python课件总结
[toc]
ps:
这份笔记并不完整,是笔者学了一遍粗糙的python后二刷看课件觉得有用的东西,课件想要的私聊,不贵不贵,一杯奶茶:laughing:
还有那份课件的题目值得一做!
1.语言基础
面向对象 、 解释型 、 动态数据类型



变量与地址



Python 解释器会为每个出现的对象分配内存单元,即使它们的值相等,也会这样
为了 提高内存利用效率,对于一些简单的对象,如一些数值 较小(-256~256 )的 整型(int )对象,Python 采取重用对象内存的办法
单独的下画线(_ )是一个特殊变量,用于表示上一次运算的结果

Math
整数二进制0b\0B开头,八进制0o\0O开头,十六进制0x\0X开头
对于浮点数,Python 3.x 默认提供17 位有效数字的精度,相当
于C 语言中的双精度浮点数
可以通过x.real 和x.imag 来分别获取复数x 的实部和虚部,结果都是浮点型,是j不是i
数学常量:e pi
函数:
fabs sqrt pow(x,y) exp log(x[,base])(base默认是e) log10()
ceil floor
fmod(x,y) # x/y的余数 (浮点)
degrees <=> radians
sin cos tan asin acos atan(默认用弧度)
Cmath模块函数基本一致,但是对复数运算
cmath.sqrt(-1) ij 用的是j不是i
cmath 模块包括复数 运算特有的 函数。
复数x=a+bi ,phase(x) 函数返回复数x 的幅 角,即atan(b/a) 。

Random
seed设置种子,默认将系统时间设为种子值
choice(seq) :从 序列的元素中随机挑选一个 元素 。
sample(seq,k) :从 序列中随机挑选k 个元素。
shuffle(seq) :将 序列的所有元素随机排序 ,这个只能用于可更改的,字符串不可用

时间和日历
datetime基于time进行了优化,更方便全面
datetime
from datetime import datetime,date,time
dt = datetime(2021,5,1,21,8,30)
dt.year,month,day,hour,minute,second
dt.date()输出前三个
dt.time()输出后三个
dt.strftime('%x%x%x')
datetime.strptime('202151',"%Y%m%d")#转换为datetime对象!!这个是datetime下的datetime子类!!!
datetime相减会产生datetime.delta对象
delta = datetime2 - datetime1
delta == datetime.timedelta(99,7179) #间隔99天,7179秒
timedelta和datetime可以做加减得到新的datetime
%y 两位数的年份表示(00-99)
*%Y 四位数的年份表示(000-9999)
*%m 月份(01-12)
*%d 月内中的一天(0-31)
*%H 24小时制小时数(0-23)
*%I 12小时制小时数(01-12)
*%M 分钟数(00=59)
*%S 秒(00-59)
*%a 本地简化星期名称
*%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
python内置
range iter

帮助




Python 中能表示浮点数的有效数字是有限的,而在实际应用中数据的有效位数并无限制,这种矛盾,势必带来计算时的微小误差。
2.顺序结构
在Python 中,语句行从解释器提示符后的第一列开始, 前面不能有任何空格 ,否则会产生语法错误


Python 中的赋值并不是直接将一个值赋给一个变量的,而是通过引用传递的,在赋值时,不管这个对象是新创建的还是一个已经存在的,都是将该对象的 引用( 并不是值 )
同步赋值指的是多变量一条式子赋值时,实际上先创建了一个元组,先后顺序不影响
eval()去掉字符串最外侧的引号
print(xxx[,sep =][,end = ])





