前言和环境
跨学科是数据科学的关键
ipython
?和?? ?几乎适用任何对象包括魔法指令
有时候??不能显示源代码,因为该对象不是用python实现的,此时等价于一个?
Tab补全,配合通配符 * 使用
一般带下划线的私有方法和特殊方法不会被默认显示,可以通过显式输入 _ 再tab来获取他们
甚至可以 import <TAB> 查看你能导入的包
C + a/e
C + u/k 剪掉前面,后面
C + t 交换前两个字符,怪毙了
C + r对历史反向搜索,继续ctrl+r往前匹配下一个,找到后回车
C + l/c/d 清屏,中断当前python命令,退出ipython会话
魔法指令
ipython在普通python语法上的增强功能
行魔法 %
单元魔法 %%,用于处理多行输入比如%%timeit
%quickref 快速参考卡
%magic 探索所有魔术命令
%debug从最后发生报错的底部进入交互式调试器 %pdb出现任意报错自动进入调试器
%hist
%paste %cpaste 解决包含符号的多行输入/复制问题
%reset 清空所有变量/名称 %xdel variable 删除变量和相关引用
%page OBJECT 通过分页器更美观的打印一个对象
%run %prun statement 使用CProfile执行语句,报告输出
%time 报告单个语句执行时间 %timeit 多次运行单语句,计算平均执行时间,用于估算代码最短执行时间
%who %who_ls %whos 依次更加详细的展示变量集成matplotlib:
- 在ipython命令行中 %matplotlib
- 在jupyter中 %matplotlib inline
In是一个列表,记录了历史命令
Out是一个字典,将输入的索引对应起输出,很多命令没有输出(None),则不会被记录!
Out[x] 的简写是_x
print(_) 一二三条下划线对应倒数第几个历史输出,这个厉害,或者直接 _3
但是如果输入的最后加上;就不会被添加到历史,也不会把输出显示出来,这样当其他引用被删除时,该空间可以被释放。
shell
很多教材说是用 ! 加shell指令,但是pycharm全是%呀
可以用赋值将任何shell命令的输出保存到一个python列表,这是一个长得像列表的特殊返回类型
在shell里面用{varname}来调用变量
很多shell的指令可以直接使用,比如%cd 可以直接cd
调试
%xmode Plain/Context/Verbose 异常模式,改变异常时的打印信息
plain只会输出函数和行号,context是默认,会显示出错行上下几行代码,verbose还会显示每一级的参数和出错位置的变量值,好方便
标准调试工具pdb 的Ipython增强版ipdb,ipython专用
还有个很方便的%debug魔法指令,在最近的异常点打开一个交互式调试指令符(是用了ipdb)
%pdb on 会在抛出异常时自动启动,pdb有 up down 等命令配合print来检查
有一些常用调试命令:
list 显示路径
h(help) 显示命令列表
q(uit) 退出调试器和程序
c(ontinue) 推出调试器,继续程序
n(ext) 跳到程序下一步
<enter> 重复前一个命令
p(rint) 打印变量
s(tep) 步入子进程
r(eturn) 从子进程跳出代码的分析与计时
“大约百分之97的时间,我们应该忘记微小的效率差别;过早优化是不被推荐的”
但是当代码跑起来后,提高运行效率是有用的
%time 对单个语句的执行时间进行计时(适合不可重复的,或者时间较长的)
%timeit 对单个语句的重复执行进行计时,以获得更高的精确度(但需要保证可重复性,别对排序这样干)
在进行相同操作时,timeit总是比time更快,因为timeit在底层采取了一些措施组织系统调用对计时过程的干扰,例如阻止清理未利用的python对象。
👇需要安装line_profiler 和 memory_profiler 拓展
python包含一个内置的代码分析器,可以通过魔法指令👇简单的调用
%prun 使用分析器运行代码,输出一个时间报告 + 函数(参数)
%lprun 使用逐行分析器运行代码,逐行分析
%memit 测量单个语句的内存使用
%mprun 使用逐行的内存分析器运行代码%%file 来写一个简单的模块文件
Numpy
将异构的各种数据都看成数组,第一步将这些数据转化成数值数组形式的可分析数据。
数据科学的绝对基础:有效存储数据,操作数值数组
数据类型
标准的python实现是用C编写的,这意味着每一个python对象都是一个聪明的伪C结构体
比如python的整形变量其实是一个指针,它的结构体里包含了大量额外信息,所以可以自由,动态编码,但也会成为负担。
python列表实质:指向一个指针域,域里的每一个指针指向一个确切的对象
numpy牺牲了这一点,指向一块类似C的域,但是能更有效地存储和操作数据。
所以numpy要求数组必须包含同一类型的数据,不匹配则向上转换
数组基础
创建
np.array(手打l)
np.zeros(10,dtype = int)/ones((3,5),dtype = float)/full((3,5),3.14)
np.full(size,fulfiller) #用fulfiller填充
np.arange(0,10,2)#左闭右开 默认int
np.linspace(0,8,5)#左闭右闭 默认float,找5个等间距点
np.random.random((shape))# 0~1均匀分布
np.random.normal(0,1,(shape))# 均值 方差 shape
np.random.int(0,10,(shape))#左闭右开 区间[0,10)
np.random.uniform(x,y)
np.eye(n) #n单位矩阵
np.empty(shape) #未初始化的数组,数组值是内存空间中的任意值
np.mgrid(坐标轴1(左开右闭),坐标轴2) .ravel()拉直 .c_()组合 看另一个教程吧
用来生成网格
还有各种_alike()dtype可以用字符串参数或者相关的Numpy对象来指定。
标准类型大概有bool_ int类 float类 complex类 可以查一查,还有更高级的数据类型指定P35
后面带一个下划线的代表默认的类型
属性
ndim 维度 shape 形状(每个维度大小) size 元素个数(数组大小)
dtype 数据类型 itemsize 每个元素的字节大小 nbytes 总字节大小
索引切片
与python类似,更改元素时自动发生类型变换
获取第一列x2[: , 0]
获取第一行x2[0 , :] #获取行时其实可以省略,直接x2[0]
抽取左上角的2x2数组,x2[:2,:2]
切片返回的是视图,.copy() 才是复制,这意味着可以处理大型数据集的片段而不用花费额外的内存
变形
.reshape() 大小必须一致
或者在索引中使用newaxis 关键字,插入一个新维度,不过记得要加上前缀,即np.newaxis,比如原来有个是3(一行),后插变成(3,1)(一列)
x = x[np.newaxis,:] 在前面加了一个维度,反之则是在后面插入
拼接和分裂
np.concatenate(默认沿着第一个轴) #二维就是列,用axis = 1 可以改成行
grid = np.array([[1,2,3],
[4,5,6]])
np. concatenate([grid,grid],axis = 1)
array([1,2,3,1,2,3],
[4,5,6,4,5,6])前三维可以用np.vstack(垂直) np.hstack(水平) np.dstack(第三维) 来拼接
vertical horizontal deep
np.split(x, [3,5])#后面那个数组记录的是下一段首的索引位置,如果是3,那就在索引2(第3个元素)和3间断开,返回一个子元组
In [12]: grid
Out[12]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [8]: x1,x2,x3 = np.split(grid,[2,3])
In [9]: x1
Out[9]:
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
In [10]: x2
Out[10]: array([[ 8, 9, 10, 11]])
#np.hsplit 和 np.vsplit 和 np.dsplit 差不多,记得后面那里要用索引列表
upper,lower = np.vsplit(grid,[2]) #上下四行均分成两行通用函数
Numpy高效的关键是采用 向量化 操作,通常用通用函数(ufunc)实现——提高了数组元素重复计算的效率
Python灵活的数据类型导致序列操作不能被编译成有效的机器码,所以循环操作超级慢
很多方案试图解决,比如Cpython,Cython,LLVM字节码,但是Cpython是最流行的
Cpython的主要瓶颈在于每次循环时必须做数据类型检查和函数的调度。
Numpy为许多类型的操作提供了方便,静态,可编译程序的接口,被称为向量操作。这将被循环推送至Numpy下的编译层。
只要看到python脚本有循环,就可以考虑能否用向量替代。
通用函数有两种形式,一元和二元。
python原生的算术运算符被重构了,相当于调用一些通用函数,比如 * 相当于 np.mulitiply
+ - * / // ** %都被重构了,还有布尔/位运算符
Numpy可以理解python内置的某些函数比如绝对值函数 abs(x),对应的是np.absolute 或者别名np.abs,但这个numpy的处理复数时返回幅值。
三角函数:sin cos tan arcsin arccos acrtan 还有很多别的
指对数:exp exp2(2^) power(底数,操作的数组x) ||log log2 log10
还有专门用来处理小量的:np.expm1(x) == exp(x) - 1 np.log1p(x) == log(1+x) #在x很小时精度较高
还有很多双曲三角啊,比特位运算,比较运算,弧度角度转化等等等。可以查文档
还有一个更专用的子模块scipy.special 里面有一堆牛逼函数比如伽马(广义阶乘), 高斯积分啥的,可以搜索xxx function python
高级特性
指定输出
有一个out参数指定输出结果的存放位置,此时不创建临时数组而直接写入目标位置,对于较大的数据能有效节约内存,但是注意要提前创建好用来存放的nparray
聚合
二元通用函数指的是对两个输入操作,它们有些非常有趣的聚合功能,可以直接在对象上计算,会对给定的元素和操作重复执行,直到得到单个结果,这是任何通用函数都有的方法
比如reduce(压缩),任何通用函数都有,可以重复计算直到获得单个结果
x = np.arange(1,6)
np.add.reduce(x)
x == 15 --True如果需要存储每次计算的中间结果,可以使用accumulate,项数不会变,但是除了第一项其他依次被处理
np.add.accumulate(x) –array([1,3,6,10,15])
外积
任何输入函数都可以使用outer方法获得 两个不同输入数组 所有元素对 的函数运算结果
In [5]: x = np.arange(1,6)
In [4]: np.multiply.outer(x,x)
Out[4]:
array([[ 1, 2, 3, 4, 5],
[ 2, 4, 6, 8, 10],
[ 3, 6, 9, 12, 15],
[ 4, 8, 12, 16, 20],
[ 5, 10, 15, 20, 25]])更多的通用函数信息可以在Numpy和SciPy的文档网站查到
聚合
在处理大量数据的时候第一步通常是计算相关概率的概括统计值,比如最常用的均值和方差。
Numpy又快速的内置聚合函数可用于数组,如下:
np.sum 和内置的sum都可以起作用,但是numpy的sum在编译码中运行,所以操作更快(1000倍),而且注意不要混淆,他们的参数有不同的意义,np.sum函数是知道数组的维度的
np.min max啥的,还有一种更简洁的语法是数组对象直接调用这些方法: x.min() x.sum()
多维度聚合
可以用axis指定处理的维度,但是要注意,这个指定的是数组将会被聚合(折叠)的维度,而不是要返回的维度,比如说axis = 0 意味着第一个轴(二维数组的列)将要被折叠。
numpy有很多内置的聚合函数,大多数聚合都有对NaN的安全处理策略,即计算的时候忽略所有缺失值。
np.sum np.nansum
np.prod np.nanprod 积(product)
np.mean 平均值
std 标准差 Standard deviation
var 方差 variance
min max 最小最大
argmin argmax 最小最大的索引
median 中位数
percentile 基于元素排序的统计值,例子如下
In [7]: x
Out[7]: array([1, 2, 3, 4, 5])
In [8]: np.percentile(x,75)
Out[8]: 4.0
In [9]: np.percentile(x,100)
