们可以防止将来的软件过时错误。
新环境里最好安装个pip
# Check if pip is already installed, by running this command on Terminal/Anaconda Prompt
pip --version
# Once you have conda installed, run the command below on Terminal/Anaconda Prompt
conda install pip装包
您可以同时安装多个软件包。例如,下面的命令将同时安装所有三个软件包。
conda install numpy scipy pandas也可以通过添加版本号(例如)来指定所需的软件包版本conda install numpy=1.10。
Conda还会自动为您安装依赖项。例如scipy使用和要求numpy。如果仅安装scipy(conda install scipy),numpy则尚未安装的Conda也将安装。
conda remove PACKAGE_NAMEconda update package_name
conda update --all如果您不知道要查找的软件包的确切名称,可以尝试使用进行搜索conda search *SEARCH_TERM*。例如,我知道我想安装Beautiful Soup,但是我不确定确切的软件包名称。因此,我尝试conda search *beautifulsoup*。请注意,*在运行conda命令之前,您的shell可能会扩展通配符。要解决此问题,请将搜索字符串用单引号或双引号引起来,例如conda search '*beautifulsoup*'。
请参阅《Conda命令参考指南》以了解有关conda命令的更多信息
管理环境
conda create -n env_name [python=X.X] [LIST_OF_PACKAGES]此处-n env_name设置环境-n名称(用于名称),并且LIST_OF_PACKAGES是要在环境中安装的软件包的列表。如果要安装要安装的特定版本的Python,例如3.7,请使用python=3.7。例如,要创建一个以my_envPython 3.7命名的环境,并在其中安装NumPy和Keras,请使用以下命令。
conda create -n my_env python=3.7 numpy Keras激活
activate my_env
deactivate保存和加载环境
一个真正有用的功能是共享环境,以便其他人可以使用正确的版本安装代码中使用的所有软件包。让我们使用以下命令查看所有软件包名称,包括当前环境中存在的Python版本:
conda env export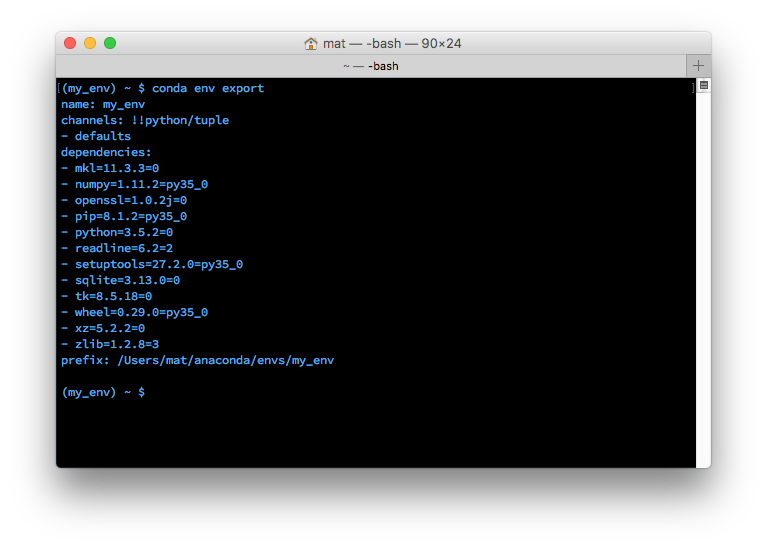
导出环境打印到终端
在上图中,您可以看到环境的名称,并且列出了所有依赖项(以及版本)。您可以将上述所有信息保存到YAML文件中environment.yaml,然后再通过GitHub或其他方式与其他用户共享此文件。该文件将在当前目录中创建(或覆盖)。
conda env export > environment.yaml上面的export命令的第二部分,> environment.yaml将导出的文本写入environment.yaml。现在可以使用Github存储库(或任何其他方式)共享此文件,其他人将能够创建与项目所用的环境相同的环境。
对于不使用conda的用户,您可能希望共享当前环境中安装的软件包列表。您可以使用以下pip命令生成此类列表作为requirements.txt文件:
pip freeze > requirements.txt稍后,您可以requirements.txt通过Github与其他用户共享此文件。用户(或您自己)切换到另一个环境后,可以使用以下命令安装requirements.txt文件中提到的所有软件包:
pip install -r requirements.txt您可以在此处了解更多有关使用pip而不是的信息conda。这将使人们更容易为您的代码安装所有依赖项
创建环境
要从环境文件创建环境,请使用以下命令:
conda env create -f environment.yaml上面的命令将创建一个新环境,其名称与中列出的相同environment.yaml。
conda env list //检查现有的环境如果有不再使用的环境,请使用下面的命令删除指定的环境(此处名为env_name)。
conda env remove -n env_name- 要了解有关conda及其在Python生态系统中的适用性的更多信息,请查看Jake Vanderplas的这篇文章:Conda的神话和误解。
- 这是conda词汇表文档,供您参考。
Jupyter
一直想学来着,这个课程也太好了吧!