字符串format方法
这才是王道


用序号调整次序,重复什么的很方便


注意这个居中填充,还有居中不对称时左边少一个
print('what {1:<10}{0}the {c:&<10.1f}'.format('a','b',c = 21.311))
what b athe 21.3&&&&&&
In [3]: print('what {1:<10}{0}the {c:&=+10.1f}'.format('a','b',c = 21.311))
what b athe +&&&&&21.3
3.循环结构
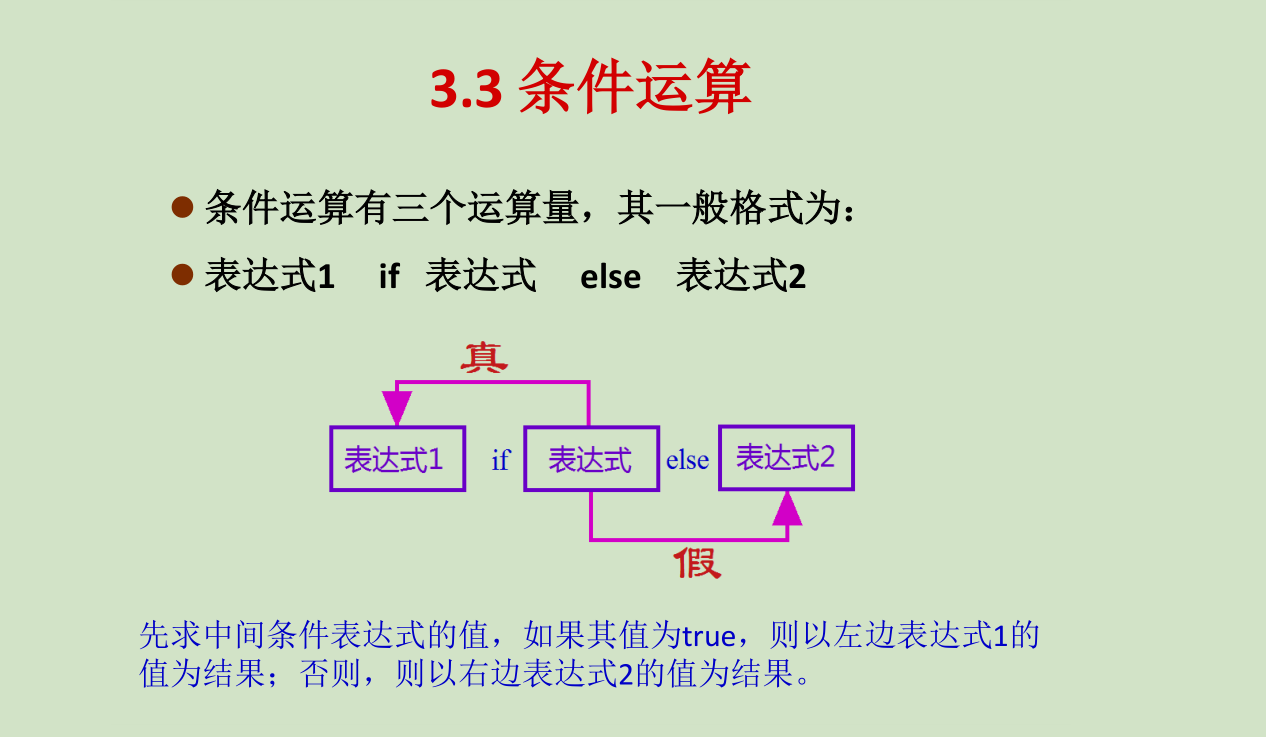

for 语句是通过遍历任意序列的元素进行来建立循环的,针对序列的每一个元素执行一次循环体


首先Python 对关键字in 后的对象调用iter() 函数获得迭代 器,然后 调用next() 函数获得迭代器的 元素,直到 抛出stopIteration
while 语句多用于循环次数不确定的情况,而对于循环次数确定的情况,使用for
pass空语句
注意 :布尔常量True 和False 首字母必须大写 !
4.字符串
建议看看原文
编码
万国码Unicode是python选择的标准符号表,它每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求(翻译二进制码的方式)
ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节。
UTF-8 编码中,一个英文字为一个字节,一个中文为三个字节。
Unicode 编码中,一个英文为一个字节,一个中文为两个字节。
字节只是一个单位(8位)罢了,不同的编码中采用不同的规则存储字符,而这些规则实现的时候消耗字节大小不同
UTF-8
是 一种为Unicode 字符设计的变长编码系统
对于ASCII 字符,UTF-8 仅使用1 个字节来编码



Unicode规定了,所有字符统一由两个字符来表示,也就是16位
utf-8就是缩小一点,从4到8到12到16分段
详述有一点错误就是最后那个中文例子,看我的👇
而python字符串默认是unicode编码
In [1]: a = '卧槽'
In [2]: a[0]
Out[2]: '卧'
In [3]: a.encode('utf-8')
Out[3]: b'\xe5\x8d\xa7\xe6\xa7\xbd' #一个汉字拆成三个字节
In [10]: c = 'dnoad'
In [11]: c.encode('utf-8')
Out[11]: b'dnoad'
# 英文在utf-8中不会发生转换,直接用一个字节表示
In [13]: ord('我')
Out[13]: 25105 #unicode
In [14]: chr(25104)
Out[14]: '成'分片的操作很灵活,开始和结束 的索引值 可以超
过字符串的长度
字符串用 + 和 *

但是在解释器里面,都是输出普通的’abc’
Python 的字符串是不可变类型,只能通过新建一
个字符串去改变一个字符串的元素


字符比较是按其计算机内部字符编码值的大小进
行比较,西文字符按ASCII 码值大小进行比较
比较的基本规则是,空格字符最小,数字比字母
小,大写字母比小写字母小( 对应字母相 差32
函数。。



prefix和suffix是字符串,start 可以选择开头位置,end我不知道干嘛的


split如果两个分隔符中没东西,也会拆出空字符串,从左右拆顺序不变,可能只影响matsplit参数
那个splitlines试了一下:
c = 'dada\nwdad'
c
Out[51]: 'dada\nwdad'
print(c)
dada
wdad
c.splitlines()
Out[53]: ['dada', 'wdad']


字节类型

和字符串一样,可以使用内置的len() 函数求bytes对象的长度,也可以 使用“+ ” 运算符连接两个bytes 对象,其操作结果是一个新的bytes 对象

如果需要改变某个字节,可以组合使用字符串的分片和连接操作(效果跟字符串是一样的), 也可以 将bytes 对象转换为bytearray 对象,bytearray对象是可以被修改的
可以 使用编号给bytearray 对象的某个字节赋值 , 并且这个值必须是0~255 之间的一个整数
也 不允许针对bytes 对象的出现次数进行计数,因为字符串里面 根本没有字节字符
encode和decode可以在两者间转换
5.正则
在Python 中,正则表达式的功能通过正则表达式
模块re
re 模块提供各种正则表达式 的匹配 操作,在文本解析、复杂字符串分析和信息提取时是一个非常有用的工具。