Out[9]: 5.0
any all 存在 任意为真 #无安全版本广播
可以理解为将低维数组拓展,拓展到匹配的维度,但是其实并没有发生这样的内存分配,只是便于理解。
规则如下:
- 如果两个数组的维度不同,小维度数组的形状在最左边补1
- 如果数组在任何一个维度上大小不相等,而且数组该维度为1,则会沿着该维度拓展到匹配另一个数组
- 如果数组在任何一个维度上大小不相等,而且并没有某个数组维度为1,那么引发异常。
- 小心numpy的一维数组,也就是shape是(n,)这不等于列向量!
最值得注意的就是他补充一个维度是在左边补1而不是右边,如果希望右边补全,可以使用变形数组。
这些广播规则适用于任意二进制通用函数
实际应用
数组的归一化
In [12]: X = np.random.random((10,3))
In [13]: Xmean = X.mean(0) #沿着第一个维度聚合
In [14]: X_centered = X - Xmean
In [15]: X_centered.mean(0)
Out[15]: array([-8.88178420e-17, 0.00000000e+00, -1.11022302e-17])
妙啊画一个二维函数
看不懂他的骚操作,可以翻一下书的P60页比较,掩码,布尔
当想基于某些准则来抽取,修改,技术或对一个数组中的值进行其他操作时,掩码就可以派上用场了,在Numpy中,布尔掩码是完成这类任务的最高效完成方式。
比较有六种运算符== != < <= > >= 两边可以是表达式,每次返回的结果是布尔数组
利用复合表达式实现逐元素比较也是可行的
In [11]: (2*x) == (x ** 2)
Out[11]: array([False, True, False, False, False])这些比较运算符也是借助通用函数来实现的,例如x < 3 其实调用np.less(x,3)
操作布尔数组
记录布尔数组中非零(其实就是True)的个数 np.count_nonzero()
统计小于6的则np.count_nonzero(x<6)
或者也可以 np.sum(x<6) 都是返回为True的个数,sum的好处是可以沿着行或者列进行
np.any 和 np.all 快速检测全部
需要提醒的是python有内置的sum,any,all函数,这些函数在numpy中有对应的版本,但是语法不同,如果在多维数组上混用这两个版本,会导致神奇的错误,请确保使用numpy版本
布尔运算符
逻辑运算符也被重载,可以实现对数组的逐位逻辑运算。有& | ^ ~
np.sum((inches > 0.5) & (inches < 1)) 注意用括号调整运算次序。表示inches在0.5到1间的数目
将布尔数组作为掩码
就是传说中的布尔矩阵作为索引呗,会得到一个一维数组
and or 和 & | 的区别and / or 判断整个对象是真是假,而后两者是指每个对象中的比特位,依次化成二进制码进行操作而布尔矩阵可以被当成比特字符组成的,所以采用后者,而使用前者比较整个对象的时候会出错。记得布尔索引会被拉直成一个一维数组,所以还是当作索引用,不要单独用。
花哨的索引
花哨(fancy)的索引对多个维度也适用。
花哨索引和前面的简单索引类似,但是传递的是索引数组,可以让我们快速获得并修改复杂的数组值的子数据集
结果的形状与索引数组的形状一致,如果有广播,就是跟广播后的索引数组的形状一致,而不是被索引的数组
如果是普通的一维一维的
b = np.array([[0,1,2,3],
[4,5,6,7],
[8,9,10,11]])
row = np.array([0,1,2])
col = np.array([2,1,3])
b[row,col]那就像坐标一样
Out[13]: array([ 2, 5, 11])
但如果b[row[:,np.newaxis],col]
array([2,1,3],
[6,5,7],
[10,9,11])
那就是广播,淦,当年为何困惑了我这么久,广播以后 索引数组的每一个位置其实都是一个坐标。。就这么简单配合切片,简单索引,布尔效果更好。
应用
从一个矩阵中选择行的子集!
可以用花哨索引来修改值,但是重复的索引会有一些诡异的事情发生
In [20]: i = [2,3,3,4,4,4]
In [21]: x = np.zeros(10)
In [22]: x[i] += 1
In [23]: x
Out[23]: array([0., 0., 1., 1., 1., 0., 0., 0., 0., 0.])
#应该看成x[i] = x[i] + 1就会发现神奇索引导致的诡异地方,解决方法是at👇at函数可以对给定的操作,给定的索引,给定的值进行就地操作。
比如np.add.at(x,i,1) x为被操作的矩阵,i为索引,1为操作数(+1)
数组的排序
python有内置的sort和sorted但是太慢了
np.sort 是快速排序【N log N】,另外可以选择归并排序和堆排序。
np.sort(X) 不会修改原始数组,x.sort()这种python内置的方法会替代原始数组
np.argsort(X)返回的是如果排序 好的索引值。
利用axis可以选择行列排序噢,这是将行和列当成独立数组,任何关系都将丢失!
部分排序:分隔
np.partition(x,3) 将最小的3个和其他的分隔开,两组数是任意排序的
当用axis时也会破坏行和列的关系,np.argpartition返回索引
结构化数据
P82 数据类型
Numpy的结构化数组和记录数组。
他们为复合的,异构的数据提供了非常有效的存储。
其实就是把dtype当作一个结构嘛
name = ['a','b','c','d']
age = [21,21,21,34]
weight = [21.21,4.43,4334.65,45.9]
data = np.zeros(4,dtype = {'names':('name','age','weight'),
'format':('U10','i4','f8')})
#U10表示长度不超过10的字符串,
data['name']=name
data['age']=age
data['weight']=weight
这样可以用连续的内存存储异构的数据,反映了他们间的关系
可以用date[0]查看是('a',21,21.21)
然后就有很多骚操作比如
data[data['age']<30]['name']#获得年龄小于30的人的年龄
数值类型可以用python类型或者Numpy的dtype来指定2
< 和 > 分别表示低字节序 和 高字节序
b 字节型
i u 有、无符号整形
f 浮点型
c 复数浮点型
S a 字符串
U Unicode编码字符串
V 原生数据
#还有一种格式是元组列表
np.dtype([('name','U10'),('age','<i4'),('weight','f8')])
这样就直接生成一个结构化数组
结构化数组的dtype属性里,第n个反映了每个单元中第n个数据的索引和属性,比如
data
[('Alice',25,55.0),('Bob',45,85.8),('Cathy',37,68.0)]
data.dtype
[('name','<U10'),('age','<i4'),('weight','<f8')]np.dtype([('id','i8'),('mat','f8',(3,3))])这样就定义了一个id和3x3矩阵的结构由于numpy中的dtype直接映射到C结构定义,包含数组内容的缓存可以直接在C程序里使用,如果想写一个python接口与一个遗留的C\Fortran接口交互,非常有用
如果需要使用结构化数组,更好是掌握pandas包。
Pandas
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame结构。
DataFrame本质上是一种带行标签和列标签、支持相同类型数据和缺失值的多维数组。
Pandas不仅为各种带标签的数据提供了便利的存储界面,还实现了许多强大的操作,这些操作对数据库框架和电子表格程序的用户来说非常熟悉
当我们需要处理更灵活的数据任务(为数据添加标签,处理缺失值),或者需要分组数据计算,Numpy就会显露出限制,而Pandas为“数据清理”(data munging)任务提供了捷径
对象简介
如果从底层视角观察pandas对象,可以看成是增强版的Numpy结构化数组,行列不再是简单的整数索引,还可以带上标签!要理解基本数据结构内部的细节!
Series
带索引数据的一维数组
可以用数组创建Series对象 data = pd.Series([0.25,0.5,0.75,1.0])
values属性返回Numpy数组的对象
index返回一个类型为pd.Index的类数组对象,后续介绍
name属性会作为dataframe的列标签
In [52]: data['one']
Out[52]:
Darren 21
Jack 37
Jessica 56
Name: one, dtype: int32
In [53]: data['one'].name
Out[53]: 'one'Series比它模仿的一维Numpy数组更加通用,灵活!!
本质差别在索引
Numpy数组用的是隐式定义的索引,Series是显式定义,索引完全可以是任意类型,不按顺序
pd.Series([2,2,22,],index = [‘a’,’c’,’d’])
字典将任意键映射到一组任意值,Series将类型键映射到一组类型值,
Pandas Series的类型信息使得她在某些操作上比Python的字典更高效
可以用字典创建一个Series对象
dict
Out[9]: {'dadaa': 1223, 'tda': 12124, 'dada': 341}
dict2 = pd.Series(dict)
dict2
Out[11]:
dadaa 1223
tda 12124
dada 341
dtype: int64
#用字典创建对象时,索引按照排序好的默认顺序排列Series支持索引切片!
dict2[‘dadaa’:’dada’]
在pd.Series(data,index = index)中,data若是标量,则会填充到每一项上
索引默认0-n整数序列,RangeIndex(start = 0, stop = n, step = 1)
data可以是列表,字典(index是默认的排序字典键,也就是先会按照默认方式排序一遍)
每种类型都可以通过显式指定索引筛选需要的结果:但是字典这样做只会保留显式定义的部分键值对!
In [3]: a = np.array([2,3,4,5,6])
In [4]: b = dict([['a',4],['b',5],['c',7]])
In [5]: a1 = pd.Series(a,index = [1,3,4])
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-5-5bed21d603af> in <module>
----> 1 a1 = pd.Series(a,index = [1,3,4])
D:\Anaconda3\lib\site-packages\pandas\core\series.py in __init__(self, data, index, dtype, name, copy, fastpath)
348 try:
349 if len(index) != len(data):
--> 350 raise ValueError(
351 f"Length of passed values is {len(data)}, "
352 f"index implies {len(index)}."
ValueError: Length of passed values is 5, index implies 3.
#当列表的时候index和data长度需一致
In [6]: a1 = pd.Series(b,index = ['a','c'])
In [7]: a1
Out[7]:
a 4
c 7
dtype: int64DataFrame
和Series一样,它也既可以作为一个通用型Numpy数组,也可以看作特殊的Python字典
可以看成一种既有灵活行索引,又有灵活列名的二维数组
可以看成有序排列的若干Series对象。这里的“排列”指的是它们拥有共同的索引
假设a,b是两个Series对象,而且拥有相同的索引,那么可以
c = pd.DataFrame({'column1':a,'column2':b}) #其中a和b为长度一样的Series对象
c
column1 column2
index1 32423 32423
index2 2189 2198128
index 312312 21312DataFrame的index属性和Series一样,返回Index对象(如果是默认生成的,则是RangeIndex)
还有个columns属性,也返回Index对象,不过是每列的标签
DataFrame可看成特殊的字典,每列映射一个Series数据,通过列索引c[‘column1’]可以得到该Series对象
创建
ps:创建字典
使用dict() 函数创建一个空字典并给变量赋值

