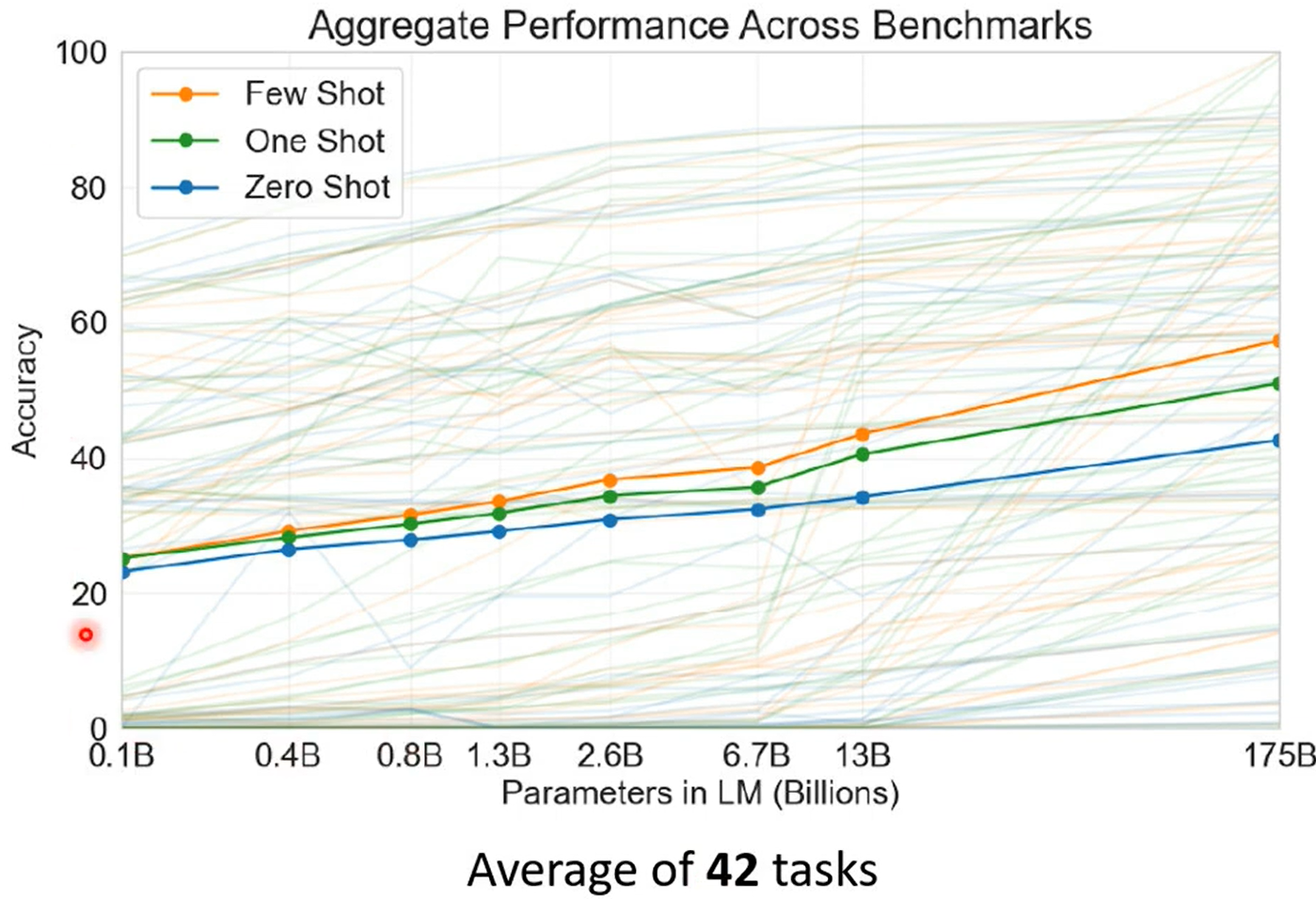
CV
Spatial Transformer
普通的CNN能够显示的学习平移不变性,以及隐式的学习旋转不变性,但attention model 告诉我们,与其让网络隐式的学习到某种能力,不如为网络设计一个显式的处理模块,专门处理以上的各种变换。
李宏毅: CNN其实没有scaling的不变性,rotation的泛化性也不是很强。【not invariant to them】
translation的泛化性有一些,可以归功于max-pooling。但没有“完全的平移泛化性”
【不然为啥还要数据增强呢xs】
Spatial transformer 也是一种layer,放在了CNN的前面,用来转换输入的图片数据,其实也可以转换feature map,因为feature map说白了就是浓缩的图片数据,所以Transformer layer也可以放到CNN里面。
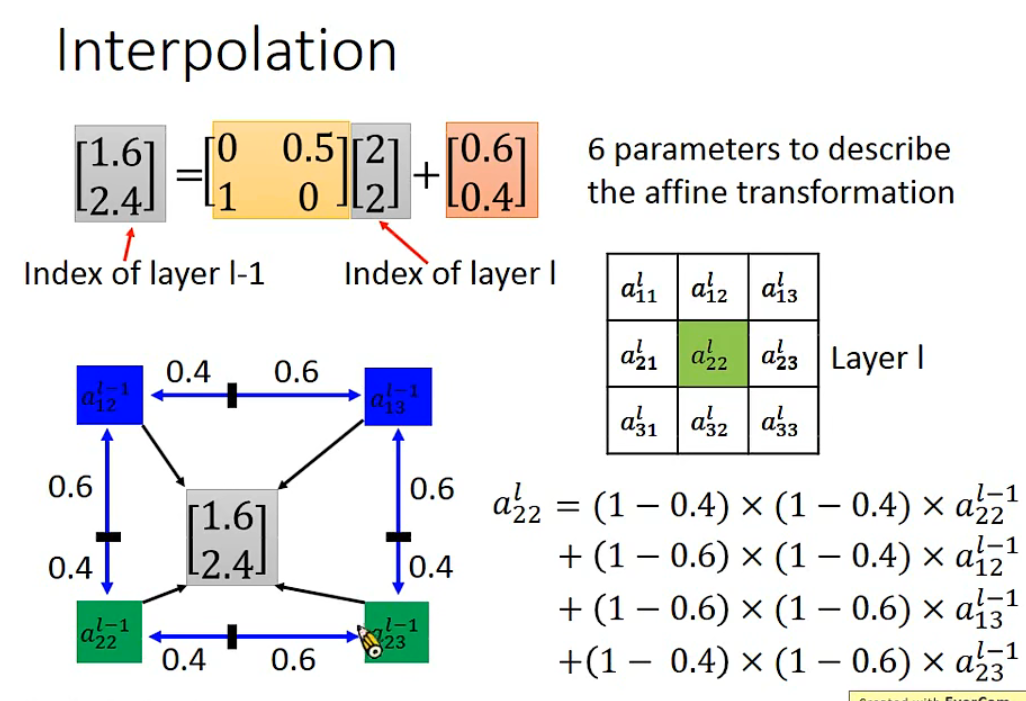
旋转和平移其实只用六个参数就能完全表示。
针对输出不是整数的情况,采用的是相邻点加权的方式。【不然没法反向求导】
基本架构如下:【可以放在CNN外和CNN内】
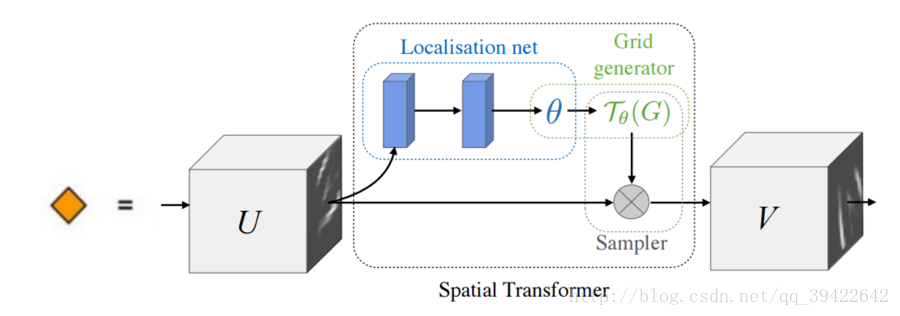
主要的部分一共有三个,它们的功能和名称如下:
参数预测:Localisation net
坐标映射:Grid generator
像素的采集:Sampler
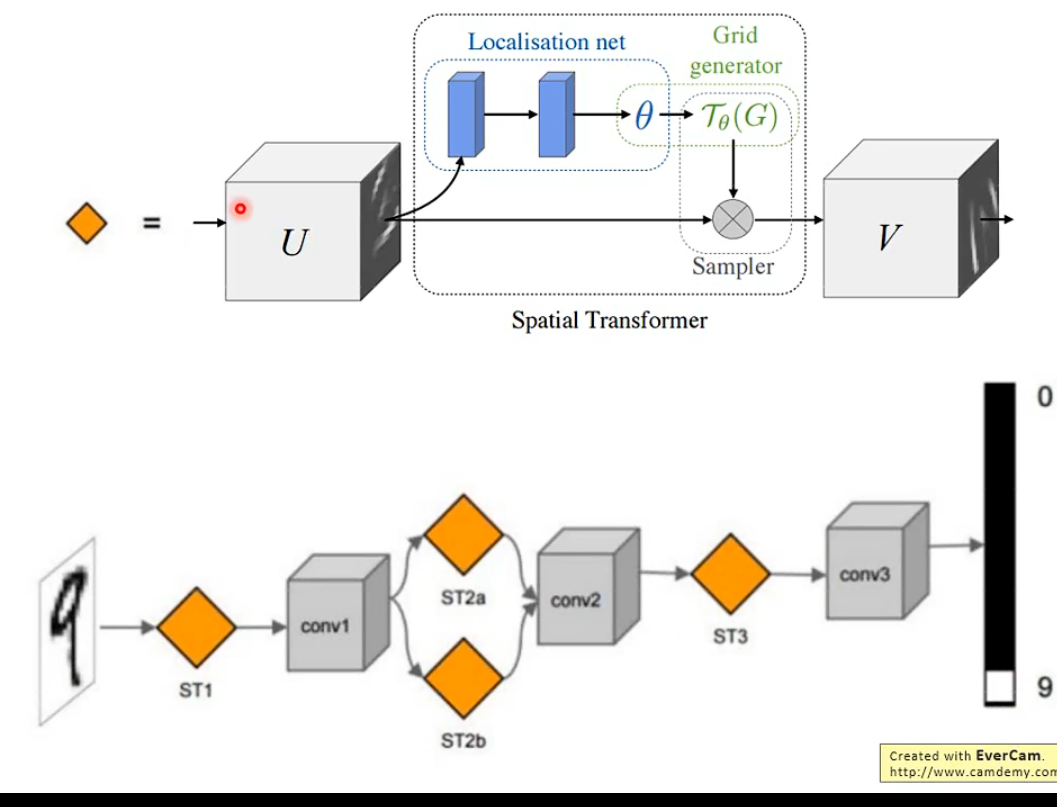
直观理解,ST相当于提供一个更稳定的输入。cool啊

NLP
预处理
从Word Embedding到Bert模型——自然语言处理预训练技术发展史
有人提到,图像、语音属于比较自然地低级数据表示形式,在图像和语音领域,最基本的数据是信号数据,我们可以通过一些距离度量,判断信号是否相似,在判断两幅图片是否相似时,只需通过观察图片本身就能给出回答。
而语言作为人类在进化了几百万年所产生的一种高层的抽象的思维信息表达的工具,其具有高度抽象的特征,文本是符号数据,两个词只要字面不同,就难以刻画它们之间的联系,即使是“麦克风”和“话筒”这样的同义词,从字面上也难以看出这两者意思相同(语义鸿沟现象),可能并不是简单地一加一那么简单就能表示出来,而判断两个词是否相似时,还需要更多的背景知识才能做出回答。
那么据上是不是可以自信地下一个结论呢:如何有效地表示出语言句子是决定NN能发挥出强大拟合计算能力的关键前提!
语言模型
语言模型包括文法语言模型和统计语言模型,一般我们指的是统计语言模型。
统计语言模型: 统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列S = ⟨w1, · · · , wT ⟩ ∈ Vn,统计语言模型赋予这个序列一个概率P(S),来衡量S 符合自然语言的语法和语义规则的置信度。一个句子的打分概率越高,越说明他是更合乎人说出来的自然句子。
常见的统计语言模型有N元文法模型(N-gram Model)
理想的语言模型就能够基于模型本身生成自然文本。 与猴子使用打字机完全不同的是,从这样的模型中提取的文本 都将作为自然语言(例如,英语文本)来传递。 只需要基于前面的对话片断中的文本, 就足以生成一个有意义的对话。 显然,我们离设计出这样的系统还很遥远, 因为它需要“理解”文本,而不仅仅是生成语法合理的内容。
表示方法
- 独热表示one-hot representation
最直观,也是到目前为止最常用的词表示方法?
向量的维度会随着句子的词的数量类型增大而增大
任意两个词之间都是孤立的,根本无法表示出在语义层面上词语词之间的相关信息,而这一点是致命的。
- 分布式表示distributed representation
分布假说:词的语义由其上下文决定( a word is characterized by thecompany it keeps)。
根据建模的不同,主要可以分为三类:基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。【均基于分布假说】
两部分:一、选择一种方式描述上下文;二、选择一种模型刻画目标词与其上下文之间的关系。
分布式表示
基于矩阵的分布表示 基于矩阵的分布表示通常又称为分布语义模型,在这种表示下,矩阵中的一行,就成为了对应词的表示,这种表示描述了该词的上下文的分布。由于分布假说认为上下文相似的词,其语义也相似,因此在这种表示下,两个词的语义相似度可以直接转化为两个向量的空间距离。
常见到的Global Vector 模型(GloVe模型)是一种对“词-词”矩阵进行分解从而得到词表示的方法,属于基于矩阵的分布表示。
基于聚类的分布表示 基于聚类的分布表示作者也还不是太清楚,所以就不做具体描述。
基于神经网络的分布表示,词嵌入(word embedding)
词嵌入/词向量
在前面基于矩阵的分布表示方法中,最常用的上下文是词。如果使用包含词序信息的 n-gram 作为上下文,当 n 增加时, n-gram 的总数会呈指数级增长,此时会遇到维数灾难问题。而神经网络在表示 n-gram 时,可以通过一些组合方式对 n 个词进行组合,参数个数仅以线性速度增长。有了这一优势,神经网络模型可以对更复杂的上下文进行建模,在词向量中包含更丰富的语义信息。
而神经网络在表示 n-gram 时,可以通过一些组合方式对 n 个词进行组合,参数个数仅以线性速度增长。有了这一优势,神经网络模型可以对更复杂的上下文进行建模,在词向量中包含更丰富的语义信息。
当你的任务的训练集相对较小时,词嵌入的作用最明显,所以它广泛用于NLP领域。我只提到一些,不要太担心这些术语(下问列举的一些NLP任务),它已经用在命名实体识别,用在文本摘要,用在文本解析、指代消解,这些都是非常标准的NLP任务。
词嵌入在语言模型、机器翻译领域用的少一些,尤其是你做语言模型或者机器翻译任务时,这些任务你有大量的数据。
统计语言模型statistical language model就是给你几个词,在这几个词出现的前提下来计算某个词出现的(事后)概率。
可以参考参考李沐的:https://zh-v2.d2l.ai/chapter_recurrent-neural-networks/language-models-and-dataset.html
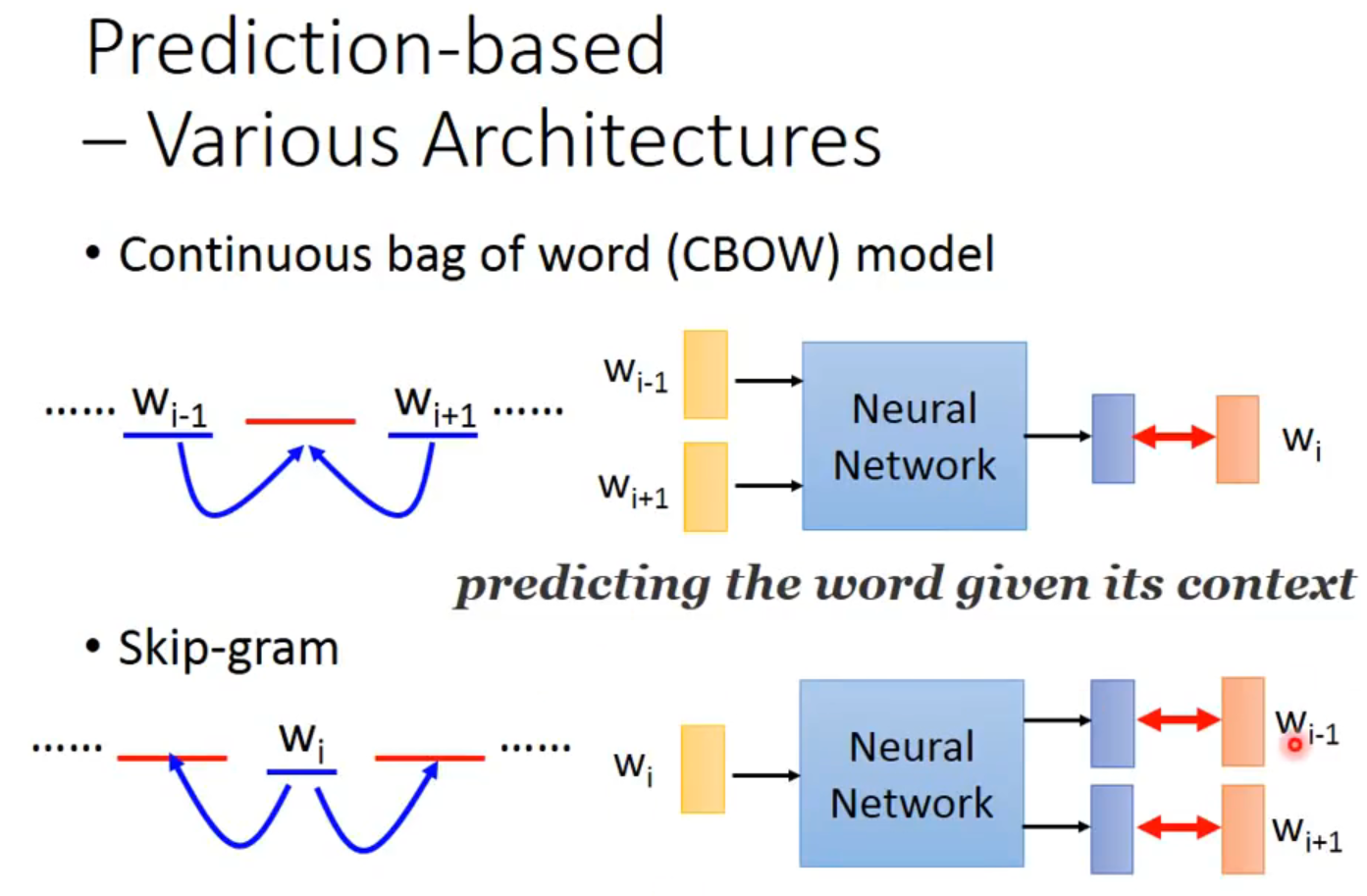
CBOW也是统计语言模型的一种,顾名思义就是根据某个词前面的C个词或者前后C个连续的词,来计算某个词出现的概率。Skip-Gram Model相反,是根据某个词,然后分别计算它前后出现某几个词的各个概率。