使用




正则表达式中,group()用来提出分组截获的字符串,()用来分组
import re
a = "123abc456"
print re.search( "([0-9]*)([a-z]*)([0-9]*)" ,a).group( 0 ) #123abc456,返回整体
print re.search( "([0-9]*)([a-z]*)([0-9]*)" ,a).group( 1 ) #123
print re.search( "([0-9]*)([a-z]*)([0-9]*)" ,a).group( 2 ) #abc
print re.search( "([0-9]*)([a-z]*)([0-9]*)" ,a).group( 3 ) #456- 正则表达式中的三组括号把匹配结果分成三组
- group() 同group(0)就是匹配正则表达式整体结果
- group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
- 没有匹配成功的,re.search()返回None



注意到匹配模式串使用了原始字符串r’ ‘
match() 方法并不是完全匹配。当正则表达式结束时,若string 还有剩余字符 ,仍然视为 成功
想 要完全匹配,可以在表达式末尾加上边界匹配符’$
match() 函数只是在字符串 的左端位置 尝试匹配正则表达式,也就是只报告从位置0 开始的 匹配情况。
如果想要搜索整个字符串来寻找匹配,应当用search() 函数 ,使用方法完全一样
findall() 函数搜索字符串,以列表形式返回全部能匹配正则表达式的子串 。

finditer() 与findall() 函数类似,在字符串中找到正则表达式所匹配的所有子串,并组成一个迭代器返回。


subn() 函数的功能和sub() 函数 相同,但 返回新的字符串以及替换的次数组成的元组 。




两个斜杠噢,第一次先让编译器把两个斜杠转成一个斜杠,第二步到正则字符串则把剩下的单斜杠看成是转义
6.列表&元组
len() min() max()
sum()返回序列s中所有元素和,元素必须为数值
reduce 位于functools模块中
reduce(f,s[,n]) :reduce() 函数把序列s 的前两个元素作为 参数,传 给函数f ,返回 计算的结果和 序列的下一个元素重新作为f 的参数,直到序列的最后一个元素
enumerate 和 zip不必多言
利用* 号操作符,可以将对象解压 还原
>>> t
[('a', '1'), ('b', '2'), ('c', '3')]
>>> m=zip(*t)
>>> list(m)
[('a', 'b', 'c'), ('1', '2', '3')]还有sorted reversed all any

加星号的变量只允许一个,否则会出现语法错误syntaxError 。
列表可以进行元素赋值(索引不能超)
元素删除 del 分片赋值 在使用分片赋值时,可使用与原序列不等长的序列将分片替换




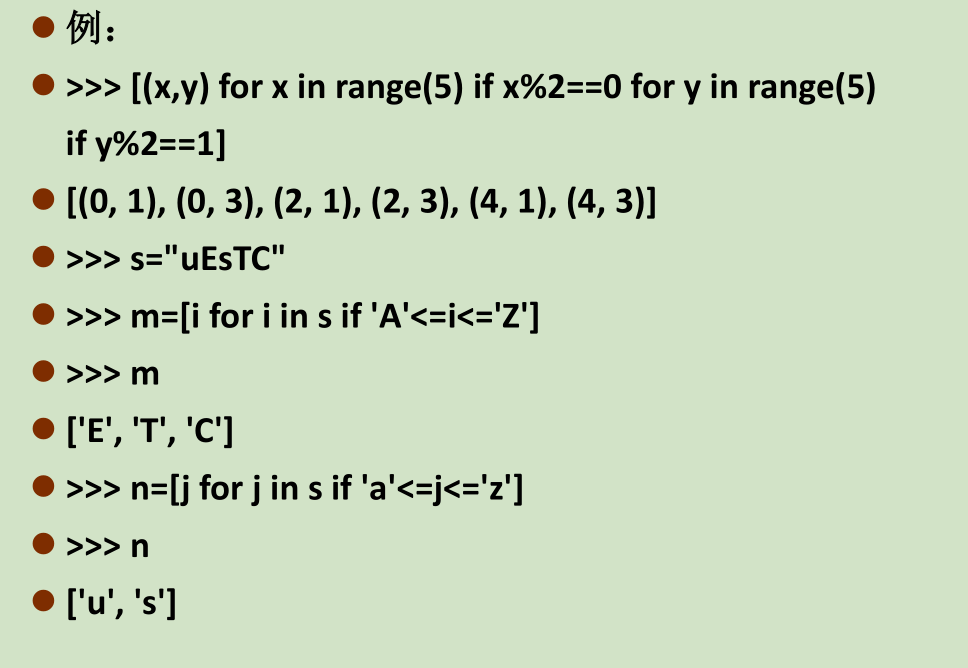
for前面的部分是一个表达式,它必须根据x计算出一个结果,必须加上else,如:
[x if x % 2 == 0 else -x for x in range(1, 11)]列表常用方法
- 序列都可以用
并不改变序列本身,可用于列表,元组,字符串
s.count(x) :返回x 在序列s 中出现的次数
s.index(x) :返回x 在s 中第一次出现的下标
不过x是完整的

- 仅使用列表


s.reverse() :将列表s 中的元素逆序排
s.pop([i]) :删除并返回列表s 中指定位置i 的元素,默认是最后一个元素。若i 超出列表长度 ,则 抛出IndexError 异常
s.insert(i,x) :在列表s 的i 位置处插入x 。如果i 大于列表的长度,则插入到列表最后 。