第二种方法应该是大规模处理中用的多的

创建DataFrame
(1)可以用单个Series对象
pd.DataFrame(populations,columns = [‘population’])
(2)可以用元素是字典的列表来创建,若是字典有一些键(作为列索引)不在,会用NaN补全
data = [{'a':i,'b':2*i}for i in range(3)]
data
Out[10]: [{'a': 0, 'b': 0}, {'a': 1, 'b': 2}, {'a': 2, 'b': 4}]
pd.DataFrame(data)
Out[12]:
a b
0 0 0
1 1 2
2 2 4
pd.DataFrame([{'a':1,'b':2},{'b':3,'c':4}])
Out[13]:
a b c
0 1.0 2 NaN
1 NaN 3 4.0
#这里的例子都是用默认Index(3)通过Series对象、列表字典创建
c = pd.DataFrame({'column1':a,'column2':b})
c
column1 column2
index1 32423 32423
index2 2189 2198128
index 312312 21312
如果值是列表,索引是默认的0,1,2(4)通过Numpy二维数组创建。假如有二维数组,就可以创建一个可以指定行列索引值的DataFrame,如果不指定,那么行列都是默认索引 IndexRange
pd.DataFrame(np.random.rand(3,2),columns = ['foo','bar'],index = ['a','b','d'])
Out[15]:
foo bar
a 0.855538 0.595667
b 0.575162 0.149108
d 0.034177 0.156297(5)通过Numpy结构化数组创建
A = np.zeros(3,dtype = [('A','i8'),('B','f8')])
In [4]: A
Out[4]: array([(0, 0.), (0, 0.), (0, 0.)], dtype=[('A', '<i8'), ('B', '<f8')])
In [5]: pd.DataFrame(A)
Out[5]:
A B
0 0 0.0
1 0 0.0
2 0 0.0
可以发现子结构的名字被作为了列标签Index
可以看成一个不可变数组或有序集合,可以包含重复值。这两种观点体现了其一些功能
不可变数组
Index很多操作都像数组,比如切片,还有许多与Numpy数组相似的属性,比如
In [8]: ind = pd.Index([2,3,5,7,11])In [9]: indOut[9]: Int64Index([2, 3, 5, 7, 11], dtype='int64')In [10]: ind[::2]Out[10]: Int64Index([2, 5, 11], dtype='int64')In [11]: print(ind.size,ind.shape,ind.ndim,ind.dtype)5 (5,) 1 int64#这几个属性竟然还保留了最大的不同在于Index对象的索引是不可变的,ind[1]=0会报错,这使得索引共享更安全
有序集合
Index遵循python标准库的集合(set)数据结构的许多惯用法 & | ^ ~
indA & indB 也有indA.intersection(indB)
数据取值与选择
类推Numpy的各种花式操作
Series
两个类比:一维Numpy数组和Python标准字典,很多操作是一样的。
看作字典
In [3]: data = pd.Series([0.25,0.5,0.75,1.0],index = ['a','b','c','d'])
In [4]: data['b']Out[4]: 0.5In [5]: 'a' in dataOut[5]: TrueIn [7]: data.values() #这个失败了
In [63]: ata.values
Out[63]: array([0.25, 0.5 , 0.75, 1. ])
In [64]: ata.keys
Out[64]: <bound method Series.keys of a 0.25b 0.50c 0.75d 1.00dtype: float64>
In [65]: ata.keys()
Out[65]: Index(['a', 'b', 'c', 'd'], dtype='object')
In [8]: data.items()
Out[8]: <zip at 0x201ee3bbcc0>
In [9]: list(data.items())
Out[9]: [('a', 0.25), ('b', 0.5), ('c', 0.75), ('d', 1.0)]In [10]: data['e'] = 1.25
In [11]: data
Out[11]:a 0.25b 0.50c 0.75d 1.00e 1.25dtype: float64Series对象的可变性是一个非常方便的特性,pandas在底层已经为可能发生的内存布局和数据复制自动决策,用户不用担心。
看作一维数组
包括索引,掩码,花哨索引都有
In [13]: data['a':'c'] #显示索引包含最后一位Out[13]:a 0.25b 0.50c 0.75dtype: float64In [14]: data[0:2] #隐式索引不包含最后一位Out[14]:a 0.25b 0.50dtype: float64In [15]: data[(data>0.3) & (data<0.8)] #布尔索引yydsOut[15]:b 0.50c 0.75dtype: float64In [16]: data[['a','e']]#fancy indexOut[16]:a 0.25e 1.25dtype: float64索引器
切片和取值的习惯用法经常混乱,如果Series选了显式整数索引,那么data[1]这样取值会使用显式索引,而data[1:3]这样的切片操作却会使用隐式索引!
所以Pandas准备了一些索引器(indexer)来作为取值的方法
它们不是Series对象的方法,而是暴露切片接口的属性
loc属性
表示使用显式切片和取值,左闭右闭!!
In [17]: data = pd.Series(['a','b','c'],index = [1,3,5])
In [18]: data.loc[1]
Out[18]: 'a'
In [20]: data.loc[1:3]
Out[20]:
1 a
3 b
dtype: object
#不然的话默认是隐式的
In [21]: data[1:3]
Out[21]:
3 b
5 c
dtype: object同理,iloc 表示都是python形式的隐式索引,左闭右开
ix是前两者的混合,在Series对象中ix等价隐式,主要用于DataFrame。已经被弃用了
Python的设计原则之一是“显式优于隐式”,loc和iloc让代码更容易维护。
DataFrame
DataFrame有些方面像二维或结构化数组,有些方面又像一个共享索引的若干Series对象构成的字典
看作字典
看作由若干Series对象组成的字典
比如 area 和 pop是索引一样的两个Series
data = pd.DataFrame({‘area’: area,’pop’: pop})来构建列索引为area和pop的数组
可以通过对列名进行字典形式取值,也可以用属性形式选择纯字符串列名的数据
data['area'] is data.area True 都是选取同一个Series对象
但是如果列名不是纯字符串,或者列名与DataFrame的方法同名,那么就不能使用,比如pop方法
由此还要避免用data.pop = z 这种形式赋值,而要用 data[‘pop’] = z来赋值
和前面介绍的Series对象一样,还可以用字典形式的语法调整/增加对象,如果要增加一列可以这样:
data[‘c’] = data[‘a’]/data[‘b’] 顺便展示了两个Series对象算术运算的简便语法,(。・∀・)ノ゙嗨
看作二维数组
可以看成是一个增强版的二维数组,用values属性按行查看数组数据(还记得Series是没有values属性的)
In [35]: x
Out[35]:
one two
Darren 123 123313
Jack 21212 2131132
In [36]: x.T
Out[36]:
Darren Jack
one 123 21212
two 123313 2131132
In [37]: x.values
Out[37]:
array([[ 123, 123313],
[ 21212, 2131132]])
In [38]: x.items
Out[38]:
<bound method DataFrame.items of one two
Darren 123 123313
Jack 21212 2131132>
In [39]: x.columns #注意复数
Out[39]: Index(['one', 'two'], dtype='object')
In [40]: x.index
Out[40]: Index(['Darren', 'Jack'], dtype='object')
In [41]: x.keys
Out[41]:
<bound method NDFrame.keys of one two
Darren 123 123313
Jack 21212 2131132>
#因为索引被用在了列上,我们取行的能力收到了限制,x['one']可以取出一列
x['one']
Out[9]:
Darren 123
Jack 21212
Name: one, dtype: int32
#但是取行得用values属性
x.values[0]
Out[10]: array([ 123, 1213313])data.values,理解了”二维数组“这一点,就能引出很多骚操作:比如data.T转置
#可以用索引器来帮助进行索引
#loc 和 iloc 处理起来就像处理二维数组一样,而且行列标签会自动保存在结果中
#ix的规则是,既可以使用隐式也可以使用显式,但是在遇到整数索引时,规则和之前的Series一样混乱
#其他用于索引的功能全都可以用于这些索引器
data = pd.DataFrame(np.array([21,34,12,45,37,23,76,23,56,98,34,87]).reshape((3,4)),columns = ['one','two','three','four'],index = ['Darren','Jack','Jessica'])
data
Out[12]:
one two three four
Darren 21 34 12 45
Jack 37 23 76 23
Jessica 56 98 34 87
data.iloc[1:2,2:3]
Out[15]:
three
Jack 76
data.loc['Darren':'Jack','one':'three']
Out[16]:
one two three
Darren 21 34 12
Jack 37 23 76
#任何用于处理Numpy形式的方法都可用于这些索引器比如掩码和花哨
#结合使用来筛选一部分,先筛选行,再筛选列噢
In [50]: data.loc[data.one>22,['two','four']]
Out[50]:
two four
Jack 23 23
Jessica 98 87
#记住一定要加loc索引器,不然报错其他的取值方法
有点奇怪但是很好用。对单个标签取值就是选择列,对多个标签用切片就选择行
data[1:3] #隐式切片Out[21]: one two three fourJack 37 23 76 23Jessica 56 98 34 87data['Darren':'Jessica'] #显式切片Out[22]: one two three fourDarren 21 34 12 45Jack 37 23 76 23Jessica 56 98 34 87data['two']Out[23]: Darren 34Jack 23Jessica 98Name: two, dtype: int32#掩码操作起到筛选某些 行 的作用data[data.three>20]Out[24]: one two three fourJack 37 23 76 23Jessica 56 98 34 87# 这两种操作方法其实和Numpy数组的语法类似,虽然它们与Pandas的操作习惯不太一致,但是非常好用数值运算
Pandas继承了Numpy的功能,可以对元素进行快速运算
但是Pandas实现了一些高效的技巧:
- 对于一元计算,通用函数在输出结果中保留索引和列标签。
- 对于二元计算,Pandas在传递通用函数时会自动对齐索引进行计算
这意味着:保存数据内容 组合不同来源的数据 这两处在Numpy里容易出错的地方,成了Pandas杀手锏
ps:补充一下伪随机数
np.random.seed(1234)这个设置的是全局随机数种子rng = np.random.RandomState(123)#设置单独的随机数种子
arr = rng.randn(10) #这样生成的就是独立的
seedpermutation(arr) #返回一个序列的随机排列
shuffle # 随机排列一个序列,直接更改原来的
rand #从均匀分布[0,1)中抽取样本
uniform #选定区间【】均匀分布
randint #根据给定的从低到高(左闭右开,左边省略为0)的范围抽取随机一个整数,如果给一个元组,则在0-元组每一项之间取,输出一个列表
randn #从均值0方差1的正态分布
normal(x1,x2,(shape))#平均值,标准差,
shapebinomial #从二项分布中抽取样本
beta #从beta分布中抽取样本
chisquare #从卡方分布中抽取样本uniform(x1,x2,(shape)) #从均匀分布中抽取样本
gamma #从伽马分布中抽取样本索引对齐
当在两个Series或DataFrame对象上进行二元计算时,Pandas会在计算过程中对齐两个对象的索引,在处理不完整的数据时,这一点非常方便
结果数组的索引是两个输入数组索引的并集,缺失位置填充NaN,这是通过python内置集合运算规则实现的
我们也可以通过a.index | b.index 来获得这个新索引
两个对象的行列顺序可以是不一样的,结果的索引会自动排序
当然也能自行设置缺失值,A.add(B,fill_value = 0) 这样会相加A和B并用0来填充
对于DataFrame其实大同小异:(下面有一些骚操作)
In [55]: rng = np.random.RandomState(42)
In [56]: A = pd.DataFrame(rng.randint(0,20,(2,2)),columns = list('AB'))
In [57]: B = pd.DataFrame(rng.randint(0,10,(3,3)),columns = list('BAC'))
In [58]: A
Out[58]:
A B
0 6 19
1 14 10
In [59]: B
Out[59]:
B A C
0 7 4 6
1 9 2 6
2 7 4 3
In [60]: A+B
Out[60]:
A B C
0 10.0 26.0 NaN
1 16.0 19.0 NaN
2 NaN NaN NaN
#如果想要设置fill_value得用A.add(B,fill_value = x)
python运算符 映射 Pandas方法
+ add
- sub
* mul
/ div
// floordiv
% mod
** powDataFrame和Series的混合运算
In [66]: df
Out[66]:
Q R S T
0 7 7 2 5
1 4 1 7 5
2 1 4 0 9
#df.iloc[0]选取的是第一列,有点类似广播,默认是按行计算!
In [67]: df - df.iloc[0]
Out[67]:
Q R S T
0 0 0 0 0
1 -3 -6 5 0
2 -6 -3 -2 4
#按列计算就得调一下轴
In [68]: df.sub(df['R'],axis = 0)
Out[68]:
Q R S T
0 0 0 -5 -2
1 3 0 6 4
2 -3 0 -4 5
#否则结果会很坑爹
In [72]: df - df['R']
Out[72]:
Q R S T 0 1 2
0 NaN NaN NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN NaN
#值得注意的是在二元运算中缺失的直接判定为NaN而不是不进行操作
#还是得注意“按行操作”的含义。Series翻转成水平后的标签是否为dataframe的columns的子集
In [70]: halfrow
Out[70]:
Q 7
S 2
Name: 0, dtype: int32
In [71]: df - halfrow
Out[71]:
Q R S T
0 0.0 NaN 0.0 NaN
1 -3.0 NaN 5.0 NaN
2 -6.0 NaN -2.0 NaN处理缺失值
缺失值
缺失值的问题十分普遍,处理不同数据源缺失值的方法不同
本节介绍一些处理缺失值的通用规则,Pandas对缺失值的表现形式,并演示Pandas自带的几个处理缺失值的工具
本书涉及的缺失值主要有三种形式:null 、NaN、 NA
不愧是作者,列举了他在创建pandas时对于这个问题的看法,最终他选择了用标签方法表示缺失值
这包括两种python原有的缺失值:浮点数据的NaN值,还有None对象
当然,Numpy支持掩码数据,Pandas也集成了这个功能,但由于存储、维护的资源浪费,并不可取
P106
None
这是一个Python单体对象,不能作为任何Numpy/Pandas数组类型的缺失值,只能用于’object’数组类型
即由python对象构成的数组,dtype = object 就是这个意思。