实现CBOW( Continuous Bagof-Words)和 Skip-gram 语言模型的工具正是word2vec!另外,C&W 模型的实现工具是SENNA。
NNLM 是怎么训练的?是输入一个单词的上文,去预测这个单词。这是有显著差异的。为什么 Word2Vec 这么处理?原因很简单,因为 Word2Vec 和 NNLM 不一样,NNLM 的主要任务是要学习一个解决语言模型任务的网络结构,语言模型就是要看到上文预测下文,而 word embedding 只是无心插柳的一个副产品。但是 Word2Vec 目标不一样,它单纯就是要 word embedding 的,这是主产品,所以它完全可以随性地这么去训练网络。
预训练过程(18年以前)
句子中每个单词以 Onehot 形式作为输入,然后乘以学好的 Word Embedding 矩阵 Q,就直接取出单词对应的 Word Embedding 了。那个 Word Embedding 矩阵 Q 其实就是网络 Onehot 层到 embedding 层映射的网络参数矩阵。
所以你看到了,使用 Word Embedding 等价于什么?等价于把 Onehot 层到 embedding 层的网络用预训练好的参数矩阵 Q 初始化了。这跟前面讲的图像领域的低层预训练过程其实是一样的,区别无非 Word Embedding 只能初始化第一层网络参数,再高层的参数就无能为力了。下游 NLP 任务在使用 Word Embedding 的时候也类似图像有两种做法:
- 一种是 Frozen,就是 Word Embedding 那层网络参数固定不动;
- 另外一种是 Fine-Tuning,就是 Word Embedding 这层参数使用新的训练集合训练也需要跟着训练过程更新掉。
ELMO
word embedding多义词问题。我们知道,多义词是自然语言中经常出现的现象,也是语言灵活性和高效性的一种体现。
在用语言模型训练的时候,不论什么上下文的句子经过 word2vec,都是预测相同的单词 bank,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的 word embedding 空间里去。所以 word embedding 无法区分多义词的不同语义,这就是它的一个比较严重的问题。
ELMO 提供了一种简洁优雅的解决方案。【论文:Deep contextualized word representation】
在此之前的 Word Embedding 本质上是个静态的方式,所谓静态指的是训练好之后每个单词的表达就固定住了
ELMO 的本质思想是:我事先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,在我实际使用 Word Embedding 的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以 ELMO 本身是个根据当前上下文对 Word Embedding 动态调整的思路。
ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的 LSTM 网络结构,而这两者后面都有用。
多义词问题解决了吗?解决了,而且比我们期待的解决得还要好。
对于 Glove 训练出的 Word Embedding 来说,多义词比如 play,根据它的 embedding 找出的最接近的其它单词大多数集中在体育领域,这很明显是因为训练数据中包含 play 的句子中体育领域的数量明显占优导致;而使用 ELMO,根据上下文动态调整后的 embedding 不仅能够找出对应的「演出」的相同语义的句子,而且还可以保证找出的句子中的 play 对应的词性也是相同的,这是超出期待之处。之所以会这样,是因为我们上面提到过,第一层 LSTM 编码了很多句法信息,这在这里起到了重要作用。
ELMO 有什么值得改进的缺点呢?首先,一个非常明显的缺点在特征抽取器选择方面,ELMO 使用了 LSTM 而不是新贵 Transformer
GPT
把 ELMO 这种预训练方法和图像领域的预训练方法对比,发现两者模式看上去还是有很大差异的。除了以 ELMO 为代表的这种基于特征融合的预训练方法外,NLP 里还有一种典型做法,这种做法和图像领域的方式就是看上去一致的了,一般将这种方法称为“基于 Fine-tuning 的模式”,而 GPT 就是这一模式的典型开创者。
GPT 也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过 Fine-tuning 的模式解决下游任务。
区别于ELMO,预训练使用Transformer作为特征抽取器,并且只用上文,不用下文(很吃亏,这限制了其在更多应用场景的效果)对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向 GPT 的网络结构看齐,把任务的网络结构改造成和 GPT 的网络结构是一样的。然后,在做下游任务的时候,利用第一步预训练好的参数初始化 GPT 的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了
GPT 论文给了一个改造施工图。
GPT 的效果是非常令人惊艳的,在 12 个任务里,9 个达到了最好的效果,有些任务性能提升非常明显。
那么站在现在的时间节点看,GPT 有什么值得改进的地方呢?其实最主要的就是那个单向语言模型,如果改造成双向的语言模型任务估计也没有 Bert 太多事了。当然,即使如此 GPT 也是非常非常好的一个工作,跟 Bert 比,其作者炒作能力亟待提升。
BERT
Bert 采用和 GPT 完全相同的两阶段模型,首先是语言模型预训练;其次是使用 Fine-Tuning 模式解决下游任务。和 GPT 的最主要不同在于在预训练阶段采用了类似 ELMO 的双向语言模型,当然另外一点是语言模型的数据规模要比 GPT 大。所以这里 Bert 的预训练过程不必多讲了。
在改造任务方面 Bert 和 GPT 有些不同
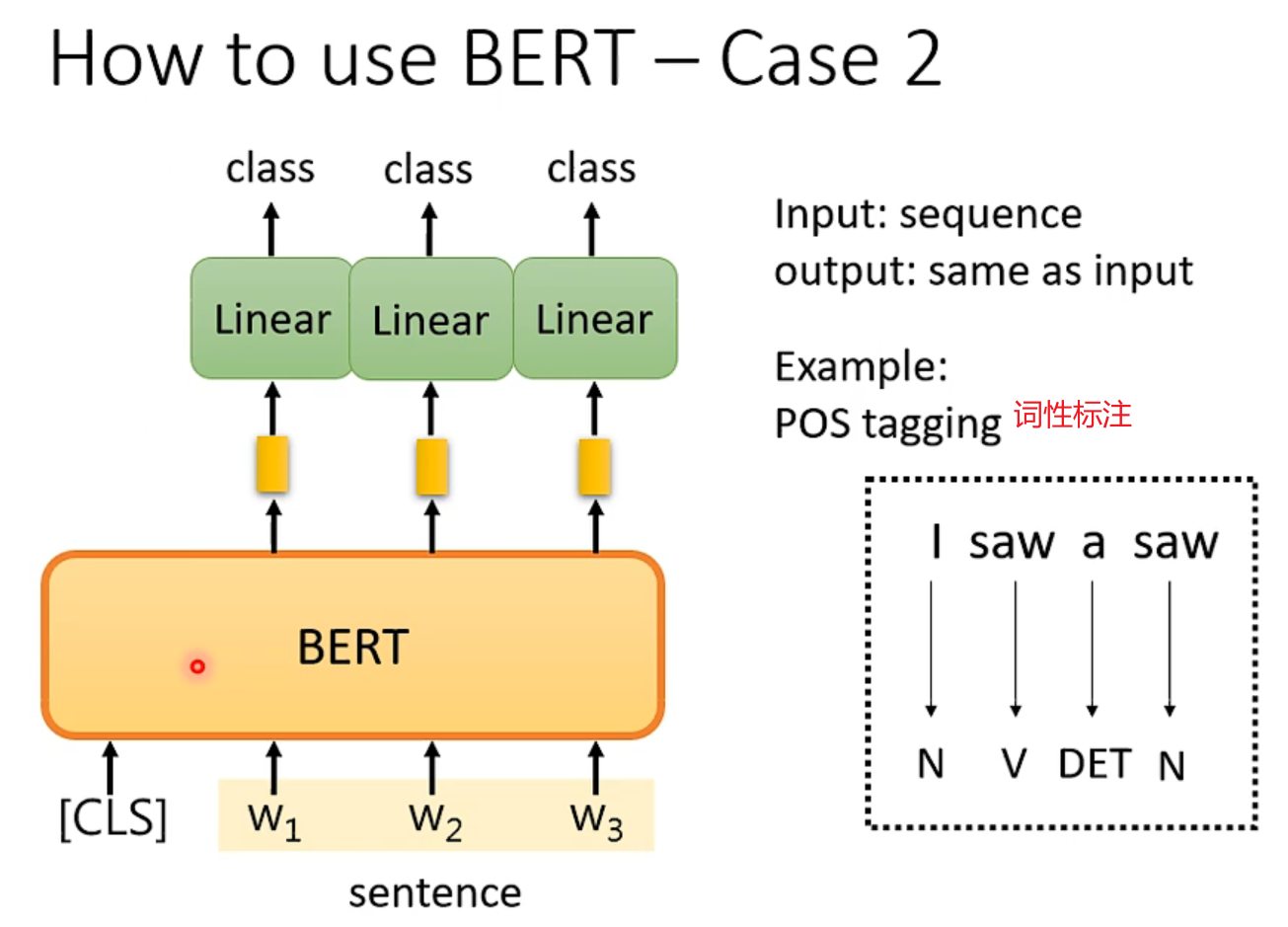
先大致说下 NLP 的几类问题,以强调 Bert 的普适性有多强。通常而言,绝大部分 NLP 问题可以归入上图所示的四类任务中:
- 一类是序列标注,这是最典型的 NLP 任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
- 第二类是分类任务,比如我们常见的文本分类,情感计算等都可以归入这一类。它的特点是不管文章有多长,总体给出一个分类类别即可。