可以看看题目
7.字典

更新和创建都用索引,删除则用del,检查关键字用in / not in
len() 函数可以获取字典所包含“关键字: 值”对的数目,即字典长度 。虽然 也支持max() 、min() 、sum() 和sorted() 函数,但只针对字典的关键字进行计算,很多情况下没有实际意义。
字典不支持连接(+) 和重复操作符(*) ,关系运算中只有“==” 和“!=” 有意义
常用方法
dict三用法:
使用dict() 函数创建一个空字典并给变量赋值

第二种方法应该是大规模处理中用的多的

Python 字典和集合实际上也是对象,Python 提供了很多有用的方法。


原先的键会被清除,字符串也可以做序列, 重复的键会被删除
d2 = d.fromkeys(('dwad'))
d2
Out[92]: {'d': None, 'w': None, 'a': None}






8.集合
在Python 中, 集合( set )是 一个无序排列的、不重复的数据集合体,类似于数学中的集合概念 ,可 对其 进行并、 交、 差等 运算
集合和字典都属于无序集合体,有许多操作是一致的



在Python 中,用大括号将集合元素括起来,这与字典的创建类似,但{} 表示空字典,空集合用set()表示。
集合 的 自动删除重复元素 这个特性非常有用,例如,要删除列表中大量的重复元素,可以先用set()函数将列表转换成集合,再用list() 函数将集合转换成列表,操作效率非常高。

Python 提供frozenset() 函数来创建不可变集合,不可变集合是不能修改的,因此能作为其他集合的元素,也能作为字典的关键字。

传统运算

比较用 == 和 != 还有包含真包含 < <=
当然还有赋值运算符 s1 |= s2
集合与for 循环语句配合使用,可实现对集合各个元素的遍历

常用方法
- 适用于可变和不可变集合


s.copy() :复制集合s 。
- 适合可变集合的方法



9.函数与模块
在Python 中,实参向形参传送数据的方式是“值传递”,即“拷贝”或“复制”
实参 的值传给形参 ,是对象间整体赋值,是 一种单向传递方式,不能由形参传回给实参。
主函数


参数传递
1. 必选参数就是位置参数,必须填,
2. 默认参数可填可不填。默认参数有个坑,就是每次调用函数,默认参数的指向不便且会保存,所以可修改,每次都不一样,因此定义默认参数要牢记一点:默认参数必须指向不变对象!
3. 然后就到可变参数,指的是可以接受所有值的元组,*args 放在第三位接受所有的
4. 第四是命名关键字,或者说可变字典**kw 接受所有的 a = 'xxx' 这样的参数,并赋给字典,但是key不用加引号
5. 最后是关键字参数,不能省略的键值对!
#其实就是无限接受的放在后面。
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job):
print(name, age, city, job)
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
调用方式如下:
>>> person('Jack', 24, city='Beijing', job='Engineer')
Jack 24 Beijing Engineer
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job):
print(name, age, args, city, job)
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错:
>>> person('Jack', 24, 'Beijing', 'Engineer')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: person() takes 2 positional arguments but 4 were given
#命名关键字参数可以有缺省值,从而简化调用函数参数规则:
- 参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
- 对于任意函数,都可以通过类似
func(*args, **kw)的形式调用它,无论它的参数是如何定义的。 - 虽然可以组合多达5种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
注意 **dict解包作为参数时,是复制一份,也就是传值
当在 函数内部修改列表、字典的 元素时,形参的改变会影响实参,即双向传递,类似于“传地址”、“共享内存”、“借”,
匿名函数lambda
lambda [ 参数1[, 参数2,……, 参数n]]: 表达式
关键字lambda 表示匿名函数,冒号前面是函数参数,可以有多个函数参数,但只有一个返回值 ,所以只能有一个表达式,返回值就是该表达式的结果。

装饰器
这个讲的比一般的清楚一点所以放在这。
装饰器 (decorator ,[ˈdekəreɪtə(r)] )可简单地理解为一个函数,这是一个用来包装函数的函数,经常用于为已经存在的函数添加额外的功能
当多个函数有重复代码时,可以将此部分代码单独拿出来整理成一个 装饰 器,然后对每个函数调用该装饰器,这样可以实现代码的复用,而且可以让原来的函数更轻便 。
当 需要为多个己经写好的函数添加一个共同功能,例如检查参数的合法性时,就可以单独写一个检查合法性的装饰器,然后在每个需要检查参数合法性的函数处调用即可,而不用去每个函数内部修改
无参数


把@deco 语句放在函数square_sum() 定义之前,实际上是将square_sum 传递给装饰器deco ,并将deco 返回的新函数对象赋给原来的函数名 square_sum=deco(square_sum)
从本质上,装饰器起到的就是这样一个重新指向函数名的作用,让同一个对象名指向一个新返回的函数,从而达到修改可调用函数的目的
最外层定义deco的本体,把函数传进去,里面定义新函数,新函数肯定要调用到原来的函数。如果需要传参数,就在本体外面再加一层传递参数的壳。
有参数