这样的类型对数据的任何操作最终都会在python层面完成,进行常见快速操作时会消耗更多资源。
同时,python没有定义整数与None之间的加减运算,Sum和min()这些都会出错。
NaN
这是一种按照IEEE浮点数标准设计,在任何系统中都兼容的特殊浮点数。
In [75]: vals1 = np.array([1,None,3,4])
In [76]: vals1
Out[76]: array([1, None, 3, 4], dtype=object)
In [77]: vals2 = np.array([1,np.nan,3,4])
In [79]: vals2.dtype
Out[79]: dtype('float64')#Numpy会自动为这个数组选择一个原生浮点类型,这意味着与object不同,该数组会被编译成C代码从而实现快速操作而且NaN无论进行何种操作,结果都是NaN,跟病毒一样。
但还记得Numpy提供了一些特殊的累计函数来规避NaN,np.nansum(vals2) == 8
NA
Pandas把NaN和None看作是可以等价交换的
Pandas会将没有标签的数据类型自动转换为NA,规则见P109
| 类型 | 存在缺失值时转换 | NA标签值 |
|---|---|---|
| float | 无变化 | np.nan |
| object | 无变化 | np.nan或None |
| integer | 强制转换为float64 | np.nan |
| boolean | 强制转换为object | np.nan或None |
*Pandas中字符串类型的数据通常是用object类型存储的
处理
发现缺失值
isnull 和notnull 会返回布尔类型的掩码数组,以此可以直接用作索引
剔除缺失值
dropna
这两个操作在Series里没有什么问题
但在DataFrame中就需要注意,并没有办法单独剔除一个值,只能剔除缺失值所在整行或整列
dropna默认剔除整行(因为数据按行为一条),如果加参数df.dropna(axis = 1)或者axis = ‘columns’那就是整列,或者是“1”,但是有点诡异。
可以用how或参数设置阈值,默认是how =’any’,可以是all(必须整行、列都是缺失值才剔除)
thresh参数可以设置非缺失值的最小数量,thresh = 3则正常数据<3的行、列被剔除。
填充缺失值
fillna返回填充了缺失值后的数组副本
参数可以选择method = ‘ffill/bfill’ 用缺失值前/后的有效值来依次填充,也可以改axis来左右填充。
但是如果前面一直找不到有效值填充,那就还是缺失值。。。
层级索引
当我们遇到存储多维数据需求时,数据索引超过一两个键。
Pandas提供了Panel和Panel4D对象解决三维数据和四维数据。
这两种对象采用密集存储,在维度增加的情况下效率越来越低,作者更推荐层级索引
但更直观的形式是hierarchical indexing,层级索引,配合多个不同等级的以及索引一起用,将高维数组转换成类似一维和二维对象的形式。
P114有解释层级索引便利性的例子
创建层级索引
#最直接的方法是将index的参数设置为至少二维的索引数组
In [4]: df = pd.DataFrame(np.random.rand(4,2),index = [['a','a','b','b'],['1','2','1','2']],columns =['data1','data2'])
In [5]: df
Out[5]:
data1 data2
a 1 0.290846 0.466652
2 0.245400 0.860682
b 1 0.697193 0.100121
2 0.028793 0.633941
#输出按照index顺序来,但是如果重复就会自动少显示,所以要手动确认哪个在前合适。
In [10]: df.index
Out[10]:
MultiIndex([('a', '1'),
('a', '2'),
('b', '1'),
('b', '2')],
)
#index的类型变为了MultiIndex
#第二种方法是把元组作为键的字典传递给Pandas
In [11]: data = {('a',2000):32432,
...: ('a',2010):312312,
...: ('b',2000):3241332,
...: ('b',2010):3243252,
...: ('c',2000):32434532,
...: ('c',2010):3223432}
In [12]: pd.Series(data)
Out[12]:
a 2000 32432
2010 312312
b 2000 3241332
2010 3243252
c 2000 32434532
2010 3223432
dtype: int64unstack可以把一个多级索引的Series转化为DataFrame,而stack相反(用level来选择处理的层数)不过注意,unstack和stack默认竟然是后面那层,可以用level = 0 来选第一层。
注意DataFrame是用于二维的。
#显式创建MultiIndex也是很有用的#可以用不同等级的数组来创建In [17]: pd.MultiIndex.from_arrays([['a','a','b','b'],[1,2,1,2]])#可以用包含不同等级索引值的元组构成的列表来创建In [18]: pd.MultiIndex.from_tuples([('a',1),('a',2),('b',1),('b',2)])#可以用两个索引序列的笛卡尔积来创建(这个逻辑上妙一点)In [19]: pd.MultiIndex.from_product([['a','b'],[1,2]])#原有的levels和labels属性好像被删掉了?#可以加名字来方便管理In [29]: bOut[29]:a 2000 32432 2010 312312b 2000 3241332 2010 3243252c 2000 32434532 2010 3223432dtype: int64In [30]: b.index.names = ['owner','year']In [31]: bOut[31]:owner yeara 2000 32432 2010 312312b 2000 3241332 2010 3243252c 2000 32434532 2010 3223432dtype: int64#多级列索引
In [32]: index = pd.MultiIndex.from_product([[2013,2014],[1,2]],names = ['year','visit_time'])
In [33]: columns = pd.MultiIndex.from_product([['Bob','Darren','Jack'],['HR','Temp']],names = ['name','type'])
In [34]: data = np.round(np.random.randn(4,6),1)#round是保留小数位,此处为1
In [35]: data
Out[35]:
array([[-0.7, -0. , -0.8, -0.9, -0. , 2.4],
[-2.1, 0.5, 1.6, 0.2, -1.3, -0.4],
[ 0.4, -1.3, 0.6, -0.5, 2.4, 0.9],
[-0.1, 2.2, 0.1, 0.9, -0.9, -1.4]])
In [36]: data[:,::2]*=10
In [37]: data+=37
In [38]: health_data = pd.DataFrame(data,index = index,columns = columns)
In [39]: health_data
Out[39]:
name Bob Darren Jack
type HR Temp HR Temp HR Temp
year visit_time
2013 1 30.0 37.0 29.0 36.1 37.0 39.4
2 16.0 37.5 53.0 37.2 24.0 36.6
2014 1 41.0 35.7 43.0 36.5 61.0 37.9
2 36.0 39.2 38.0 37.9 28.0 35.6
columns名字 多级columns
index名字 内容
多级index 内容多级索引取值、切片
#Series
In [18]: one
Out[18]:
year visit_time
2013 1 53.0
2 35.3
2014 1 34.0
2 36.9
dtype: float64
#可以通过指定所有级别的索引值来获取单个元素
In [19]: one[2013,1]
Out[19]: 53.0
#也可以“局部取值”,取出来还是Series,不过貌似必须得从前到后
In [20]: one[2013]
Out[20]:
visit_time
1 53.0
2 35.3
dtype: float64
#切片类似
In [22]: one.loc[2013:2014]
Out[22]:
year visit_time
2013 1 53.0
2 35.3
2014 1 34.0
2 36.9
dtype: float64
#巧妙
In [24]: one.loc[:,2]
Out[24]:
year
2013 35.3
2014 36.9
dtype: float64
#布尔和花哨的使用方法类似,并无太大变化#DateFrame
单独取是列索引,类似Series
In [30]: health_data
Out[30]:
name Bob Darren Jack
type HR Temp HR Temp HR Temp
year visit_time
2013 1 53.0 35.3 34.0 36.9 37.0 37.0
2 20.0 35.8 47.0 37.2 42.0 37.0
2014 1 36.0 36.3 44.0 37.7 35.0 37.4
2 28.0 37.4 32.0 33.7 40.0 38.0
#对索引器来说,他们还是按照先行后列来操作,而且在loc和iloc中可以传递多个层级的索引元组,👇先取所有行,再对列进行层级索引,但在元组中使用切片会导致语法错误(不能确定范围),不是很方便
In [29]: health_data.loc[:,('Darren','Temp')]
Out[29]:
year visit_time
2013 1 36.9
2 37.2
2014 1 37.7
2 33.7
Name: (Darren, Temp), dtype: float64
#更好的方法时使用IndexSlice对象而不是python自带的slice函数,这样可以在内部使用切片
In [37]: health_data.loc[idx[2013,2],idx['Darren',:]]
Out[37]:
name type
Darren HR 47.0
Temp 37.2
Name: (2013, 2), dtype: float64
#ps:不要忘记使用loc,不然会报错而且错误贼长多级索引行列转换
局部切片和其他很多类似操作都要求MultiIndex的各级索引是有序的,否则大部分操作都会失败。
可以用data = data.sort_index() 或者data.sortlevel()来搞定
sort_index有个参数ascending True代表升序
In [21]: pop
Out[21]:California 2000 3234234 2010 324322NewYork 2000 6434634 2010 52364Texas 2000 67573 2010 43525dtype: int32 #level设置转换的层数In [22]: stack = pop.unstack(level = 0)In [23]: stackOut[23]: California NewYork Texas2000 3234234 6434634 675732010 324322 52364 43525In [24]: stack2 = pop.unstack(level = 1)In [25]: stack2Out[25]: 2000 2010California 3234234 324322NewYork 6434634 52364Texas 67573 43525In [26]: stack2.stack()Out[26]:California 2000 3234234 2010 324322NewYork 2000 6434634 2010 52364Texas 2000 67573 2010 43525dtype: int32在实践中处理数据集非常好用的方法:
行列标签转换
#reset_index可以生成一个DataFrame,之前的行索引将变成内容,行名变列名,可以指定name来设置原来内容的列名称
In [29]: pop.index.names = ['state','year']
In [30]: pop.reset_index(name = 'population')
Out[30]:
state year population
0 California 2000 3234234
1 California 2010 324322
2 NewYork 2000 6434634
3 NewYork 2010 52364
4 Texas 2000 67573
5 Texas 2010 43525
#反过来,也可以这样,将其中的几列变为行索引
In [32]: a = pop.reset_index(name = 'population')
In [33]: a.set_index(['state','year'])
Out[33]:
population
state year
California 2000 3234234
2010 324322
NewYork 2000 6434634
2010 52364
Texas 2000 67573
2010 43525多级索引数据累计
数据累计方法,如mean()、sum()、max()之类的,其实就是结合level参数,level取的是index的名字,表明保留该列、行,其他合并,通过axis表明沿行、列
In [42]: a = pop.mean(level = 'state')
In [43]: a
Out[43]:
state
California 1779278
NewYork 3243499
Texas 55549
dtype: int32合并数据集
这是非常有趣的事情,既包括简单拼接,也包括处理重叠片段,pandas提供了高效的函数
concat 和 append
In [75]: x = [1,2,3]
In [76]: np.concatenate([x,x,x])
Out[76]: array([1, 2, 3, 1, 2, 3, 1, 2, 3])
In [77]: np.concatenate([x,x,x],axis = 1)
---------------------------------------------------------------------------
AxisError Traceback (most recent call last)
<ipython-input-77-cdd90a57a401> in <module>
----> 1 np.concatenate([x,x,x],axis = 1)
<__array_function__ internals> in concatenate(*args, **kwargs)
AxisError: axis 1 is out of bounds for array of dimension 1
#对于一维数组的concatenate好像是个特例。
#pd.concat与np.concatenate语法类似,参数更多,功能更强
DataFrame默认逐行合并(axis = 0),可以设置成axis = 'col'/1
差异:
1. 索引重复,合并时保留哪怕是重复的索引
可以设置verify_integrity = True 来引发异常
可以设置igonre_index = True 会无视原有的索引,直接新建一个0,1,2.。。
可以设置keys = [xxxx],keys会作为数据源的索引,就是高一层的多级索引。
2. 合并
join = 'outer'取并集(默认),会出现NAN, inner 取交集
join_axes = [[xxx,xx]],直接确定结果使用的列名。
append语法方便:df1.append(df2),和pd.concat()效果一样
但是不像原生的append可以直接更新原有对象,而是新建,所以效率不高,不如建立DF列表然后一次性concatmerge(合并) and join(连接)
高性能的内存式数据连接是Pandas的卖点之一。
关系代数是处理关系型数据的通用理论,绝大部分数据库的可用操作都以此为理论基础。
关系代数方法论的强大之处在于,它提出的若干简单操作规则经过组合就可以为任意数据集构建十分复杂的操作。Pandas 在 pd.merge() 函数与 Series 和 DataFrame 的 join() 方法里实现了这些基本操作规则。
合并与链接
pd.merge() 函数实现了三种数据连接的类型:一对一、多对一和多对多。
一对一就是一对一呗。。merge至少要有一列是一样的
多对一连接是指,在需要连接的两个列中,有一列的值有重复。通过多对一连接获得的结果 DataFrame 将会保留重复值。
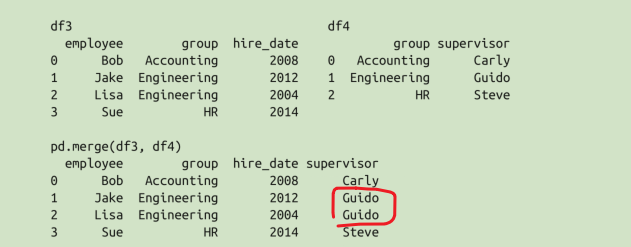
在结果 DataFrame 中多了一个“supervisor”列,里面有些值会因为输入数据的对应关系而有所重复
多对多连接是个有点儿复杂的概念,不过也可以理解。如果左右两个输入的共同列都包含重复值,那么合并的结果就是一种多对多连接。来看下面的例子,里面有一个 DataFrame 显示不同岗位人员的一种或多种能力。