- 第三类任务是句子关系判断,比如 Entailment,QA,语义改写,自然语言推理等任务都是这个模式,它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系。
- 第四类是生成式任务,比如机器翻译,文本摘要,写诗造句,看图说话等都属于这一类。它的特点是输入文本内容后,需要自主生成另外一段文字。
作者言:
所以说 Bert 的模型没什么大的创新,更像最近几年 NLP 重要进展的集大成者,这点如果你看懂了上文估计也没有太大异议,如果归纳一下这些进展就是:
- 首先是两阶段模型,第一阶段双向语言模型预训练,这里注意要用双向而不是单向,第二阶段采用具体任务 Fine-tuning 或者做特征集成;
- 第二是特征抽取要用 Transformer 作为特征提取器而不是 RNN 或者 CNN;
- 第三,双向语言模型可以采取 CBOW 的方法去做(当然我觉得这个是个细节问题,不算太关键,前两个因素比较关键)。
Bert 最大的亮点在于效果好及普适性强,几乎所有 NLP 任务都可以套用 Bert 这种两阶段解决思路,而且效果应该会有明显提升。可以预见的是,未来一段时间在 NLP 应用领域,Transformer 将占据主导地位,而且这种两阶段预训练方法也会主导各种应用。
wordembedding
Count-based方法:比如Glove
Prediction-based:
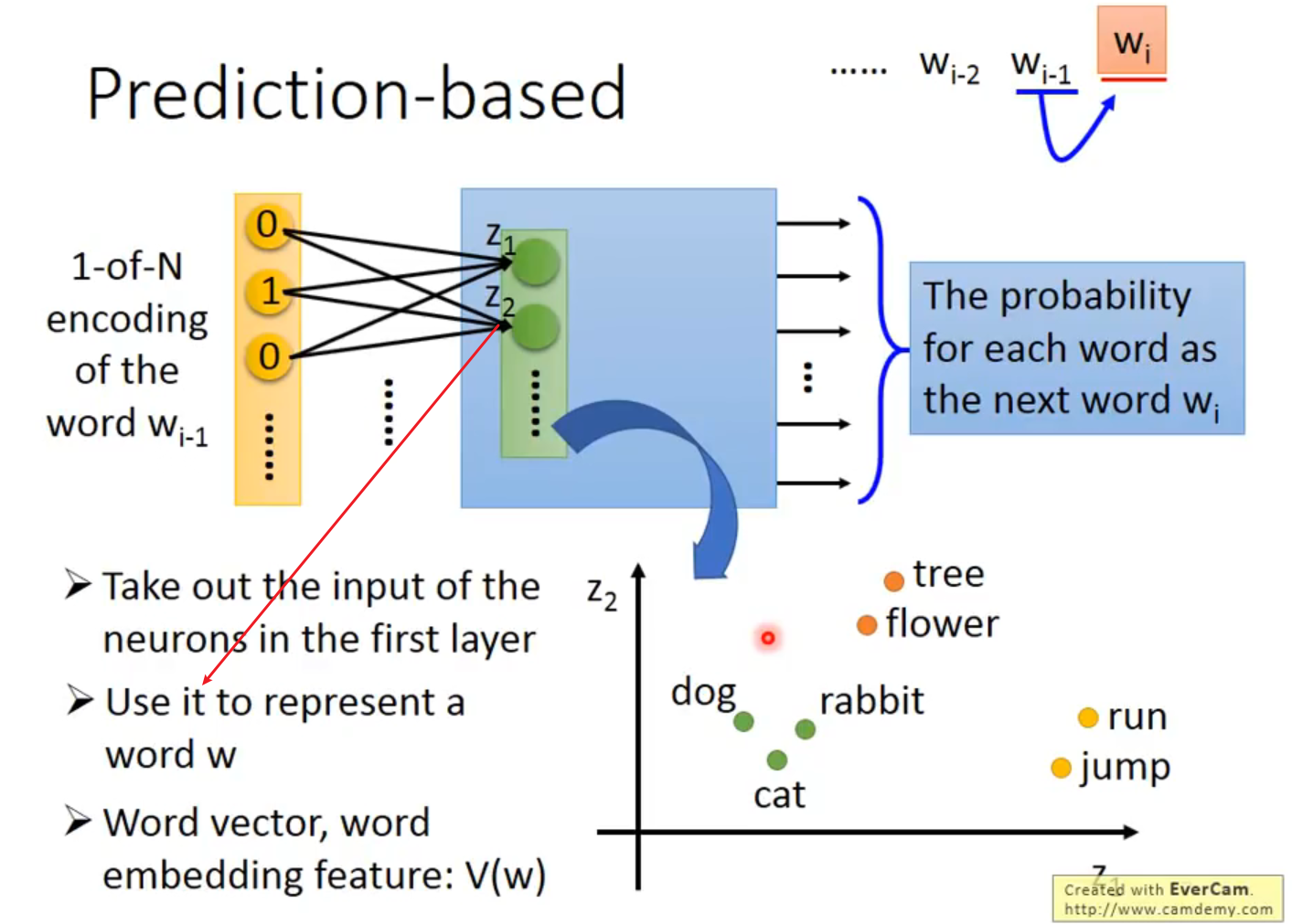
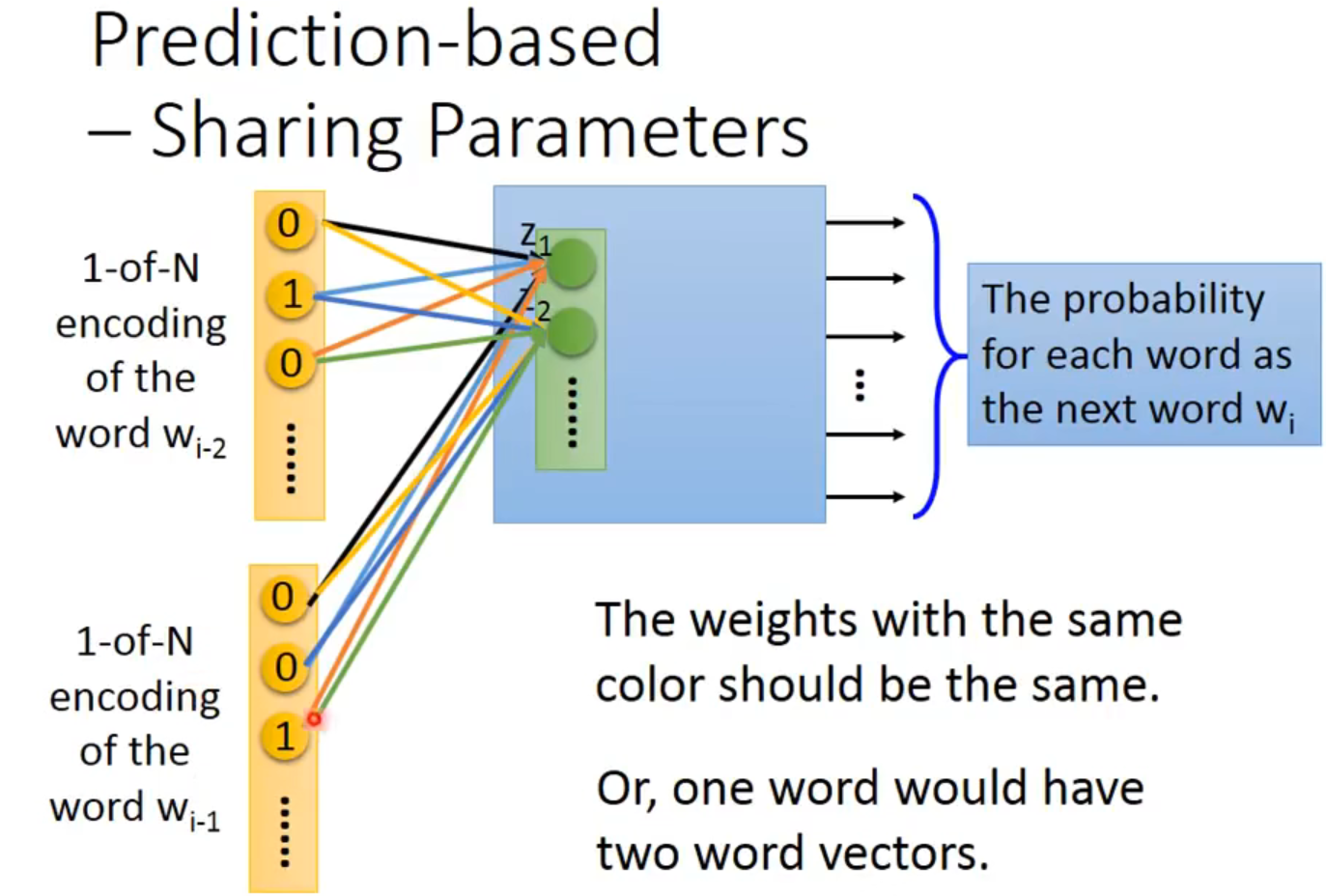
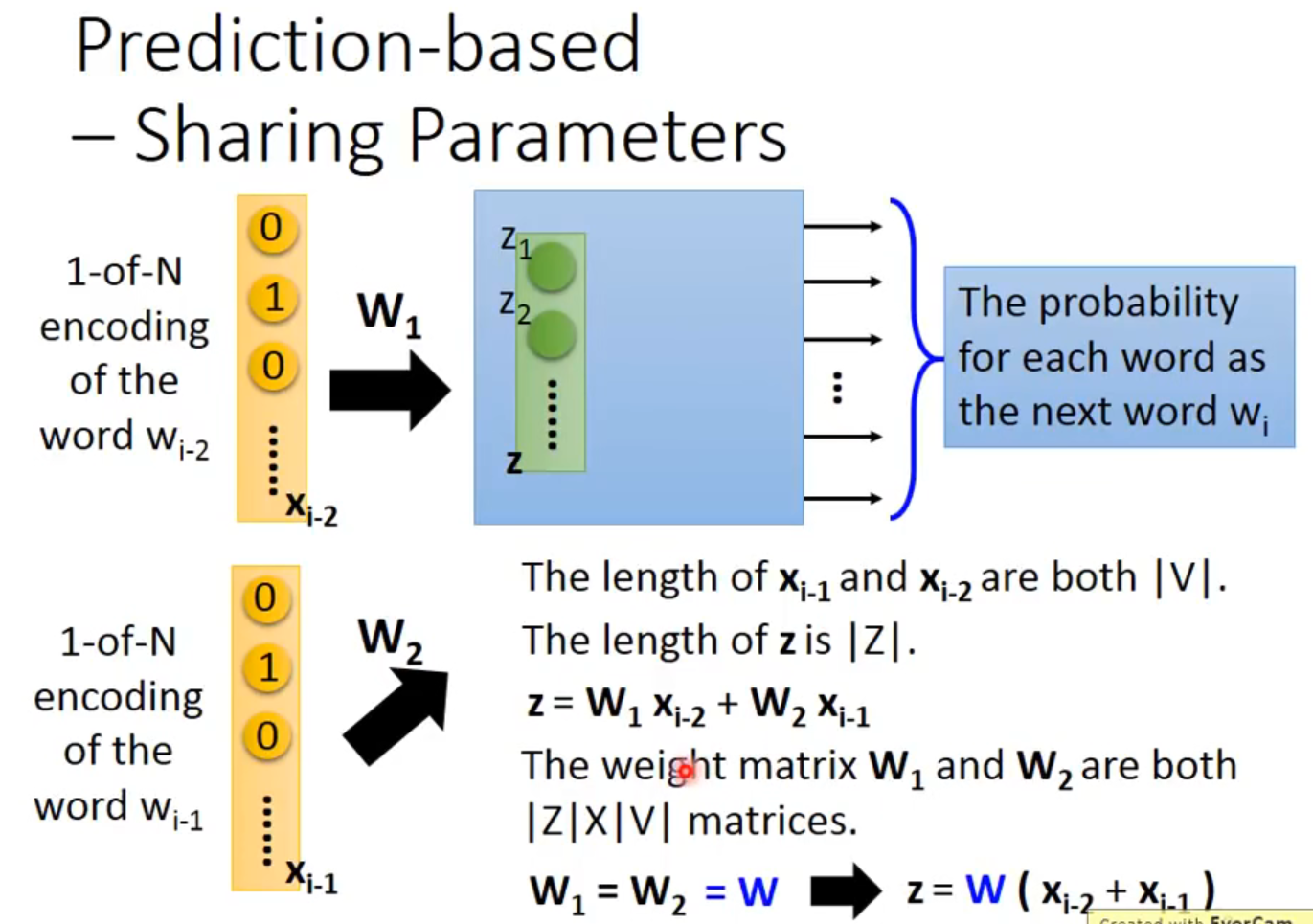
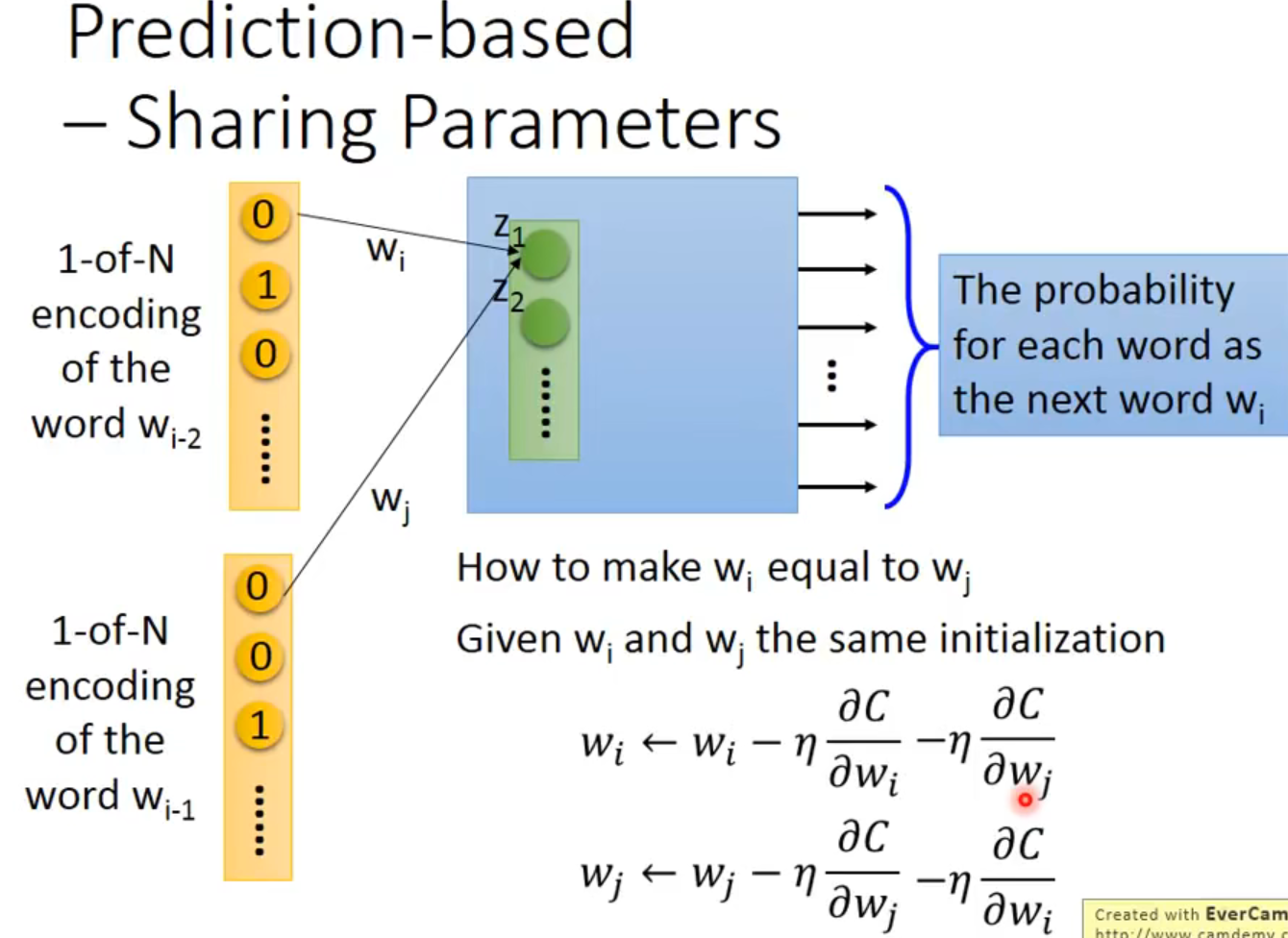
可以拓展这个model到n个词汇,比如第二幅图就是词,但是weight要相等【我不能理解,这忽略了部分时序吧】
有种种变形,难说哪种比较好,不同的test上互有胜负,包括了CBOW、Skip-gram。
Interpretability
why deep
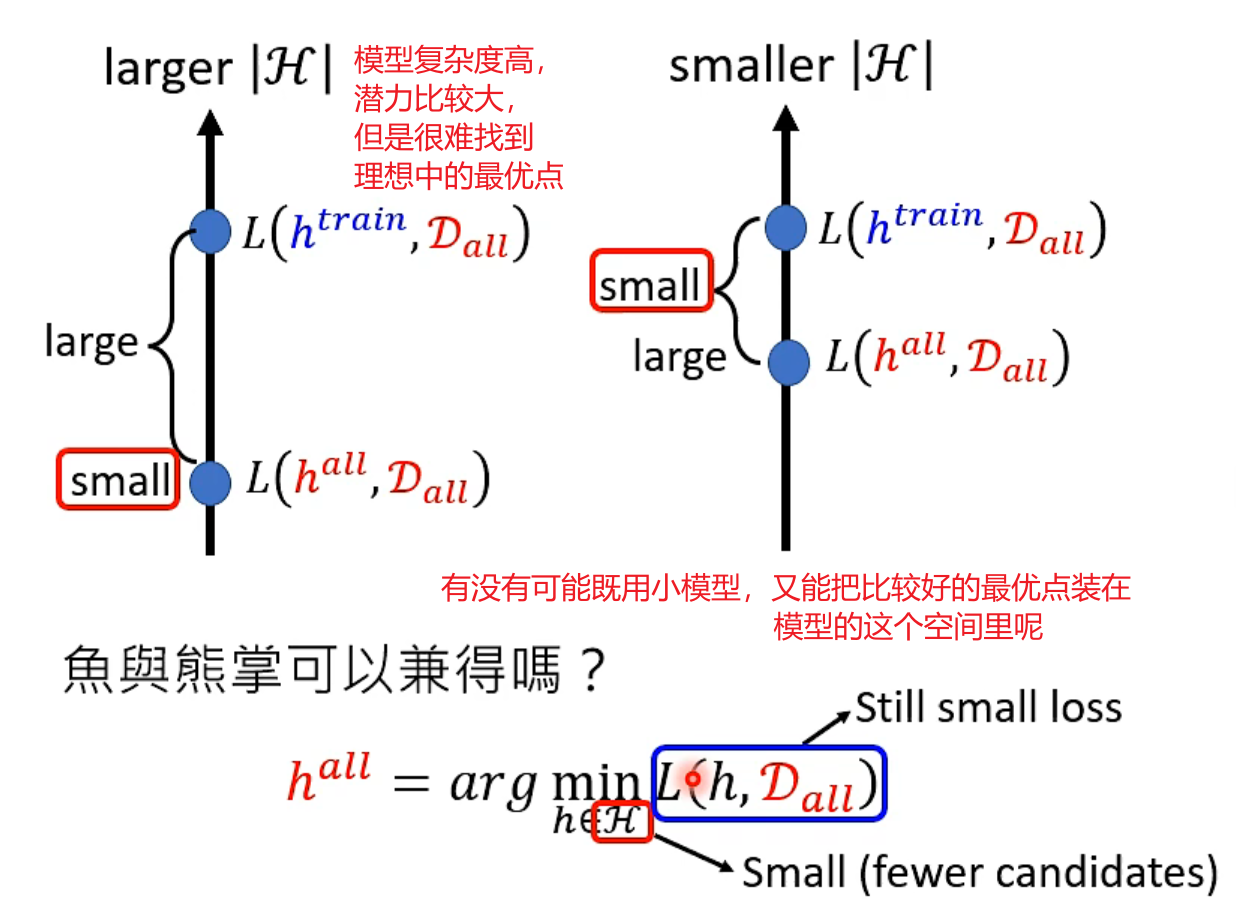
更多的数据可以让你更接近理论上限(上限由你的模型决定,模型越复杂,越有可能包含更高的上限)
理论上一个“够胖的”的hidden layer就能做任何事情。研究发现,参数量相同时👇
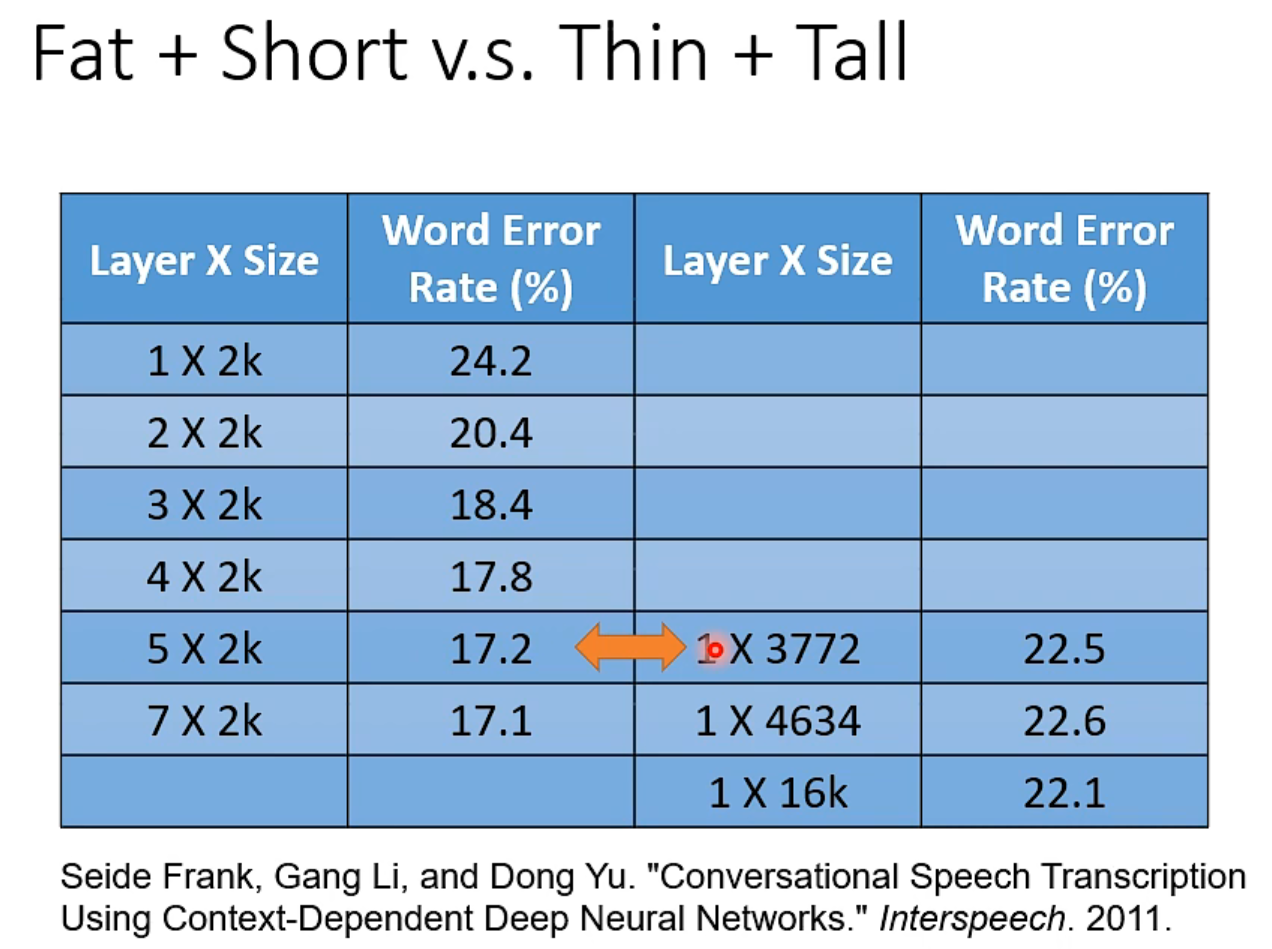
WHY?
因为数学上,要拟合一个复杂function,用高瘦的network,需要参数比较少(毕竟指数增长和线性增长。)
而比较少的参数意味着不容易overfitting,需要更少的训练资料。
直观理解:
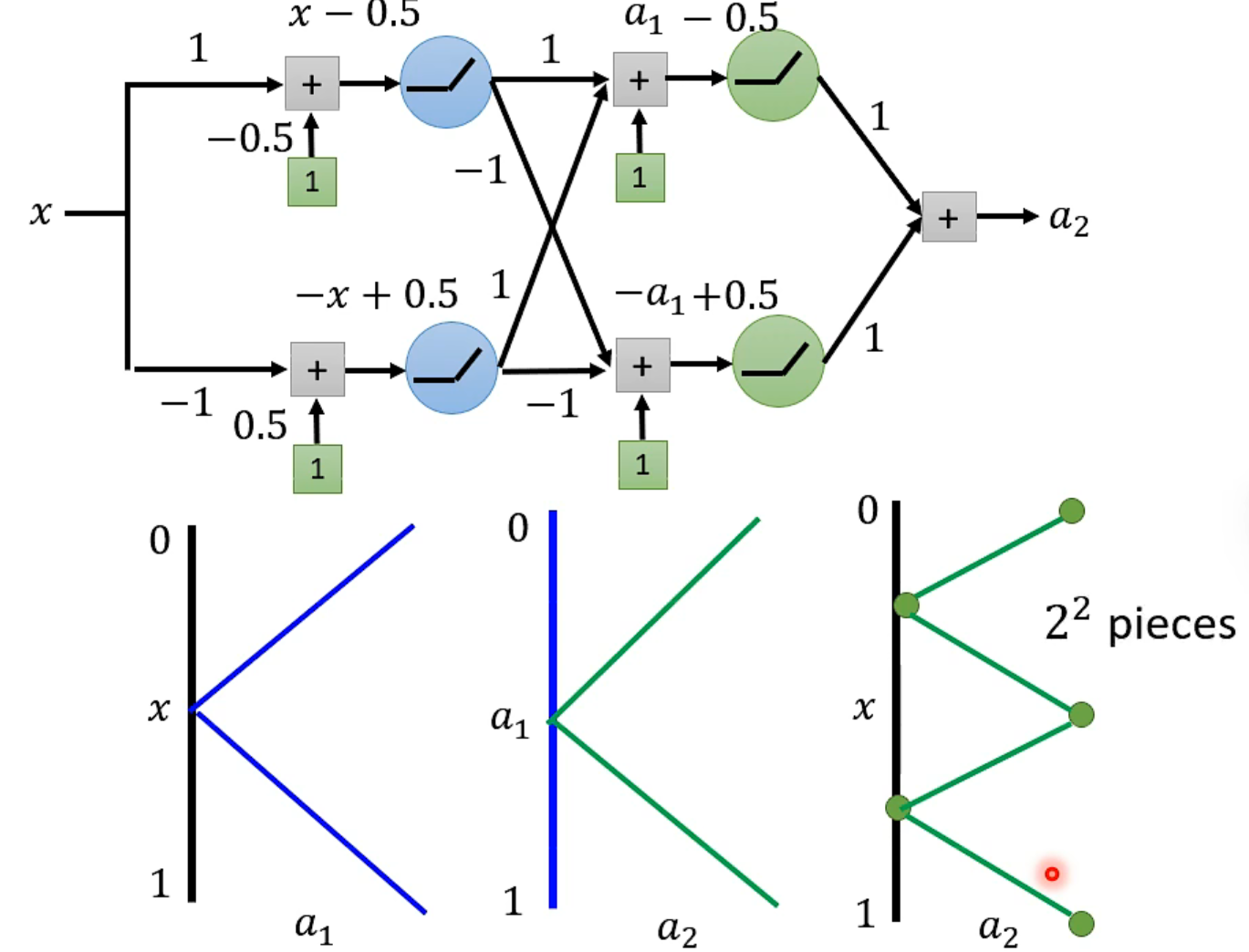
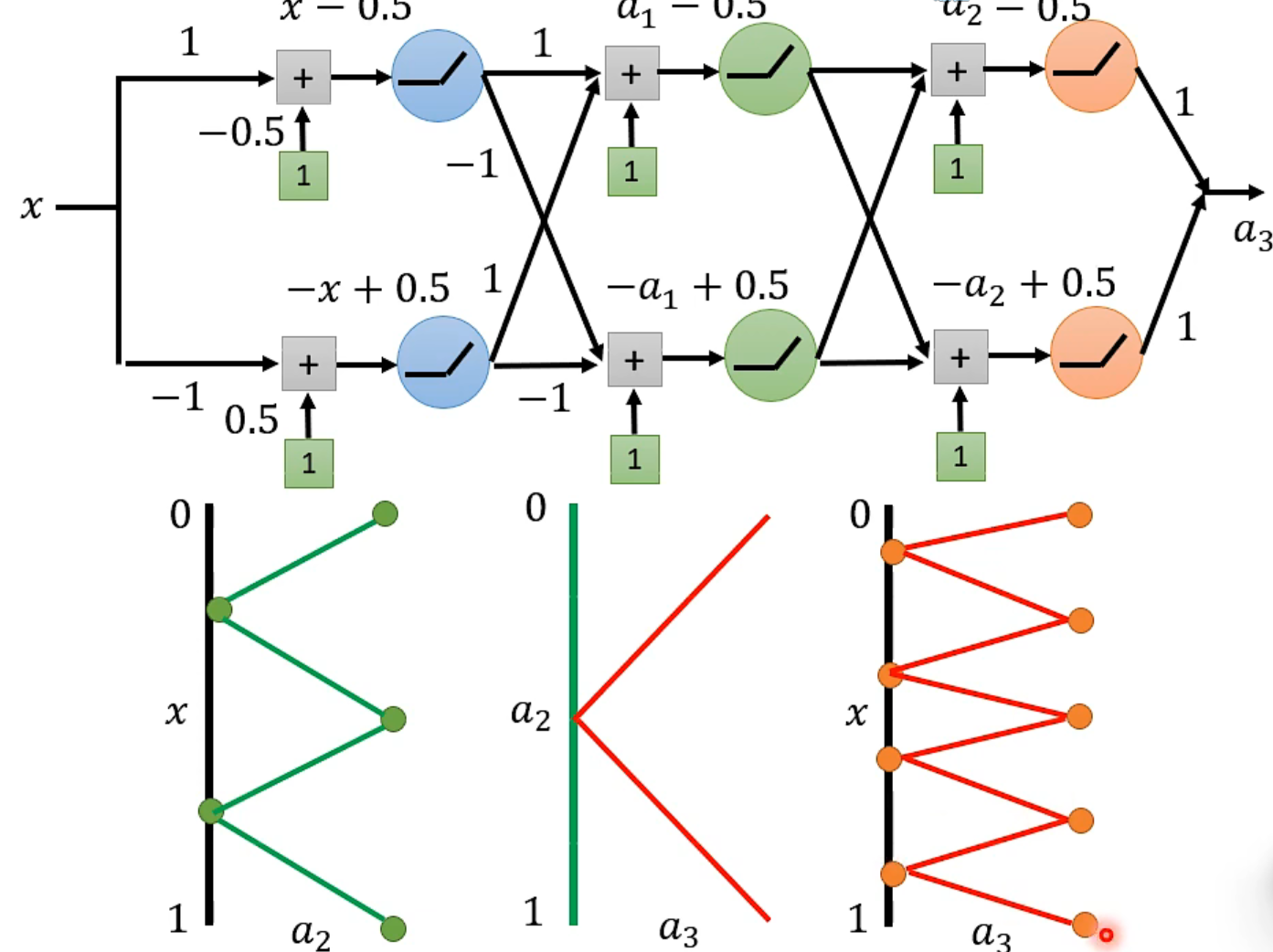
就是线性增长咯。👆
Tricks
Why Deep
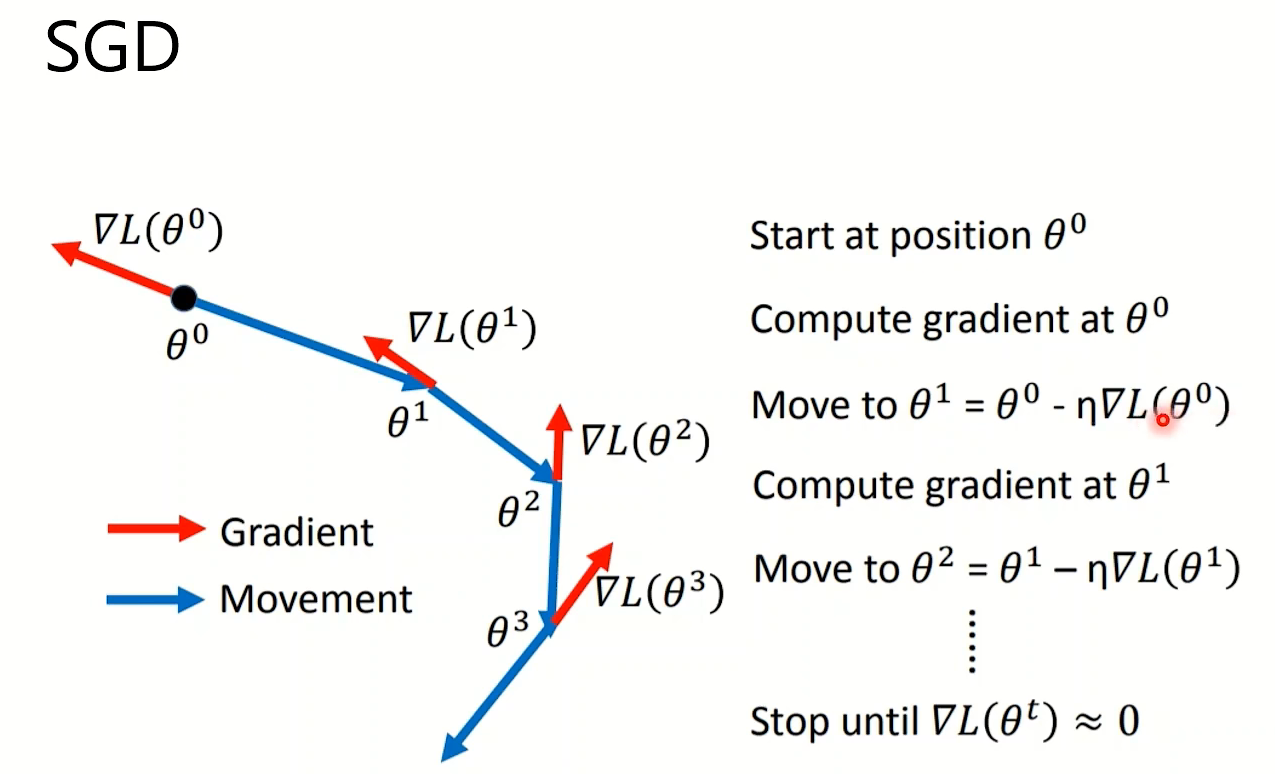
优化器
之所以不叫优化算法是因为,略过了数学证明:(即某些优化算法理论的精度上下限之类的),只关注深度学习的应用。
但是其实,由于deep learning的复杂性,不管你理论有多强的gurantee,都是不够用的
复习
SGD、SGD with momentum、Adagrad、RMSProp、Adam
基本概念:
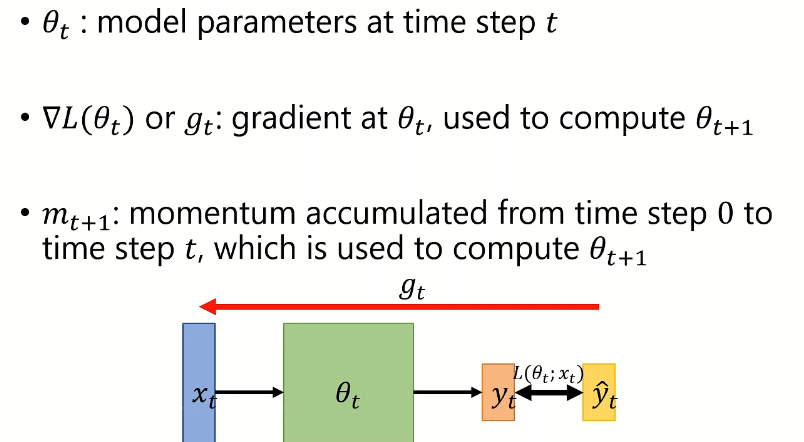
on-line:每次只能看到当前时间步的数据(x,y)
off-line:每次能看到整个数据集(本节假设为off-line),实际过程中会受到内存的限制。
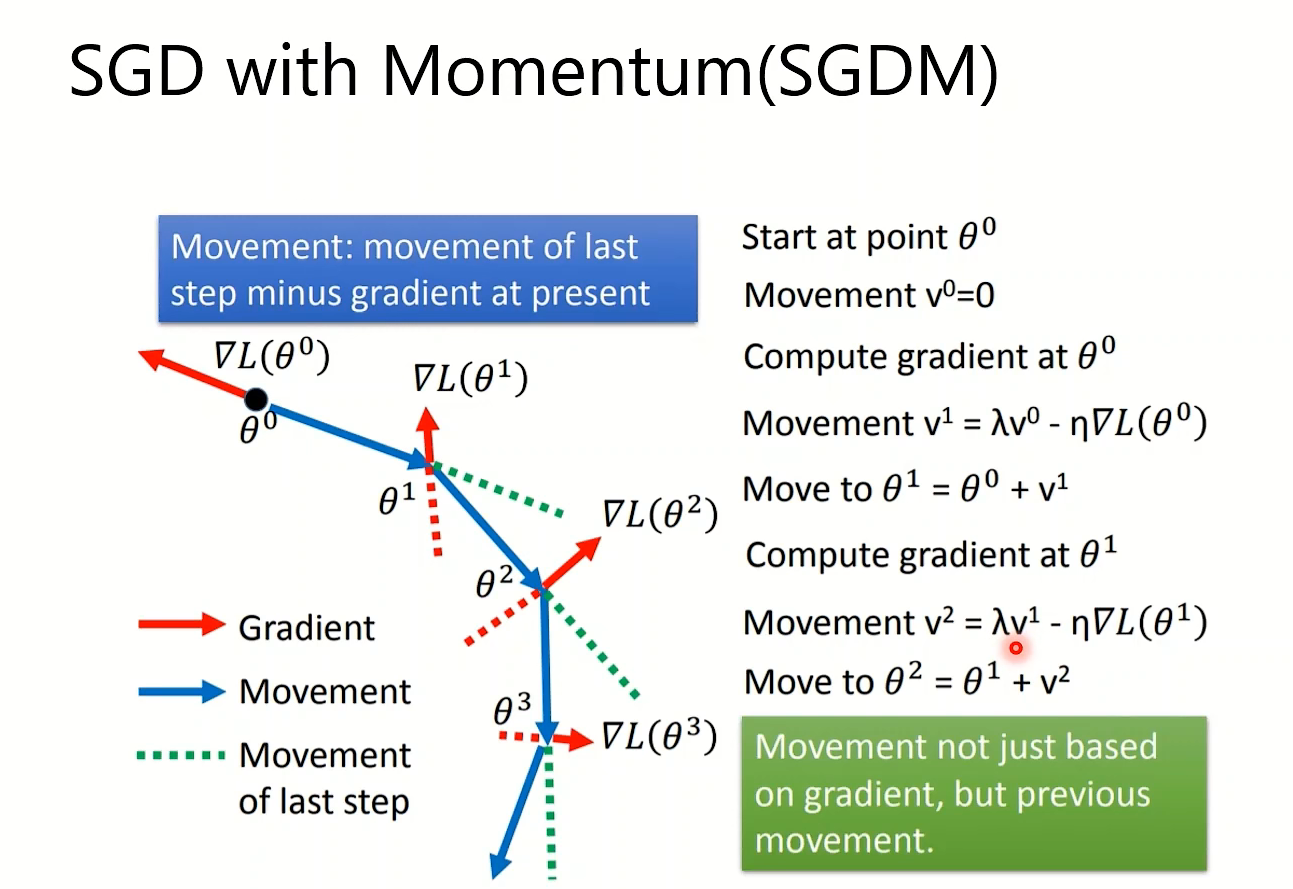
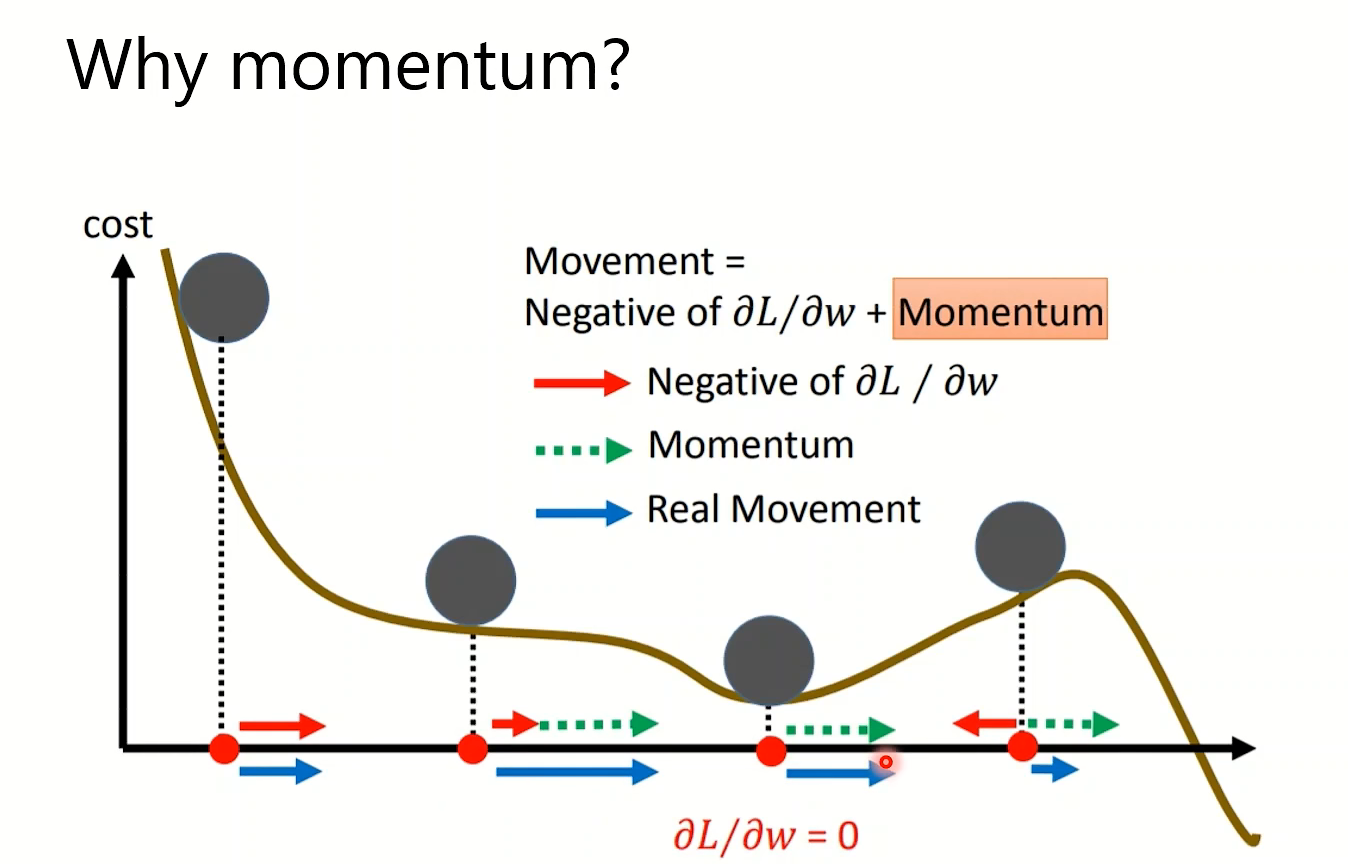
SGDM在局部最小处,不会卡在那个点,而是继续动,就像多出了动量一样(但是可能会累积而使得learning-rate爆炸)
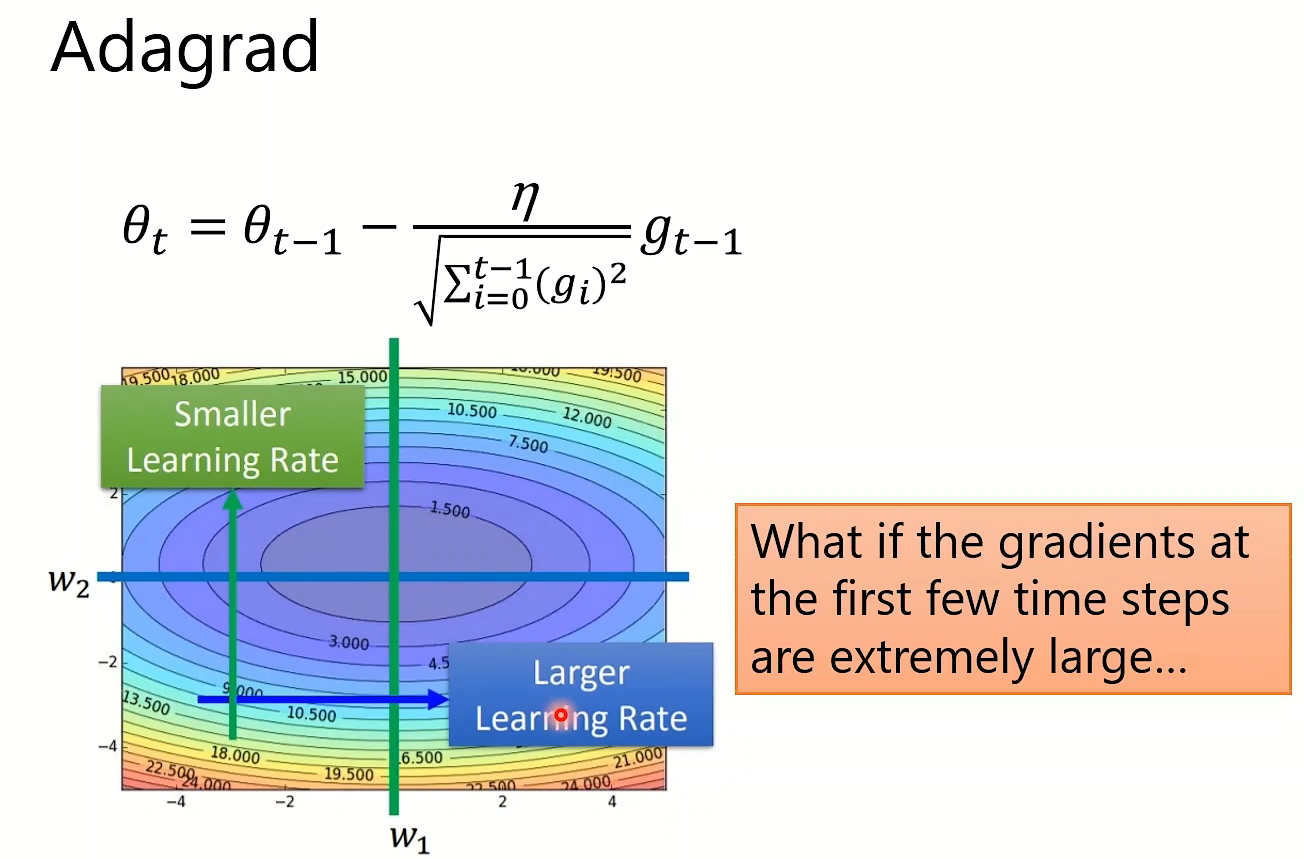
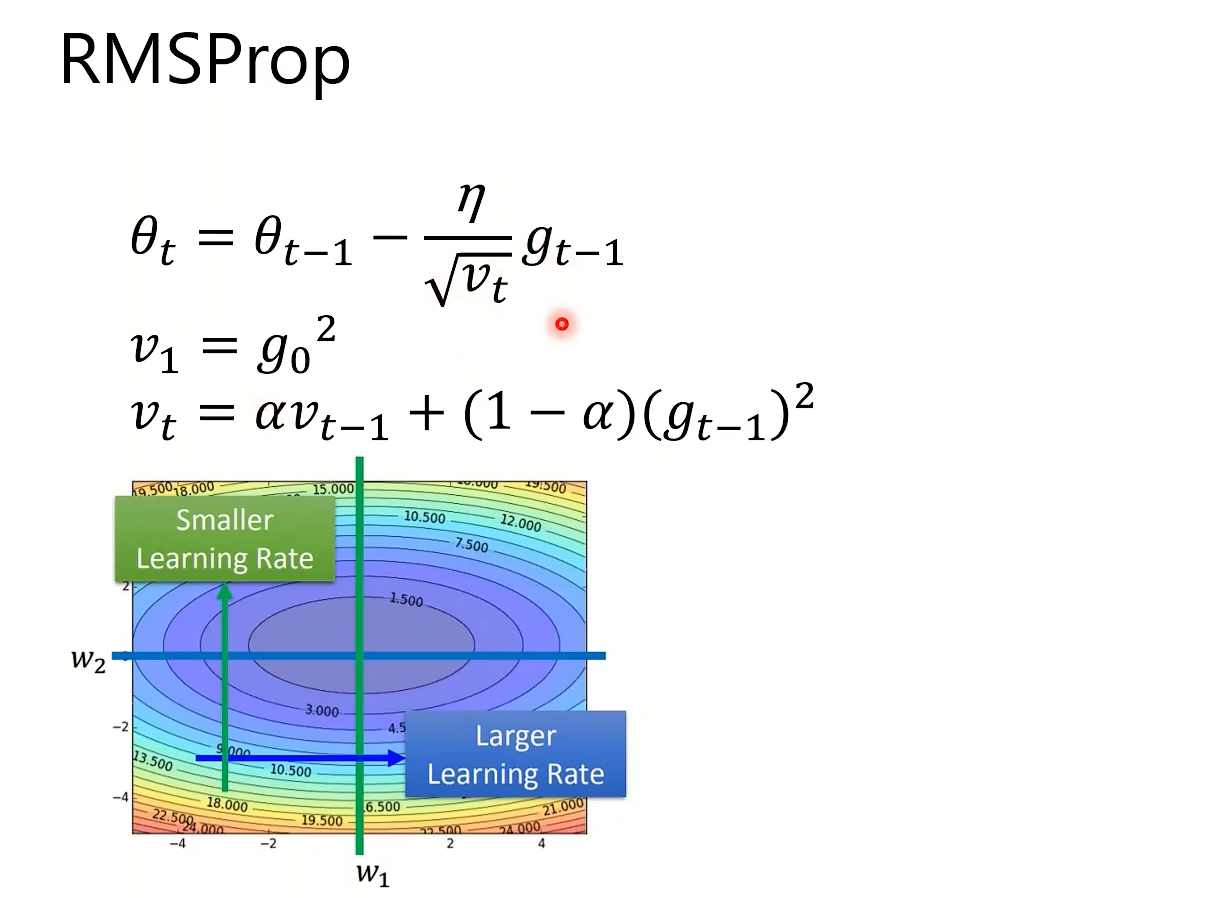
Adsgrad思路是放缓下降太快的方向,增大平缓方向的学习率。但是其分母会无止境地累加,而RMSProp确保不会因为累积过多而卡住,但是它也有卡在局部最小点的问题。
Adam算法则结合了以上两者:($m_t$一开始比较小,分母调节其大小)


折几个经典的optimizer都是2014年左右提出来的,到底出了什么问题
BERT Transformer Tacotron(语音生成)Big-GAN(生物生成)MEMO演算法(寻找通式,提取共同信息) 【Adam】
YOLO Mask R-CNN 【SGDM】
新的分析
这位助教老师自己分析:因为Adam和SGD直接抢到了两个极端的位置(来自某次实验):
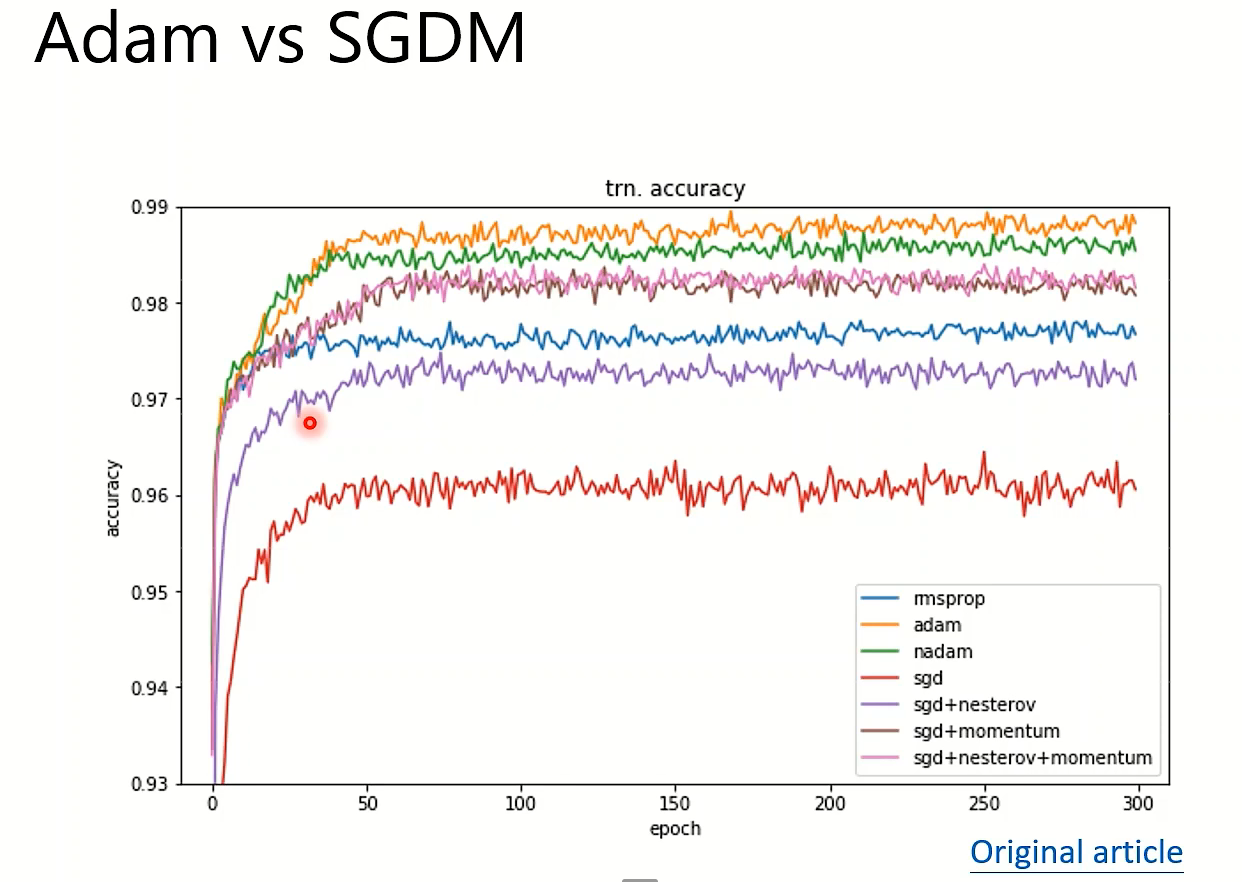
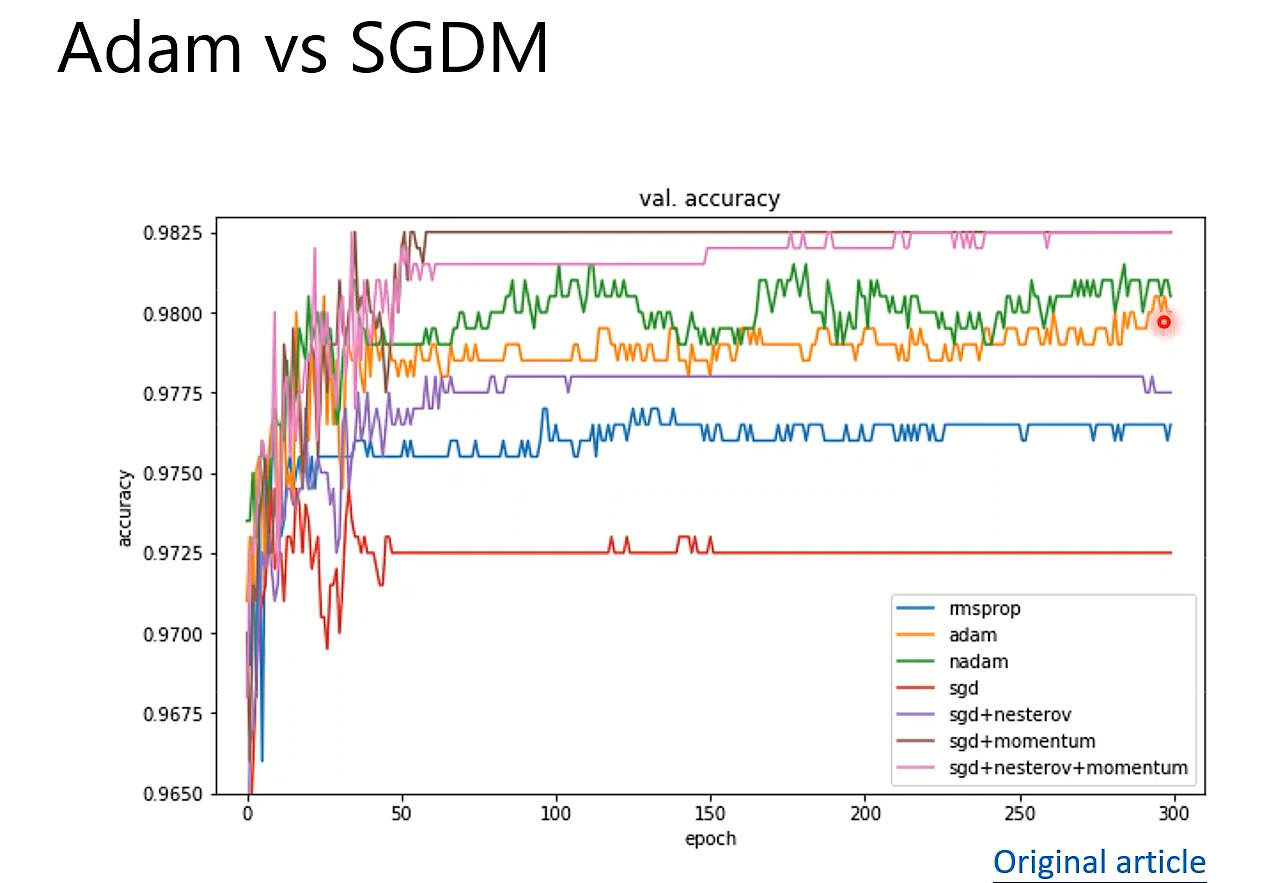
Adam: fast training, large generalization gap, unstable 快
SGDM: stable, little generation gap, better convergence 稳
SWATS:先做Adam再做SGD
AMSGrad:有意义的方向更新被限制了大小,大的步长被限制成较小的值,无法起到好作用。作者的想法是减少无用而且小的gradient造成的影响。(但是还是有learning-rate变小的问题)

还有AdaBound,助教说十分粗鲁,失去了数学的优雅,太工业了。
还有很多种比如SGDR、One-cycle LR一堆堆。总之有许多新奇的思路
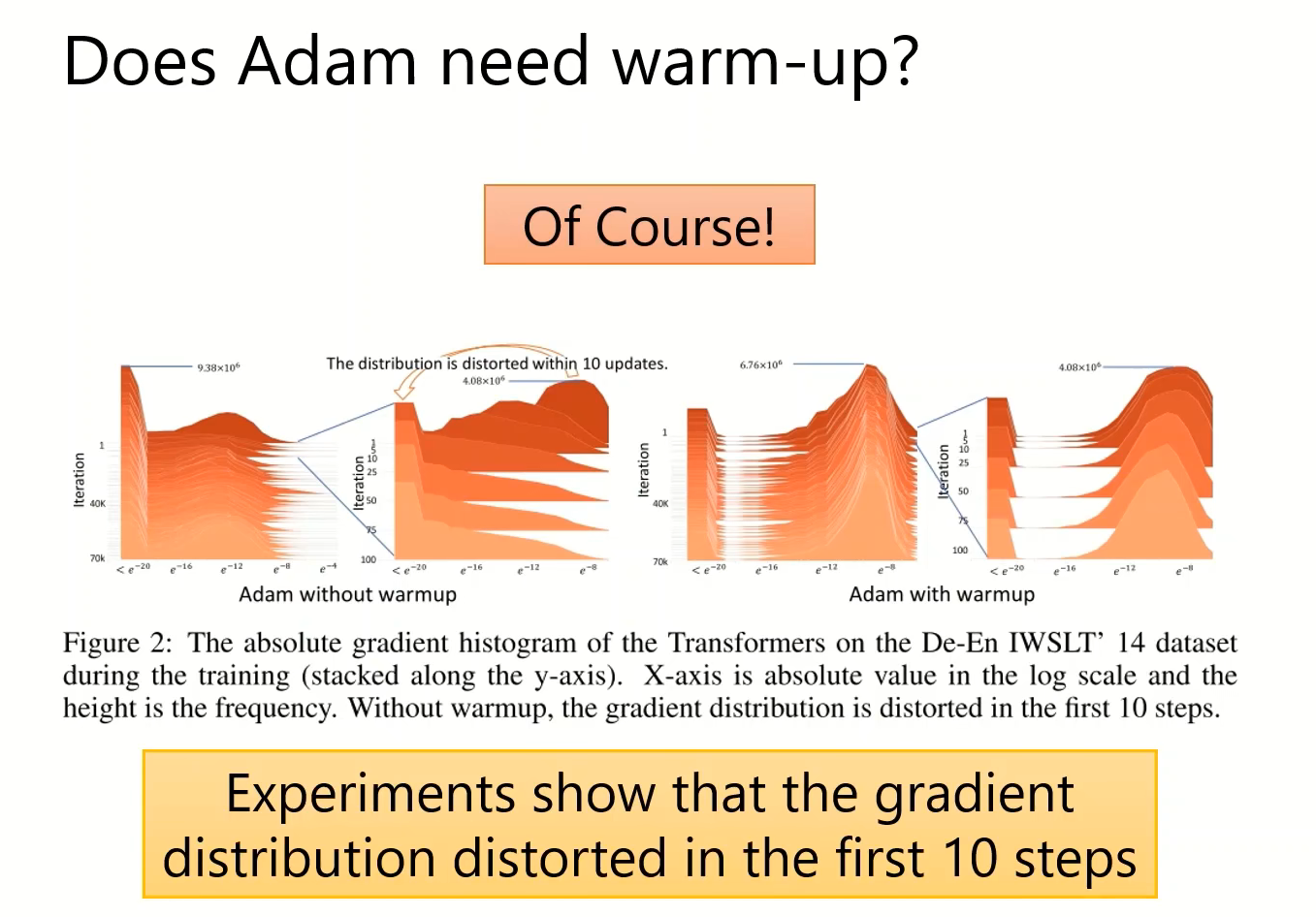
Adam最开始的步骤里,即使分母有稳定数值,但是意义上是随机的,也会使其混乱。
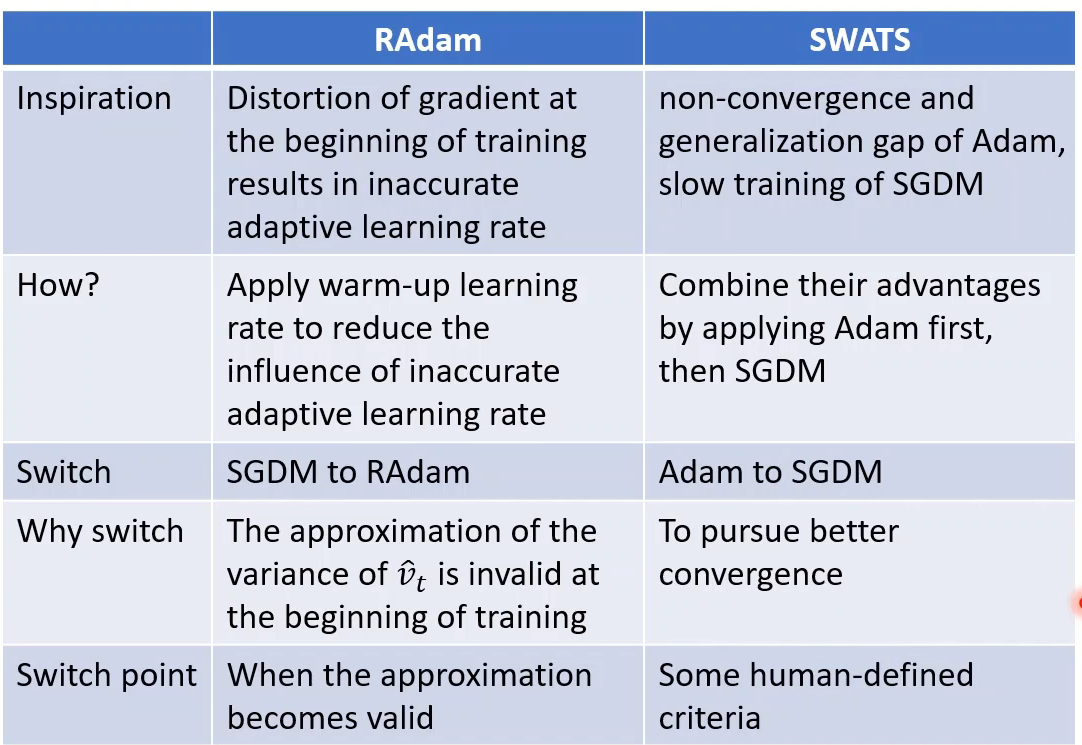
更新的
Hinton团队的一个work,和MEML演算法(原学习)的Reptile很像。
希望你走到比较平坦的地方,避免走进太崎岖的的地方然后accuracy掉下去

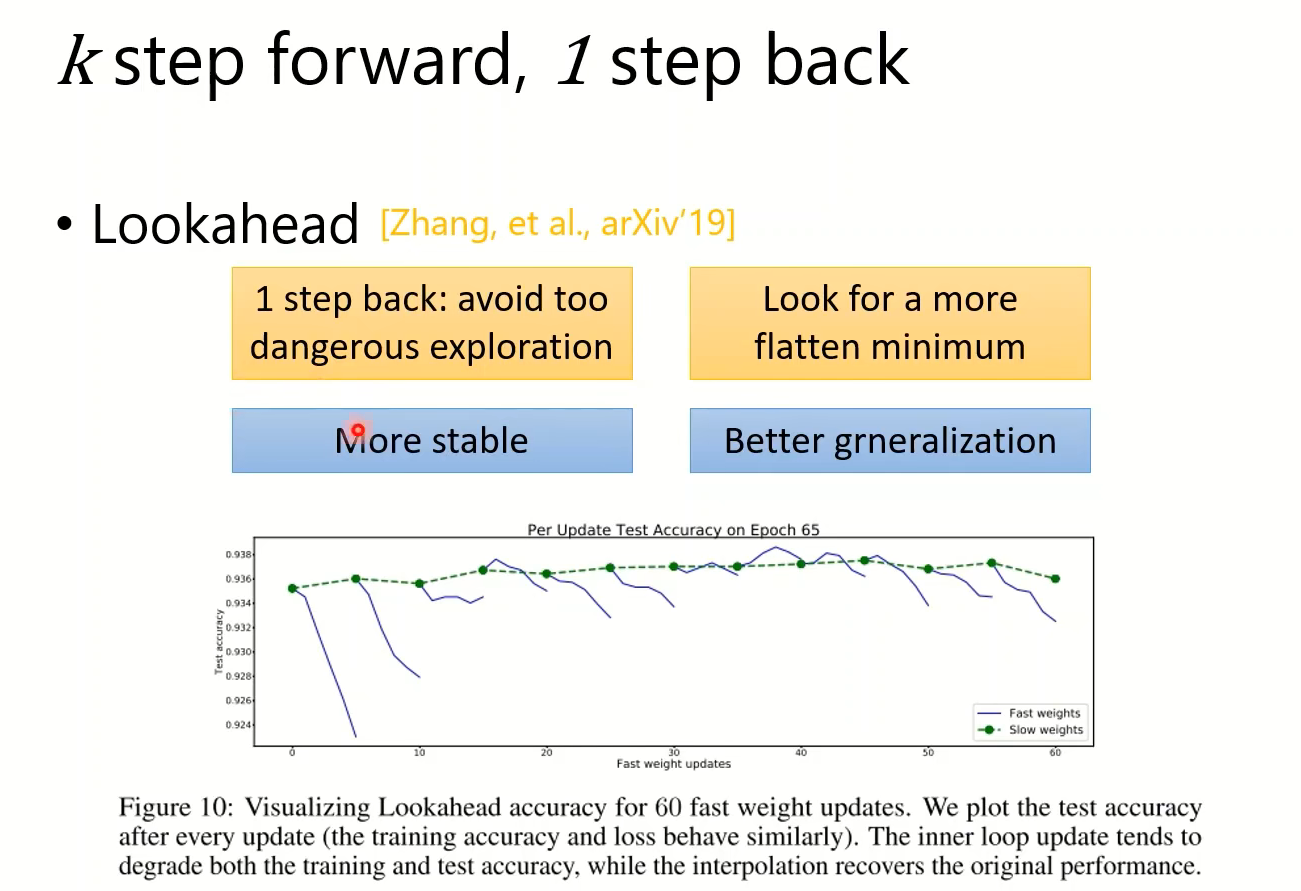
能不能看到未来,避免走到太差的点:NAG(通过数学手段免除两倍内存消耗。)【以后可以回来看】

对优化器的一些讨论
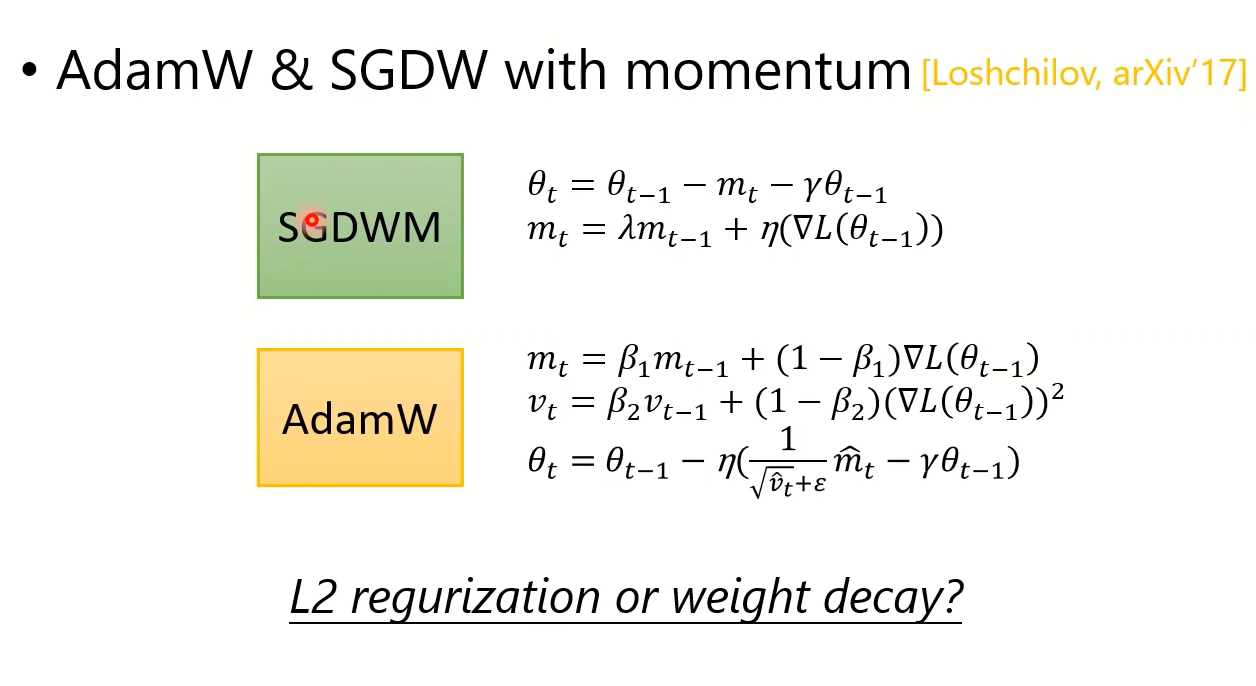
L2正则化时,正则化项要不要出现在动量的表达式中呢!