要注意多重装饰器的执行顺序,应该是先执行后面的装饰器,再执行前面的装饰器。
global
在程序中定义全局变量的主要目的是,为函数间的数据联系提供一个直接传递的通道 。
因此不要滥用全局变量
模板有条件执行
模块 中可以是一段 可以 直接执行的 程序(也称为
脚本 ) , 也可以定义一些变量、类或函数,让别的模块导入和调用, 类似于库。
模块中的定义部分,例如全局变量定义、类定义、函数定义等,因为没有程序执行入口,所以 不能直接运行,但对主程序代码部分有时希望只让它在模块直接执行的时候才执行,被其他模块加载时就不执行。
在Python 中,可以通过系统变量“__name__”(注意前后都是两个下画线)的值来区分这两种情况。 如果模块是被其他模块导入的,__name__ 的值是模块的名称,主动执行时它的值就是字符串“__main__” 。
通过__name__ 变量的这个特性,可以将一个模块文件既作为普通的模块库供其他模块使用,又可以作为一个可执行文件进行 执行。
10.面向对象
面向对象程序设计(Object-Oriented programming ,OOP )则以对象作为程序的主体,将程序和数据封装于其中,以提高软件的重用性、灵活性和扩展性
面向对象程序设计是按照人们认识客观世界的系统思维方式,采用基于对象的概念建立问题模型,模拟客观世界,分析、设计和实现软件的办法
面向对象语言的三大核心内容是封装(类和对象)、 继承(派生)和 多态




class A:
x = 5
我定义了一个类A,这个时候自动出现了个类对象A,我可以使用A.x调用类属性
“ .” 运算符:成员运算符

类中的实例方法至少应有 一 个变量 参数,一般命名为“ self ”( 习惯,非语法要求) ) ,而且该参数必须 作为形参表的第一 个参数,即必须放 于形式参数 表的最左边
实例的方法和对象只能实例调用,不能类调用,这不是废话嘛
属性
类 属性(class attribute )是类的 属性,它被 所有类对象和实例对象共有 ,在内存中只存在一个副本
公有 的类属性,在类外可以通过类对象和实例对象访问 ,但是不提倡用实例对象访问,容易绕晕
类属性还可以在类定义结束之后通过类 名(类对象)增加 比如 A.new = 212
实例对象也 可以在类定义结束之后通过实例对象名增加实例属性




方法



只要创建实例对象,就一定要调用构造方法
只要调用了构造方法,就一定创建了实例对象

构造方法重载:
- 使用默认参数
- 构造方法根据条件调用其他的自定方法
- 构造方法根据条件执行不同的操作,可以用*arg来接受数量未知的参数
具体方法


实例方法必须有一个参数放在最左端,self

@staticmethod 静态方法只是名义上归属类管理,但是不能使用类变量和实例变量,是类的工具包
放在函数前(该函数不传入self或者cls),所以不能访问类属性和实例属性
静态方法没有类似 self、cls 这样的特殊参数,因此 Python 解释器不会对它包含的参数做任何类或对象的绑定。也正因为如此,类的静态方法中无法调用任何类属性和类方法。
继承和多态
从已有类产生新类的过程就称为类的派生(derivation)(派生是继承的另一种说法)






多重 继承(multiple inheritance )是指一个子类有两个或多个直接父类,子类从两个或多个直接父类中继承所需的 属性和方法。
class 子类名( 父类名1, 父 类名2,…):

Python 本身是一种 解释型语言 ,不进行编译,因此它就只在运行时 确定 其状态,故也可以说Python 是一种多态语言 。


高级操作
__slot__,限制示例对象能自主添加的属性。
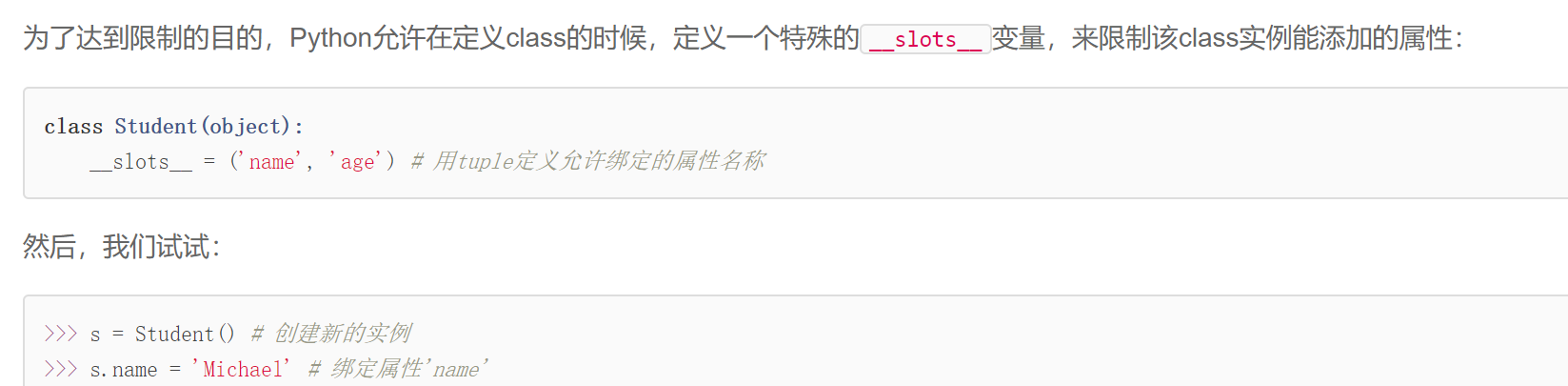
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查(在setter里),这样,程序运行时就减少了出错的可能性。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017502538658208
class Screen(object):
@property #相当于getter
def width(self):
return self.__width
@width.setter
def width(self, value):
self.__width = value
@property
def height(self):
return self.__height
@height.setter
def height(self, value):
self.__height = value
@property
def resolution(self):
return 786432dir 返回所有的方法和属性,包括私有的和隐藏的,私有的会变成 _类名__属性
hasattr getattr setattr
还可以将object提供的类的诸多参数比如__len__ \ __call__override来自定义类
11.文件操作
这个把我的心态搞炸了一会
首先python里的默认编码都是Unicode,所有的文件其实本质都是二进制码,二进制文件只能用bytes类型操作,读出来怎么解读自己来,一般都用Unicode规则来decode( 二进制文件 是把数据按其在内存中的存储形式原样输出到磁盘上存放。)
小心那个文件指针位置,你写入了以后会放在最后,再读取啥都读不出来类似的
Python你在读写文件的时候不要打开。。不然会出现更改不了。。
理解python的opentxt默认是ANSI编码,不是UTF-8,坑死了,解决方案👈

