前言
本课程结构:
- 神经网络计算:搭建第一个神经网络模型
- 神经网络优化:学习率、激活函数、损失函数、正则化、自写优化器
- 神经网络八股:搭建八股“六步法”
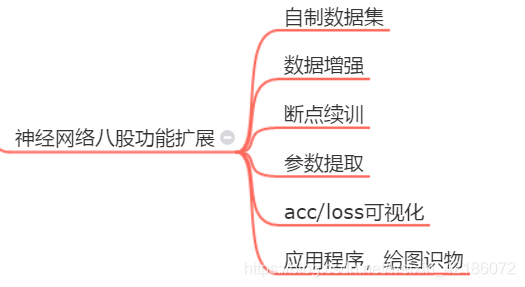
- 网络八股扩展:八股拓展:自制数据集、数据增强、断点续训、参数提取、可视化、给图识物
- 卷积神经网络:用CNN和一些工具实现图像识别
- 循环神经网络:用RNN和一些工具实现股票预测
每一章的思维框架借鉴了大佬的博客,学完一章可以看这里
鸢尾花
专家系统是理性的。(if case。)
但是有些花农直接可以看出种类,因为他们见了太多,而且经验越丰富,识别准确率越高
这是一种感性的直觉,是这门课介绍的神经网络方法

具体实现
MP模型,每个输入特征乘以线上的权重,再通过一个非线性函数输出,简化是去掉非线性函数

每个输出节点都链接了所有的输入关系,称为全连接网络

TF2
把numpy格式转换为tensor格式
创建形式和numpy非常类似!
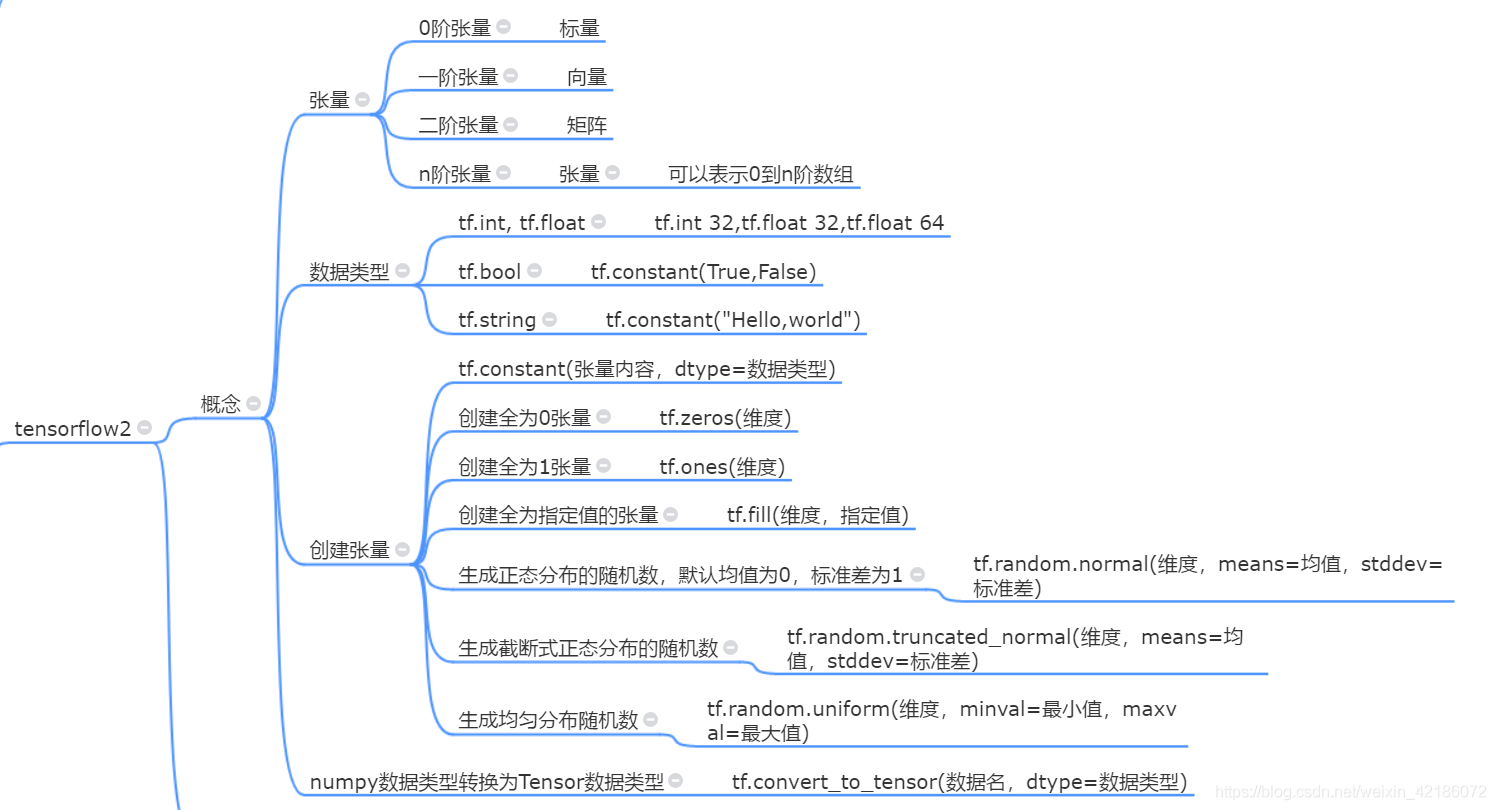
tensorflow中一切皆为张量,包括输出的常数结果也是一个shape = ()的tensor类型张量