真实数据集往往没有那么干净、整洁,下面介绍merge的一些功能。
数据合并参数
on = ‘列名’ 两边都有的
left_on = ‘’ right_on = ‘’ 分别指定左右的共同列作为键进行合并
获取的结果中会有一个多余的列,可以通过 DataFrame 的 drop() 方法将这列去掉:
pd.merge(df1, df3, left_on="employee", right_on="name").drop('name', axis=1)(drop的1是列)
除了合并列,你也可以把索引作为键来合并
left_index 和 right_index = True
也可以混合使用,print(pd.merge(df1a, df3, left_index=True, right_on='name'))
当然,这些参数都适用于多个索引和 / 或多个列名,函数接口非常简单,点我
当一个值出现在一列,却没有出现在另一列时,就需要考虑集合操作规则了。
默认outer 还有inner left right 表示行保留哪一边输入列的值

重复列名
由于输出结果中有两个重复的列名(这一列没有作为合并的键,所以多了一列),因此 pd.merge() 函数会自动为它们增加后缀 _x 或 _y
可以通过 suffixes 参数自定义后缀名:pd.merge(df8, df9, on=”name”, suffixes=[“_L”, “_R”])
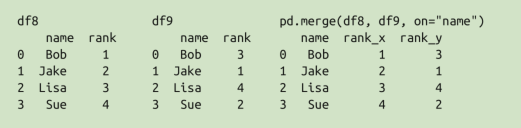
3.8的例子太秀了,好好看看
pd.any()它会检查每一列,然后用 列名 True/False 的格式一行一行打印出来

pd.unique() 返回独一无二的。。就是集合嘛
pd.read_csv(‘xxxx.csv’) 通过csv文件生成DataFrame
pd.head() 查看前五行,tail查看后五行

有点巧妙,行索引筛选哪些行的数据,列索引筛选state,然后unique一下,然后处理👇
merged.loc[merged[‘state/region’] == ‘PR’, ‘state’] = ‘Puerto Rico’
merged.loc[merged[‘state/region’] == ‘USA’, ‘state’] = ‘United States’
最巧妙的是随心所欲的操控数据,通过布尔索引和选出某列的某部分当新索引,完成神奇的工作。
pandas 中 inplace 参数 在很多函数 中 都会有,inplace = True:不创建新的对象,直接对原始对象进行修改;
累计与分组
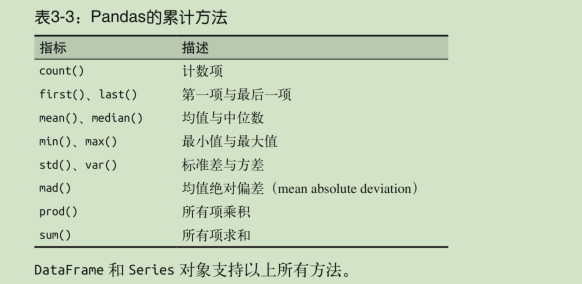
在对较大的数据进行分析时,一项基本的工作就是有效的数据累计(summarization):计算累计(aggregation)指标,如 sum() 、 mean() 、 median() 、 min() 和 max()
有一个非常方便的 describe() 方法可以计算每一列的若干常用统计值。让我们在行星数据上试验一下,首先丢弃有缺失值的行:
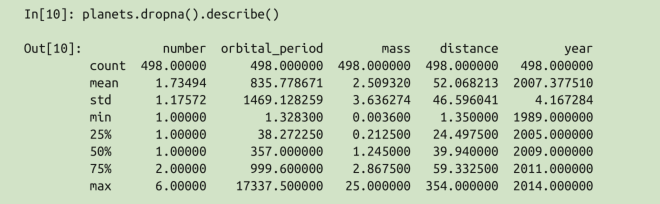
但若想深入理解数据,仅仅依靠累计函数是远远不够的。数据累计的下一级别是 groupby操作,它可以让你 快速、有效地计算数据各子集的累计值。
GroupBy:分割、应用和组合
简单的累计方法可以让我们对数据集有一个笼统的认识,但是我们经常还需要对某些标签或索引的局部进行累计分析
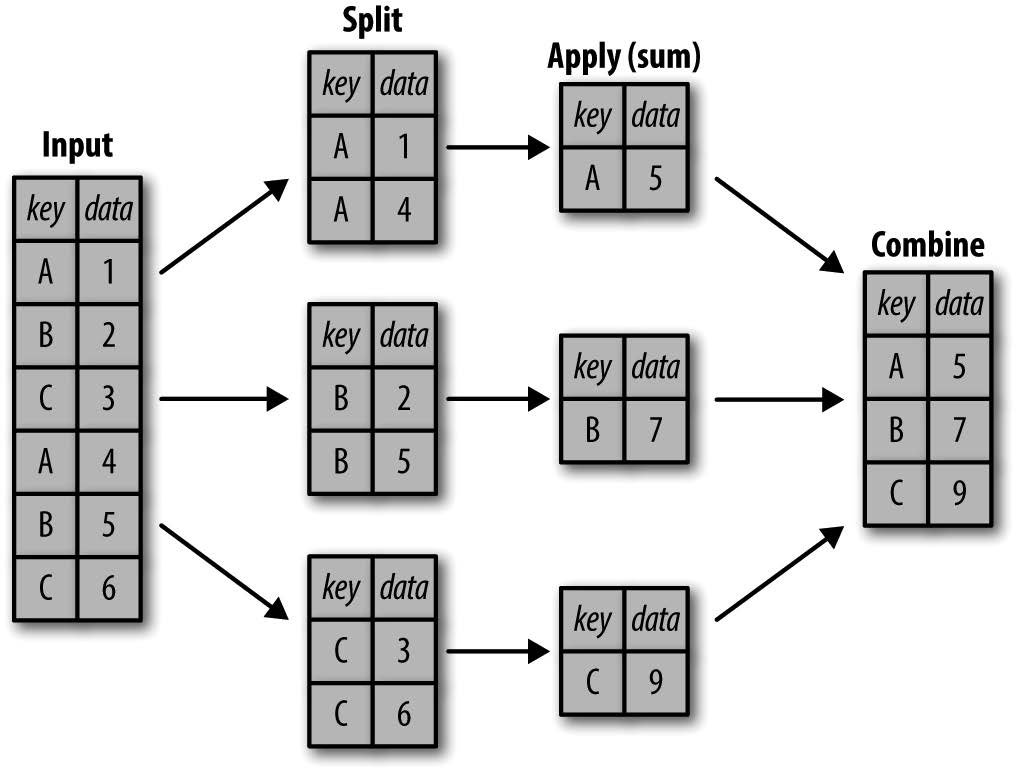
• 分割步骤将 DataFrame 按照指定的键分割成若干组。
• 应用步骤对每个组应用函数,通常是累计、转换或过滤函数。
• 组合步骤将每一组的结果合并成一个输出数组。
虽然我们也可以通过前面介绍的一系列的掩码、累计与合并操作来实现,但是意识到中间分割过程不需要显式地暴露出来这一点十分重要。而且 GroupBy (经常)只需要一行代码,就可以计算每组的和、均值、计数、最小值以及其他累计值。 GroupBy 的用处就是将这些步骤进行抽象:在底层解决所有难题,用户不需要知道在底层如何计算,只要把操作看成一个整体就够了。
延迟计算:
groupby的返回值是一个 DataFrameGroupBy 对象。你可以将它看成是一种特殊形式的 DataFrame ,里面隐藏着若干组数据,但是在没有应用累计函数之前不会计算。
In [7]: df
Out[7]:
key data
0 A 0
1 B 1
2 C 2
3 A 3
4 B 4
5 C 5
In [8]: df.groupby('key')
Out[8]: <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000022CD3E6B088>
In [9]: df.groupby('key').sum()
Out[9]:
data
key
A 3
B 5
C 7基本方法
支持按列取值,取出的对象叫SeriesGroupBy,也支持延迟计算
支持按组迭代,返回的每一组都是 Series 或 DataFrame
👇method取出的是索引,group取出的是DataFrame或Series