这个东西没有标准答案,但有人提出不加更好,也就是有实际价值的SGDWM和AdamW
这两者被用于NLP,BERT系列之类的。

这几个技术其实都是在做一件事,就是鼓励你的探索,增加随机性。


curriculum的思路是:一开始的训练决定大方向,先找到一个比较好的local minimum,再接着用难数据找比较好的点,这样就不会掉到太狭窄的山谷里。

==总结==:优化器



有必要指出,优化器的选择只不过是在你其他地方没有问题的基础上improve一些,架构、训练技巧、脏数据都是帮不了你的。
Attention
自注意力
自注意力
引入:原本的输入都是一个长度已经定义好的向量,那么如何处理 一个长度不一的向量序列(他的顺序和沐神似乎不太一样)
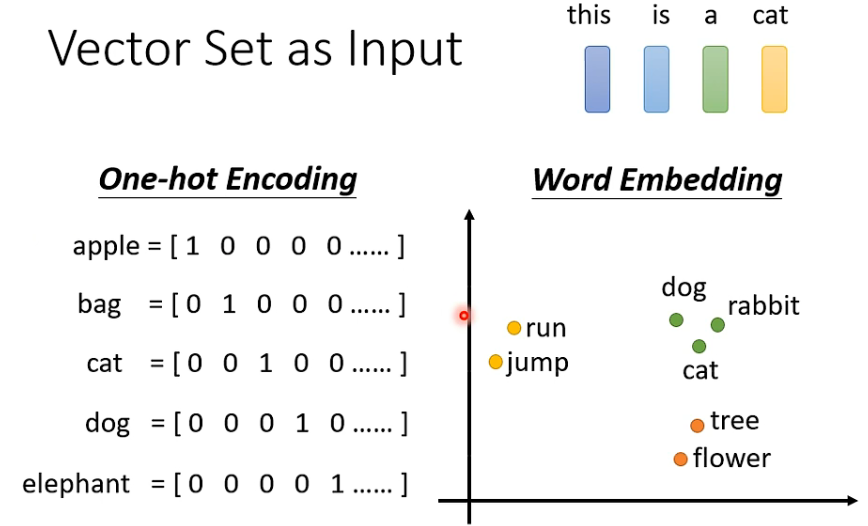
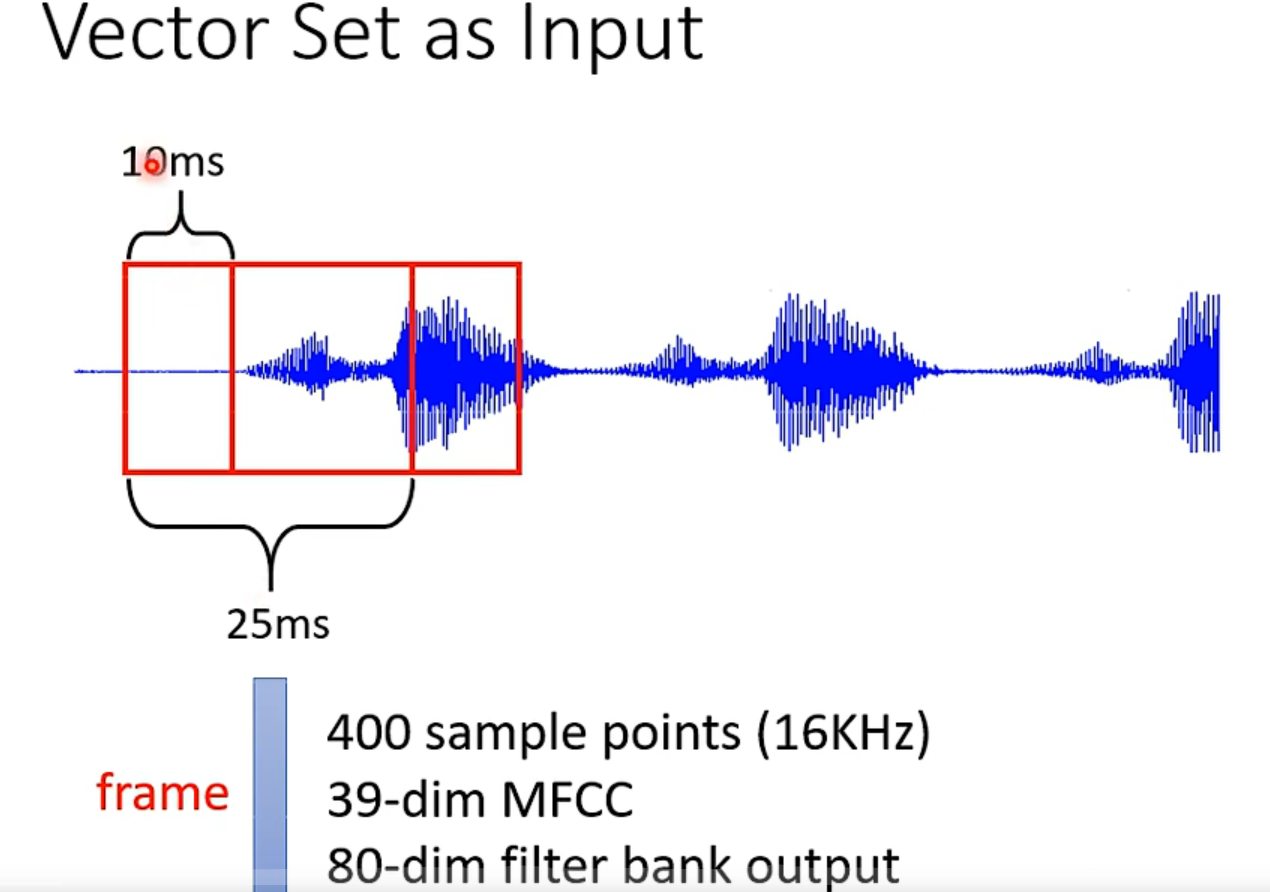
独热码并没有关心向量之间的关系和联系,word embedding解决了这个问题。👆还有对声音的处理。
输出大致有三种可能性:
- 每个vector被model赋予一个label(输入和输出数目一样)
- 一整个seq输入,只得到一个输出,比如情感分析positive和negative
- 输出是不确定的,由model自己决定【seq2seq】
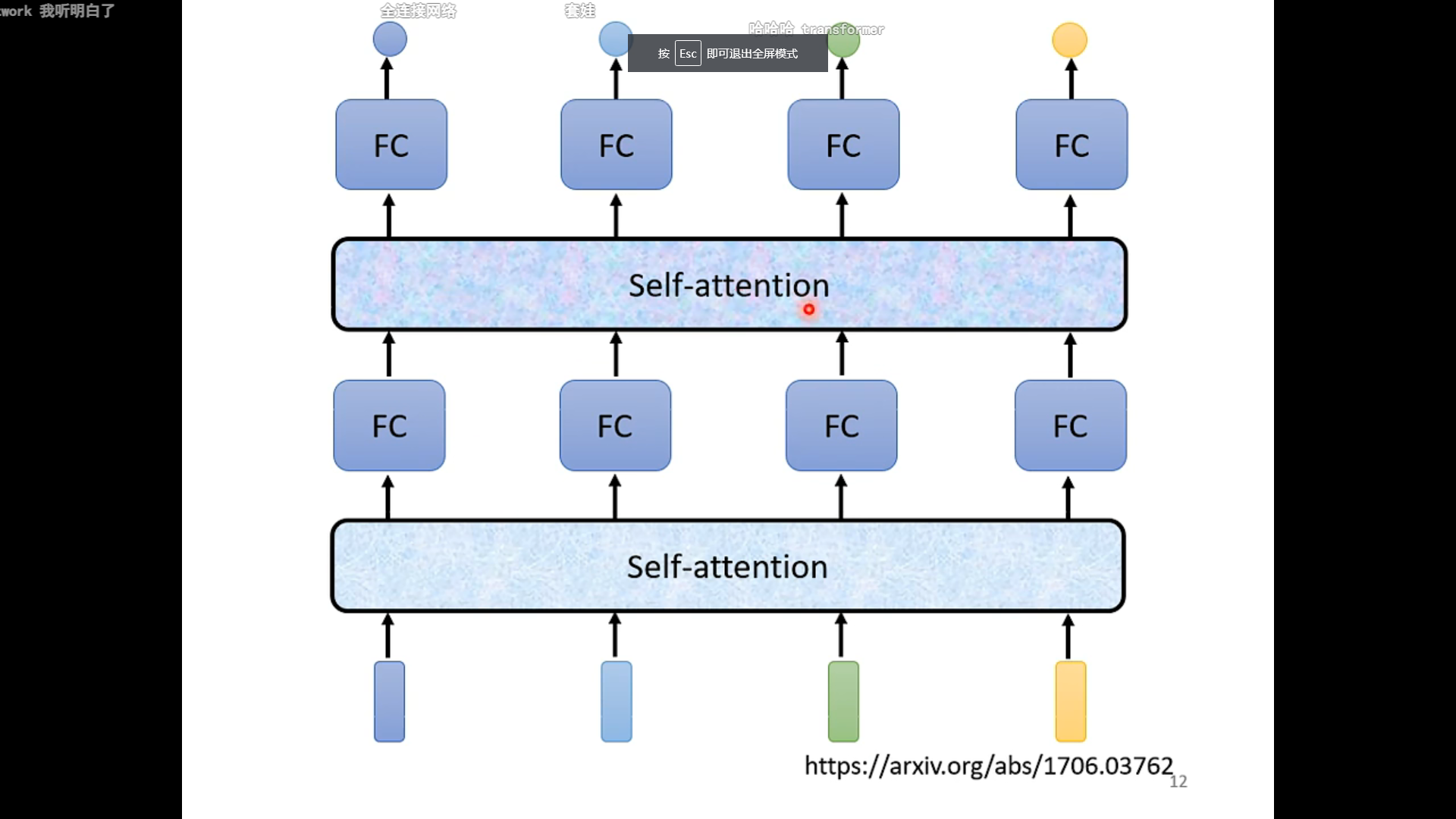
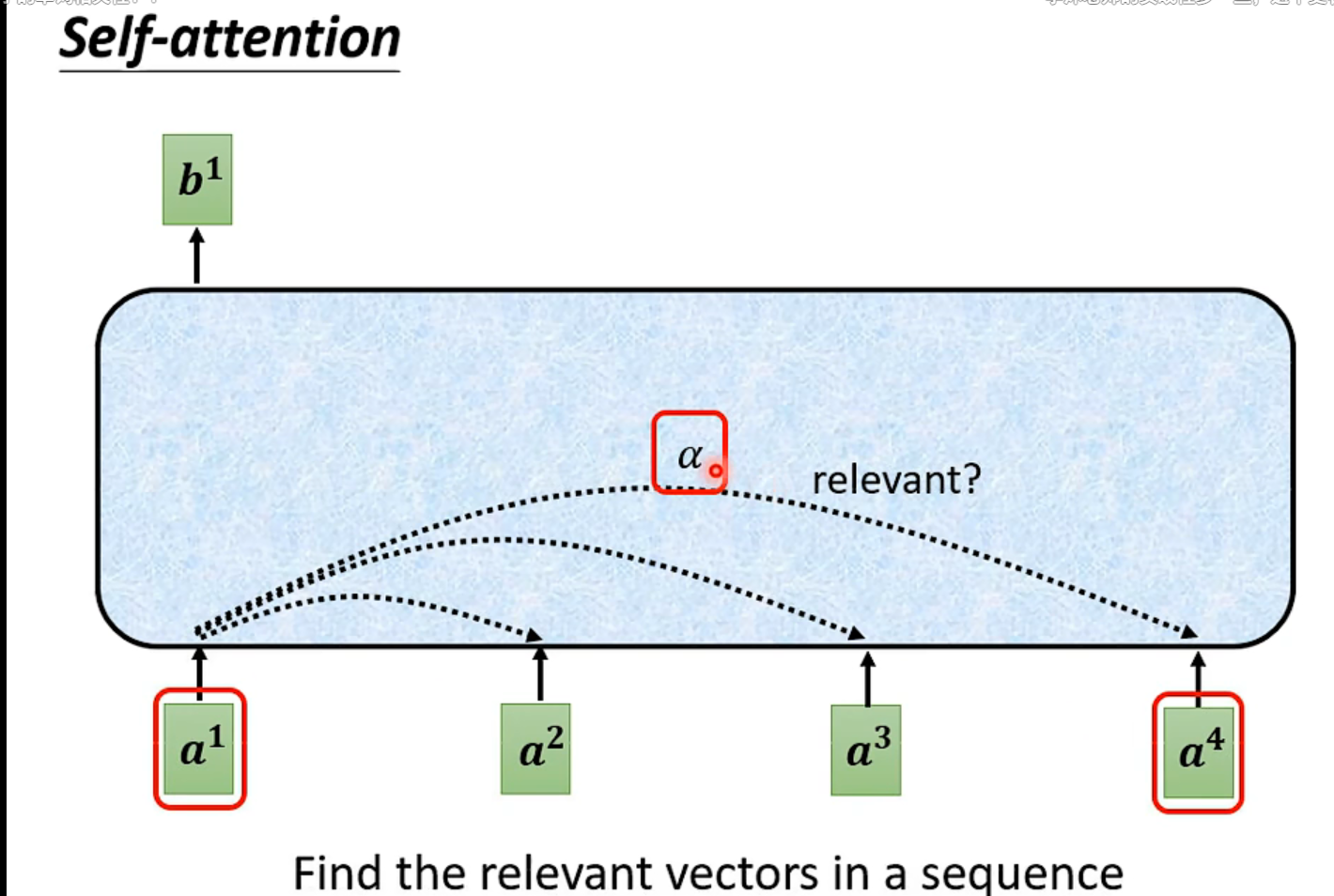
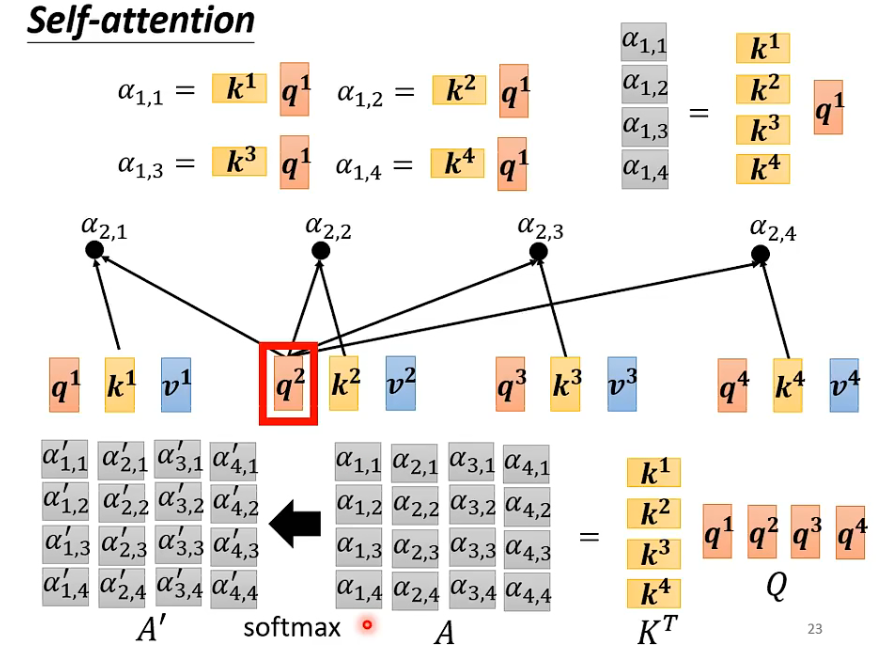
self-attention考虑到了整个输入,计算单个输出:也就是把对应的输入当作query,其他的当作key和value👆
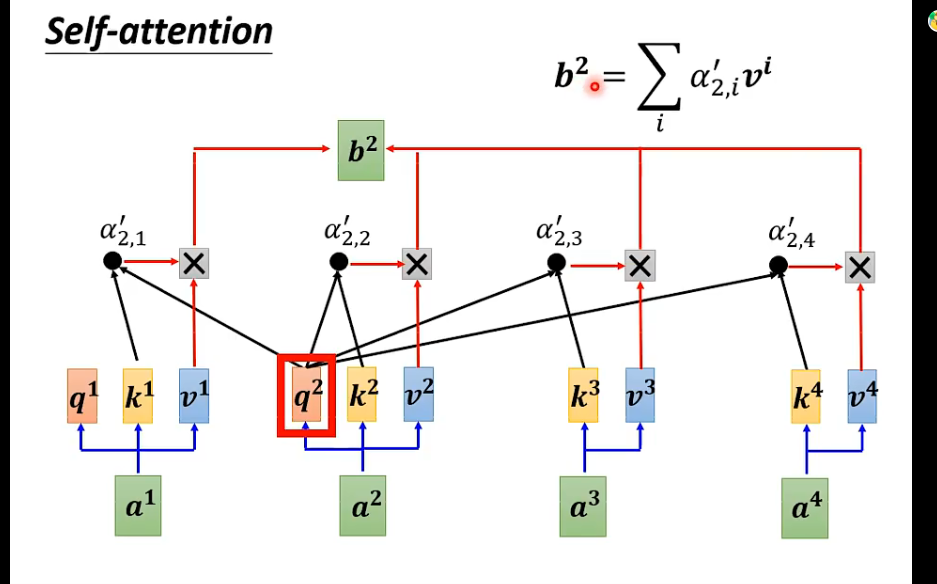
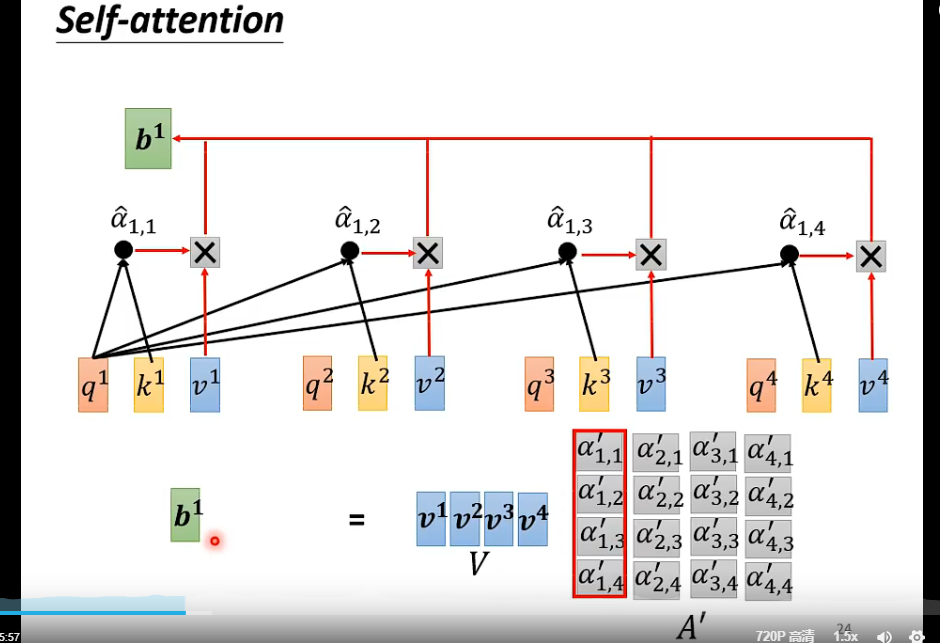
此处的$b_1 - b_n$是并行,同时被计算出来的。所以说并行性好啊,举个例子:$b_2$,矩阵形式👇
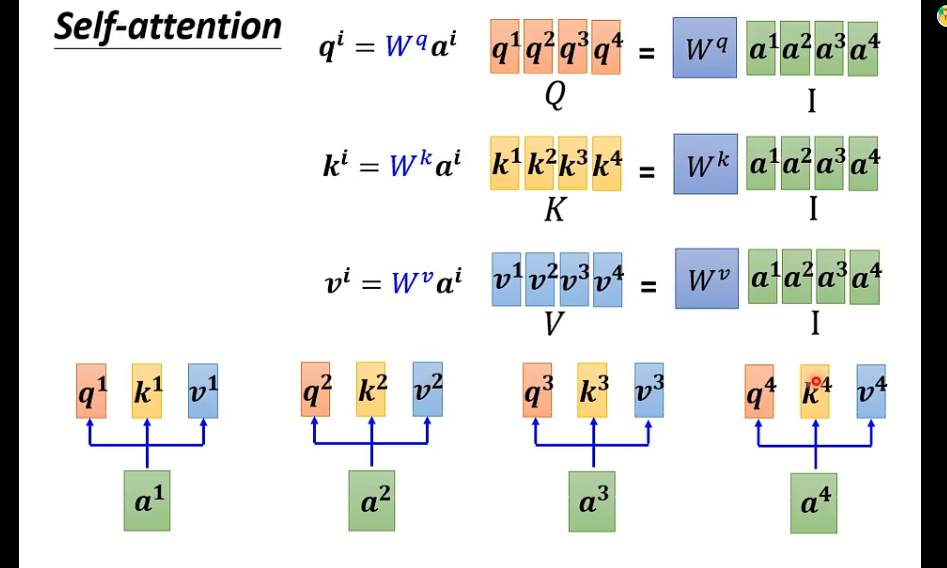
他说这里不一定用softmax,还可以用relu什么的,效果也不会太差;这也太友好了吧,shape都帮你推出来。
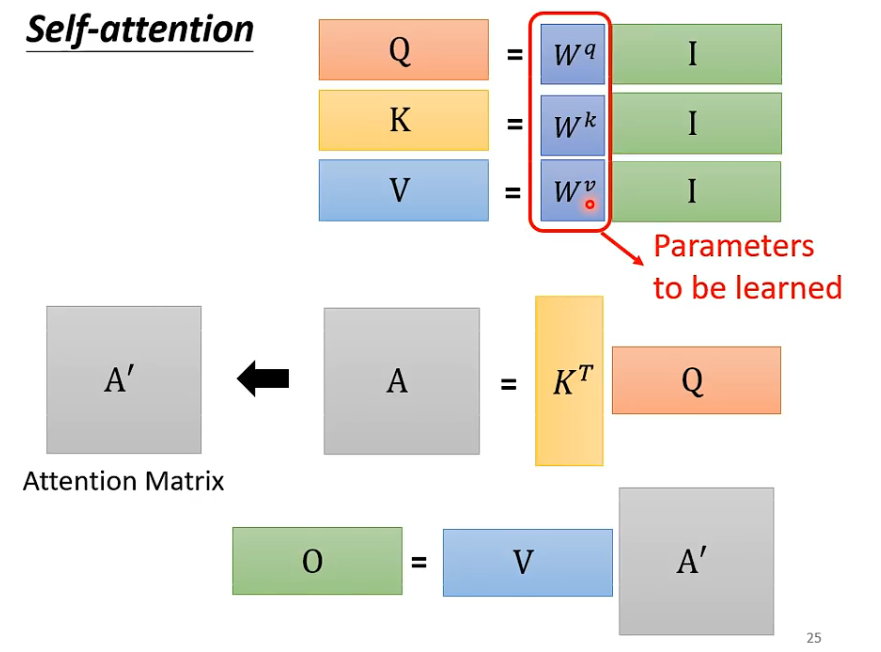
不过从原始输入还要经过不同的变换才能得到q、k、v,这里直接是多头注意力了。(原理图给的是内积分数计算)
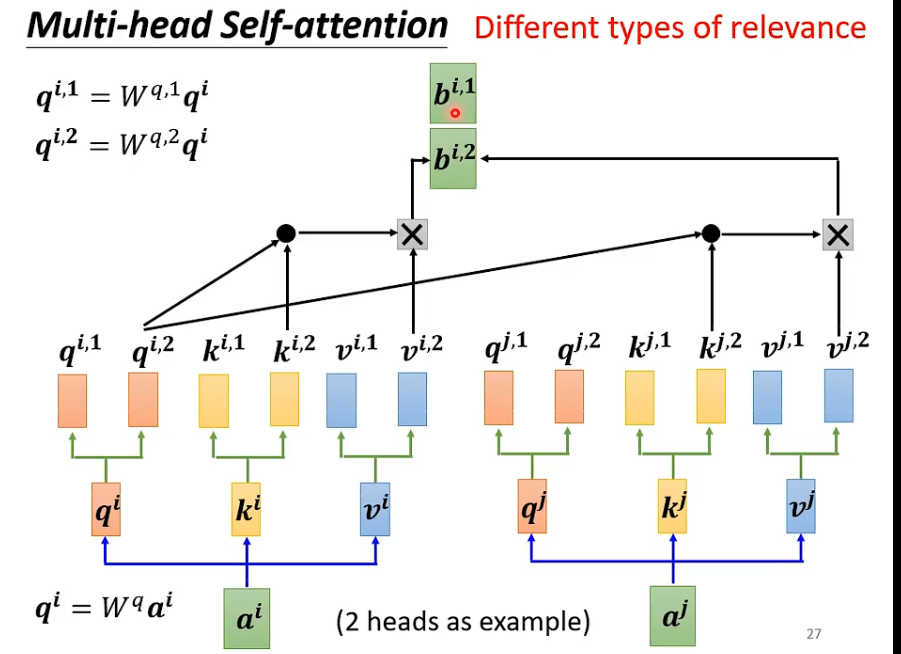
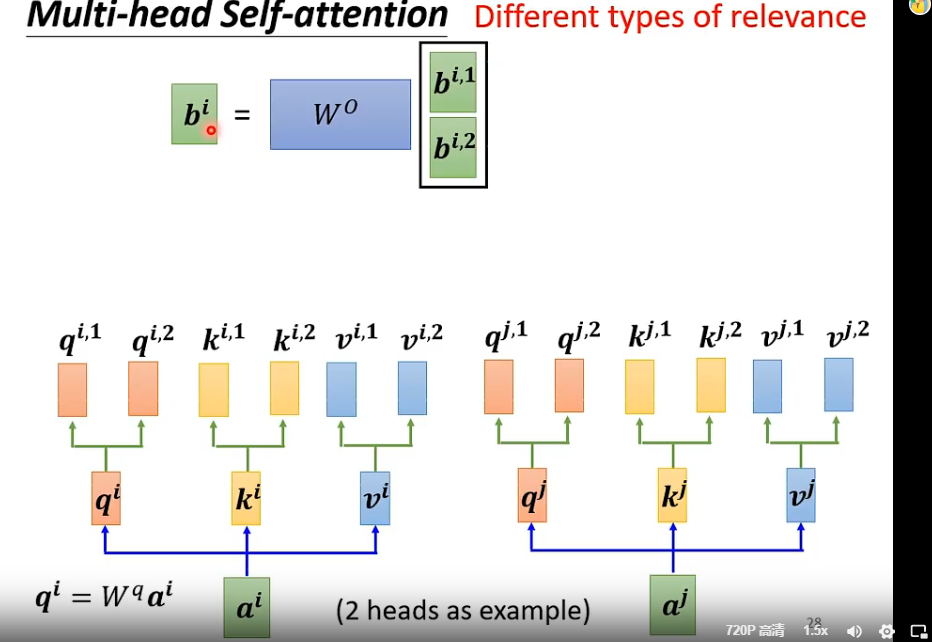
多头自注意力
“相关”这个定义方式有很多种,因此我们需要得到多个q,k,v的组合,计算的时候是组内计算的,(如$b^{i,2}$不用${i,1}$的东西),最后把多头接起来,再通过一个变换得到最终的结果。
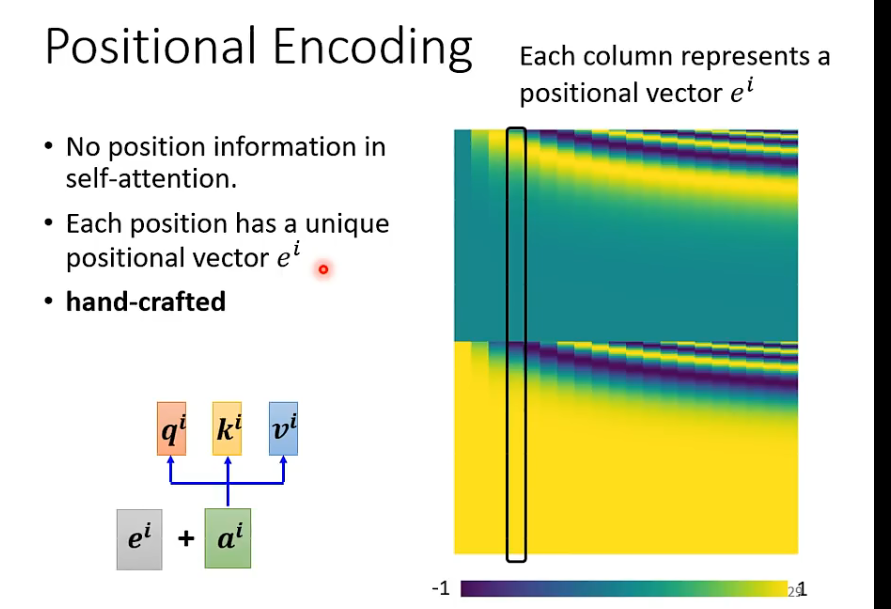
位置信息
下图黄绿那一片是最开始论文中采用的位置信息(人为设置的,有诸多问题)。