其中tf.argmax可以直接接受numpy数组类型的参数

鸢尾花2

class1 P45 非常重要,建议全文背诵hhh
参数知识
先介绍一些函数:

记住这个是逐个比较


复杂度
输入层不算层数

学习率

只是增加了一些代码
激活函数

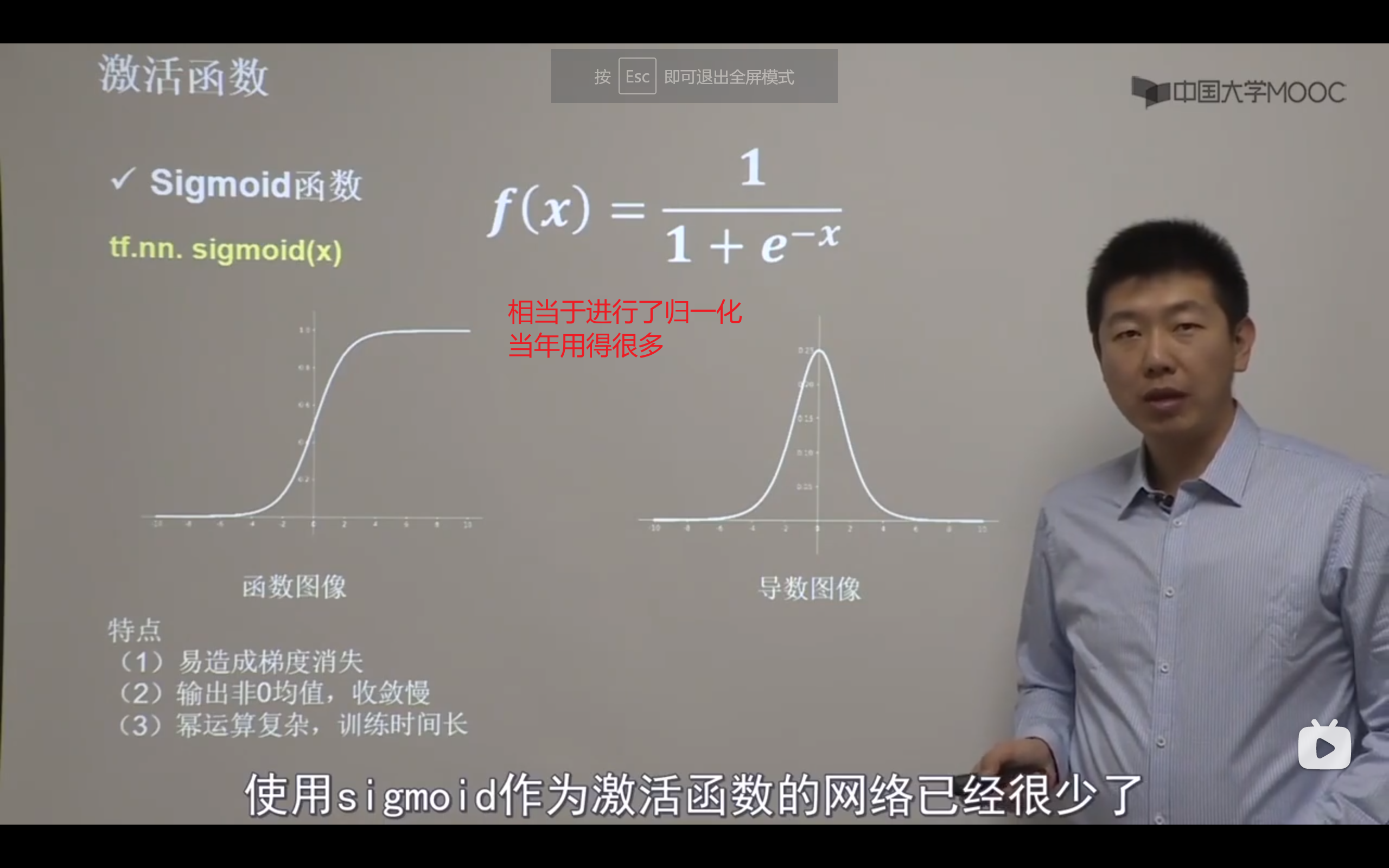
因为反向传播从输出层向输入层逐层求导,每一层的导数都落在0-0.25,多了以后趋于0,称为梯度消失,无法更新参数。所以sigmoid函数如今用的很少了