经常需要用到“终端形式”阅读的,用文本,经常修改的,最好用二进制
读/ 写操作是相对于磁盘文件而言的,而输入/ 输出操作是相对于内存储器而言的
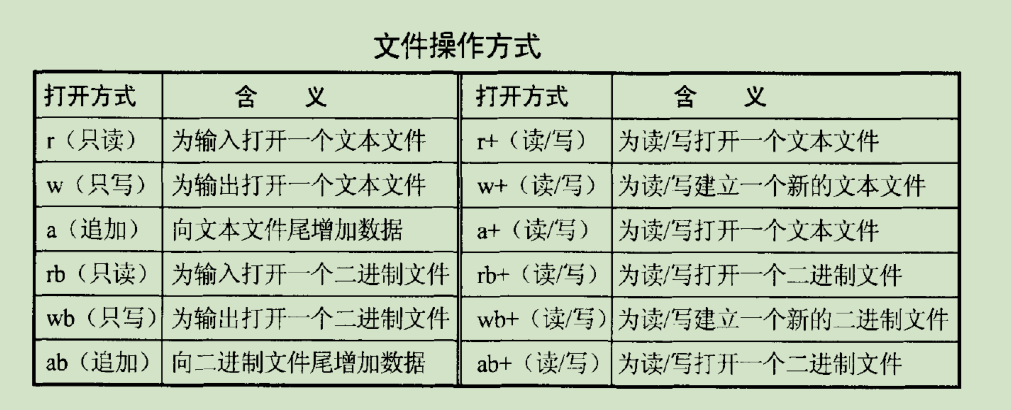
r+是从最开始开始读的
文件对象=open( 文件说明符[, 打开方式][, 缓冲区])


文件对象有一些属性


文本
文本文件是指以ASCII 码方式存储的文件:英文、数字等字符存储的是ASCII 码 ,而 汉字存储的是机内码。
文本文件中除了存储文件有效字符信息(包括能用ASCII 码字符表示的回车、换行等信息)外,不能存储其他任何信息
文本文件的 优点:方便 阅读和理解,使用常用的文本编辑器或文字处理器就可以对其创建和修改的,文件 对象提供了read() 、readline() 和readlines() 方法 用于读取文本文件的内容
每次write() 方法 执行完后并不 换行,如果 需要换行则在字符串最后加 换行符“\n
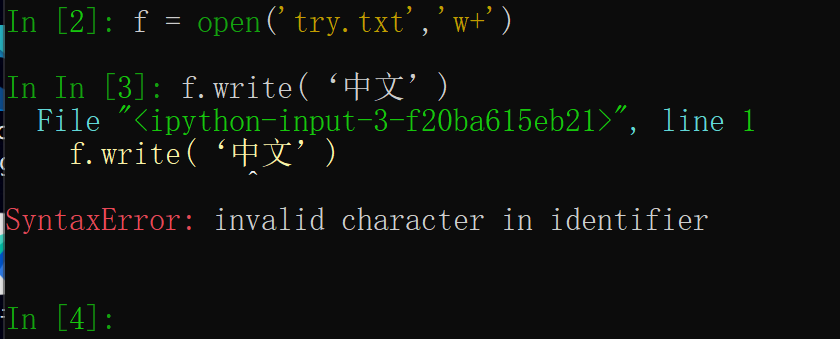
读取中文问题:
InIn [6]: f = open('try.txt','r+')
In [7]: a = f.read()
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-7-648df9718e18> in <module>()
----> 1 a = f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 8: illegal multibyte sequence
默认gbk
In [8]: f = open('try.txt','r+',encoding = 'utf-8')
In [9]: a = f.read()
In [10]: a
Out[10]: '我是中文'
In [11]: f.write('现在能输中文吗')
Out[11]: 7 #成功了二进制


seek()偏移为正数表示朝文件尾方向移动,偏移为负数表示朝文件头方向移动;