如今,还有许多人在研究position encoding,也没有人说sin cos就是最好的方法。
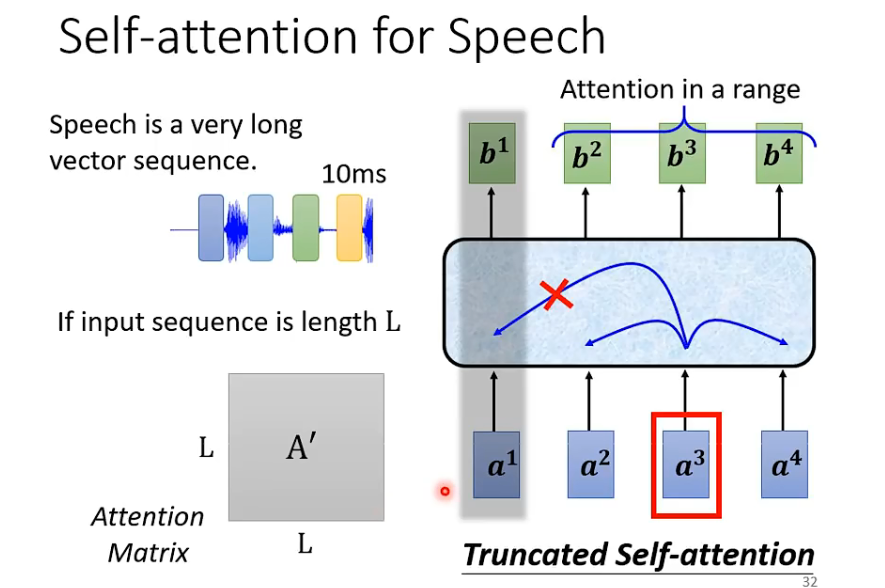
有个问题,在诸如声音讯号中,长度非常长,计算量相当大,有一招叫做truncated self-attention,只考虑一个范围,这个范围如何选定取决于你对问题的理解。
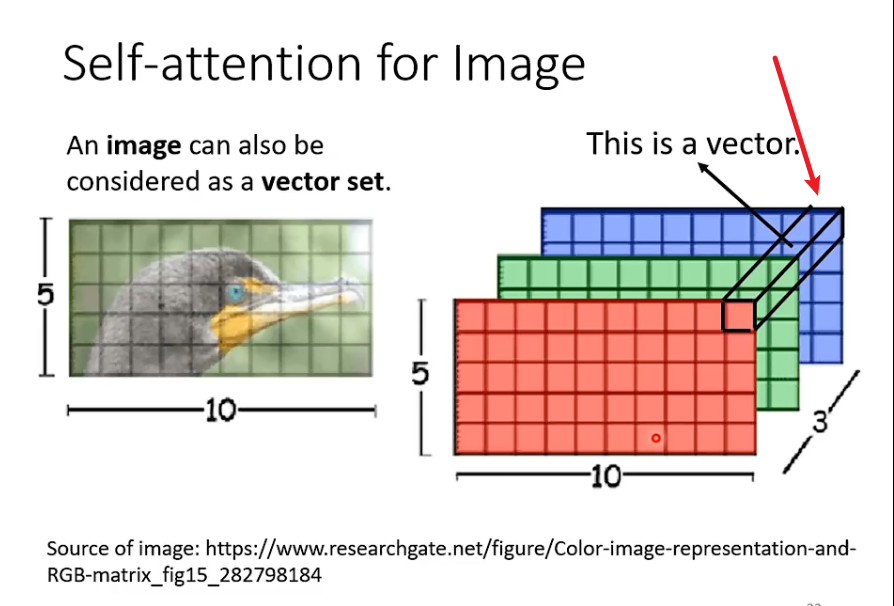
self-attention也可以用在图像中,也就是换一个角度,不把图像看成很长的向量,而是看成一个vector set,每个vector是一个像素。
如果比较CNN和self-attention,可以说self-attention是一个复杂化的CNN,考虑全局的信息而不是感受野之内的。也可以这样理解:感受野(receptive field)是自己学出来的,而不是人工设定的!【端到端狂喜!】

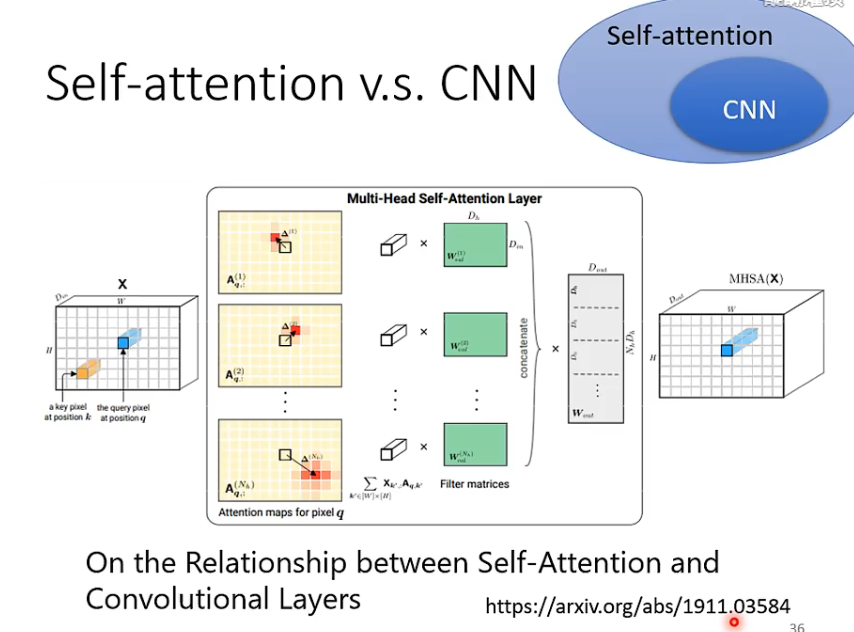
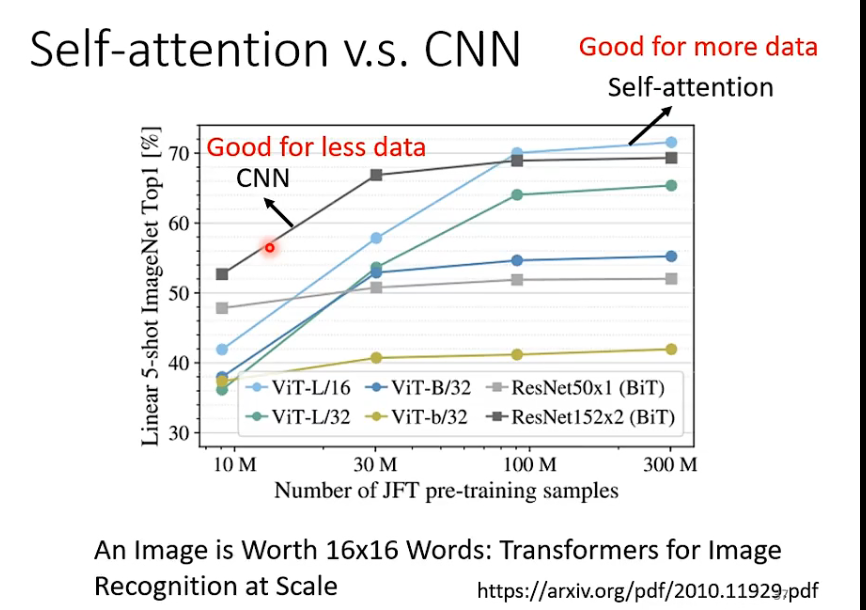
但是,更free的model需要更多的数据才能学的好,self-attention比起CNN也需要更多的model
草,李宏毅说RNN基本都能被self-attention代替,所以不讲了
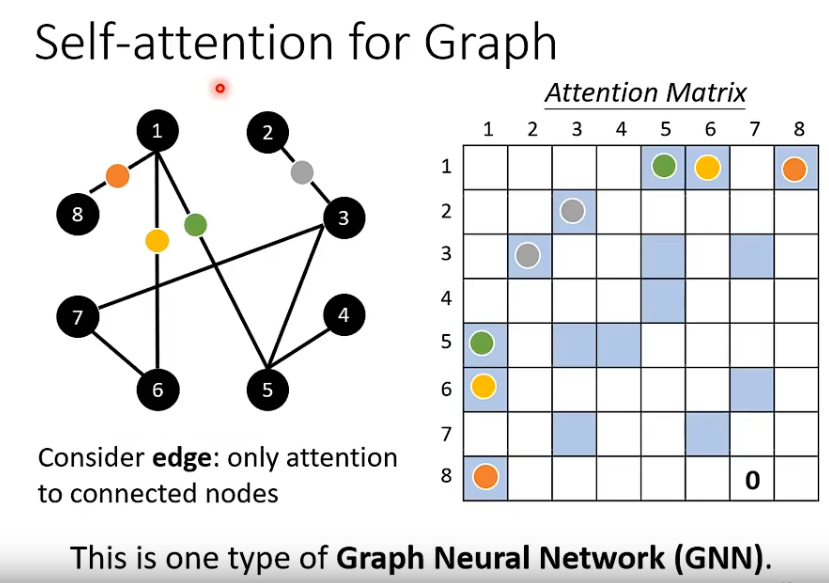
self-attention也可以用在graph上,只考虑有关联的,👆,这就是GNN
减少self-attention的计算量是非常值得研究的课题。还有各类的self-attention变形,见后文:各式SA
Transformer
Transformer 是个叠加的“自注意力机制(Self Attention)”构成的深度网络,是目前 NLP 里==最强的特征提取器==,注意力这个机制在此被发扬光大,从任务的配角不断抢戏,直到 Transformer 一跃成为踢开 RNN 和 CNN 传统特征提取器,荣升头牌,大红大紫。
Seq2seq
和bert很有关系,输入是seq,输出是长度不确定的seq。
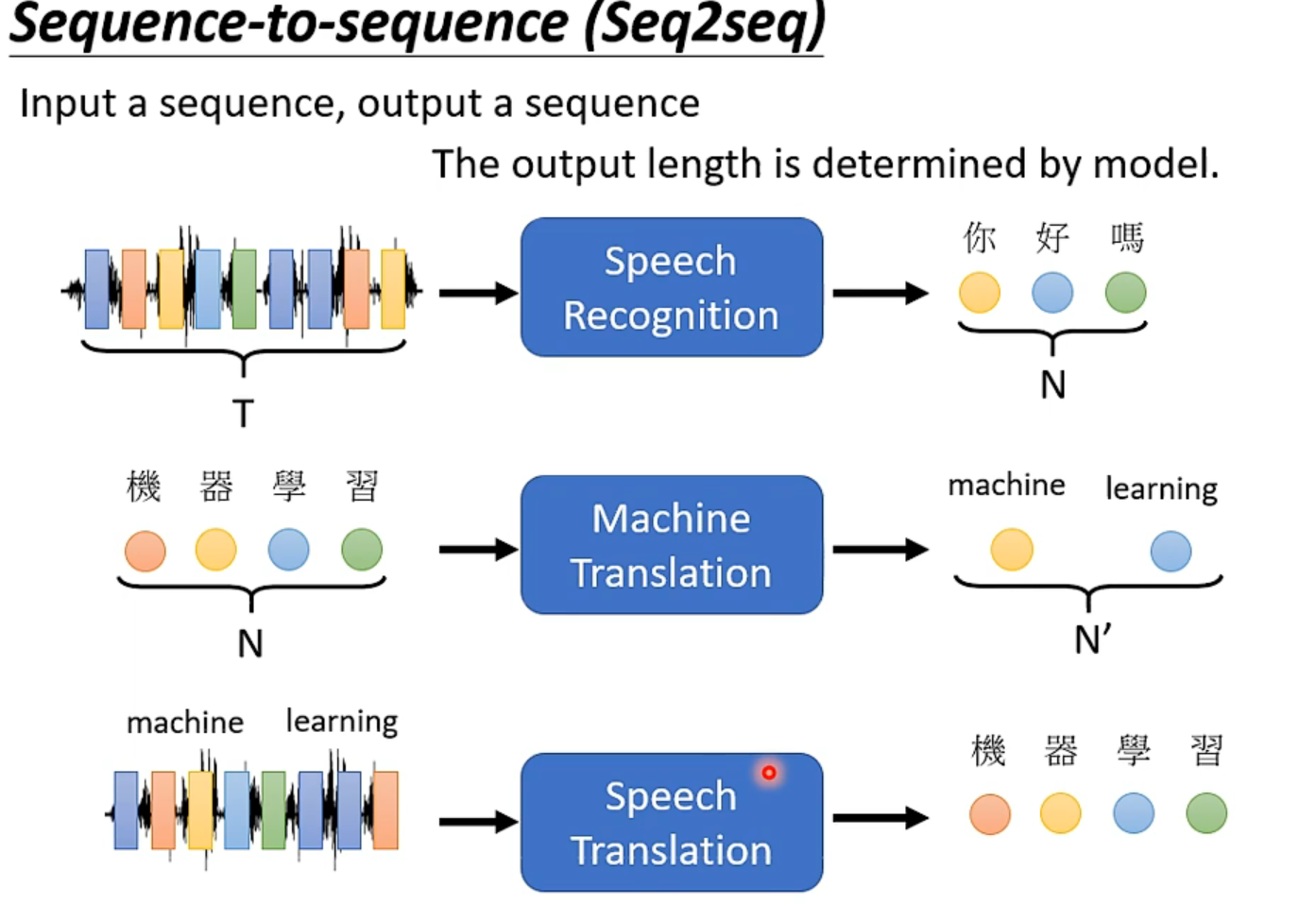
之所以要弄speech->translation而不是直接拼合上面的,是因为世界上有许多语言是没有文字的(或者像台语一样没啥人用文字)。
很多NLP的任务都可以类比QA任务:给model一个上下文context,问机器一个Q,机器返回一个A
而QA的问题就可以用seq2seq来解决【通用方案?】当然,对不同的任务采用特制的模型,可能得到更好的结果(本节不讨论)
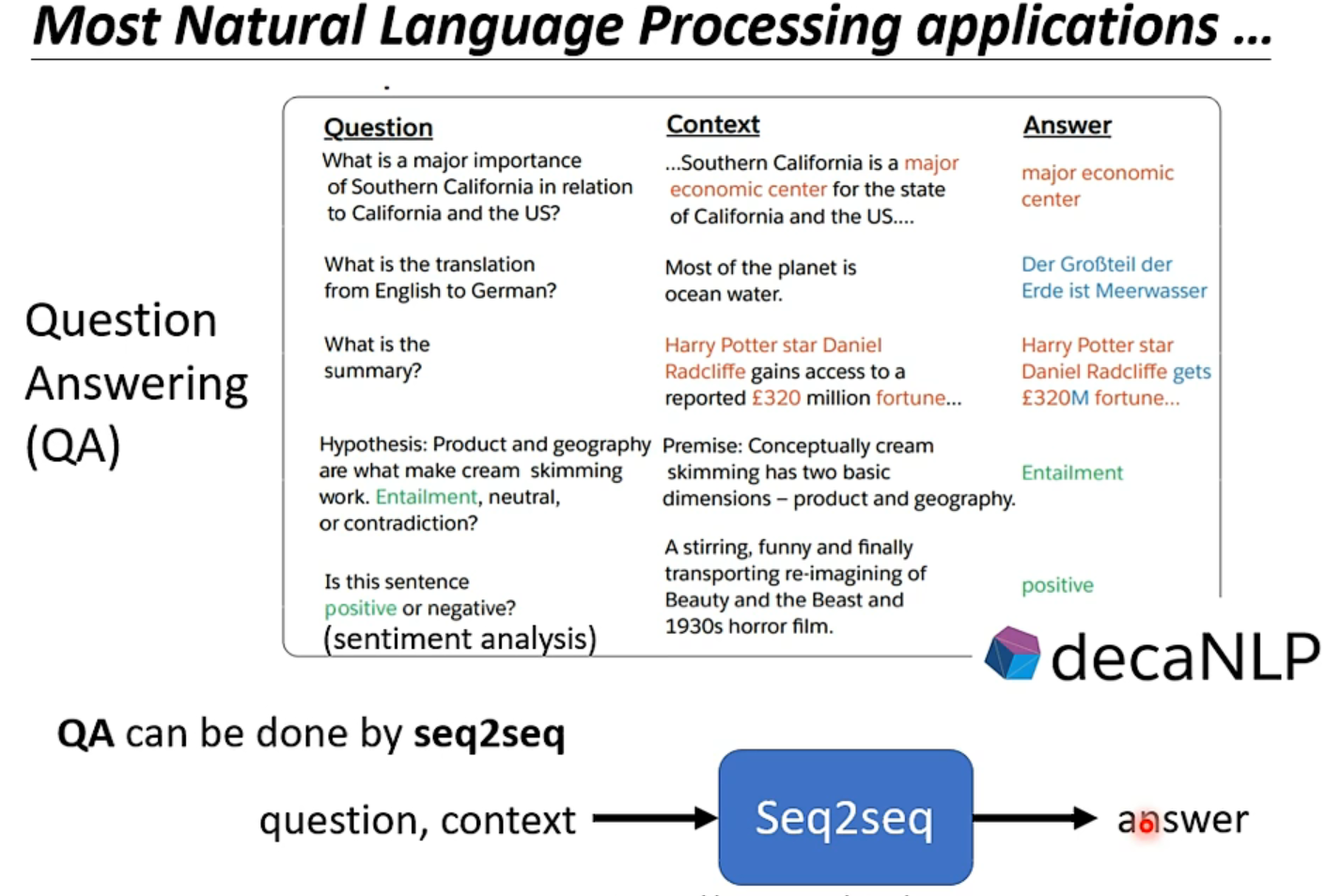
还有很多问题,你不觉得是seq2seq,但也可以用这个方法硬解它!👇【甚至物体识别都行】
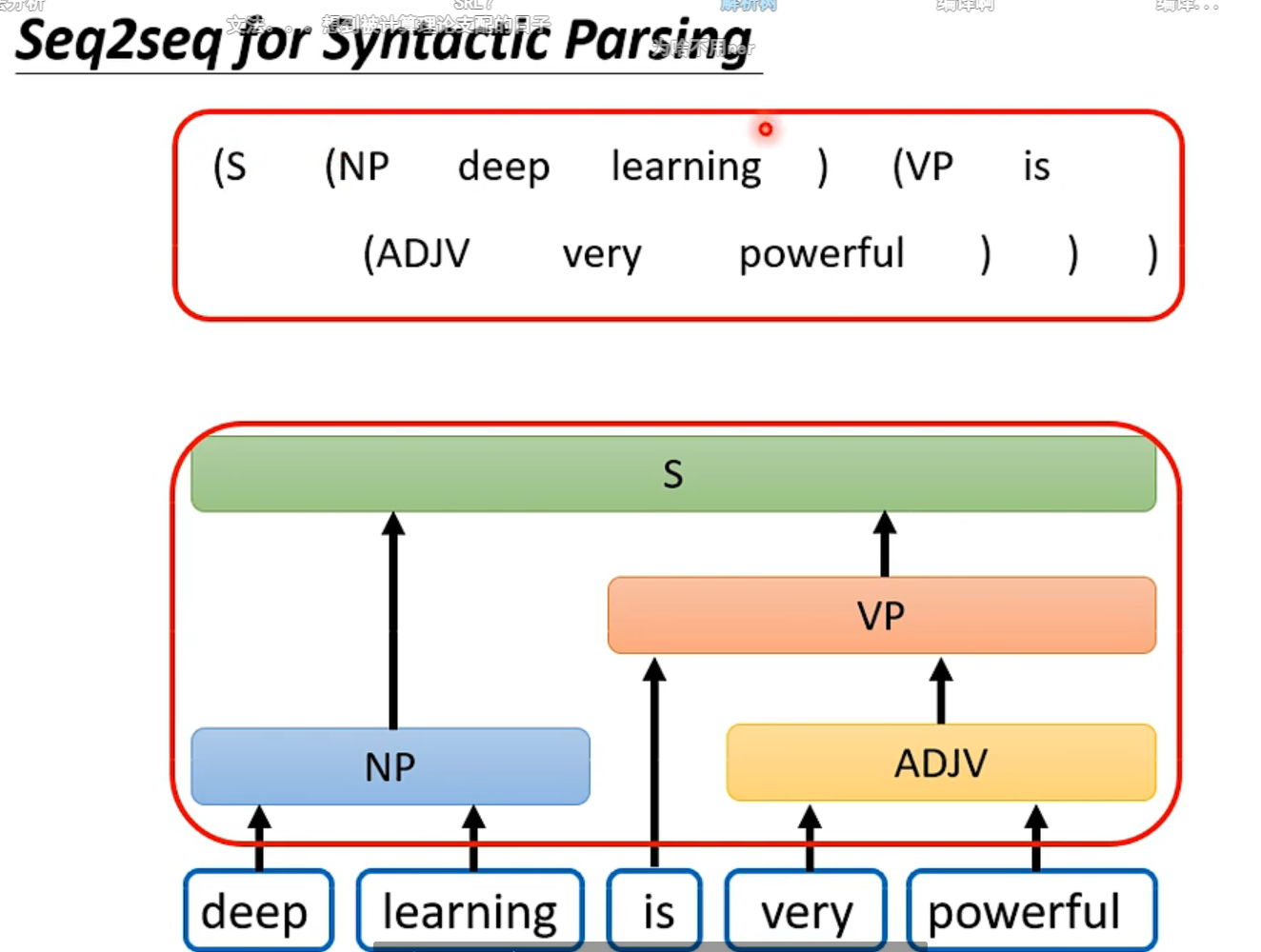
架构
架构李沐讲的不错,都没有讲什么直观理解。
BERT其实就是transformer的encoder。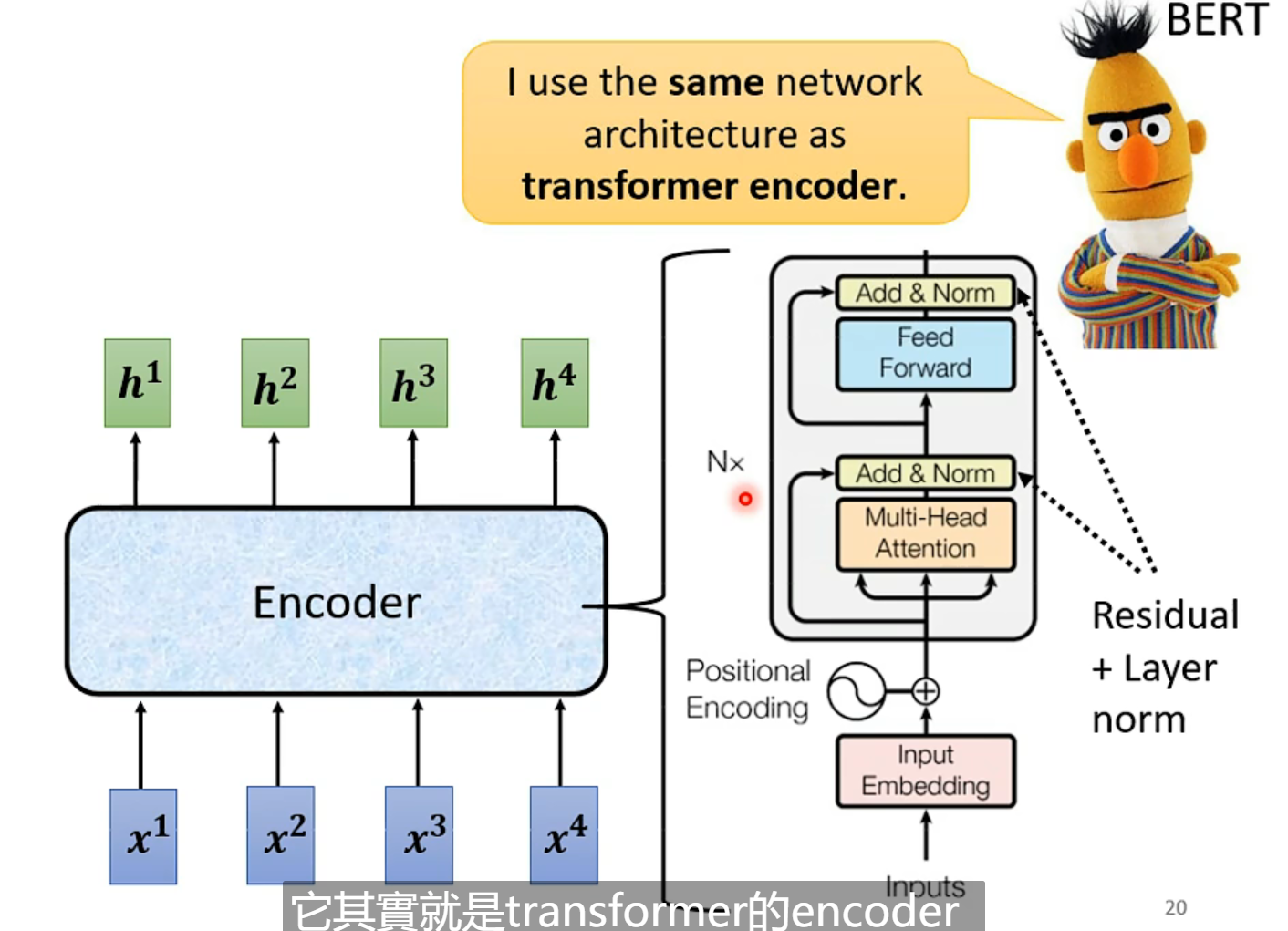