通过调整初始化来避免“神经元死亡(一直是0)”,可以设置更小的学习率,减少参数分布的巨大变化,来👆

初学者的建议:

对零均值化的解释:
https://blog.csdn.net/wtrnash/article/details/87893725
损失函数

loss_mse = tf.reduce.mean(tf.square(y_-y))
P19随机数使用很秀。
有时候也要根据实际情况自定义损失函数。

交叉熵计算概率分布间的距离
tf.losses.categorical_crossentropy(y,y_)

这个虽然可以配合softmax使用,但是还有集成的👇

如图,一换二不亏
拟合
欠拟合是对现有数据集学习的不太彻底,拟合效果不好
过拟合是对现有数据拟合的太好,却对新数据难以处理
ps:
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数。 相反,其他参数的值通过训练得出。
超参数:
- 定义关于模型的更高层次的概念,如复杂性或学习能力。
- 不能直接从标准模型培训过程中的数据中学习,需要预先定义。
- 可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定

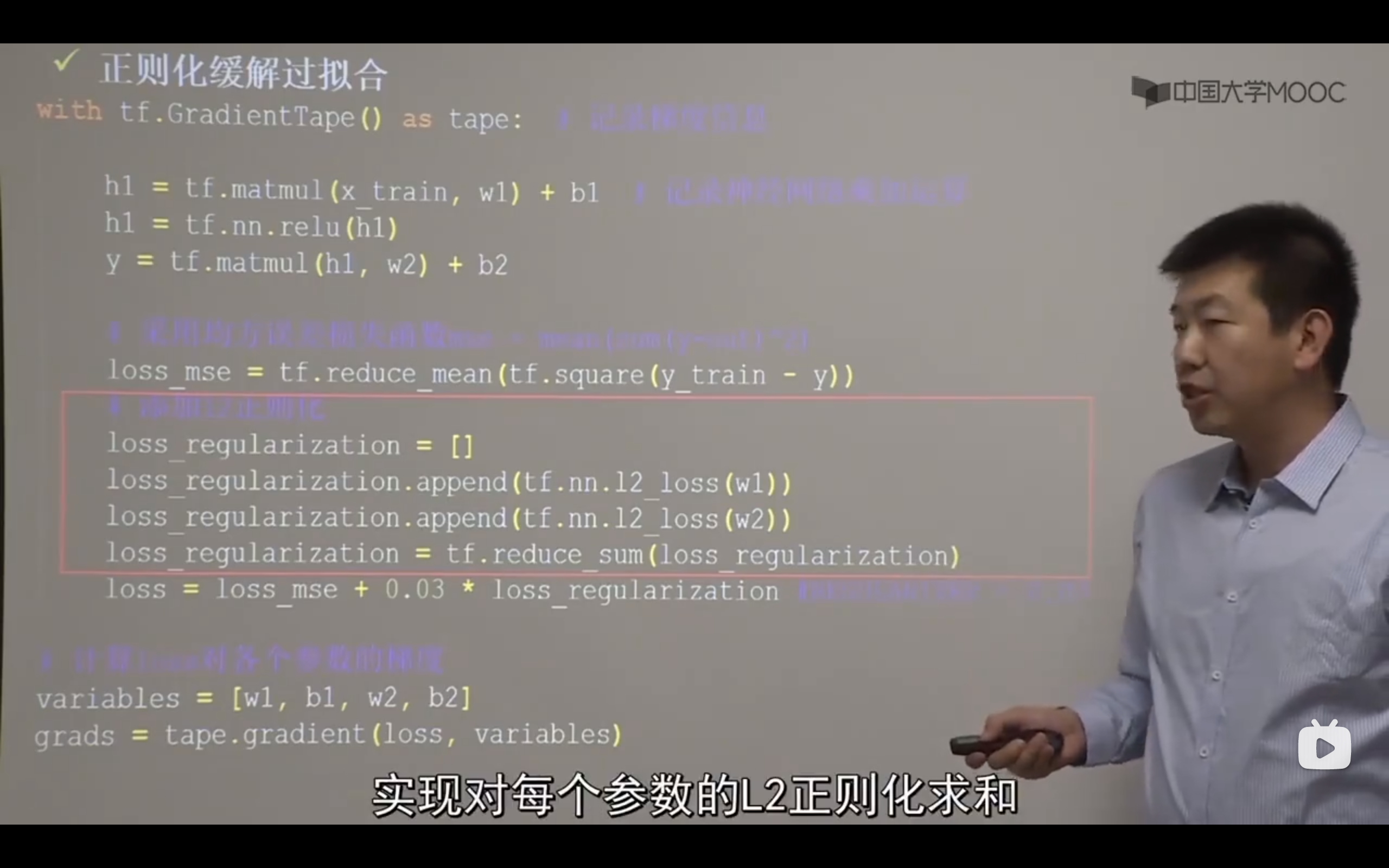