文本文件 存放的是与编码对应的字符,而二进制文件直接存储字节编码。
struct模块

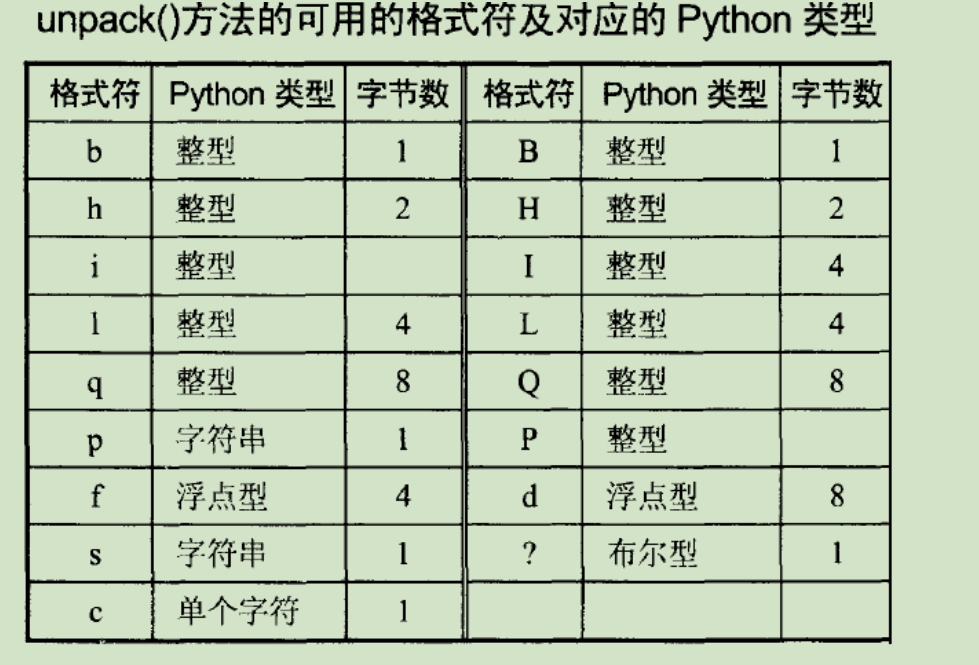
读文件的时候,可以一次读出4 个字节,然后用unpack() 方法转换成Python 的整数 。
注意:unpack() 方法执行后得到的结果是一个元组。

如果写入的数据是由多个数据构成的,则需要在pack() 方法中使用格式串

此时的bytes 就是二进制形式的数据了,可以直接写入二进制文件 。当需要时可以读出来,再通过struct.unpack() 方法解码成Python 变量

pickle模块

在pickle 模块中有2 个常用的方法:dump() 和load()
pickle.dump( 数据,文件对象)
其功能是直接把数据对象转换为字节 字符串,并保存到文件中 。