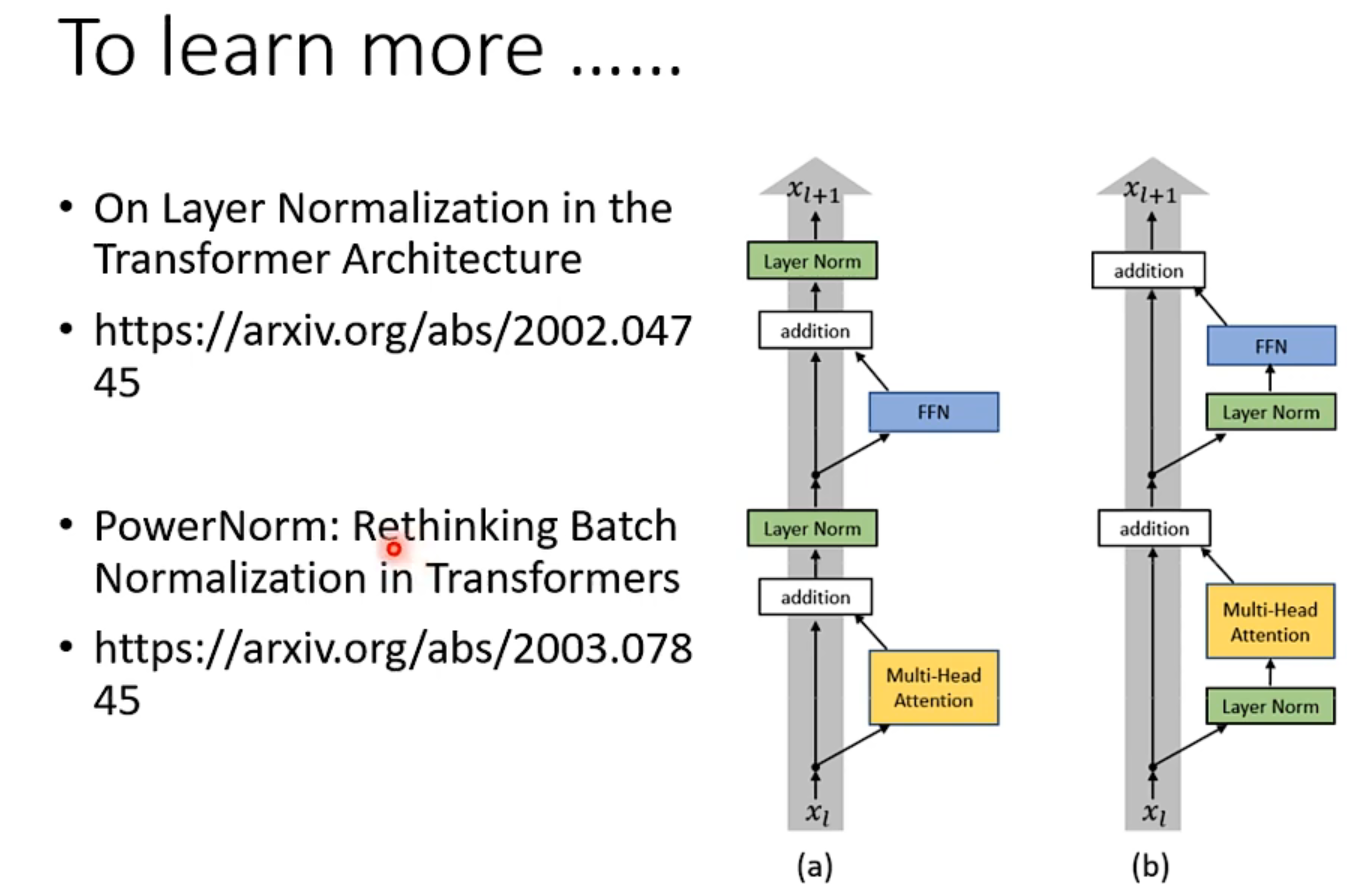
当然,这个encoder架构不一定要这样设计,有人提出了别的架构方法。下面的论文探究了为什么batch不如layer normalization
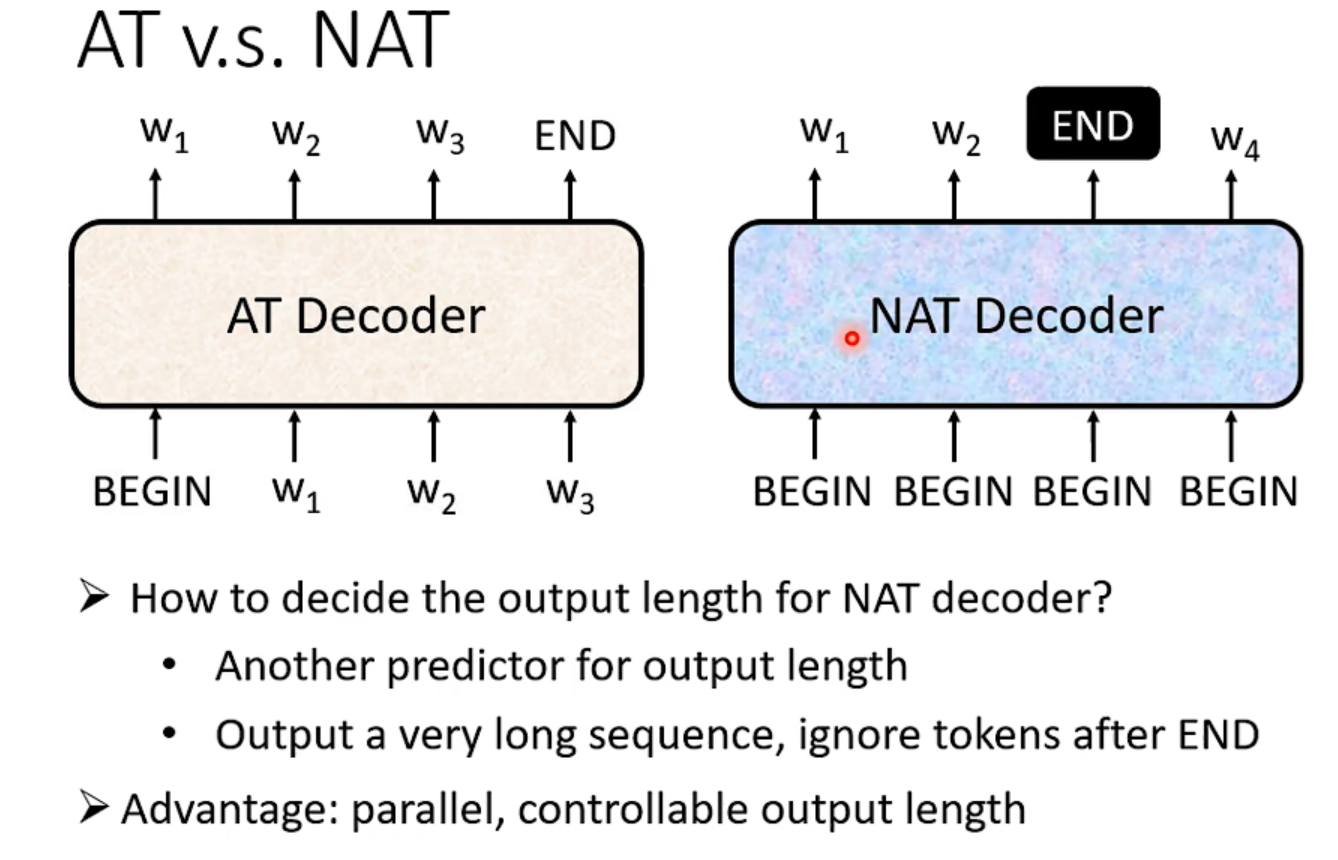
Decoder其实有两种(AT和NAT),比较常见的是Autoregressive,NAT用的也不少,比如在语音合成里。
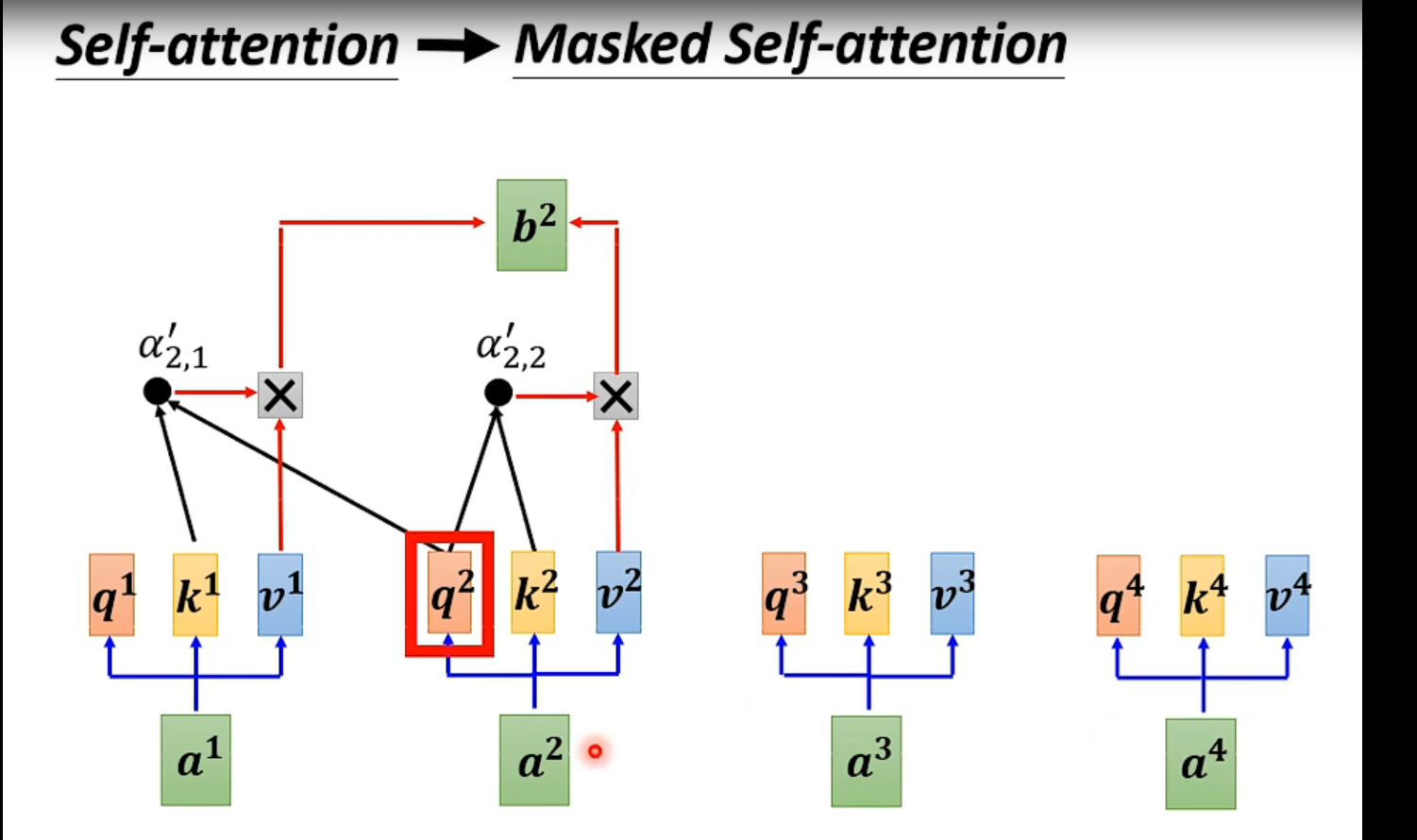
Encoder和Decoder其实结构很像,第一个注意力层那里,decoder用的是掩码attention,不考虑后面的输入
为了不让程序永无止境地推到下去,需要准备一个特殊字符“EOS”(end of sentence)对比NT和NAT👇:
NAT在并行性和长度的人为可控性有优势(比如音频倍速,就可以利用这个先验信息更好的辅助)
但是NAT这个decoder的表现往往不如AT,decoder的设计现在也是一个热门主题。【选修课有讲NAT】
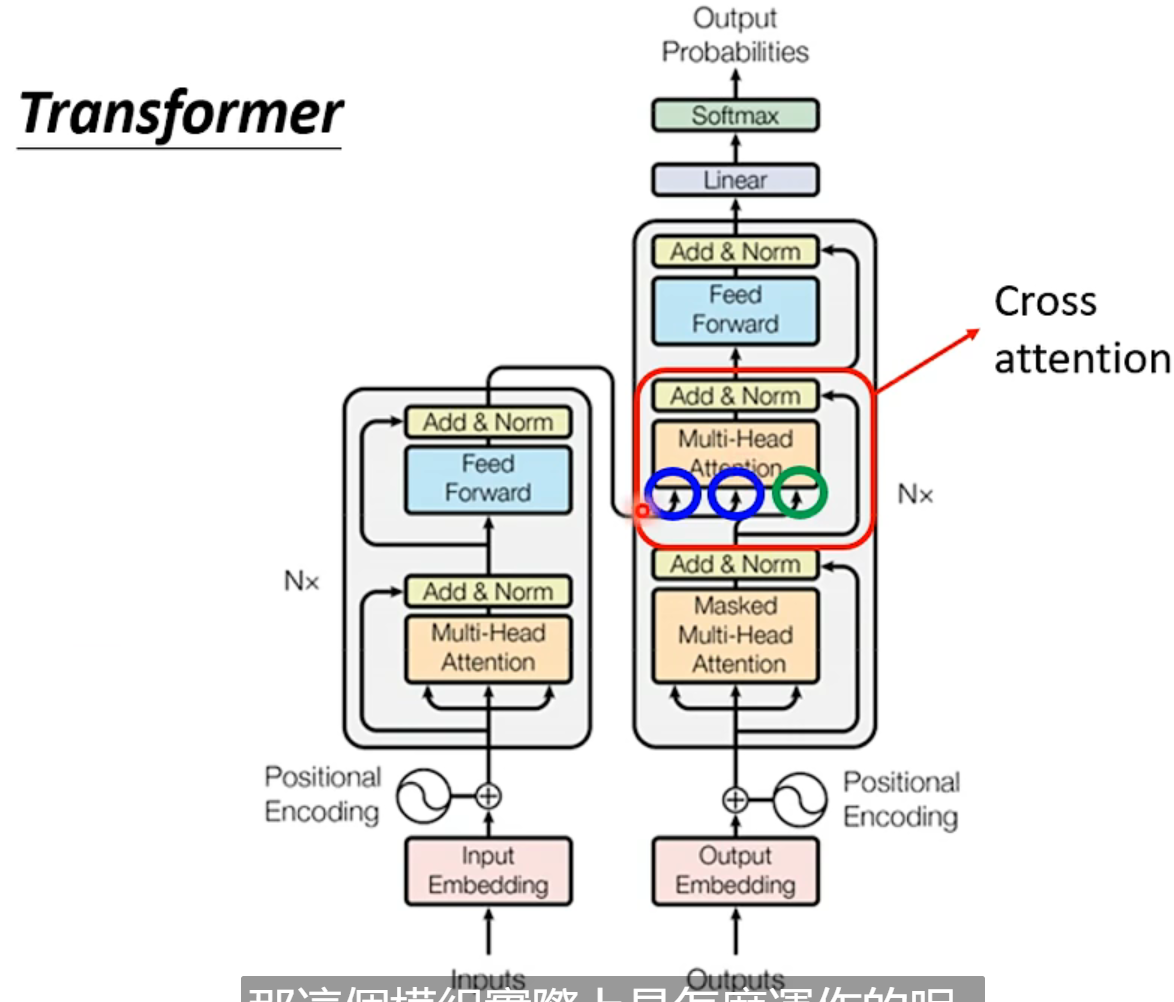
注意力机制(李宏毅称cross-attention)
当然,是先有注意力机制,再有self-attention的。
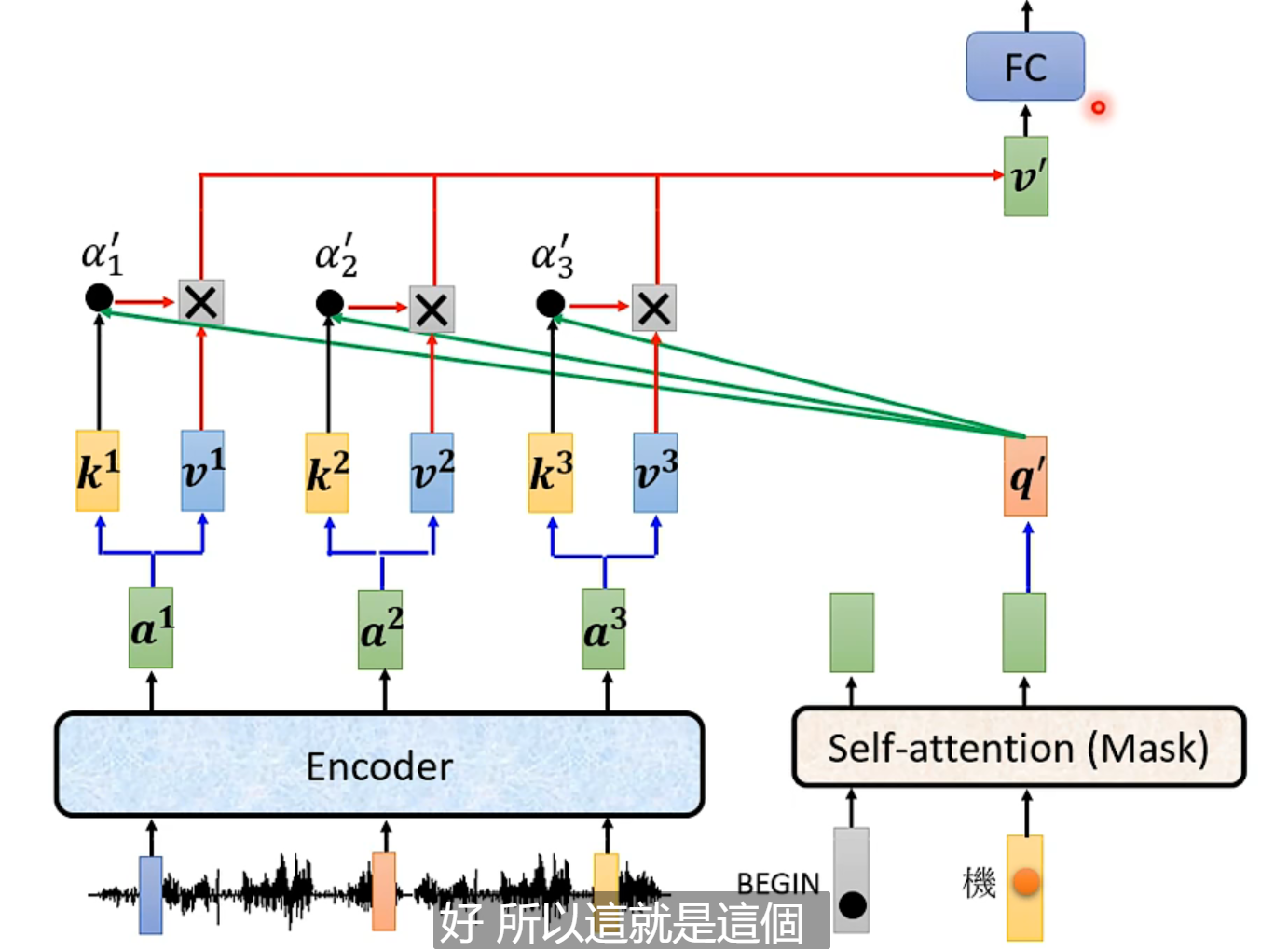
encoder和decoder之间的联系:
原始论文给出的架构中,是encoder的最后一层输入到decoder的每一层,但是完全可以有不同的联系方式。
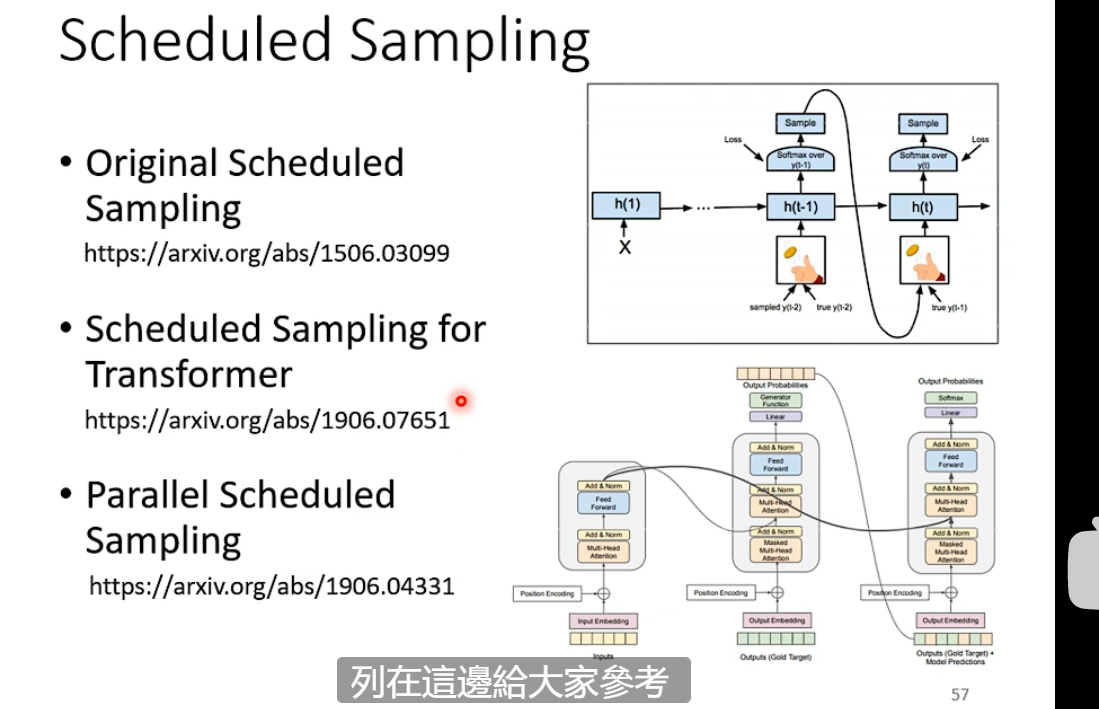
训练的时候是“强制教学[teacher forcing]”。
训练时用的损失函数是cross entropy,单独考虑每一个词元与正确答案的误差。因为BLEU计算复杂,无法用来微分求导。
【遇到无法优化的目标,用RL硬train一发,把loss当reward,decoder当agent】
但是这不一定使得BLEU减小,测试时用的是BLEU,所以validation集要用BLEU来做评估。
训练和测试评估不一样导致:exposure bias 。
因为训练的时候decoder只看正确的东西,测试的时候便会一步错,步步错。
一个解决思路是:scheduled sampling,也就是在训练的时候加入一些错的“噪音”。
transformer和RNN的解决思路不一样,有一些reference:
==TIPs==
Copy mechanism
在比如chat-box、做摘要的场景中,要学从人的输入中copy一些词当作他的输出。
那么如何才能拥有这个能力?最早的工作是pointer network
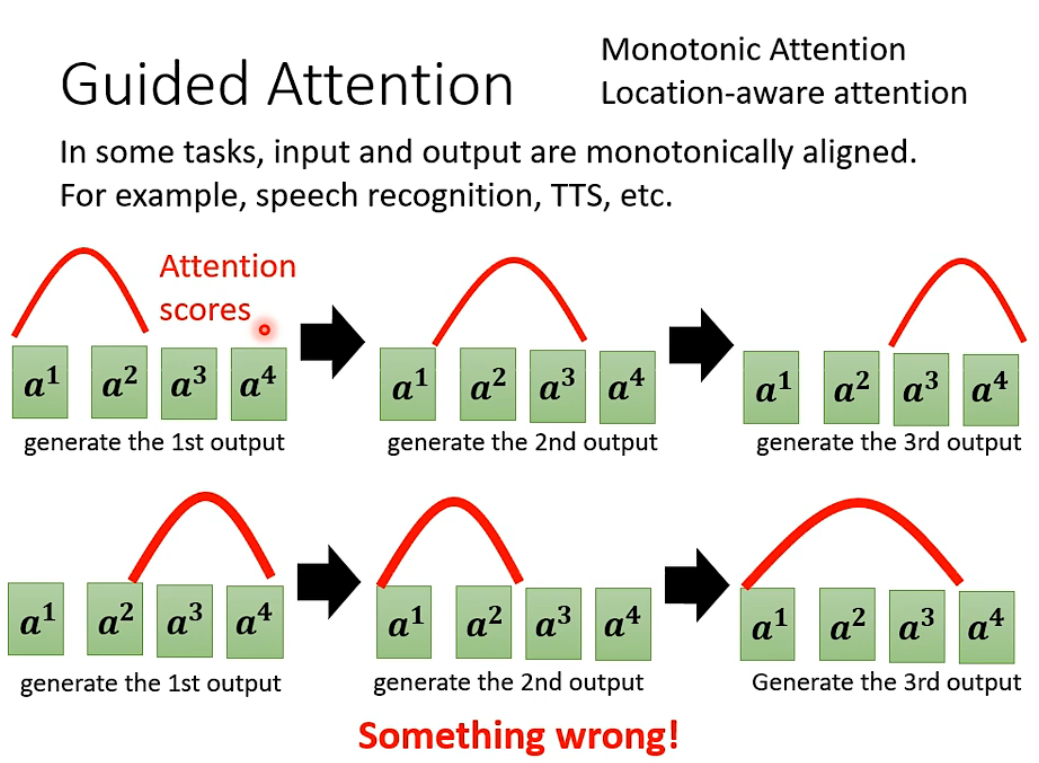
Guided attention
如果你对问题有一定的理解,那么强迫这个attention具有一定的模式,比如语音合成应该由左向右。
like monotonic attention;location-aware attention。
Beam Search