P29有最优化代码
把区分0和1的分界线0.5标出颜色
优化器(跳)
神经网络参数优化器
不同的优化器,实质上只是定义了一阶动量和二阶动量的公式。

????这个公式是什么鬼
gt是梯度,梯度下降优化器👇P32
我跑出来6.5s

我跑出来7.7s

这个公式,加了一个二阶动量,python实现如下👇P34

P36 7.3s

移动平均->指数滑动平均:
指数平滑法是在移动平均法基础上发展起来的,它具有移动平均法的优点,又可以减少运算过程中的数据储存量,同时还考虑了不同时期的数据所起的不同作用。采用指数平滑法的关键是确定α值。一般情况下,α值的大小,既和反映近期数据的能力有关,也和数据波动状况有关。通常不直接利用一次指数平滑法来预测,而是利用二次指数平滑法,求出平滑系数,建立起预测模型,再进行预测
P38 8.3s



请注意:pycharm开的控制台越多越卡,所以之前的数据应该作废呜呜。。。还有以后跑之前记得把控制台全部关上。
八股

使用keras搭建

MNIST是著名的手写数字识别
Fashion是著名的着装图片识别。
提纲
六步:

导入
设定训练、测试集
逐层搭建神经网络、前向传播
配置训练方法(优化器、损失函数、评测指标)
执行训练过程
打印网络结构和参数统计
Sequential可以认为是个容器,封装了神经网络的结构