jupyter notebook是一个Web应用程序,可让您将说明性文本,数学方程式,代码和可视化结合在一个易于共享的文档中。
非常适合数据处理,可以执行部分代码,并查看上下文信息等
原理
Notebooks are a form of literate programming proposed by Donald Knuth in 1984. With literate programming, the documentation is written as a narrative alongside the code instead of sitting off by its own. In Donald Knuth’s words,
Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.
After all, code is written for humans, not for computers. Notebooks provide exactly this capability. You are able to write documentation as narrative text, along with code. This is not only useful for the people reading your notebooks, but for your future self coming back to the analysis.
Just a small aside: recently, this idea of literate programming has been extended to a whole programming language, Eve.
Jupyter笔记本源自Fernando Perez发起的IPython项目。IPython是一个交互式shell,类似于普通的Python shell,但具有诸如语法突出显示和代码之类补全的强大功能。最初,笔记本通过将消息从Web应用程序(您在浏览器中看到的笔记本)发送到IPython内核(在后台运行的IPython应用程序)来工作。内核执行了代码,然后将其发送回笔记本。当前的架构与此类似,如下所示。
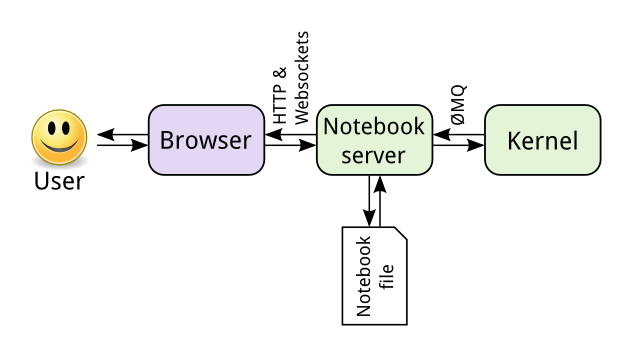
中心点是笔记本服务器。您通过浏览器连接到服务器,并且笔记本呈现为Web应用程序。您在Web应用程序中编写的代码通过服务器发送到内核。内核运行代码并将其发送回服务器,然后所有输出将在浏览器中呈现。保存笔记本时,它将作为带有.ipynb文件扩展名的JSON文件写入服务器。
该体系结构的很大一部分是内核不需要运行Python。由于笔记本和内核是分开的,因此可以在它们之间发送任何语言的代码。例如,两个较早的非Python内核分别用于R和Julia语言。对于R内核,用R编写的代码将被发送到R内核并在其中执行,这与在Python内核上运行的Python代码完全相同。IPython笔记本被重命名,因为笔记本变得与语言无关。新名称Ju pyt er来自Ju lia,Pyt hon和R的组合。如果您有兴趣,这里是可用内核的列表。