xs,不一定分数高的结果就好,有时候你需要model发挥一点“创造力”【神tm自动生成小说】
TTS中你要生成好的,必须在decoder里加入一些杂音,否则生成的像机器声一样。
各式SA
self-attention其实有各式各样的。大部分叫做xxformer
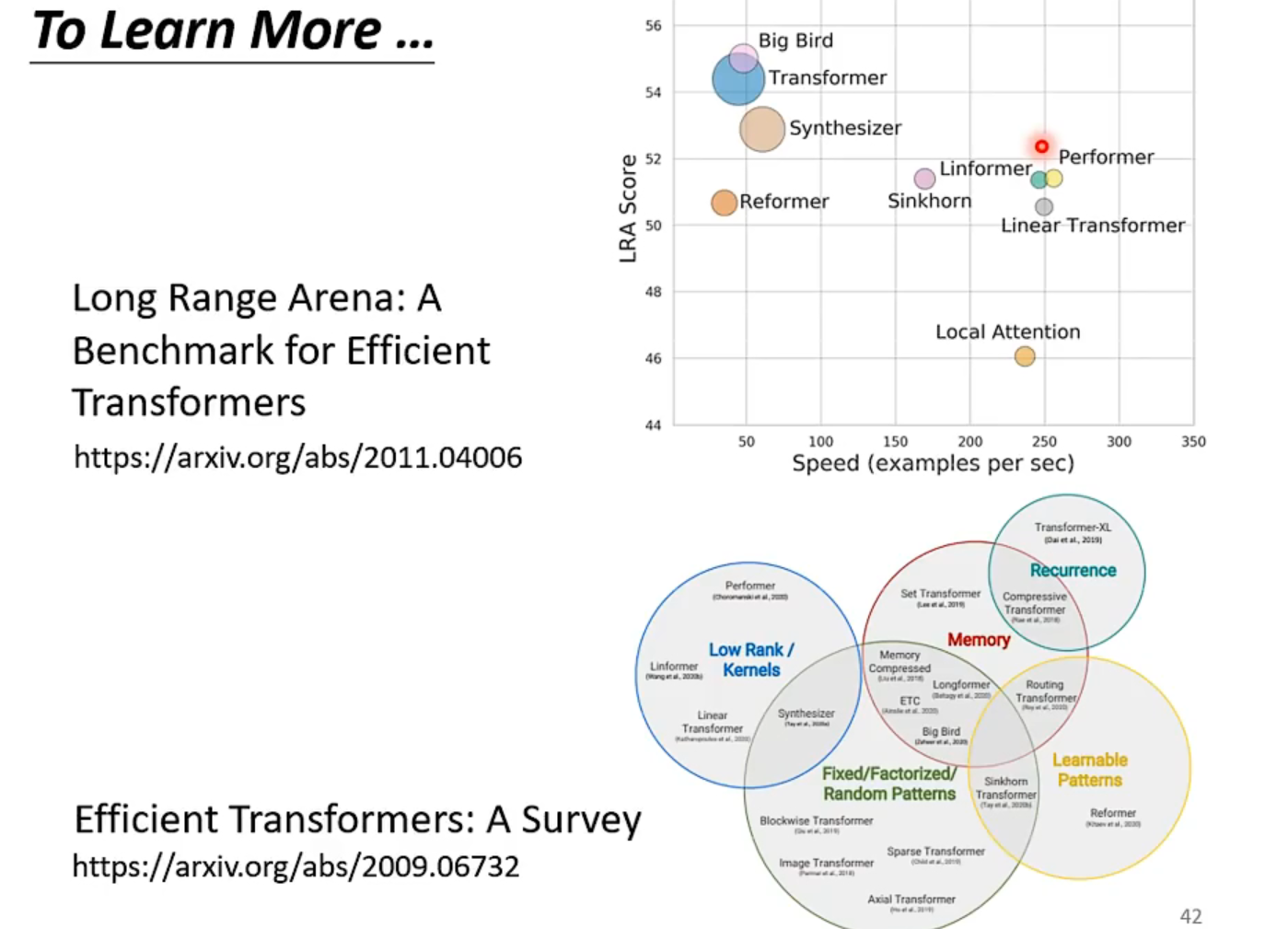
主要痛点是,指数增长的计算量,因此有各式各样的方法试图加速。主要计算来自于NxN的矩阵。
当然,self-attention只是整个network的一部分,如果占比不大,加速的效果也蛮有限的。
当input长度N非常大时,就有必要加速了,这些技术大部分在影像处理里,因为一张256x256的图的N有多达65536,计算还要平方。
手工
Local attention
有些问题,只用关注局部信息就能得到答案,无需关注全局信息。(又和CNN没差别了)
因此虽然能加快运算,但不一定能给你很好的结果。
Stride Attention
跳着看邻居的邻居的咨询,而不是直接看邻居的咨询。空几格也是超参数。
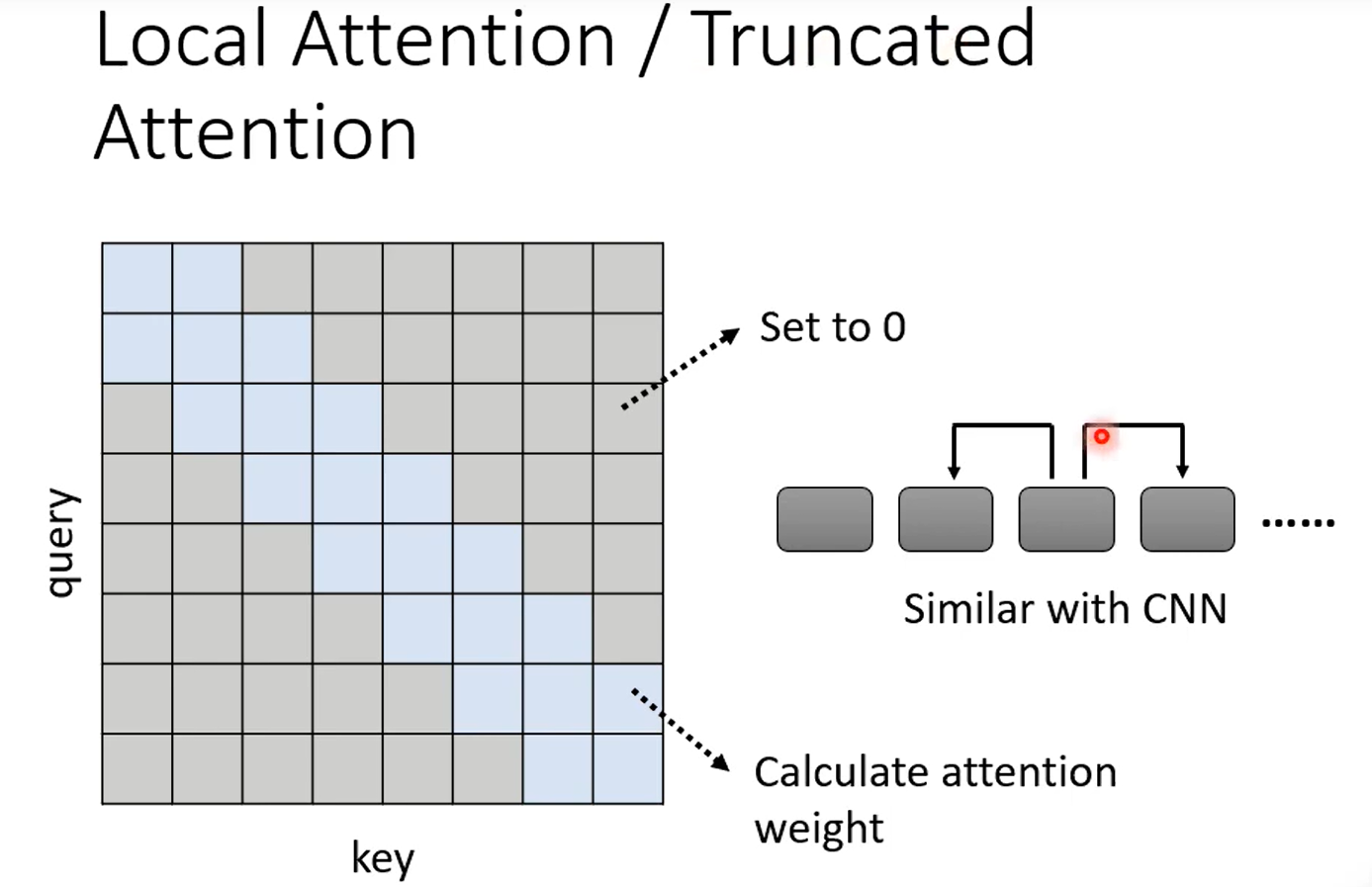
Global Attention
通过特殊的符号(token)代表这个位置要做global attention
它先attend to所有token来看看全局发生了哪些事情,然后再由全局的来查看它以获得全局的咨询。例子:
【假设序列的前两个token设为global token】感觉这个idea非常nb,有点巧妙,可解释性也高。
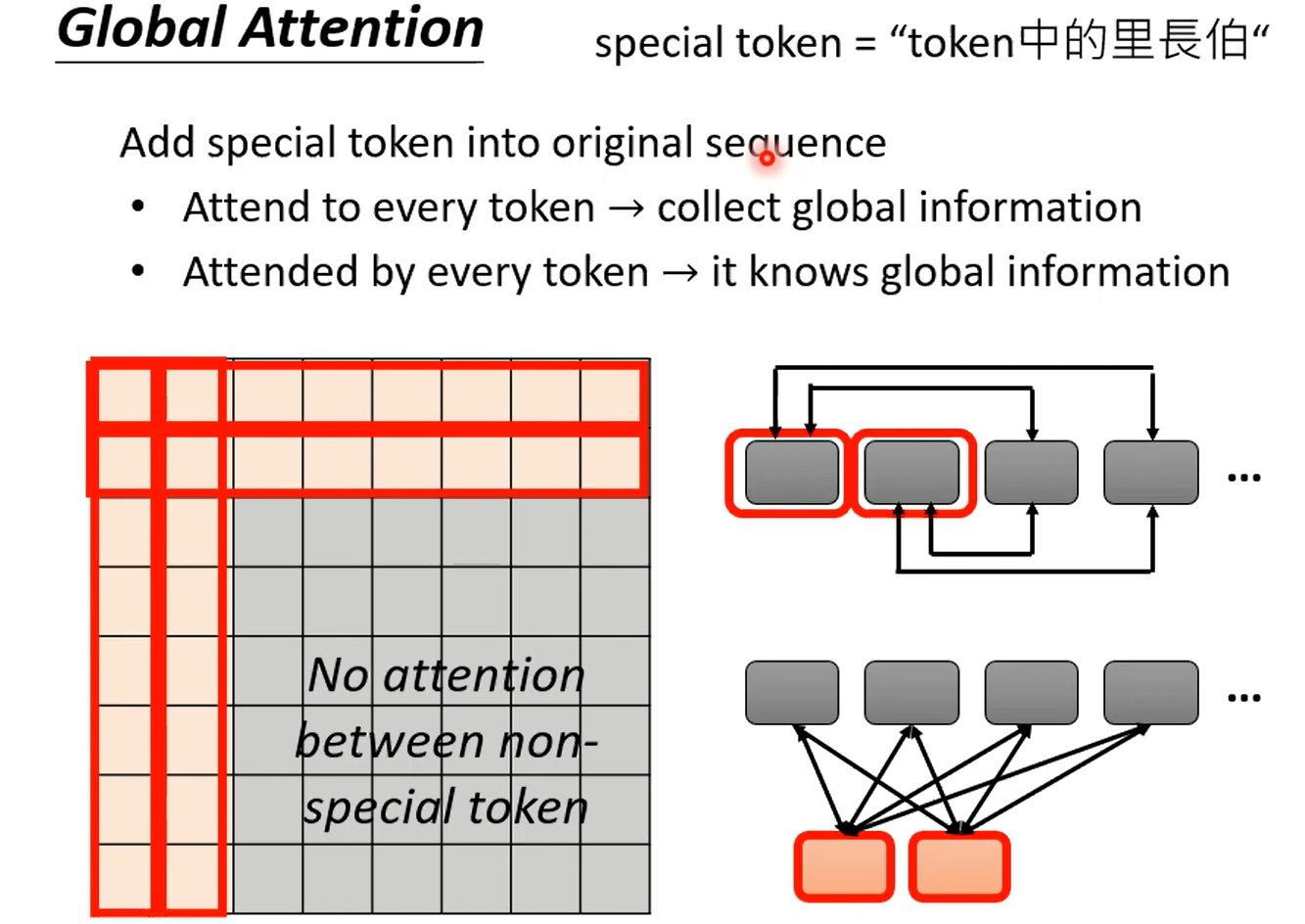
真实情况是,我全都要,多头注意力的每个头都能用不同种类的attention优化方法。
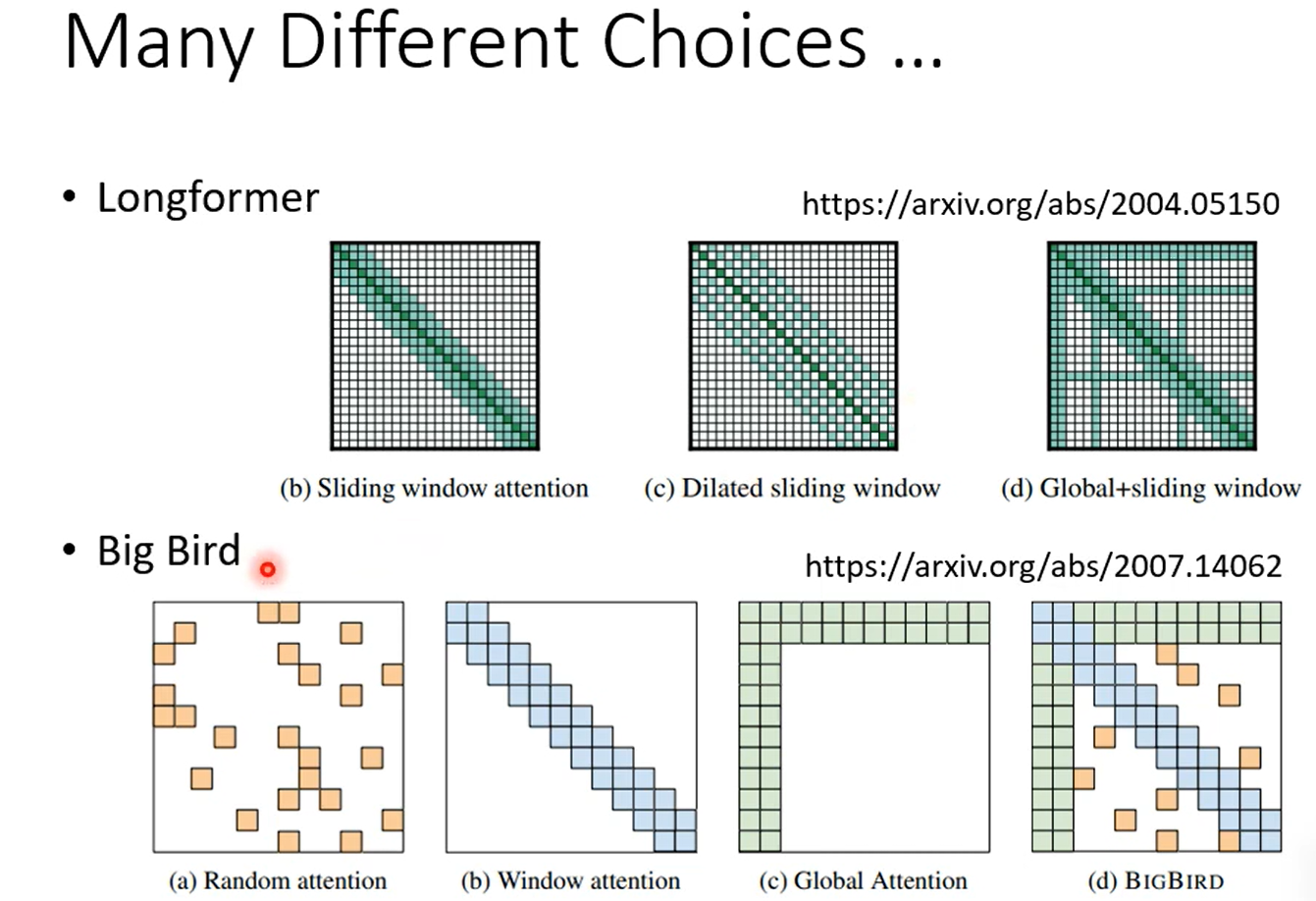
但是,刚刚提到的三种方法其实都是人工设定的,用了“先验知识”,但是凡是能用先验知识的地方,那必然有data driven
data driven
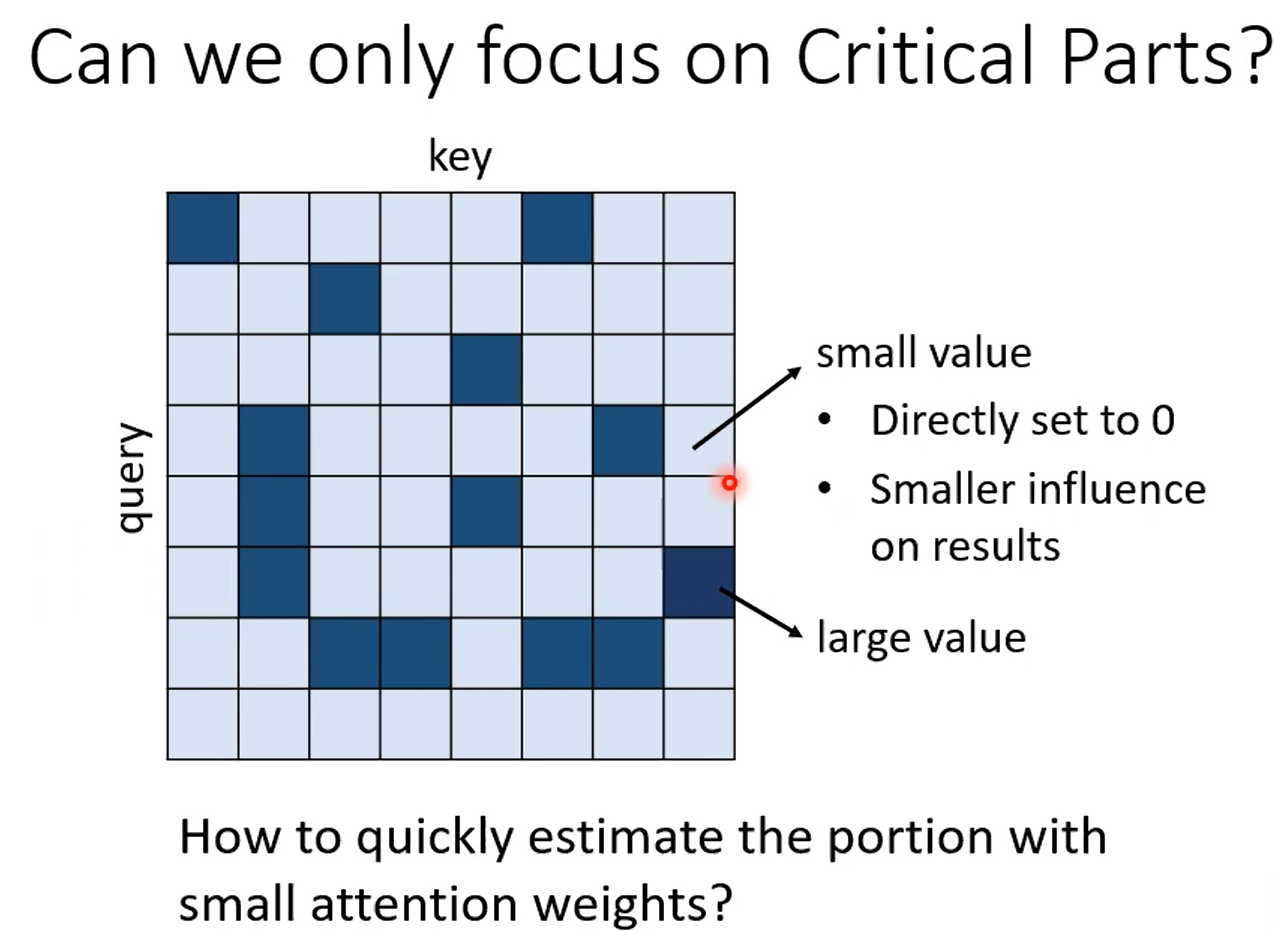
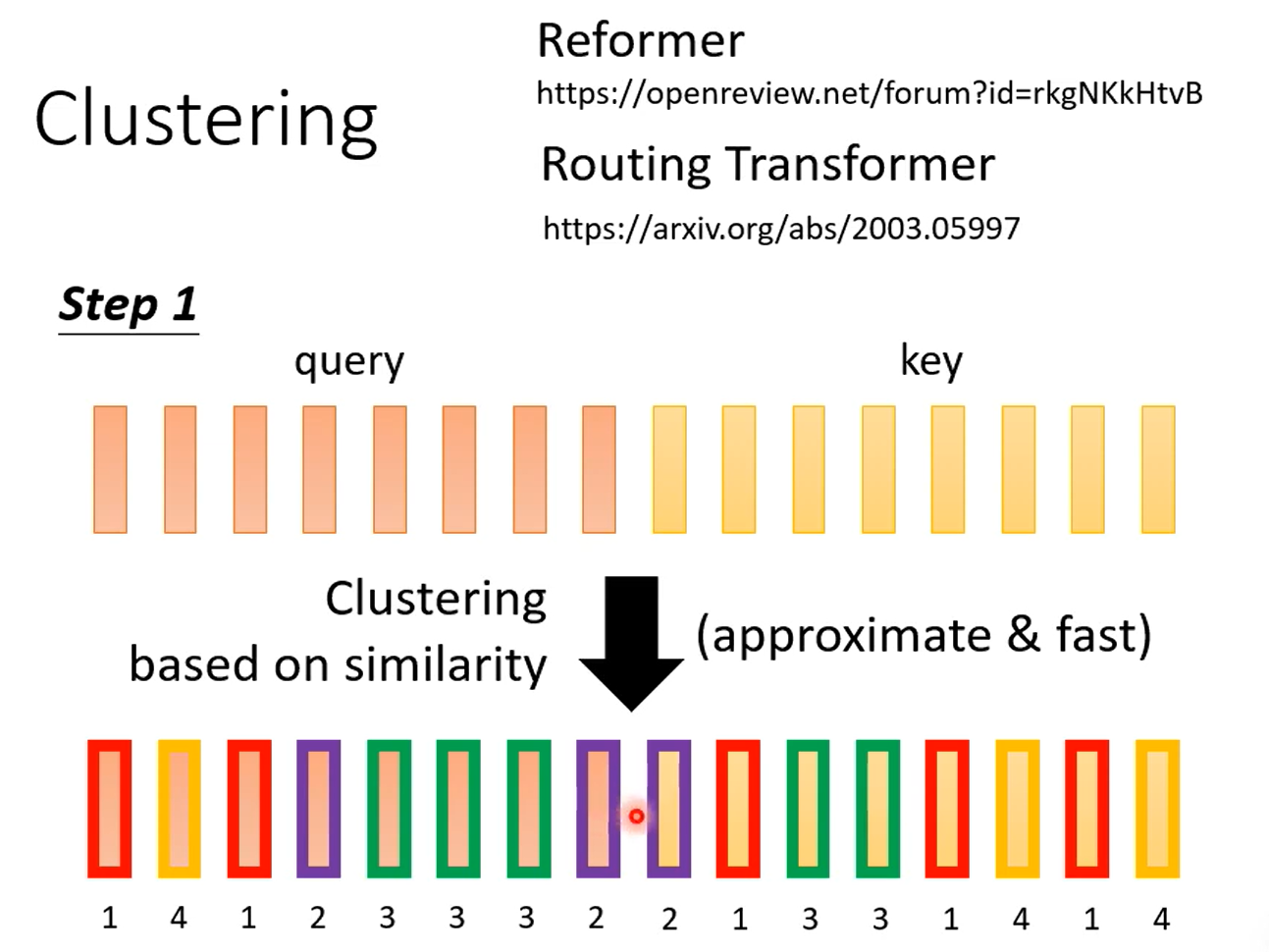
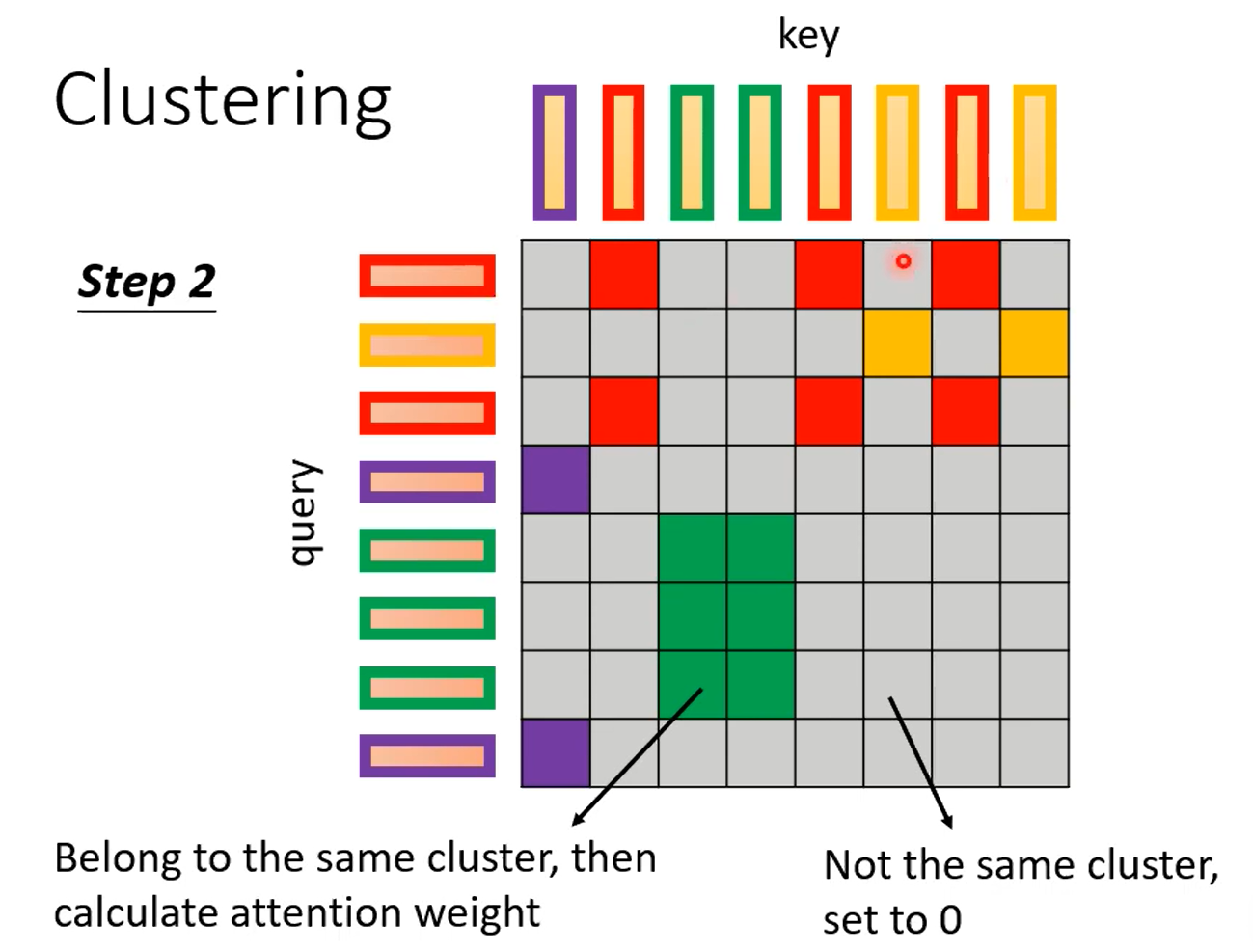
Clustering能采取很多加速的方法。我个人理解,归一化后向量模长差不多,又因为用内积计算,所以相近的自然算的值大。
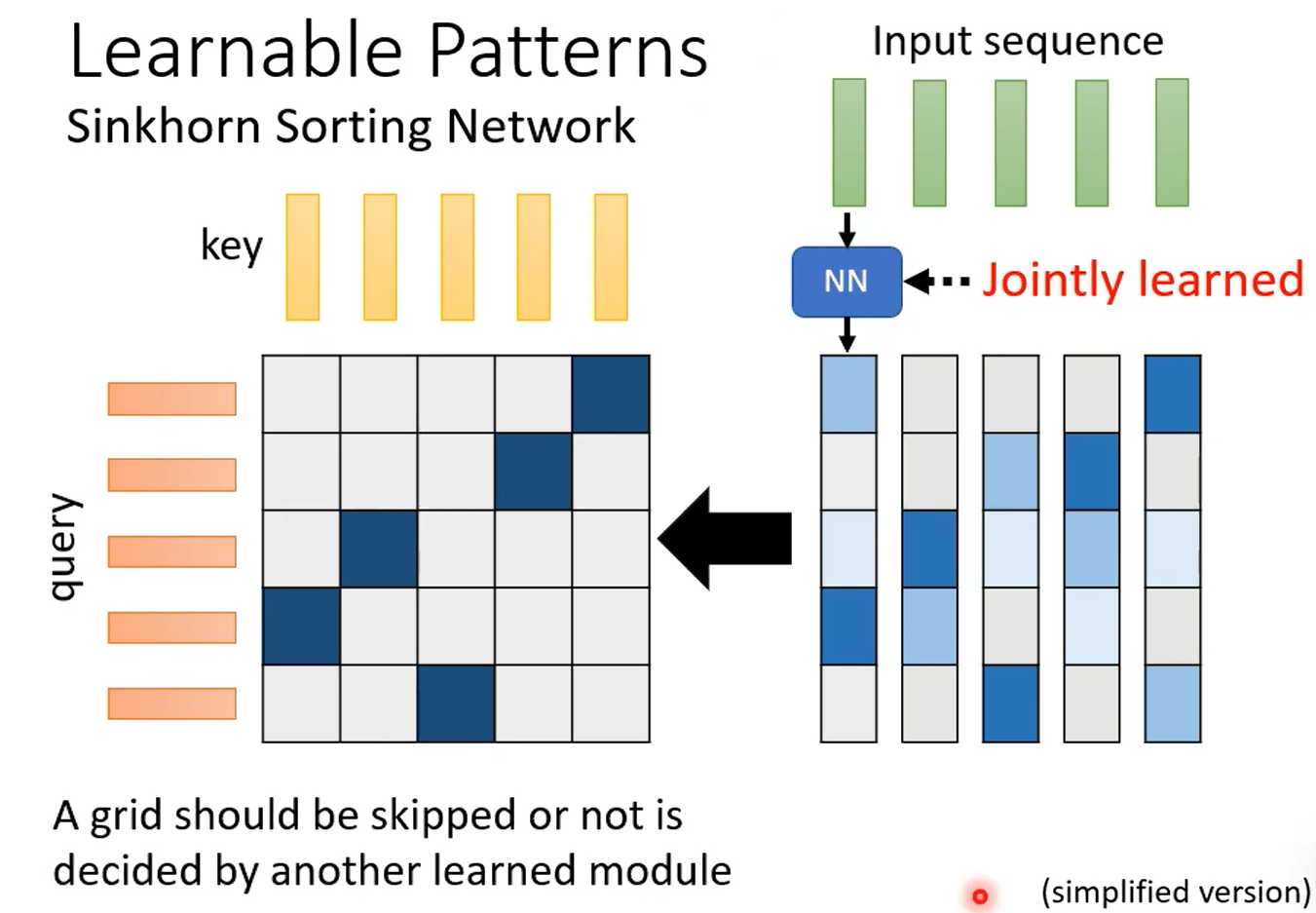
可学的模式:让另一个network去学,这种思想好常用。
sinkhorn sorting network:重点是完成从NN生成的continuous的矩阵到一个二值矩阵的变换,并且需要该过程可微!不过这个过程如果真是老老实实算,其实不便宜多少,作者采用的是多个input共用1个NN生成的output来“取巧”,比如10个共用1个就是百倍加速。
那么为什么要分两步骤,不直接计算二值矩阵呢,这是作者下一篇paper干的事。
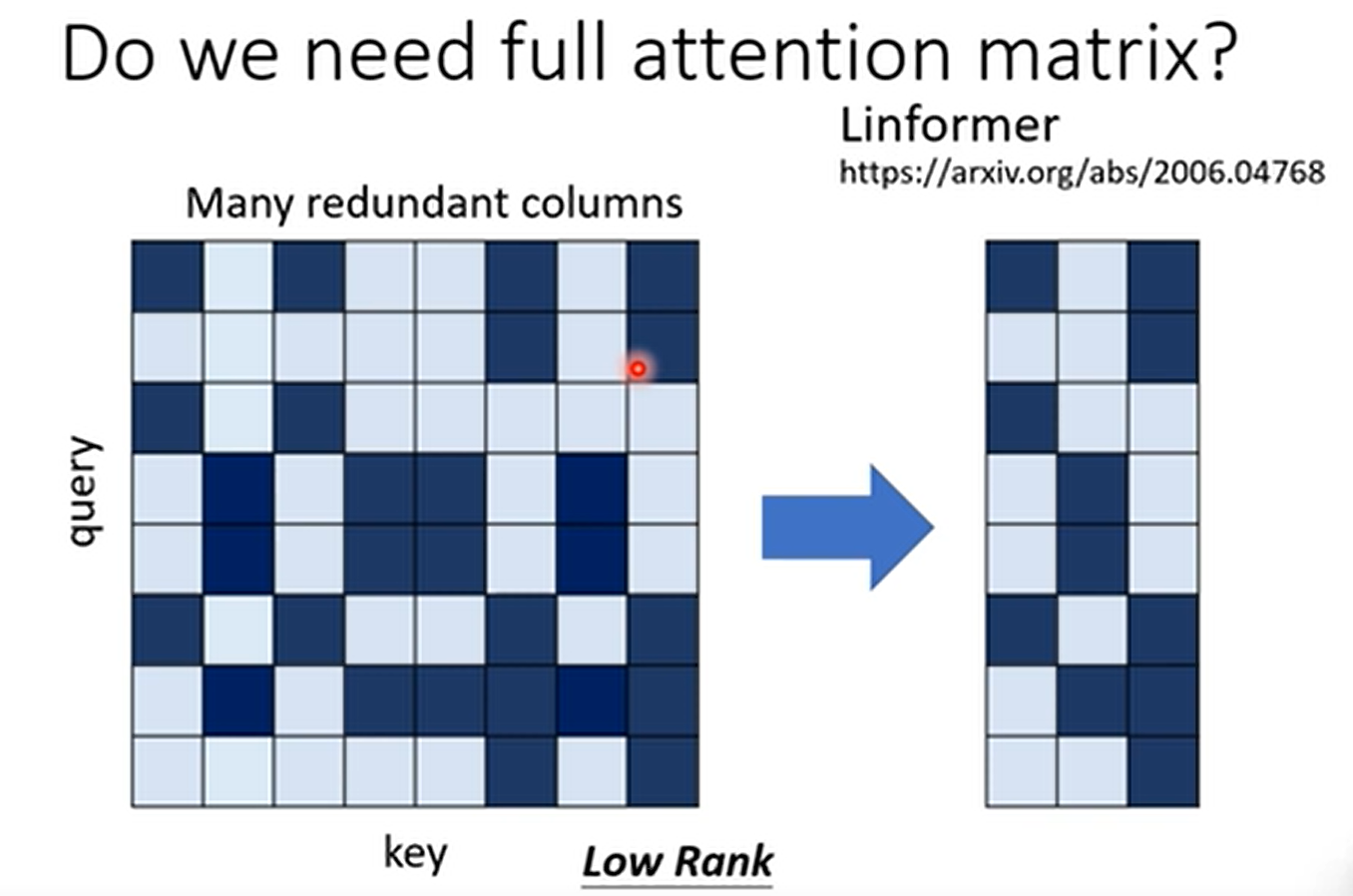
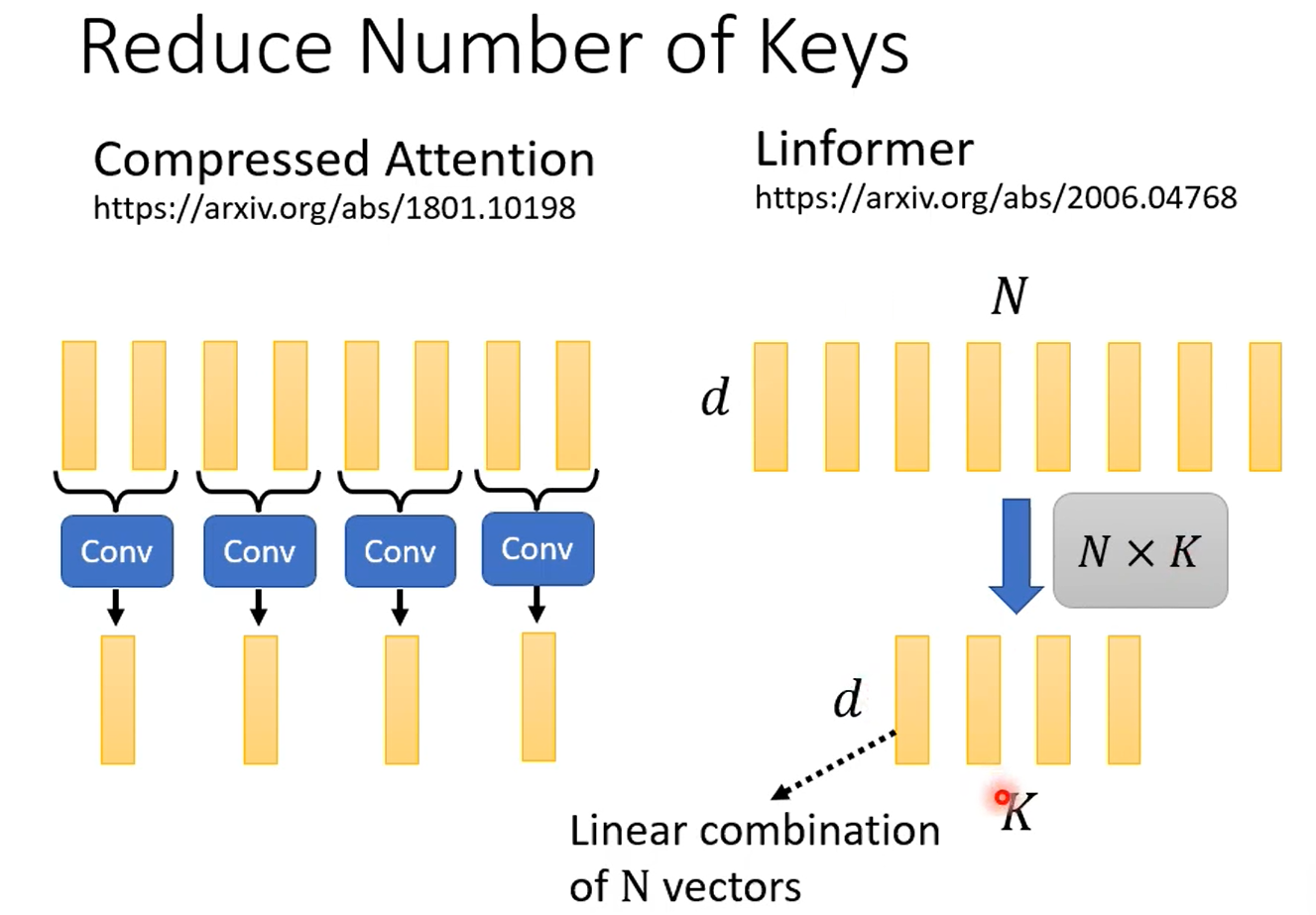