卷积神经网络和循环神经网络,在第五讲和第六讲的时候再讲。
compile里的参数既可以填默认的字符串,亦可以写出具体函数然后细调参数
入门建议直接写名字,等掌握了再去官网查看函数的具体用法,调整超参数,细调函数参数

注意from_logits判断是否经过了概率分布,如果没有进过概率分布,该参数就是true
后面经常使用sparse_categorical_accuracy

按照比例,还是按照输入特征分类。
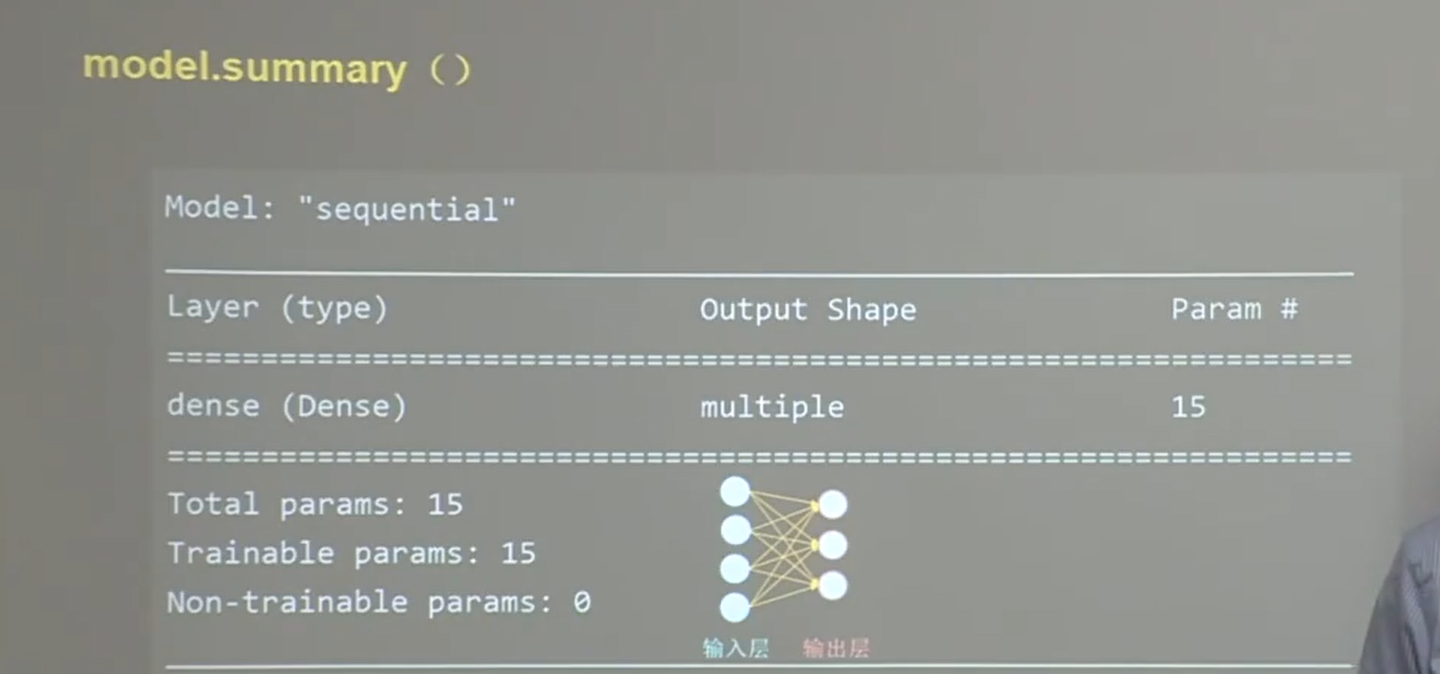
param = (输入+1)*输出 1是因为bia
鸢尾花复现在class3里的p8
如果需要“跳连”,大概就是可以设置比较深层的神经网络p11
init函数设置各层,call函数调用各层进行前向传播

其中区别如下👇,

数据集
MNIST

在class 3 里 p13 14 15
FASHION

八股功能扩展