另一个好处是服务器可以在任何地方运行并可以通过Internet访问。通常,您将在存储所有数据和笔记本文件的自己的计算机上运行服务器。但是,您也可以在远程计算机或云实例(例如Amazon的EC2)上设置服务器。然后,您可以从世界任何地方在浏览器中访问笔记本。
可以同时启动多个笔记本服务器,这会在8888默认端口后继续创建
启动
您应该考虑安装Notebook Conda软件包以帮助管理您的环境。运行以下终端命令:
conda install nb_conda
conda install -c conda-forge jupyter_contrib_nbextensions成功安装nb_conda软件包后,如果您在conda环境中运行笔记本服务器,则还可以访问下面显示的“ Conda”选项卡。在这里,您可以从Jupyter内部管理您的环境。您可以创建新环境,安装软件包,更新软件包,导出环境等等。
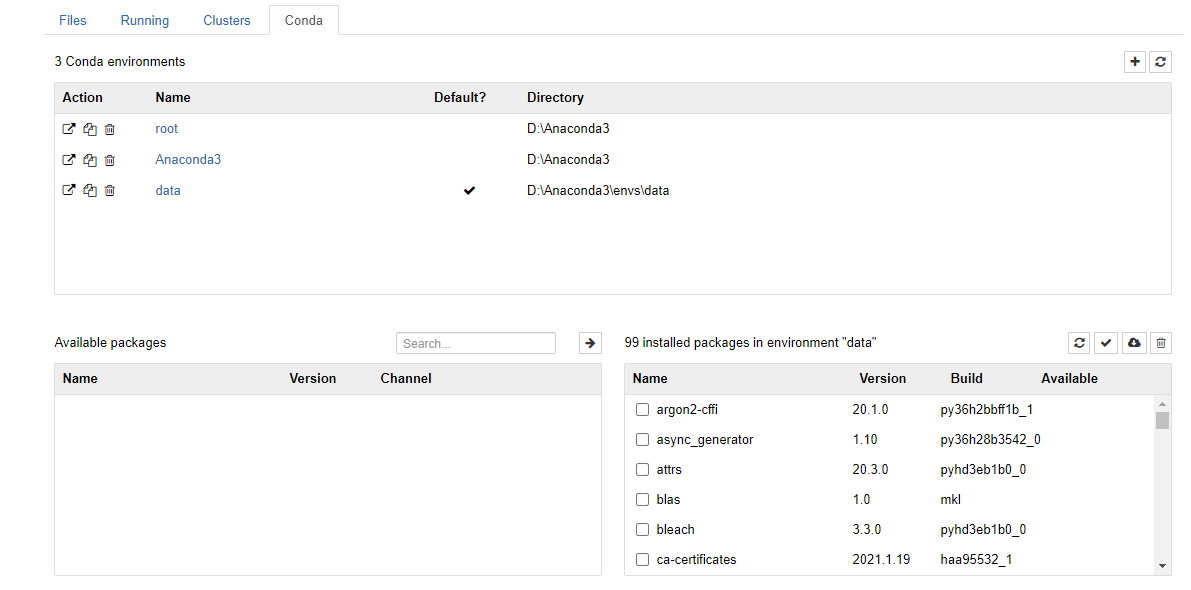
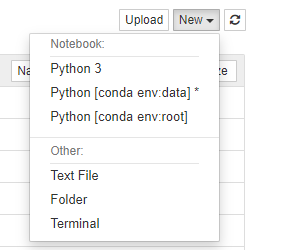
此外,nb_conda安装后,选择内核时,您将可以访问任何conda环境。例如,下图显示了在具有几种不同conda环境的计算机上创建新笔记本的示例:
关闭前记得保存
您可以通过标记服务器主页上笔记本旁边的复选框并单击“关闭”来关闭各个笔记本。不过,在执行此操作之前,请确保已保存您的工作!自上次保存以来所做的任何更改都将丢失。您还需要在下次运行笔记本时重新运行代码。
您可以通过在终端中按两次Control + C来关闭整个服务器。同样,这将立即关闭所有正在运行的笔记本,因此请确保您的工作已保存!
界面
先新建(选择一个内核)来创建一个notebook
上面的命令将在名为的新浏览器选项卡中创建一个新笔记本Untitled.ipynb
工具栏
简单明了,真不戳
小键盘是命令面板。这将显示一个带有搜索栏的面板,您可以在其中搜索各种命令。这对于加速工作流程非常有帮助,因为您无需使用鼠标在菜单中四处搜索。只需打开命令面板,然后输入您要执行的操作即可。

选项栏
右边是内核类型(在我的情况下为Python 3),旁边是一个小圆圈。当内核运行单元时,它将填充。对于大多数快速运行的操作,它不会填充。这是一个小指示器,可以让您知道更长运行的代码实际上正在运行。
连同工具栏中的“保存”按钮一起,笔记本会定期自动保存。标题右侧会显示最近保存的内容。您可以保存按钮,或者按与手动保存escape,然后按s。escape更改为命令模式,然后s是“保存”的快捷方式。稍后将介绍命令模式和键盘快捷键。
存储
在“文件”菜单中,您可以下载多种格式的笔记本。您通常会希望将其下载为HTML文件,以便与不使用Jupyter的其他人共享。另外,您可以将笔记本作为普通的Python文件下载,所有代码都将正常运行。 The Markdown and reST formats are great for using notebooks in blogs or documentation.