- 调用方法,让任何不由GroupBy对象直接实现的方法直接应用到每一组。👇这是因为Python类的魔力,继承。
In [14]: df.groupby('key').sum()
Out[14]:
data
key
A 3
B 5
C 7
In [15]: df.groupby('key').describe()#这个方法本来是pd的,但是直接用在pdGrouoby上了
Out[15]:
data
count mean std min 25% 50% 75% max
key
A 2.0 1.5 2.12132 0.0 0.75 1.5 2.25 3.0
B 2.0 2.5 2.12132 1.0 1.75 2.5 3.25 4.0
C 2.0 3.5 2.12132 2.0 2.75 3.5 4.25 5.0
#unstack()是将列索引转换为行索引(成列的转换为成行的?)
#但是注意,默认是准换到靠近数据的那一层。
#而且如果没有行索引了,会自动颠倒,就像下面这个一样。
In [16]: df.groupby('key').describe().unstack()
Out[16]:
key
data count A 2.00000
B 2.00000
C 2.00000
mean A 1.50000
B 2.50000
C 3.50000
std A 2.12132
B 2.12132
C 2.12132
min A 0.00000
B 1.00000
C 2.00000
25% A 0.75000
B 1.75000
C 2.75000
50% A 1.50000
B 2.50000
C 3.50000
75% A 2.25000
B 3.25000
C 4.25000
max A 3.00000
B 4.00000
C 5.00000
dtype: float64中间操作
累计
In [28]: df
Out[28]:
key data1 data2
0 A 0 3
1 B 1 9
2 C 2 8
3 A 3 8
4 B 4 5
5 C 5 4
In [29]: df.groupby('key').aggregate(['min', np.median, max])
Out[29]:
data1 data2
min median max min median max
key
A 0 1.5 3 3 5.5 8
B 1 2.5 4 5 7.0 9
C 2 3.5 5 4 6.0 8
#支持字符串、函数或函数列表
#也可以通过python字典指定不同列需要的函数
In [31]: df.groupby('key').aggregate({'data1': ['min',np.median],^M
...: 'data2': 'max'})
Out[31]:
data1 data2
min median max
key
A 0 1.5 8
B 1 2.5 9
C 2 3.5 8过滤
过滤操作可以让你按照分组的属性丢弃若干数据。例如,我们可能只需要保留标准差超过某个阈值的组
def filter_func(x):
return x['data2'].std() > 4
df.groupby('key').filter(filter_func)转换
累计操作返回的是对组内全量数据缩减过的结果,而转换操作会返回一个新的全量数据。数据经过转换之后,其形状与原来的输入数据是一样的,而
In [35]: df.groupby('key').transform(lambda x: x - x.mean())
Out[35]:
data1 data2
0 -1.5 -2.5
1 -1.5 2.0
2 -1.5 2.0
3 1.5 2.5
4 1.5 -2.0
5 1.5 -2.0
#注意key那个标签没了apply()方法
apply() 方法让你可以在每个组上应用任意方法。这个函数输入一个DataFrame ,返回一个 Pandas 对象( DataFrame 或 Series )或一个标量(scalar,单个数值)。组合操作会适应返回结果类型。

分组方法
前面的简单例子一直在用列名分割 DataFrame 。这只是众多分组操作中的一种,下面将继续介绍更多的分组方法。
将列表、数组、Series 或索引作为分组键(长度与 DataFrame 匹配)

这个就是用索引
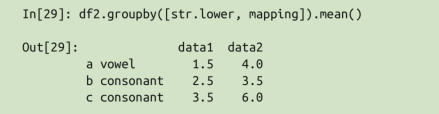
用字典或 Series 将索引映射到分组名称
In [7]: df2 Out[7]: data1 data2 key A 0 5 B 1 0 C 2 3 A 3 3 B 4 7 C 5 9 In [8]: mapping Out[8]: {'A': 'vowel', 'B': 'consonant', 'C': 'consonant'} In [9]: pd.Series(mapping)#索引指代被操作的对象的分组依据。 Out[9]: A vowel B consonant C consonant dtype: object #这里的映射后后面的哪个aggfunc不太一样 In [10]: df2.groupby(mapping).sum() Out[10]: data1 data2 consonant 12 19 vowel 3 8 In [11]: df2.groupby(pd.Series(mapping)).sum() Out[11]: data1 data2 consonant 12 19 vowel 3 8任意 Python 函数。你可以将任意 Python 函数传入 groupby ,函数映射到索引,然后新的分组输出

我才发现,str list这些原来是顶层对象,也有一般实例的方法,比如list.append是存在的。
此外,任意之前有效的键都可以组合起来进行分组,从而返回一个多级索引的分组结果
而且好像是按列表順序組合多級索引的。
mapping = {‘A’: ‘vowel’, ‘B’: ‘consonant’, ‘C’: ‘consonant’}
pd.astype(str) #强制转换数据类型。
数据透视表
我们已经介绍过 GroupBy 抽象类是如何探索数据集内部的关联性的了。
数据透视表(pivot table)是一种类似的操作方法,常见于 Excel 与类似的表格应用中。
数据透视表更像是一种多维的 GroupBy 累计操作。也就是说,虽然你也可以分割 - 应用 - 组合,但是分割与组合不是发生在一维索引上,而是在二维网格上(行列同时分组)。
import seaborn as sns
titanic = sns.load_dataset(‘titanic’) #翻墙可以下到
#关于显示的设定
# 显示所有列
pd.set_option('display.max_columns', None)
pd.set_option('display.max_columns', 5) #最多显示5列
# 显示所有行
pd.set_option('display.max_rows', None)
pd.set_option('display.max_rows', 10)#最多显示10行
#显示小数位数
pd.set_option('display.float_format',lambda x: '%.2f'%x) #两位
#显示宽度
pd.set_option('display.width', 100)#这是以前的做法,不过注意,分组的时候是不是列表也会有影响。
titanic.groupby('sex')['survived'].mean()
Out[12]:
sex
female 0.742038
male 0.188908
Name: survived, dtype: float64
titanic.groupby('sex')[['survived']].mean()
Out[13]:
survived
sex
female 0.742038
male 0.188908虽然这样就可以更清晰地观察乘客性别、船舱等级对其是否生还的影响,但是代码看上去有点 复杂。尽管这个管道命令的每一步都是前面介绍过的,但是要理解这个长长的语句可不是那么容易的事,这个适合就到数据透视表出场的时候了。
语法
titanic.groupby(['sex', 'class'])['survived'].aggregate('mean').unstack()
#还是强调一点就是unstack他首先解压的是最后面的那一列,也就是这里的‘class’
Out[21]:
class First Second Third
sex
female 0.968085 0.921053 0.500000
male 0.368852 0.157407 0.135447
#对比一下
titanic.pivot_table('survived',index = 'sex',columns = 'class')
Out[20]:
class First Second Third
sex
female 0.968085 0.921053 0.500000
male 0.368852 0.157407 0.135447这行代码可读性更强,而且取得的结果也一样。
多级数据透视表
这里面有一个cut函数,可以将数据分段并用相应的数据段来替代,不过左开右闭。
age = pd.cut(titanic['age'], [0, 18, 80])
age
Out[27]:
0 (18.0, 80.0]
1 (18.0, 80.0]
2 (18.0, 80.0]
3 (18.0, 80.0]
4 (18.0, 80.0]
...
886 (18.0, 80.0]
887 (18.0, 80.0]
888 NaN
889 (18.0, 80.0]
890 (18.0, 80.0]
Name: age, Length: 891, dtype: category
Categories (2, interval[int64]): [(0, 18] < (18, 80]]
#然后就可以
titanic.pivot_table('survived', ['sex', age], 'class')
Out[28]:
class First Second Third
sex age
female (0, 18] 0.909091 1.000000 0.511628
(18, 80] 0.972973 0.900000 0.423729
male (0, 18] 0.800000 0.600000 0.215686
(18, 80] 0.375000 0.071429 0.133663
#这里可以猜出来,第一个选的是数据,第二个是索引,第三个就是列。
#但是这里自动求了个平均(后面讲)
#这里又引出另一个分箱函数,按照分位数(默认等于2)来进行分箱
fare = pd.qcut(titanic['fare'], 2)
fare
Out[39]:
0 (-0.001, 14.454]
1 (14.454, 512.329]
2 (-0.001, 14.454]
3 (14.454, 512.329]
4 (-0.001, 14.454]
...
886 (-0.001, 14.454]
887 (14.454, 512.329]
888 (14.454, 512.329]
889 (14.454, 512.329]
890 (-0.001, 14.454]
Name: fare, Length: 891, dtype: category
Categories (2, interval[float64]): [(-0.001, 14.454] < (14.454, 512.329]]
#感觉这个函数比前面那个groupby清楚啊
pd.set_option('display.max_columns',5)
titanic.pivot_table('survived', ['sex', age], [fare, 'class'])
Out[44]:
fare (-0.001, 14.454] ... (14.454, 512.329]
class First Second ... Second Third
sex age ...
female (0, 18] NaN 1.000000 ... 1.000000 0.318182
(18, 80] NaN 0.880000 ... 0.914286 0.391304
male (0, 18] NaN 0.000000 ... 0.818182 0.178571
(18, 80] 0.0 0.098039 ... 0.030303 0.192308
[4 rows x 6 columns]
#结果是一个四位索引。其他的一些选项
fill_value 和 dropna 这两个参数用于处理缺失值,用法很简单,我们将在后面的示例中演示其用法。
aggfunc 参数用于设置累计函数类型,默认值是均值( mean ),可以用一些常见的字符串( ‘sum’ 、 ‘mean’ 、 ‘count’ 、 ‘min’ 、 ‘max’ 等)表示,也可以用标准的累计函数( np.sum() 、 min() 、 sum() 等)表示。
也可以用字典为不同的列指定不同的累计函数,函数列表。
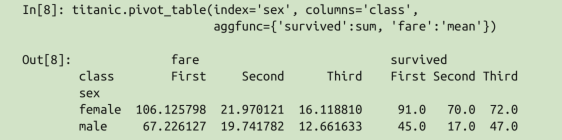
这个函数和groupby的分组不太一样。但是思想类似。
不过上面的是以索引形式,这个是更高level的columns。
这里忽略了一个参数 values 。当我们为 aggfunc 指定映射关系的时候,待透视的数值就已经确定了。
margins

margin 的标签可以通过 margins_name 参数进行自定义,默认值是 “All“ 。
3.10.4 美国人口
使用%matplotlib后,可以直接在生成的pivot_table后加.plot()来生成图表!!