OS
Python 的os 模块提供了类似于操作系统级的文件管理功能,如文件重命名、文件删除、目录管理等
os.rename(“ 当前文件名”,” 新文件名”)
os.remove(“ 文件名”)
os.mkdir(“ 新目录名”)
os.chdir(“要成为当前目录的目录名”)
getcwd() 方法显示当前的工作目录。
os.rmdir(“ 待删除目录名”) 在用rmdir() 方法删除一个目录前,先要删除目录中的所有内容。
12.异常
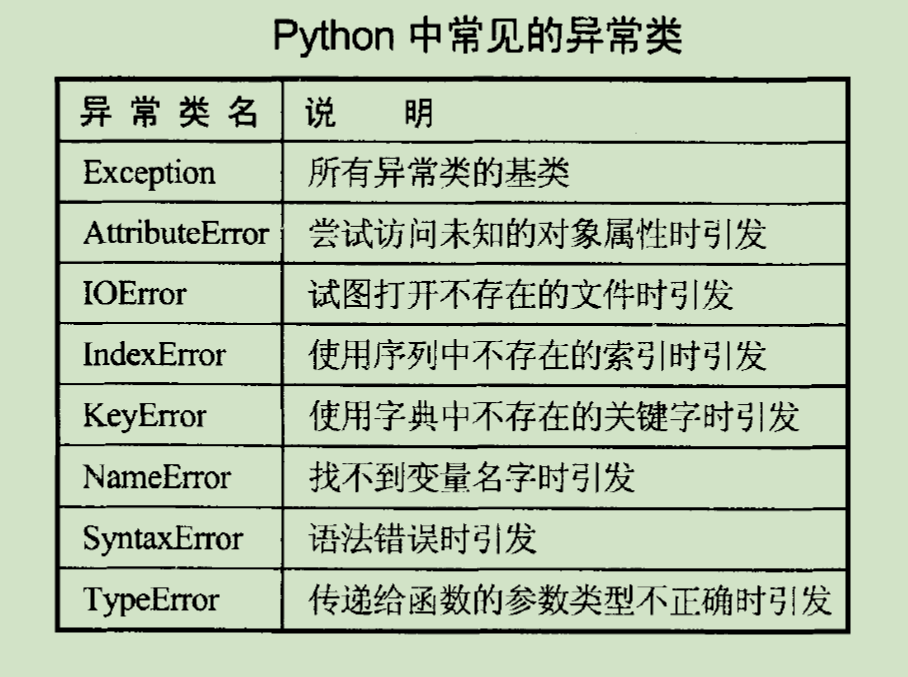
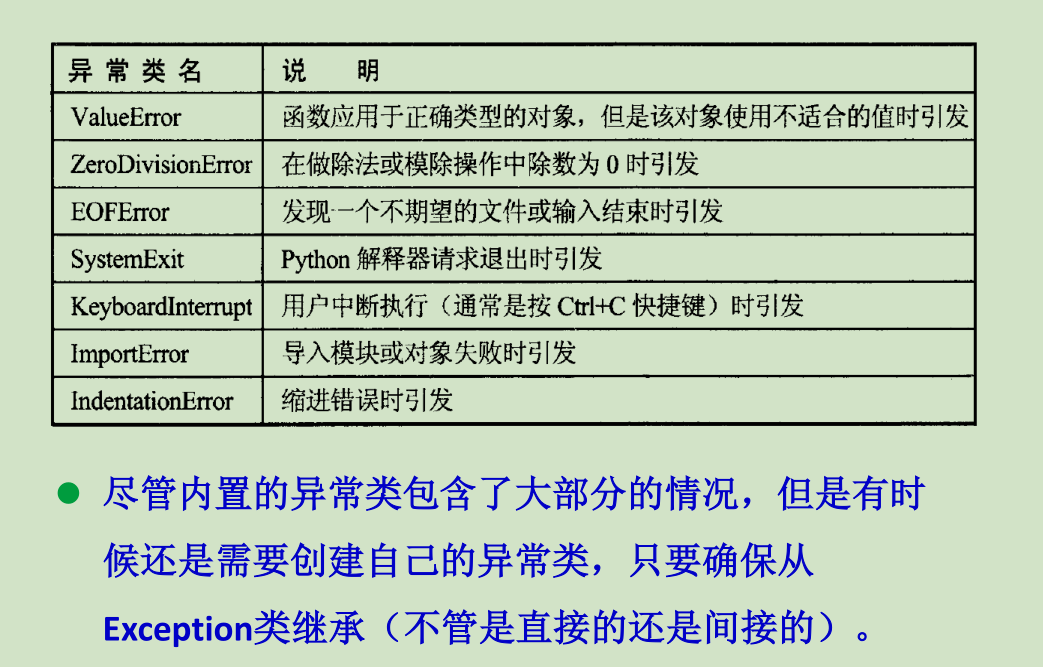
程序中的错误通常分为 语法错误 、 运行错误 和 逻辑错误 。
语法 错误是由于程序中使用了不符合 语法规则 的信息而导致的 ,这类错误比较 容易 修改,因为编译器或解释器会指出错误的位置和性质
运行错误则不容易修改,因为其中的错误是 不可预料的,或者可以预料但无法避免 的, 例如:内存 空间不够、数组下标越界、文件打开失败等
逻辑错误 主要表现在程序运行后,得到的结果与设想的结果不一致,通常出现逻辑错误的程序都能正常运行系统 不会给出提示信息,所有很难发现。
良好的程序应该对用户的不当操作做出提示,能识别多种情况下的程序运行状况,并选择适当 的应对 策略
在程序中,对各种可预见的异常情况进行处理称为异常处理(exception handling)
处理程序异常的方法有很多,最简单和最直接的办法是在发现异常时,由Python 系统进行 默认的异常处理
如果 异常对象未被处理或者捕捉,程序就会用所谓的 回溯(Traceback ) 终止

标准错误信息包括两个部分:错误类型(如NameError )和错误说明(如name ‘A’ is not defined ),两者用冒号分隔
Python 系统还追溯错误发生的位置,并显示有关
信息
捕获



异常处理
try:
xxx
except 异常类型1[as 错误描述]:
xxx
except 异常类型2[as 错误描述]:
xx......
except:
默认异常处理语句块
else:
语句块

当发生异常时,直接跳转到except,try中没执行完的语句会被跳过嗷!
可以嵌套。
finally 子句是指无论是否发生异常都将执行相应的
语句块 。

断言
在编写程序时,在程序调试阶段往往需要判断程序执行过程中变量的值,根据变量的值来分析程序的执行情况
可以 使用print() 函数打印输出结果,也可以通过断点跟踪调试查看变量,但使用断言更加灵活高效 。

a,b = eval(input())
assert b!=0,'除数不可为0'
c = a/b
print(c)
Lenovo@LAPTOP-08D3H5DC MINGW64 ~/Desktop/env
$ D:/Anaconda3/envs/TF2/python.exe c:/Users/Lenovo/Desktop/env/one.py
2,0
Traceback (most recent call last):
File "c:/Users/Lenovo/Desktop/env/one.py", line 2, in <module>
assert b!=0,'除数不可为0'
AssertionError: 除数不可为0AssertionError 异常可以被捕获,并像使用在try-except 语句中的任何其他异常处理,但如果不处理,它们将终止程序并产生回溯

主动引发异常与自定义类
前面的异常类都是由Python 库中提供的,产生的异常也都是由Python 解释器引发的
在程序设计 过程中,有时需要在编写的程序中主动引发异常,还可能需要定义表示特定程序错误的异常类。
在Python 中,要想自行引发异常,最简单的形式就是输入关键字raise ,后跟要引发的异常的名称
异常 名称标识出具体的类,Python 异常处理是这些类的对象 。 raise 语句还可指定对异常对象进行初始化的参数 ,执行raise 语句时,Python 会创建指定的异常类的一个对象



处理学生成绩时,成绩不能为负数。利用前面创建的NumberError 异常类,处理出现负数成绩的异常 。