导入本地
File -> open 选择合适的.ipynb文件
或者直接upload,然后在文件导航里面查找你需要的文件
这里有一个markdown的备忘单
快捷键
又得学新的快捷键卧槽
首先,在编辑模式和命令模式之间切换。 编辑模式允许您键入单元格,而命令模式将使用按键来执行命令,例如创建新单元格和打开命令面板。 当您选择一个单元格时,您可以通过该单元格周围的框的颜色来判断当前正在使用哪种模式。 在编辑模式下,方框和左粗框显示为绿色。 在命令模式下,它们显示为蓝色。 同样在编辑模式下,您应该在单元格本身中看到一个光标。
默认情况下,当您创建一个新的单元格或移动到下一个单元格时,您将处于命令模式。 要进入编辑模式,请按Enter / Return。 要从编辑模式返回到命令模式,请按Escape键。
练习:单击此单元格,然后按Enter + Shift进入下一个单元格。 在编辑和命令模式之间切换几次。
在命令模式按下H可以打开帮助菜单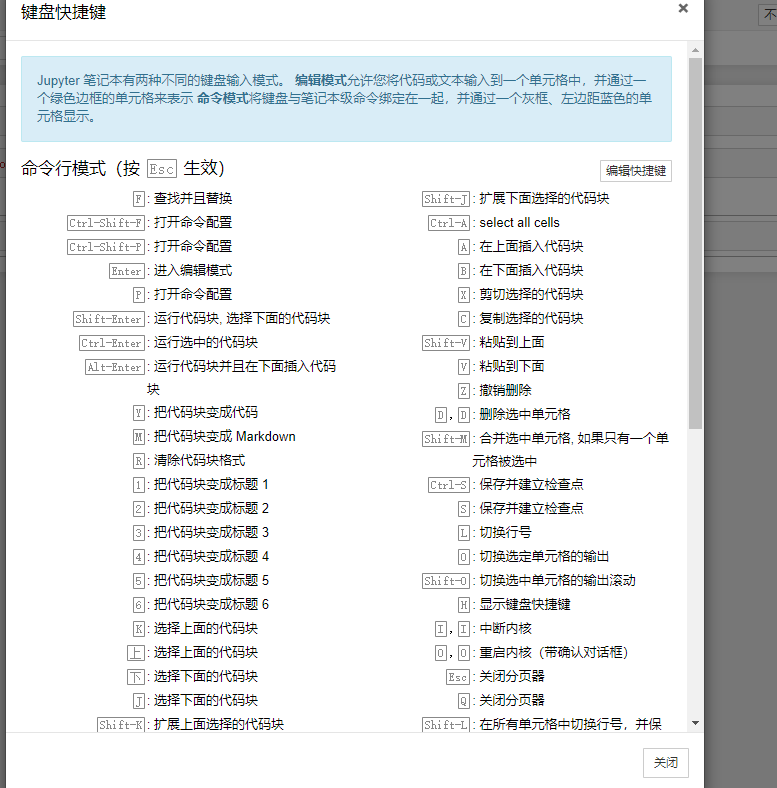
常用的快捷键
A 创建新单元格above当前单元格
B 创建新单元格below当前单元格
在markdown 和 code之间进行转换
markdown -> code Y
code -> markdown M
L 是显示行号d
双击D 可以删除单元格,Z撤销删除
S 保存!