到时候回来再看看吧。。
向量化字符串操作
使用 Python 的一个优势就是字符串处理起来比较容易。在此基础上创建的 Pandas 同样提供了一系列 向量化字符串操作(vectorized string operation),它们都是在处理(清洗)现实工作中的数据时不可或缺的功能
假如数据中出现了缺失值,那么很多时候就会引起异常
Pandas 为包含字符串的 Series 和 Index 对象提供的 str 属性 堪称两全其美的方法,它既
可以满足向量化字符串操作的需求,又可以正确地处理缺失值。例如:
names
Out[24]:
0 peter
1 Paul
2 None
3 MARY
4 gUIDO
dtype: object
names.str.capitalize()
Out[23]:
0 Peter
1 Paul
2 None
3 Mary
4 Guido
dtype: object
#None这个缺失值被跳过了字符串方法
包括了python,re模块,和自带的方法

但是有些方法返回数值,比如len
有些方法返回布尔值,比如startwith
还有些方法返回列表或其他复合值
在接下来的内容中,我们将进一步学习这类由列表元素构成的 Series (series-of-lists)对象。
正则化方法
更好的是,str同样支持一些正则化方法,采用re模块的语法,太方便了

里面参数就填正则化式子(字符串)

其他字符串方法

取值、切片
slice取的是字符,比如df.str.slice(0,3)取的是前三个字符。等价于df.str[0:3]
df.str.get(i) 与 df.str[i] 的按索引取值效果类似
get() 与 slice() 操作还可以在 split() 操作之后使用。例如,要获取每个姓名的姓
(last name),可以结合使用 split() 与 get() :
monte
Out[30]:
0 Graham Chapman
1 John Cleese
2 Terry Gilliam
3 Eric Idle
4 Terry Jones
5 Michael Palin
dtype: object
monte.str.split().str.get(-1)
Out[31]:
0 Chapman
1 Cleese
2 Gilliam
3 Idle
4 Jones
5 Palin
dtype: object指标变量
另一个需要多花点儿时间解释的是 get_dummies() 方法。当你的数据有一列包含了若干已被编码的指标(coded indicator)时,这个方法就能派上用场了。(转换成独热码)
假设有一个包含了某种编码信息的数据集,如 A= 出生在美国、B= 出生在英国、C= 喜欢奶酪、D= 喜欢午餐肉:
full_monte
Out[33]:
name info
0 Graham Chapman B|C|D
1 John Cleese B|D
2 Terry Gilliam A|C
3 Eric Idle B|D
4 Terry Jones B|C
5 Michael Palin B|C|D
full_monte['info'].str.get_dummies('|') #选择分隔符
Out[34]:
A B C D
0 0 1 1 1
1 0 1 0 1
2 1 0 1 0
3 0 1 0 1
4 0 1 1 0
5 0 1 1 13.11.3案例
recipe的每个元素的结构:
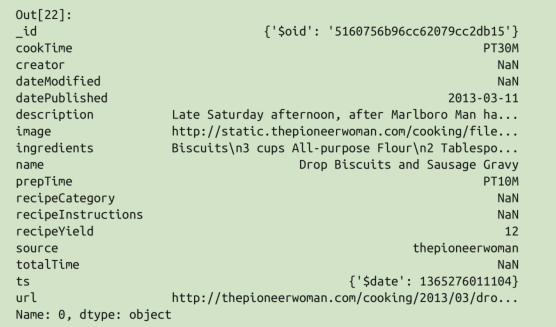
recipes.ingredients.str.len().describe() 看看菜单食材的名字长度
recipes.name[np.argmax(recipes.ingredients.str.len())]看看这个拥有最长食材列表的究竟是哪道菜
``recipes.description.str.contains(‘[Bb]reakfast’).sum()` 看看哪些食谱是早餐。
#以后再看吧,太难了
处理时间序列
Pandas 最初是为金融模型而创建的,因此它拥有一些功能非常强大的日期、时间、带时间索引数据的处理工具
时间戳表示某个具体的时间点(例如 2015 年 7 月 4 日上午 7 点)。
时间间隔与周期表示开始时间点与结束时间点之间的时间长度,例如 2015 年(指的是
2015 年 1 月 1 日至 2015 年 12 月 31 日这段时间间隔)。周期通常是指一种特殊形式的时间间隔,每个间隔长度相同,彼此之间不会重叠(例如,以 24 小时为周期构成每一天)。
时间增量(time delta)或持续时间(duration)表示精确的时间长度(例如,某程序运行持续时间 22.56 秒)
python原生工具
在开始介绍 Pandas 的时间序列工具之前,我们先简单介绍一下 Python 处理日期与时间数据的工具。
尽管 Pandas 提供的时间序列工具更适合用来处理数据科学问题,但是了解 Pandas 与 Python 标准库以及第三方库中的其他时间序列工具之间的关联性将大有裨益。
- datatime 和 dateutil
from datetime import datetime
datetime(year=2015, month=7, day=4)
Out[51]: datetime.datetime(2015, 7, 4, 0, 0)
datetime(2015,7,4,12,00)
Out[52]: datetime.datetime(2015, 7, 4, 12, 0)
#可以利用dateutil对字符串格式的日期进行正确解析
from dateutil import parser
date = parser.parse("4th of July, 2015")
date
Out[53]: datetime.datetime(2015, 7, 4, 0, 0)Python 的 datetime 文档(https://docs.python.org/3/library/datetime.html)
dateutil 的其他日期功能可以通过在线文档(http://labix.org/python-dateutil)学习
pytz (http://pytz.sourceforge.net/),这个工具解决了绝大多数时间序列数据都会遇到的难题:**时区**
datetime 和 dateutil 模块在灵活性与易用性方面都表现出色,数量大时,速度就会比较慢。
- 基于NumPy的datetime64类型(Numerical Python)
datetime64 类型将日期编码为 64 位整数,这样可以让日期数组非常紧凑(节省内存)。
datetime64 需要在设置日期时确定具体的输入类型。
因为 NumPy 的 datetime64 数组内元素的类型是统一的,所以这种数组的运算速度会比Python 的 datetime 对象的运算速度快很多(向量化计算)
NumPy 的 datetime64 文档(http://docs.scipy.org/doc/numpy/reference/arrays.datetime.html)总结了所有支持相对与绝对时间跨度的时间与日期单位格式代码
datetime64内的位数是固定的,追求的精度越高,能表示的精度越高,能表示的范围就越小。
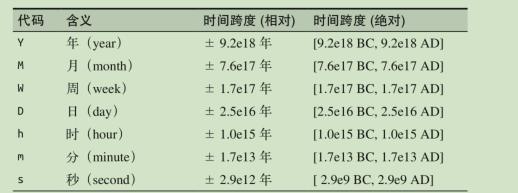
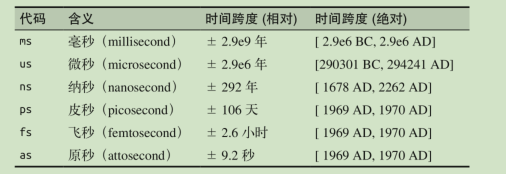
一般工作中用的就是ns,因为用它来表示时间范围精度可以满足绝大部分需求。
虽然 datetime64 弥补了 Python 原生的 datetime 类型的不足,但它缺少了许多 datetime (尤其是 dateutil )原本具备的便捷方法与函数
- Pandas的日期与时间工具:理想与现实的最佳解决方案
Pandas 所有关于日期与时间的处理方法全部都是通过 Timestamp 对象实现的。
它利用numpy.datetime64 的有效存储和向量化接口将 datetime 和 dateutil 的易用性有机结合起来。
Pandas 通过一组 Timestamp 对象就可以创建一个可以作为 Series 或 DataFrame 索引的DatetimeIndex,既有向量化的高效,又可以灵活的处理数据。
数据结构
Pandas 时间序列工具非常适合用来处理带时间戳的索引数据,支持切片,取值等。
index = pd.DatetimeIndex(['2014-07-04', '2014-08-04',
'2015-07-04', '2015-08-04'])
data = pd.Series([0, 1, 2, 3], index=index)
data
Out[56]:
2014-07-04 0
2014-08-04 1
2015-07-04 2
2015-08-04 3
dtype: int64
data['2014-07-04':'2015-07-04']
Out[57]:
2014-07-04 0
2014-08-04 1
2015-07-04 2
dtype: int64
data['2015']
Out[58]:
2015-07-04 2
2015-08-04 3
dtype: int64- 时间戳数据—— Timestamp 类型。本质上是Python 的原生 datetime 类型的替代品。对应的索引数据结构是 DatetimeIndex 。
- 时间周期数据—— Period 类型。将固定频率的时间间隔进行编码。对应的索引数据结构是 PeriodIndex 。
- 时间增量或持续时间—— Timedelta 类型代替 Python原生 datetime.timedelta 类型的高性能数据结构。对应的索引数据结构是 TimedeltaIndex 。
以上都基于np.datetime64类型
最基础的日期 / 时间对象是 Timestamp 和 DatetimeIndex 。这两种对象可以直接使用
pd.to_datetime() 函数,它可以解析许多日期与时间格式,传递一个日期会返回一个Timestamp 类型,传递一个时间序列会返回一个 DatetimeIndex 类型
from datetime import datetime
dates = pd.to_datetime([datetime(2015, 7, 3), '4th of July, 2015',
'2015-Jul-6', '07-07-2015', '20150708'])
#这个厉害
dates
Out[43]:
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-06', '2015-07-07',
'2015-07-08'],
dtype='datetime64[ns]', freq=None)
# 用带分秒的康康
dates = pd.to_datetime([datetime(2015, 7, 3,18,30), '4th of July, 2015',
'2015-Jul-6', '07-07-2015', '20150708'])
dates
Out[45]:
DatetimeIndex(['2015-07-03 18:30:00', '2015-07-04 00:00:00',
'2015-07-06 00:00:00', '2015-07-07 00:00:00',
'2015-07-08 00:00:00'],
dtype='datetime64[ns]', freq=None)
dates[0]
Out[47]: Timestamp('2015-07-03 18:30:00')
#单个就是TimeStampDatetimeIndex 类型都可以通过 to_period() 方法和一个频率代码转换成 PeriodIndex类型。下面用 ‘D’ 将数据转换成单日的时间序列
dates.to_period('D')
Out[48]:
PeriodIndex(['2015-07-03', '2015-07-04', '2015-07-06', '2015-07-07',
'2015-07-08'],
dtype='period[D]', freq='D')
#我的小时和秒都没了当用一个日期减去另一个日期时,返回的结果是 TimedeltaIndex 类型:
dates - dates[0]
Out[49]:
TimedeltaIndex(['0 days 00:00:00', '0 days 05:30:00', '2 days 05:30:00',
'3 days 05:30:00', '4 days 05:30:00'],
dtype='timedelta64[ns]', freq=None)间隔和频率
为了能更简便地创建有规律的时间序列,Pandas 提供了一些方法: pd.date_range() 可以处理时间戳、 pd.period_range() 可以处理周期、 pd.timedelta_range() 可以处理时间间隔。
pd.date_range('2015-07-03', '2015-07-10')
Out[59]:
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06',
'2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10'],
dtype='datetime64[ns]', freq='D')
#左闭右闭,默认freq是‘D’
pd.date_range('2015-07-03', periods=8)
Out[60]:
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06',
'2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10'],
dtype='datetime64[ns]', freq='D')
#第二种方法
pd.date_range('2015-07-03', periods=8, freq='H')
Out[61]:
DatetimeIndex(['2015-07-03 00:00:00', '2015-07-03 01:00:00',
'2015-07-03 02:00:00', '2015-07-03 03:00:00',
'2015-07-03 04:00:00', '2015-07-03 05:00:00',
'2015-07-03 06:00:00', '2015-07-03 07:00:00'],
dtype='datetime64[ns]', freq='H')
pd.period_range('2015-07', periods=8, freq='M')
Out[62]:
PeriodIndex(['2015-07', '2015-08', '2015-09', '2015-10', '2015-11', '2015-12',
'2016-01', '2016-02'],
dtype='period[M]', freq='M')
pd.timedelta_range(0, periods=10, freq='H')
Out[63]:
TimedeltaIndex(['0 days 00:00:00', '0 days 01:00:00', '0 days 02:00:00',
'0 days 03:00:00', '0 days 04:00:00', '0 days 05:00:00',
'0 days 06:00:00', '0 days 07:00:00', '0 days 08:00:00',
'0 days 09:00:00'],
dtype='timedelta64[ns]', freq='H')掌握 Pandas 频率代码是使用所有这些时间序列创建方法的必要条件。
Pandas 时间序列工具的基础是时间频率或偏移量(offset)代码。我们可以用这些代码设置任意需要的时间间隔。
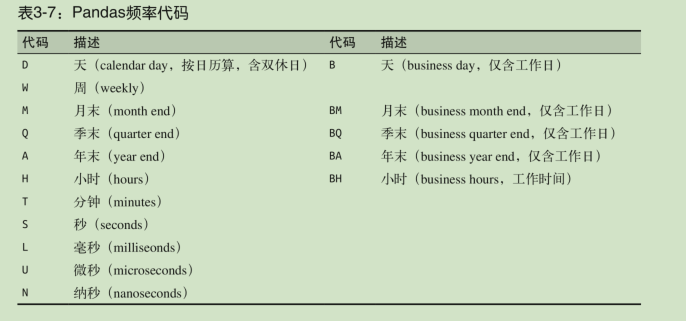
发现有一些是period,有一些是时间戳