最强的是P
打开万能的控制栏
*魔术关键字
Magic Keywords
魔术关键字是特殊命令,您可以在单元格中运行这些命令,以使您可以控制笔记本电脑本身或执行系统调用(例如更改目录)。例如,您可以使用设置matplotlib以在笔记本中进行交互工作%matplotlib。
魔术命令前面分别带有针对行魔术和单元魔术的一个或两个百分号(%或%%)。线魔术仅适用于在其上写入了魔术命令的行,而单元格魔术适用于整个单元。
注意:这些魔术关键字特定于普通的Python内核。如果您使用的是其他内核,那么这些内核很可能无法正常工作。
如果您想计时整个单元需要多长时间,可以这样使用%%timeit:
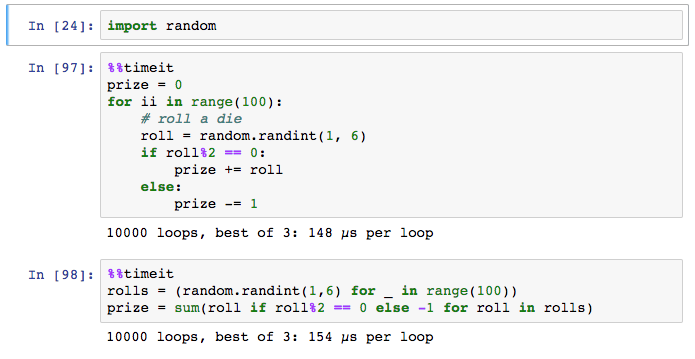
以后学学。。。
在笔记本中嵌入可视化
如前所述,笔记本使您可以将图像以及文本和代码嵌入其中。当您使用matplotlib或其他绘图程序包创建可视化效果时,此功能最为有用。您可以使用%matplotlib设置matplotlib为在笔记本中进行交互使用。默认情况下,图形将在其自己的窗口中呈现。但是,您可以将参数传递给命令以选择特定的“后端”,即渲染图像的软件。要直接在笔记本中绘制图形,您应该在命令中使用嵌入式后端%matplotlib inline。
提示:在高分辨率屏幕(例如Retina显示屏)上,笔记本计算机中的默认图像可能看起来模糊。使用
%config InlineBackend.figure_format = 'retina'after%matplotlib inline渲染更高分辨率的图像。

在笔记本中调试
使用Python内核,您可以使用magic命令打开交互式调试器%pdb。导致错误时,您将能够检查当前名称空间中的变量。

在笔记本中调试
在上面可以看到我试图总结一个给出错误的字符串。调试器会引发错误,并提示您检查代码。
pdb在文档中了解更多信息。要退出调试器,只需q在提示中输入即可。
更多阅读
还有很多其他魔术命令,我只涉及了一些您最常使用的命令。要了解有关它们的更多信息,这是所有可用的魔术命令的列表。
转换笔记本
Notebooks are just big JSON files with the extension .ipynb.
由于笔记本是JSON,因此很容易将它们转换为其他格式。Jupyter附带有一个实用程序,nbconvert用于将其转换为HTML,Markdown,幻灯片等。将给定mynotebook.ipynb文件转换为另一个FORMAT的一般语法为:
jupyter nbconvert --to FORMAT mynotebook.ipynb当前支持的输出FORMAT可以是以下任意一种(忽略大小写):
- HTML,
- LaTeX,
- PDF,
- WebPDF,
- Reveal.js HTML slideshow,
- Markdown,
- Ascii,
- reStructuredText,
- executable script,
- notebook.
For example, to convert a notebook to an HTML file, in your terminal use
# Install the package below, if not already
pip install nbconvert
jupyter nbconvert --to html mynotebook.ipynb注-如果您希望在conda中安装Anaconda发行版中没有的任何软件包(例如Airbase软件包),请使用
pip install airbase,而不是conda install airbase。
转换为HTML可以与不使用笔记本的其他人共享您的笔记本。Markdown非常适合在博客和其他接受Markdown格式的文本编辑器中添加笔记本。
与往常一样,从文档中了解更多nbconvert信息。
幻灯片
幻灯片是像普通笔记本一样在笔记本中创建的,但是您需要指定哪些单元格是幻灯片以及该单元格将是幻灯片的类型。在菜单栏中,单击“视图”>“单元格工具栏”>“幻灯片放映”以在每个单元格上弹出幻灯片单元格菜单。
打开单元格的幻灯片工具栏
这将在每个单元格上显示一个菜单下拉菜单,使您可以选择该单元格在幻灯片中的显示方式。
Slides are full slides that you move through left to right. Sub-slides show up in the slideshow by pressing up or down. Fragments are hidden at first, then appear with a button press. You can skip cells in the slideshow with Skip and Notes leaves the cell as speaker notes.
运行幻灯片
要从笔记本文件创建幻灯片,您需要使用nbconvert:
jupyter nbconvert notebook.ipynb --to slides这只是将笔记本转换为幻灯片所需的文件,但是您需要将其与HTTP服务器一起使用才能实际查看演示文稿。
要转换并立即看到它,请使用
jupyter nbconvert notebook.ipynb --to slides --post serve这将在您的浏览器中打开幻灯片放映,以便您进行演示。