在这些代码的基础上,还可以将频率组合起来创建的新的周期
pd.timedelta_range(0, periods=9, freq="2H30T")
Out[64]:
TimedeltaIndex(['0 days 00:00:00', '0 days 02:30:00', '0 days 05:00:00',
'0 days 07:30:00', '0 days 10:00:00', '0 days 12:30:00',
'0 days 15:00:00', '0 days 17:30:00', '0 days 20:00:00'],
dtype='timedelta64[ns]', freq='150T')重新取样、迁移和窗口
用日期和时间直观地组织与获取数据是 Pandas 时间序列工具最重要的功能之一。
Pandas不仅支持普通索引功能(合并数据时自动索引对齐、直观的数据切片和取值方法等),还专为时间序列提供了额外的操作。
由于 Pandas 最初是为金融数据模型服务的,因此可以用它非常方便地获取金融数据。例如, pandas-datareader 程序包知道如何从一些可用的数据源导入金融数据,包含 Yahoo 财经、Google 财经和其他数据源。
- 重新取样与频率转换
处理时间序列数据时,经常需要按照新的频率(更高频率、更低频率)对数据进行重新取样。
你可以通过 resample() 方法解决这个问题,或者用更简单的 asfreq() 方法。
resample() 方法是以数据累计(data aggregation)为基础,而asfreq() 方法是以数据选择(data selection)为基础。
(由于下载数据出了问题,只能截图)原始数据👇
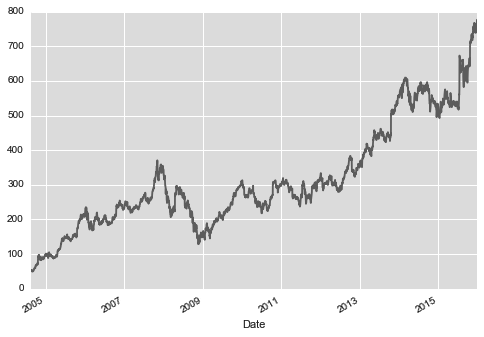
对于收盘价进行可视化结果👇
向后取样,和向前取样大体相同。
goog.resample(‘BA’).mean().plot(style=’:’)
goog.asfreq(‘BA’).plot(style=’–’);
重选频率(BA是每个年末)以后,如图,但是注意取样方式的差异,上一条是平均值,下一条是最后一个工作日。
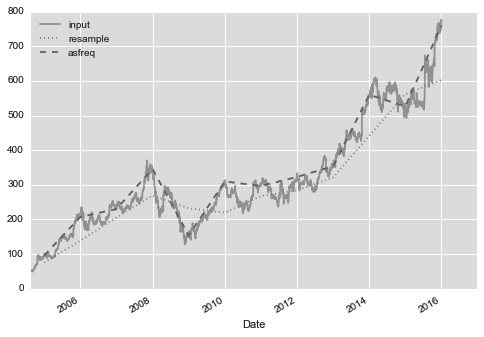
感觉没看懂,不管了,以后再查resample和asfreq吧,还要配合一些填充。
- 时间迁移
另一种常用的时间序列操作是对数据按时间进行迁移。Pandas 有两种解决这类问题的方法: shift() 和 tshift() 。简单来说, shift() 就是迁移数据,而 tshift() 就是迁移索引。两种方法都是按照频率代码进行迁移
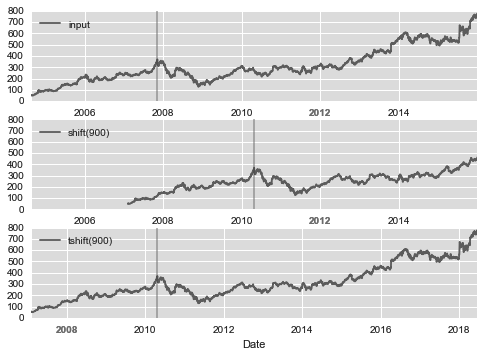
shift(900) 将数据向前推进了 900 天,这样图形中的一段就消失了(最左侧就变成了缺失值),而 tshift(900) 方法是将时间索引值向前推进了 900 天。
- 移动时间窗口
移动统计值(rolling statistics)。这些指标可以通过 Series 和 DataFrame 的 rolling() 属性来实现,它会返回与 groupby 操作类似的结果(详情请参见 3.9 节)。移动视图(rolling view)使得许多累计操作成为可能。
3.12.7 案例:美国西雅图自行车统计数据的可视化。
高性能Pandas:eval()、query()
Python 数据科学生态环境的强大力量建立在 NumPy 与 Pandas 的基础之上,并通过直观的语法将基本操作转换成 C 语言:在 NumPy 里是向量化 / 广播运算,在 Pandas 里是分组型的运算。虽然这些抽象功能可以简洁高效地解决许多问题,但是它们经常需要创建临时中间对象,这样就会占用大量的计算时间与内存。
Pandas 从 0.13 版开始(2014 年 1 月)就引入了实验性工具,让用户可以直接运行 C 语言速度的操作,不需要十分费力地配置中间数组。它们就是 eval() 和 query() 函数,都依赖于 Numexpr (https://github.com/pydata/numexpr) 程序包。
设计动机:复合代数式
在进行复合代数式运算时,例如:
rng = np.random.RandomState(42)
x = rng.rand(pow(10,6))
y = rng.rand(pow(10,6))
mask = (x > 0.5) & (y < 0.5)
#在进行这个运算的时候,由于Numpy会计算每一个代数子式,相当于
tmp1 = (x > 0.5)
tmp2 = (y < 0.5)
mask = tmp1 & tmp2
#每段中间过程都需要显式地分配内存。Numexpr 程序库可以让你在不为中间过程分配全部内
#存的前提下,完成元素到元素的复合代数式运算。
import numexpr
mask_numexpr = numexpr.evaluate('(x > 0.5) & (y < 0.5)')
np.allclose(mask, mask_numexpr)马上要介绍的 Pandas 的 eval() 和 query()工具其实也是基于 Numexpr 实现的。
eval实现高性能运算
就我自己试验的结果,还不如不优化。。可能是pandas已经内置了更厉害的吧。
import pandas as pd
nrows, ncols = 100000, 100
rng = np.random.RandomState(42)
df1, df2, df3, df4 = (pd.DataFrame(rng.rand(nrows, ncols))
for i in range(4))
%timeit df1 + df2 + df3 + df4
100 ms ± 15.4 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit pd.eval('df1 + df2 + df3 + df4')
99.2 ms ± 2.41 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
#而且内存消耗更少支持的运算:
算术运算符
pd.eval() 支持所有的算术运算符
np.allclose()这个是用来确认两者相等的。
比较运算符
支持所有的比较运算符,包括链式代数式
位运算符
另外,你还可以在布尔类型的代数式中使用 and 和 or 等字面值
result3 = pd.eval('(df1 < 0.5) and (df2 < 0.5) or (df3 < df4)')
- 对象属性与索引
可以通过 obj.attr 语法获取对象属性,通过 obj[index] 语法获取对象索引
result1 = df2.T[0] + df3.iloc[1]
result2 = pd.eval('df2.T[0] + df3.iloc[1]')
np.allclose(result1, result2)——True目前 pd.eval() 还不支持函数调用、条件语句、循环以及更复杂的运算。如果你想要进行这些运算,可以借助 Numexpr 来实现。
用DataFrame.eval()实现列间计算。
由于 pd.eval() 是 Pandas 的顶层函数,因此 DataFrame 有一个 eval() 方法可以做类似的运算。使用 eval() 方法的好处是可以借助列名称进行运算,示例如下:
df = pd.DataFrame(rng.rand(1000, 3), columns=['A', 'B', 'C'])
df.head()
Out[98]:
A B C
0 0.375506 0.406939 0.069938
1 0.069087 0.235615 0.154374
2 0.677945 0.433839 0.652324
3 0.264038 0.808055 0.347197
4 0.589161 0.252418 0.557789
result1 = (df['A'] + df['B']) / (df['C'] - 1)
result2 = pd.eval("(df.A + df.B) / (df.C - 1)")
np.allclose(result1, result2)
Out[99]: True
# 不知道为啥还是负优化。。。还是这个inplace的用法有价值
df.eval('D = (A + B) / C', inplace=True)
df.head()
Out[102]:
A B C D
0 0.375506 0.406939 0.069938 11.187620
1 0.069087 0.235615 0.154374 1.973796
2 0.677945 0.433839 0.652324 1.704344
3 0.264038 0.808055 0.347197 3.087857
4 0.589161 0.252418 0.557789 1.508776DataFrame.query() 方法
result2 = pd.eval('df[(df.A < 0.5) & (df.B < 0.5)]')
#相当于
result2 = df.query('A < 0.5 and B < 0.5')
#除了计算性能更优之外,这种方法的语法也比掩码代数式语法更好理解。
#需要注意的是,query() 方法也支持用 @ 符号引用局部变量,eval不支持!
Cmean = df['C'].mean()
result1 = df[(df.A < Cmean) & (df.B < Cmean)]
result2 = df.query('A < @Cmean and B < @Cmean')
#什么叫反向优化啊草
%timeit result2 = pd.eval('df[(df.A < 0.5) & (df.B < 0.5)]')
20.8 ms ± 943 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit result2 = df.query('A < 0.5 and B < 0.5')
1.37 ms ± 9.18 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit result2 = df[(df.A < 0.5) & (df.B < 0.5)]
520 µs ± 3.46 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)在考虑要不要用这两个函数时,需要思考两个方面:计算时间和内存消耗,而内存消耗是更重要的影响因素。
如果临时 DataFrame 的内存需求比你的系统内存还大(通常是几吉字节),那么最好还是使用 eval() 和 query() 代数式。
可以用df.value.nbytes大概估算一下
在实际工作中,我发现普通的计算方法与 eval / query 计算方法在计算时间上的差异并非总是那么明显,普通方法在处理较小的数组时反而速度更快! eval / query 方法的优点主要是节省内存,有时语法也更加简洁。
尤其需要注意的是,可以通过设置不同的解析器和引擎来执行这些查询,相关细节请 参 考 Pandas 文 档 中“Enhancing Performance”(http://pandas.pydata.org/pandas-docs/dev/enhancingperf.html)节。
剩下的东西放在notebook跑吧!!!
参考资料
但因篇幅有限,仍有许多知识无法介绍到
如果你想学习更多的 Pandas 知识,推荐参考下面的资源。
《利用 Python 进行数据分析》
PyVideo 上关于 Pandas 的教学视频(http://pyvideo.org/tag/pandas/)