Linformer
发现是低秩矩阵,很多资讯重复,很多向量是相关的。
选用代表性的key,而不是有代表性的query,这样output length就不变,如果那种固定输出的,你可能可以用代表性query
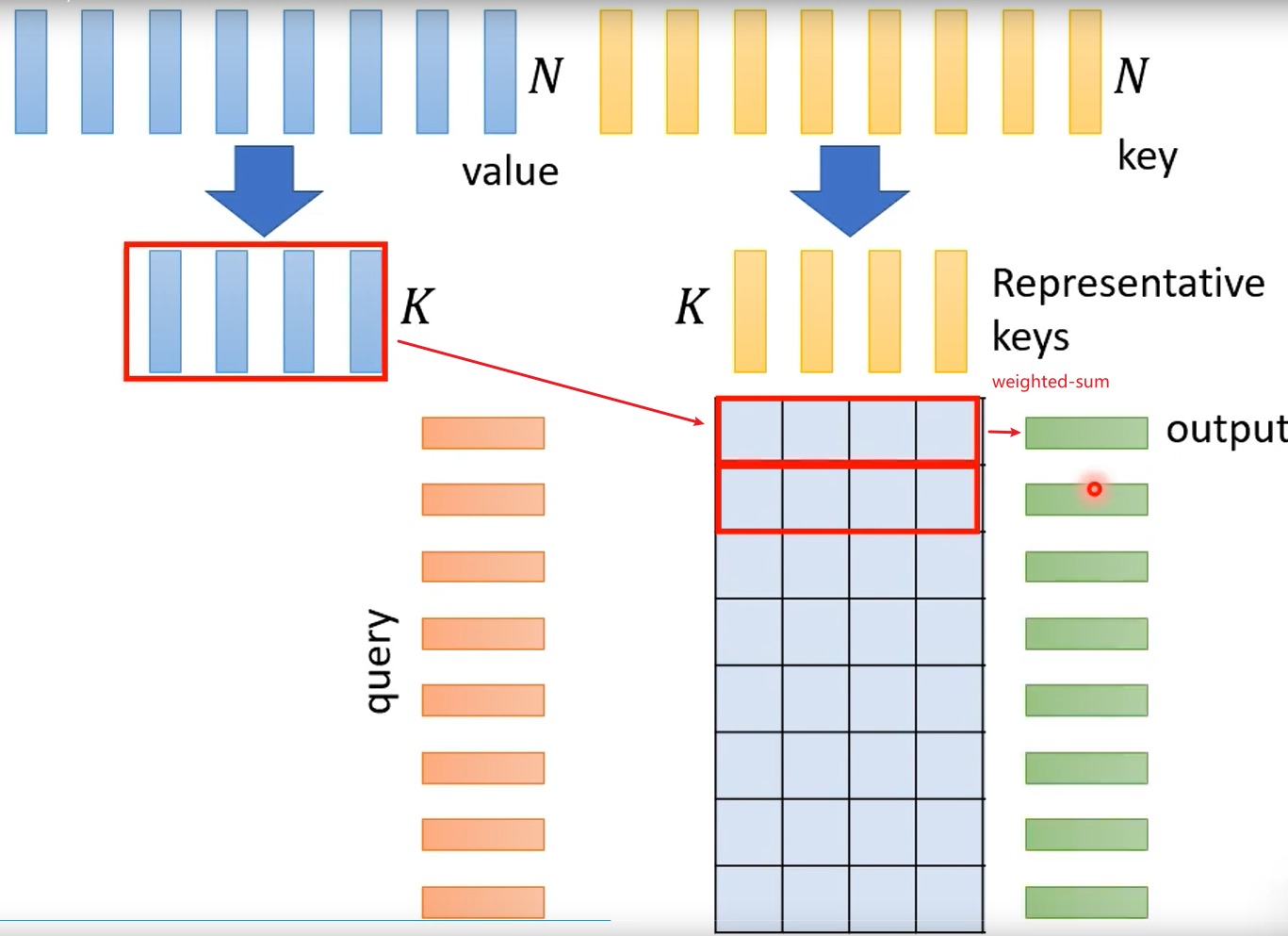
除了对K和Q做内积加速以外,整体计算也有优化到空间。
先暂时忽略softmax
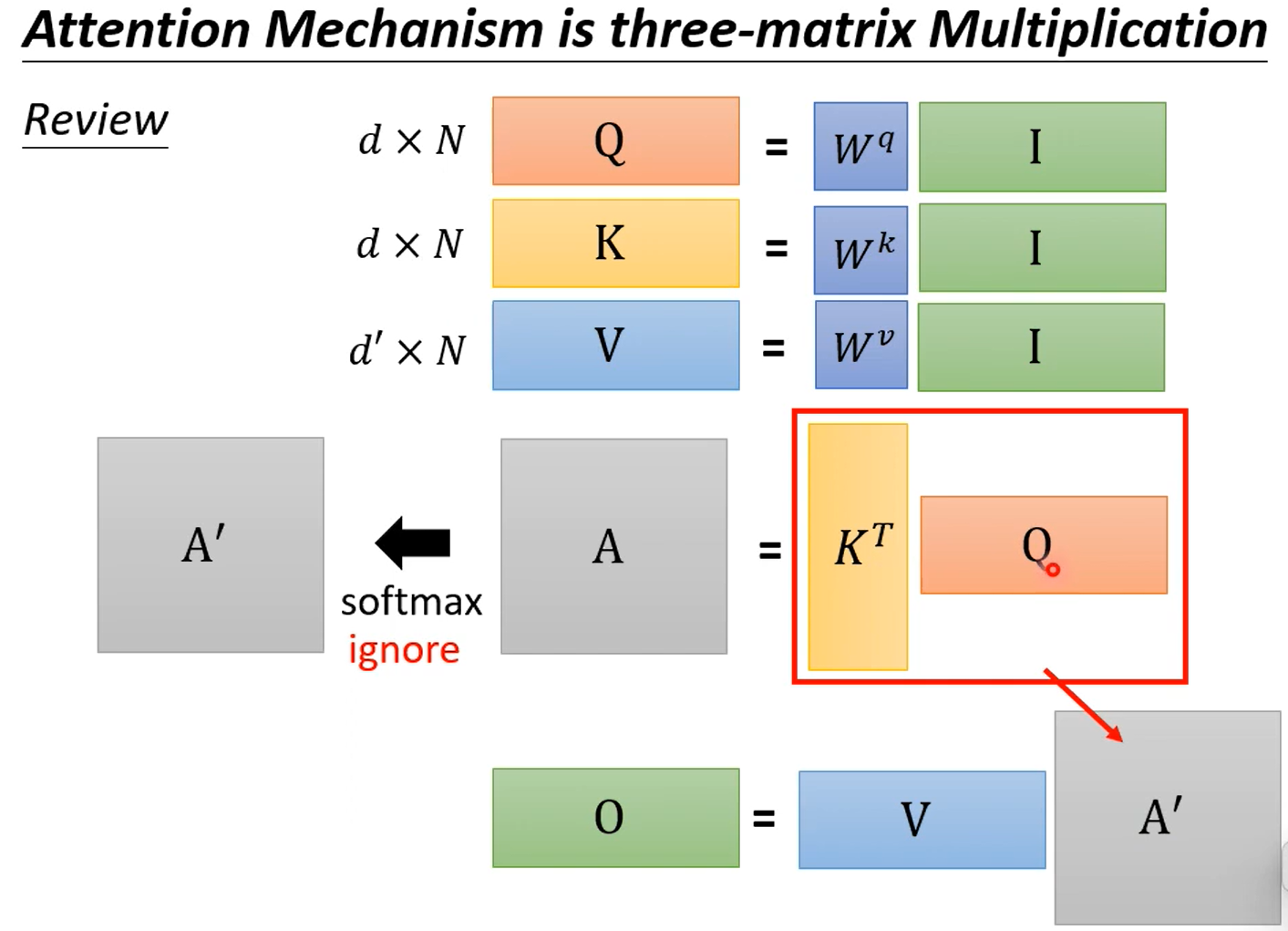
矩阵连乘,顺序不同,计算量不同,计算量为两矩阵共三个维度的积。哇哦!

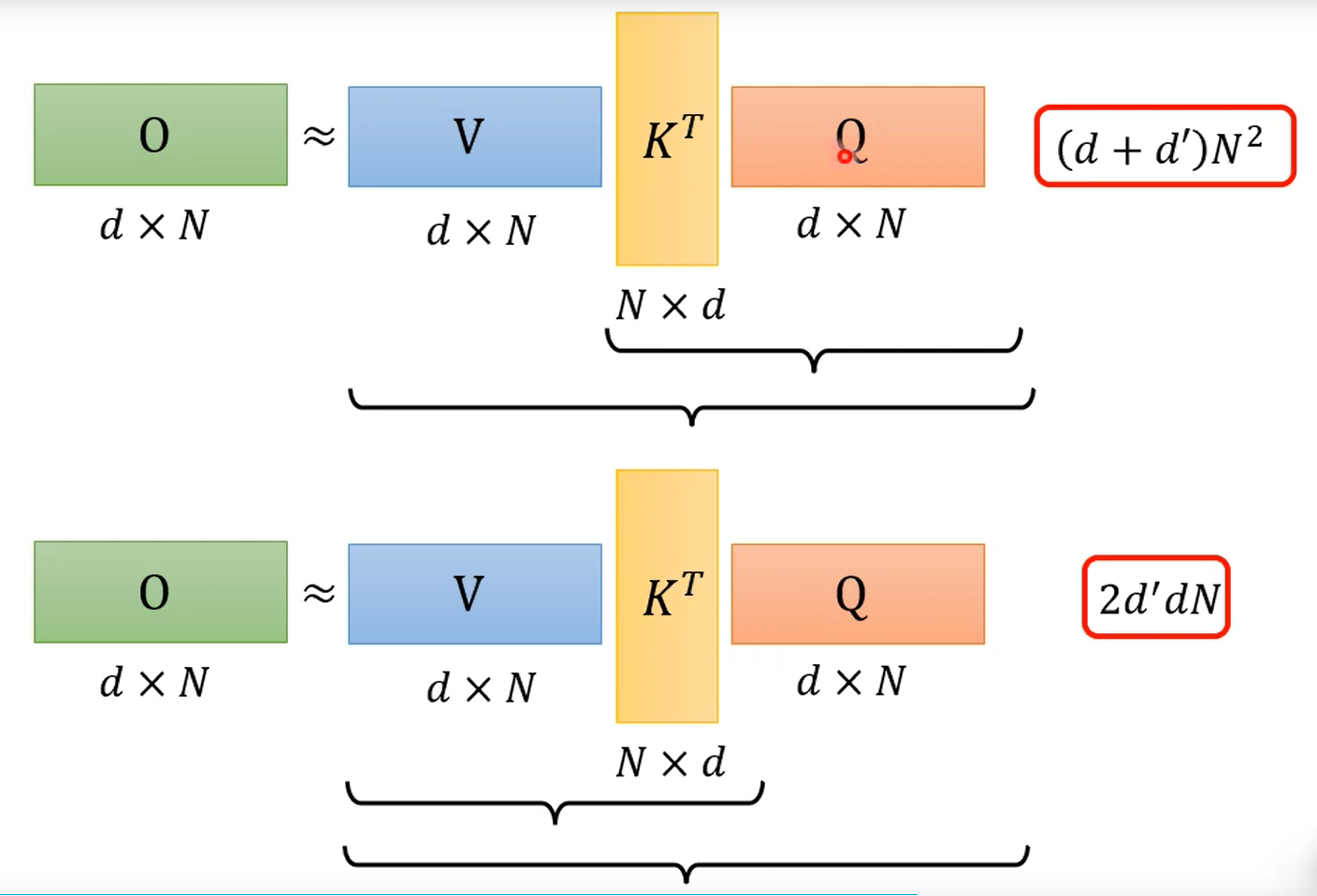
一把softmax加回去,数学就上去了。
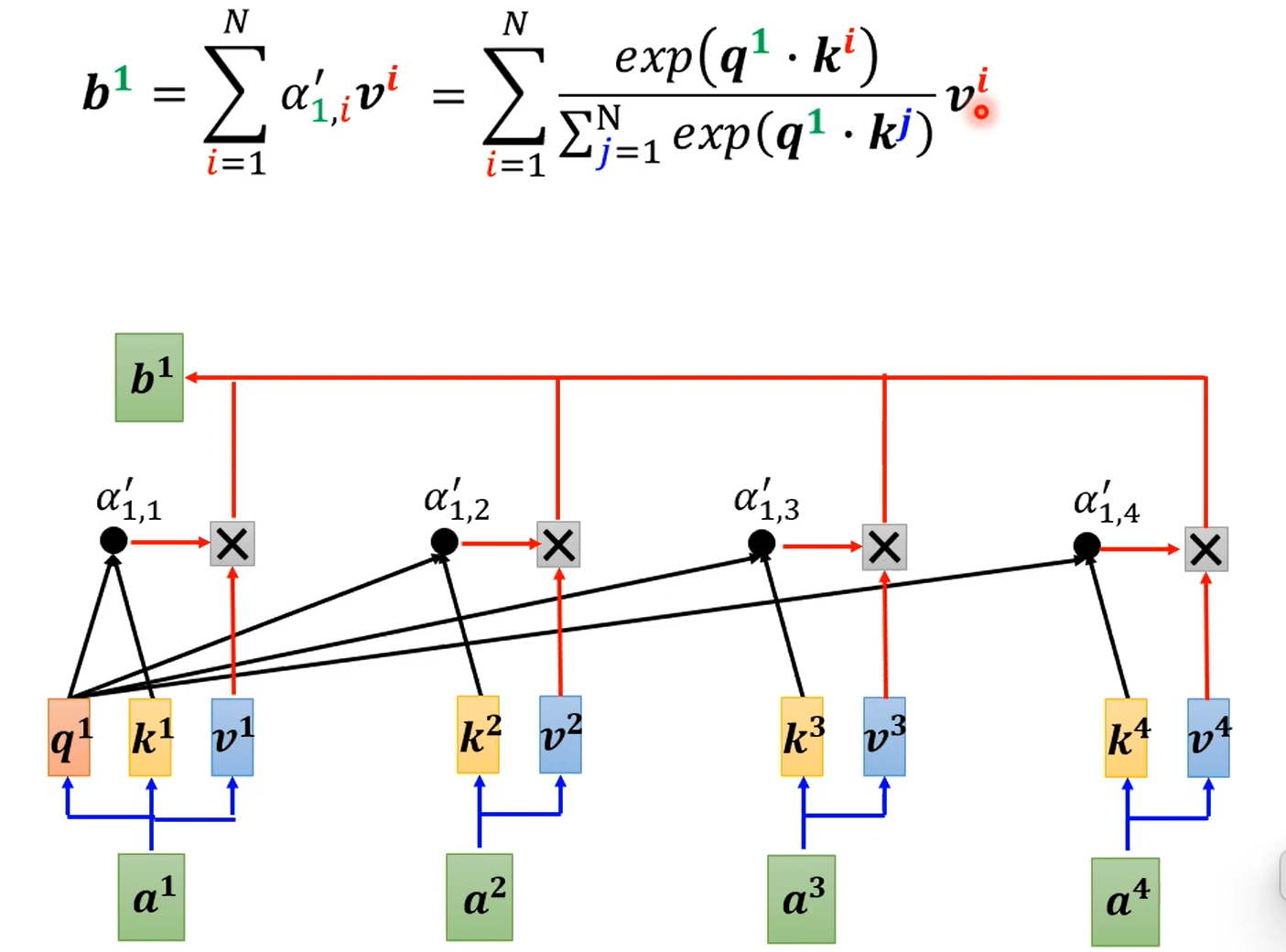
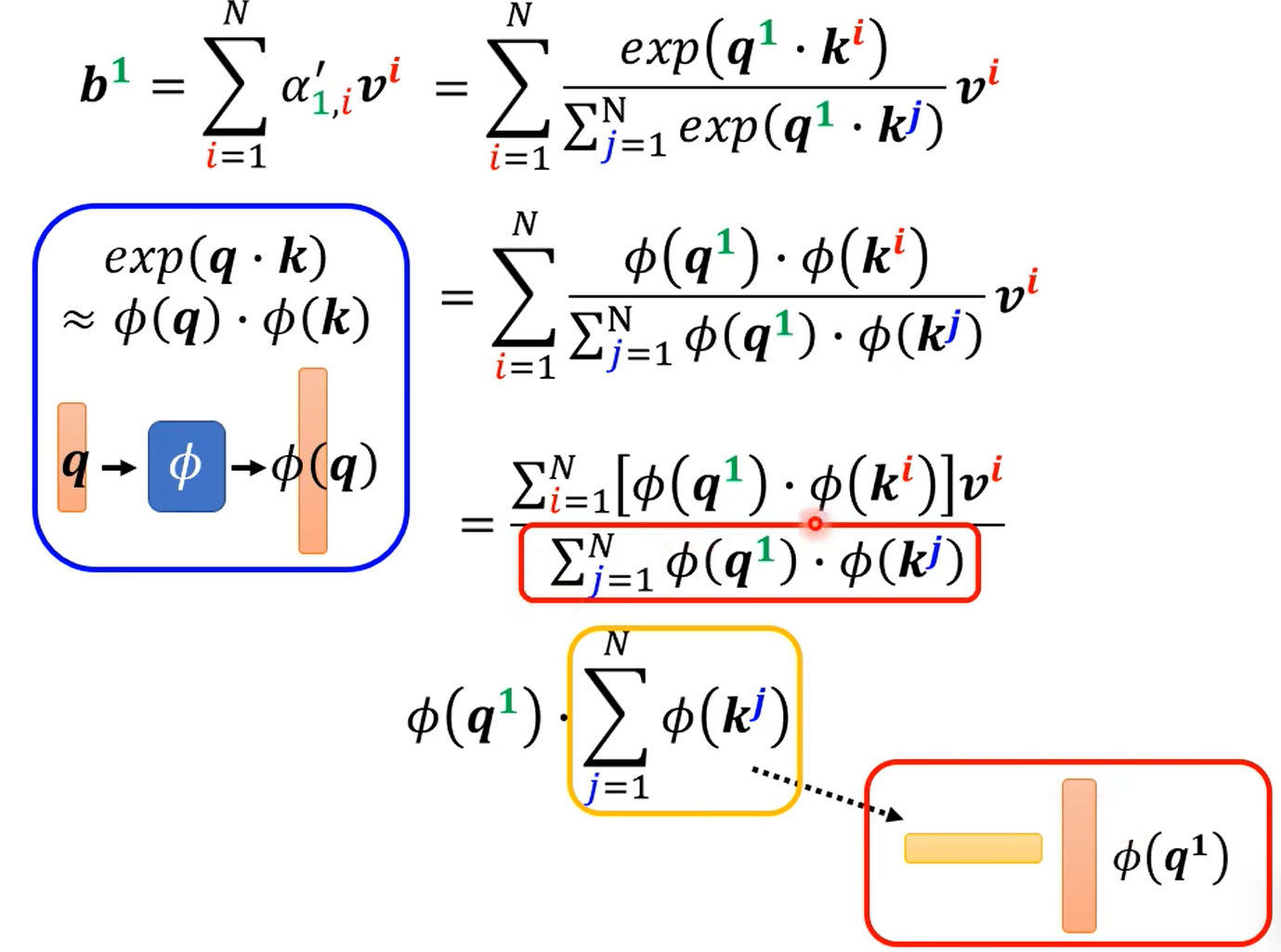
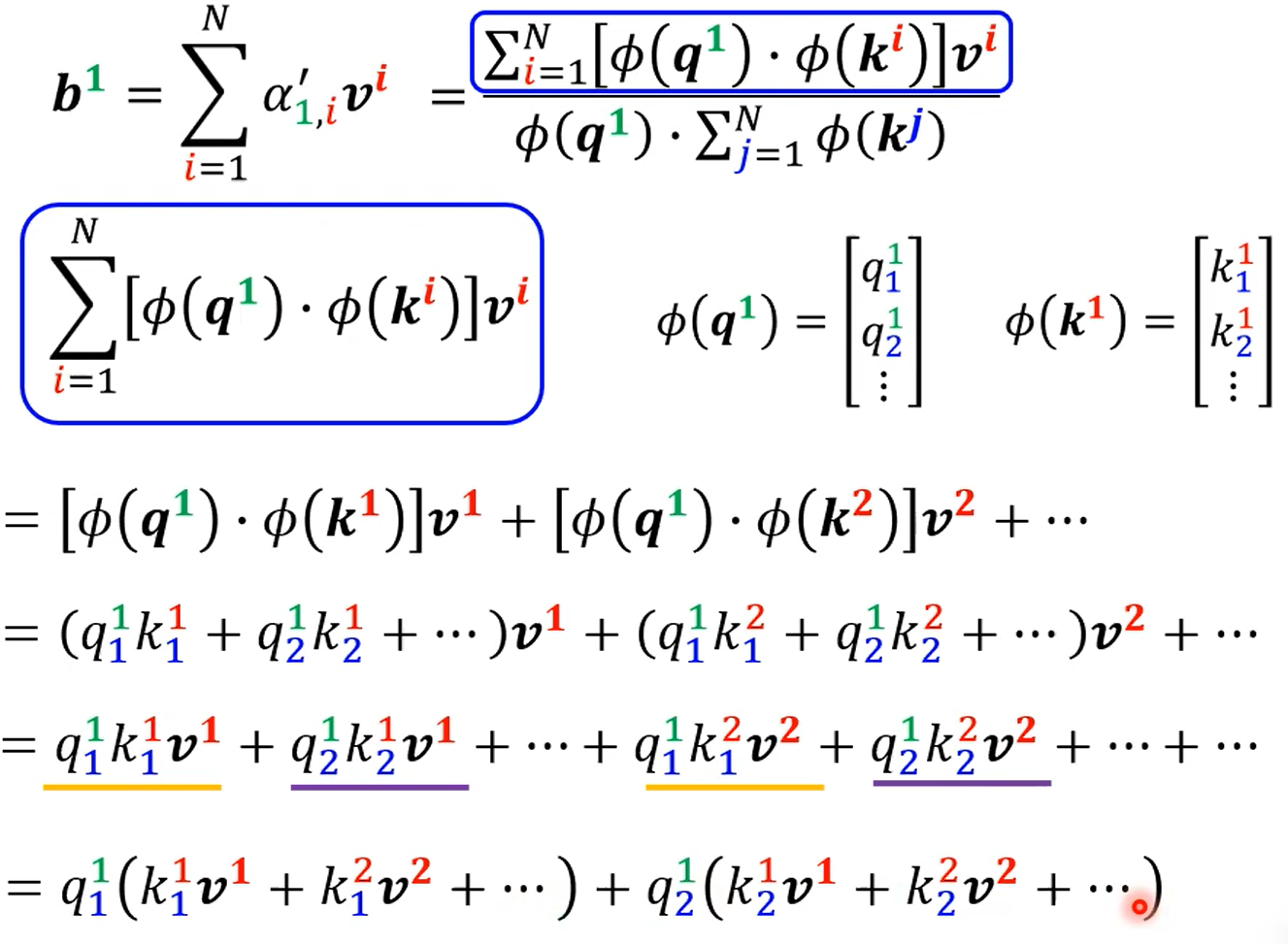
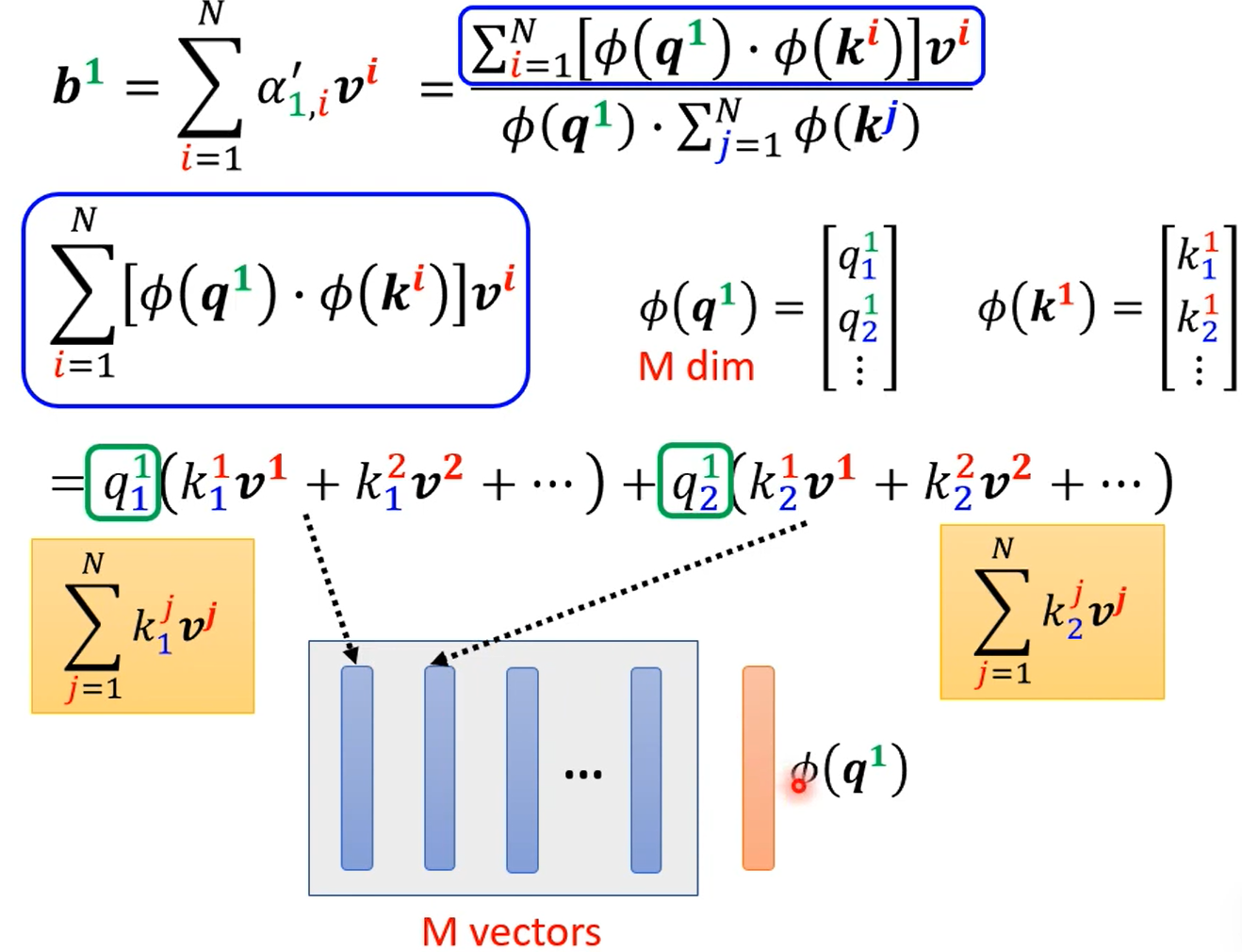
然后发现1,分子分母除了$\phi(q^i)$外,都与要算的$b^i$无关,因此一次算好,以后都不用算。
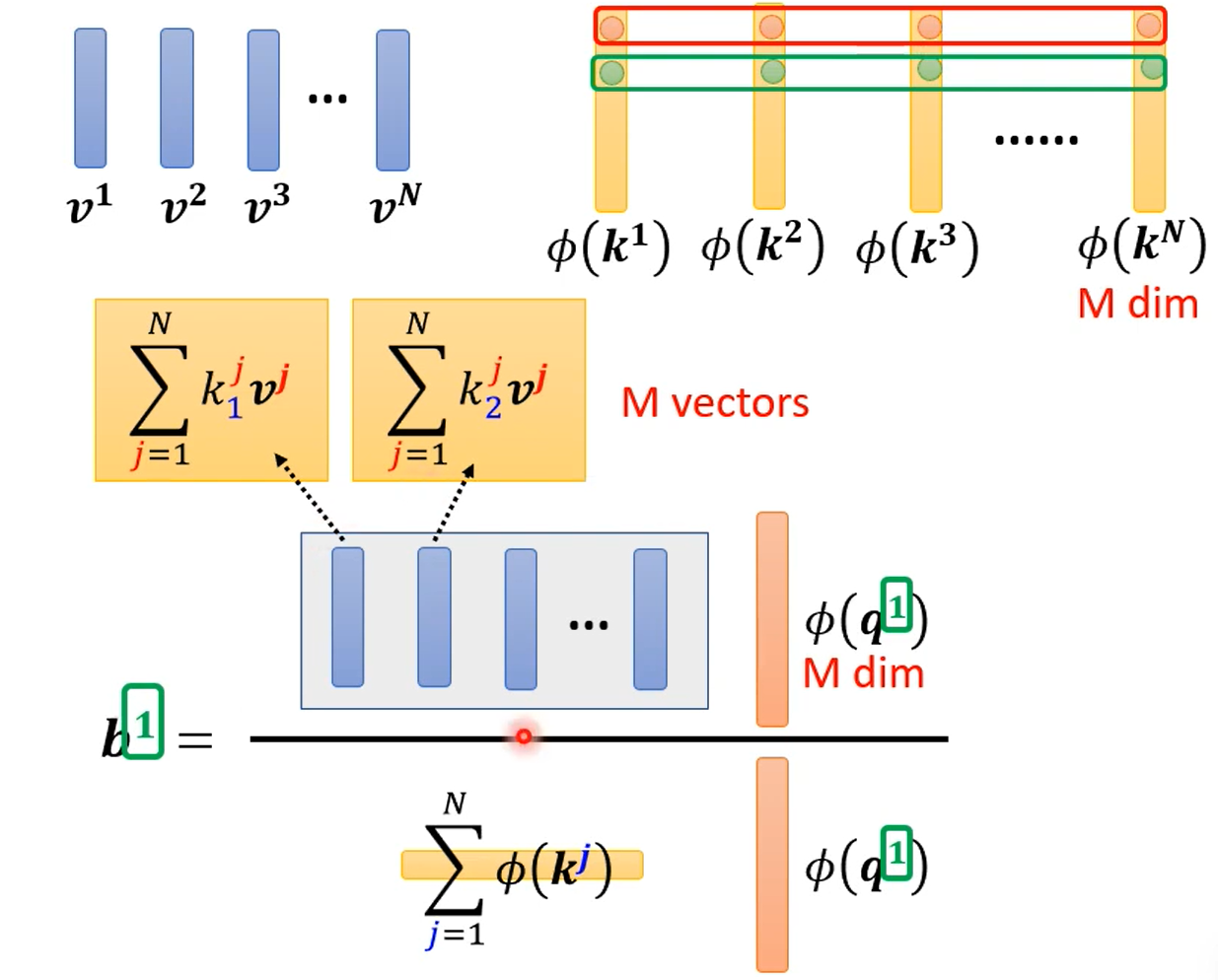
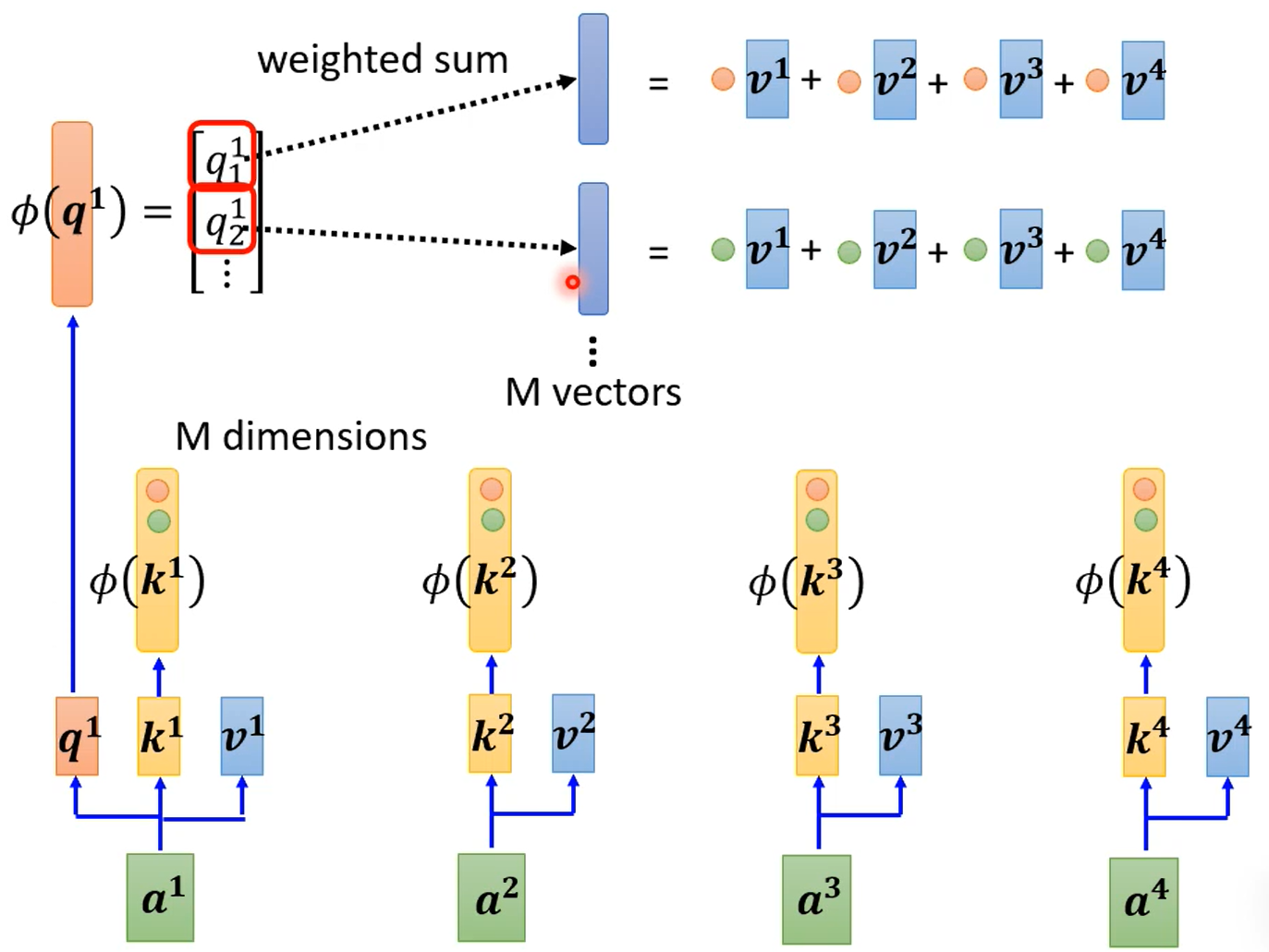
具体流程
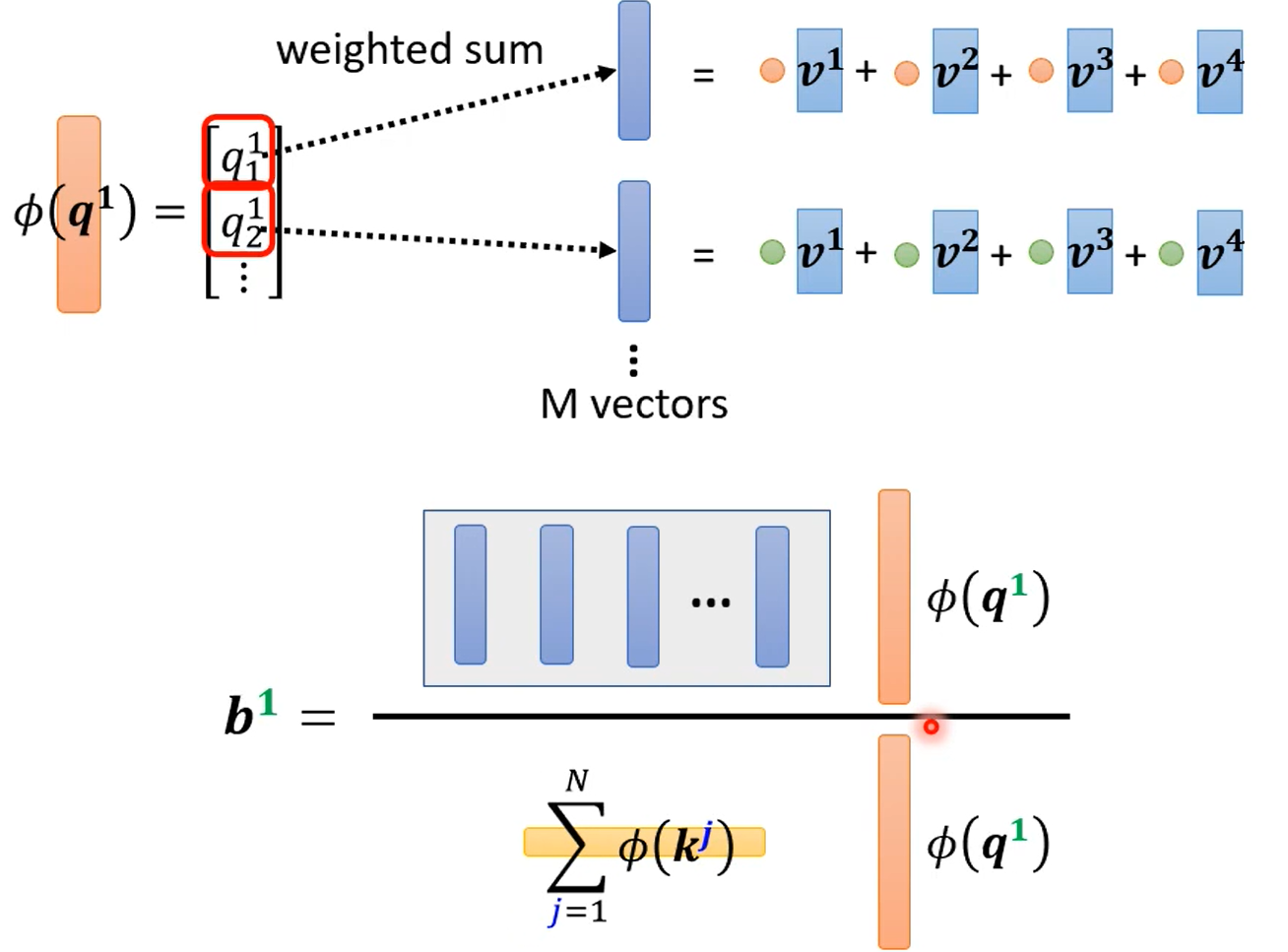
直观上的理解没有原来好,但是快呀。
不同文献给出了不同的$\phi$方法。
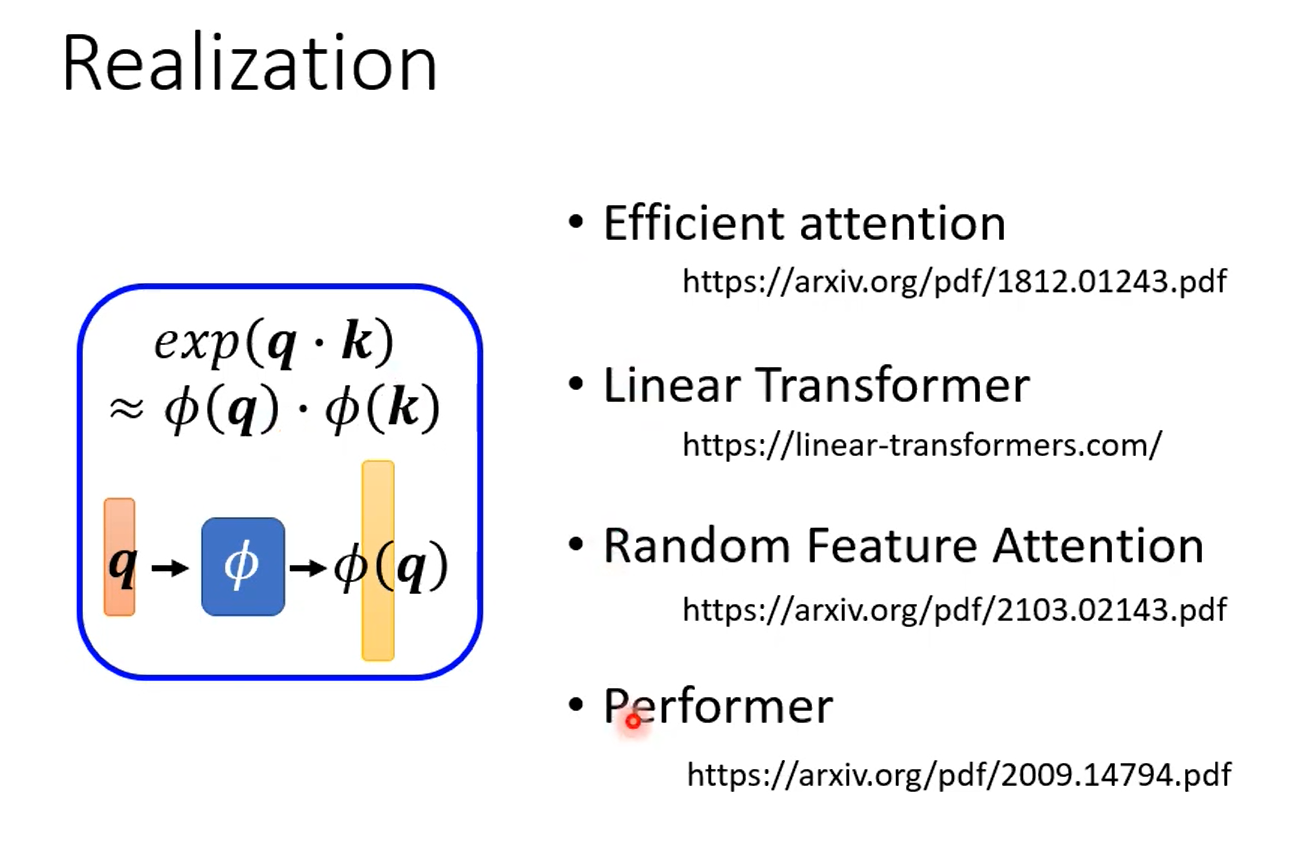
更多神奇的思考
把这个矩阵直接当成参数,根本不需要算。。。 以前丢了recurrent,现在想丢掉attention

Graph
Spatial
why:

人际关系图找凶手,人物之间的关系可以帮助我们提高识别凶手的准确率。
图非常大,不可能给所有的data都做labeling,如何利用有限的label和graph本身的structure训练出不错的模型【一般unlabelled更多】

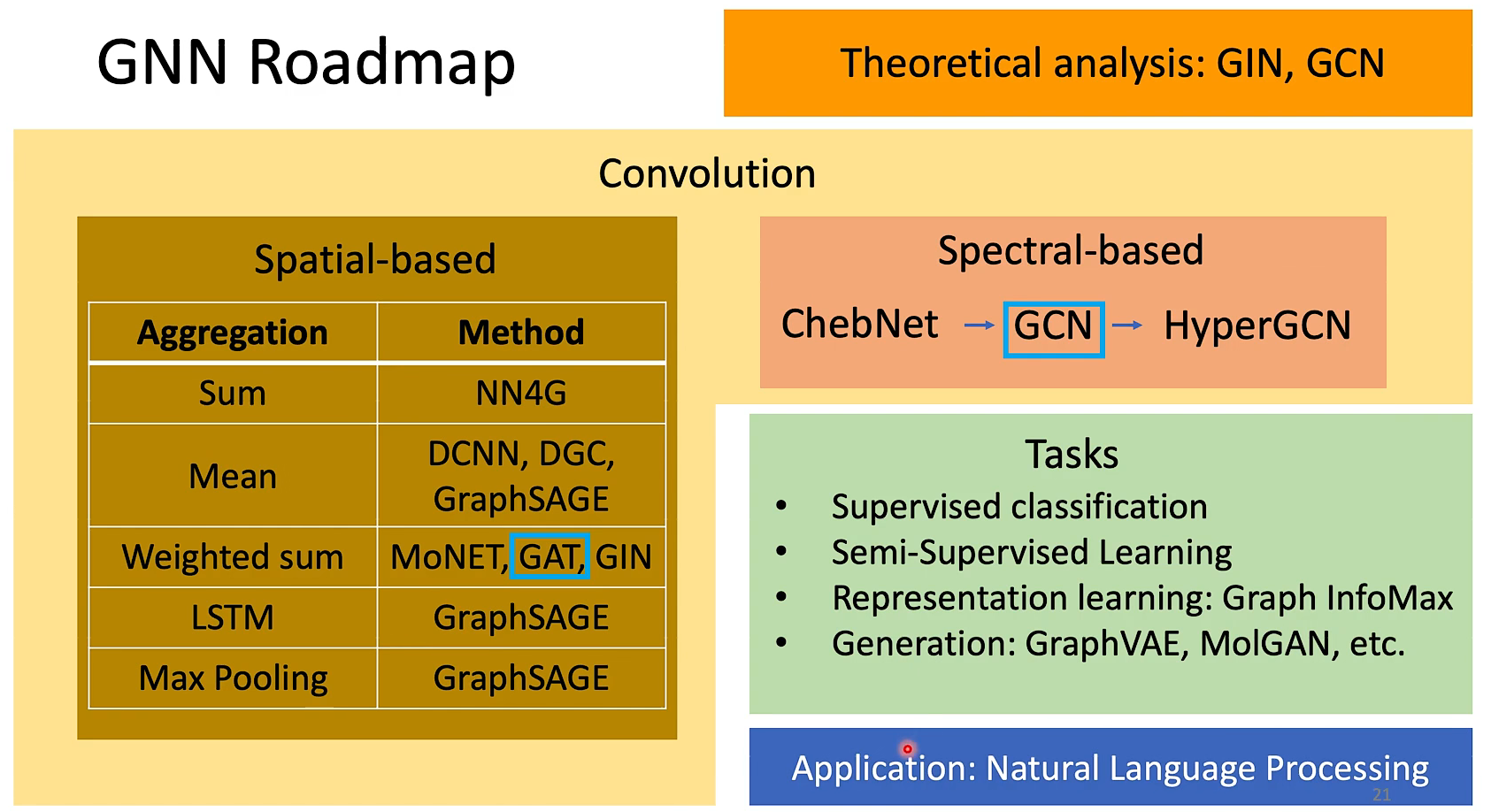
很酷的路线图,其中用的最多的是圈起来的GCN和GAT
Representation learning is a very important aspect of machine learning which automatically discovers the feature patterns in the data.
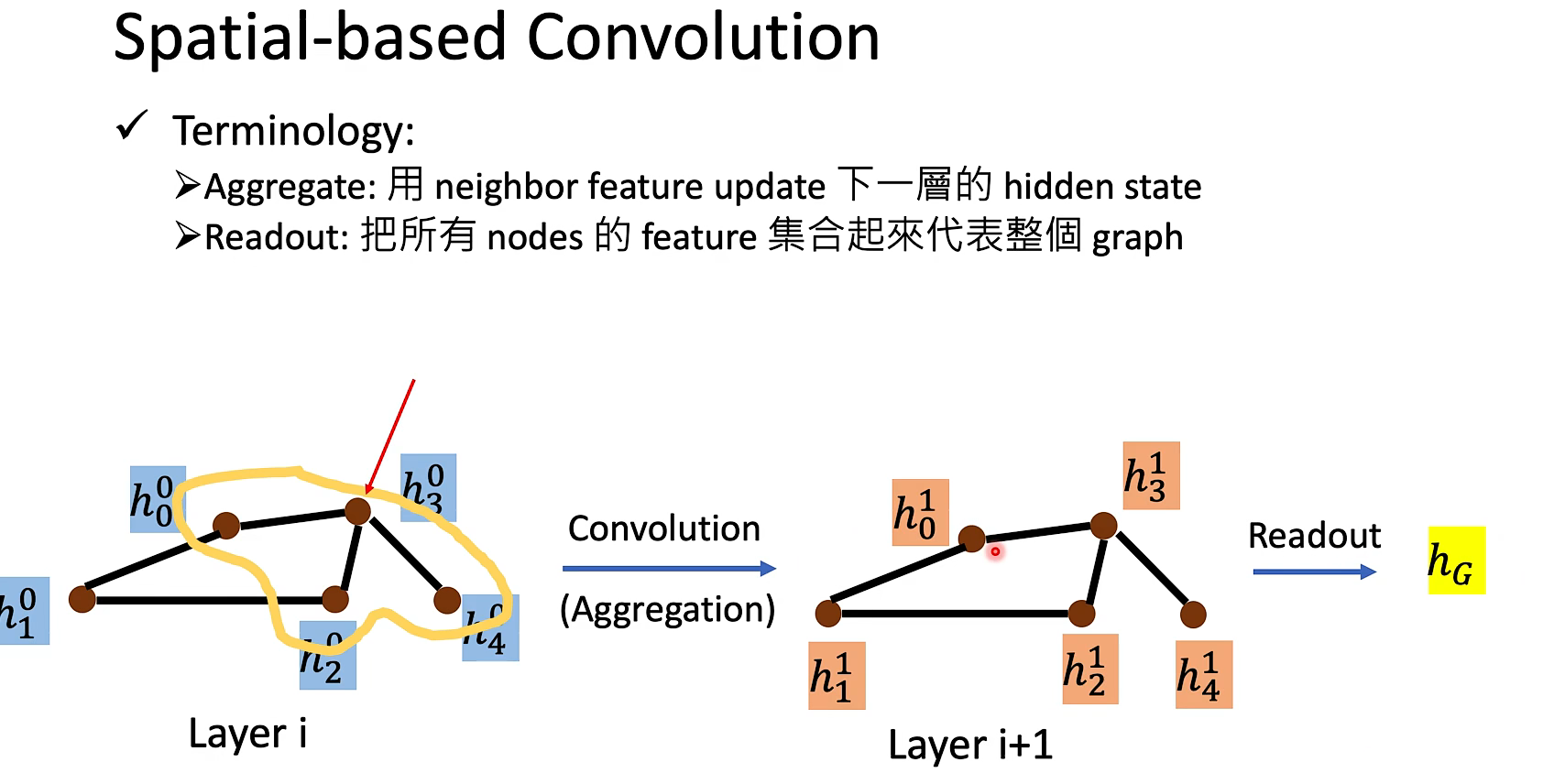
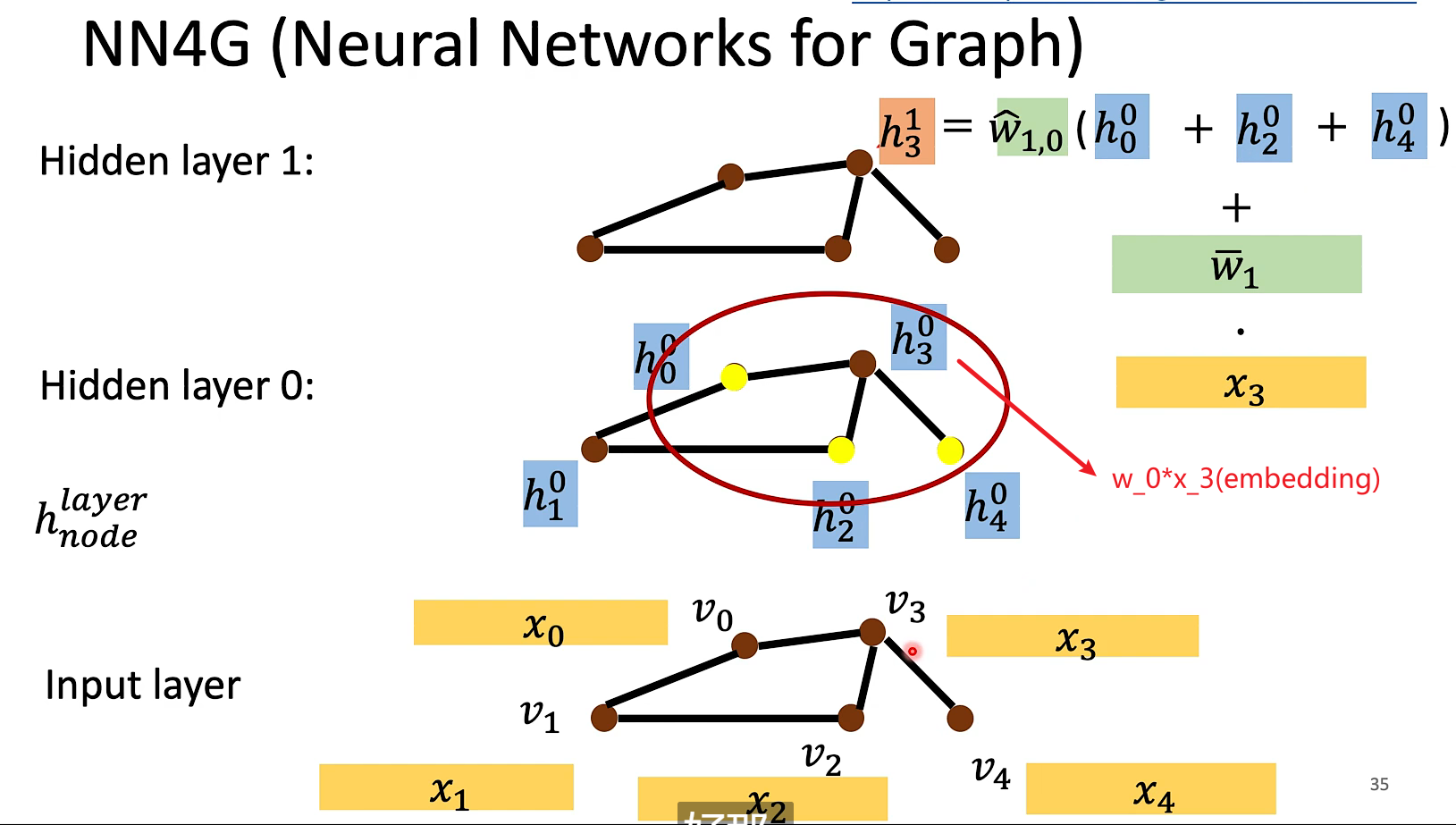
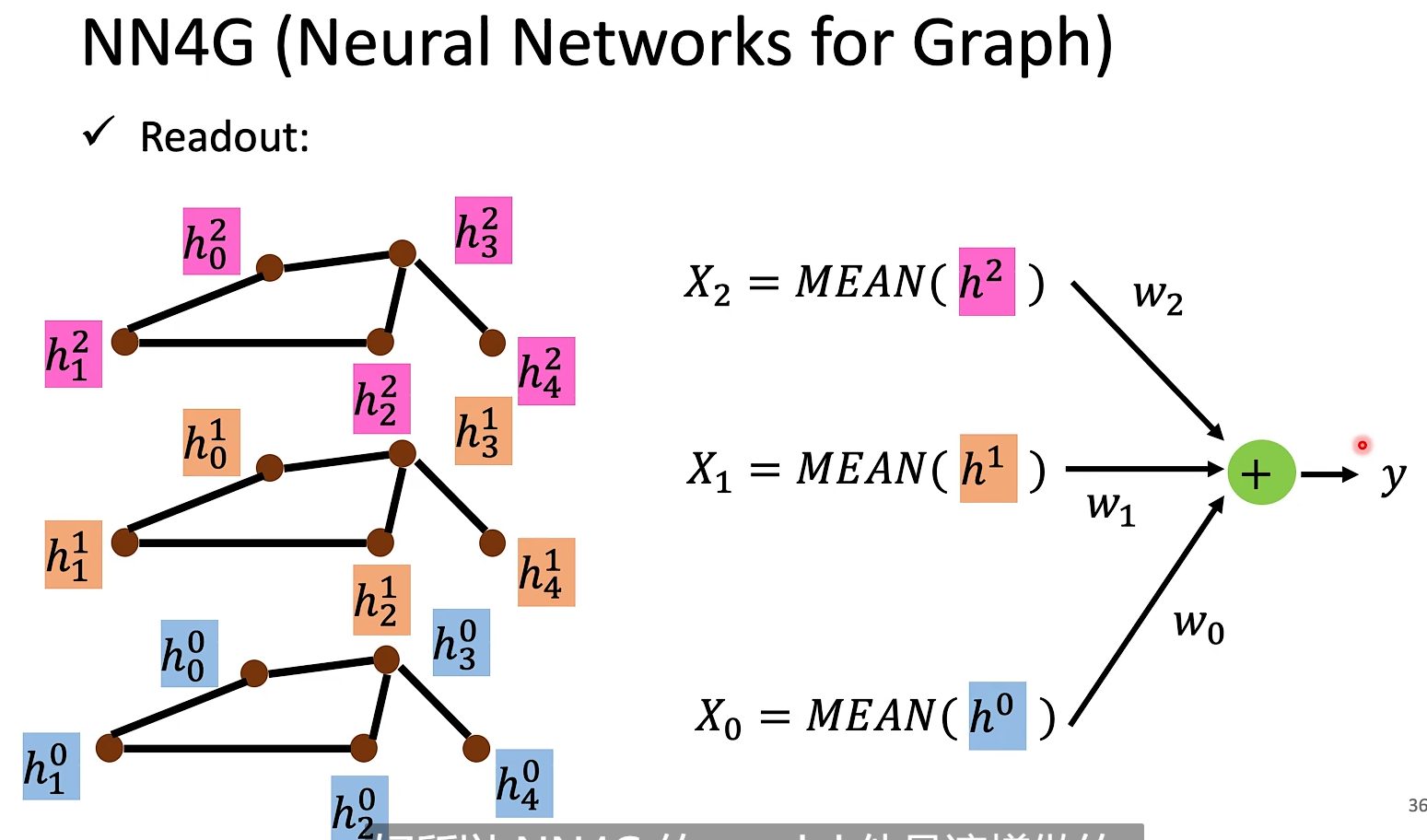
NN4G
DCNN
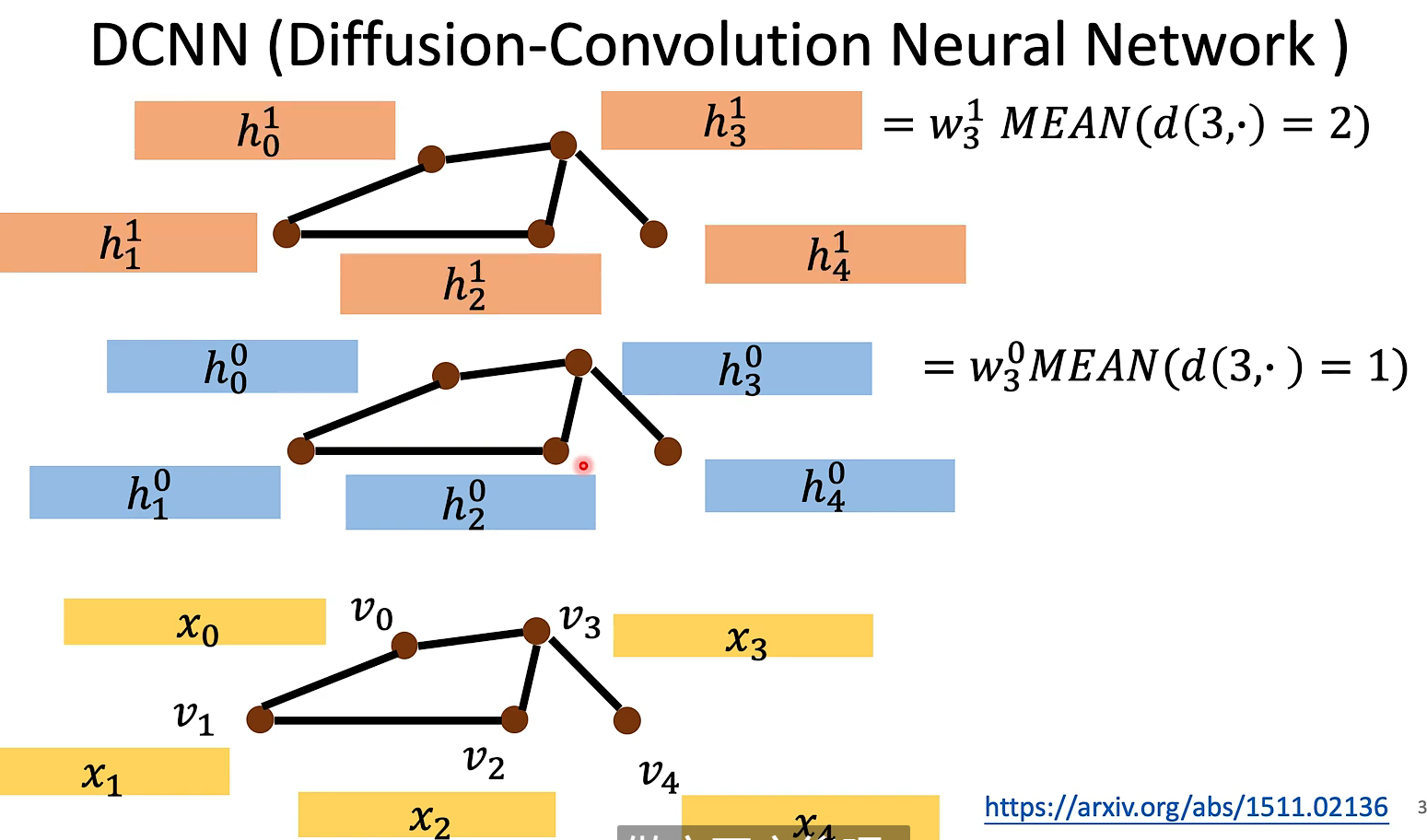
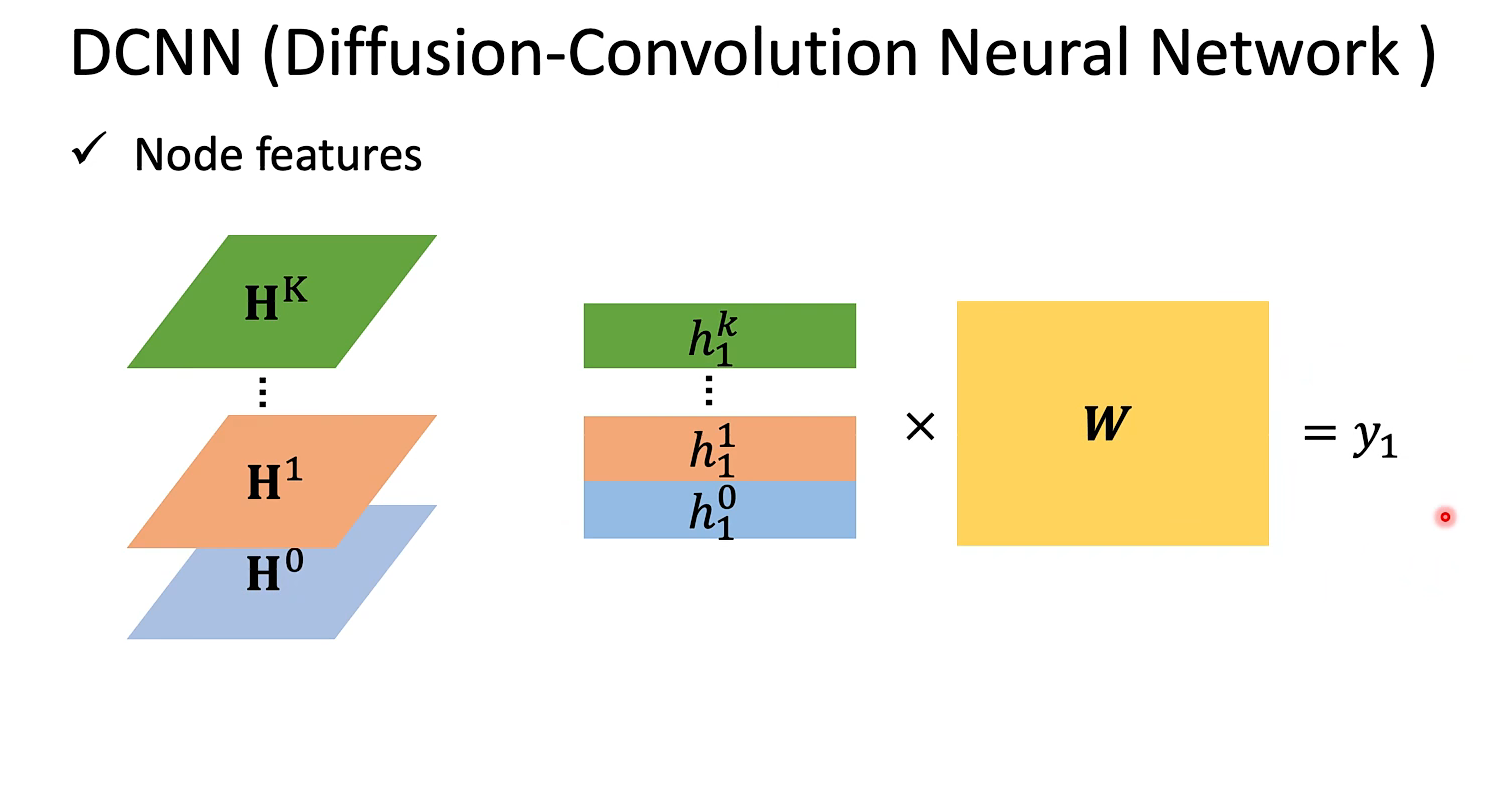
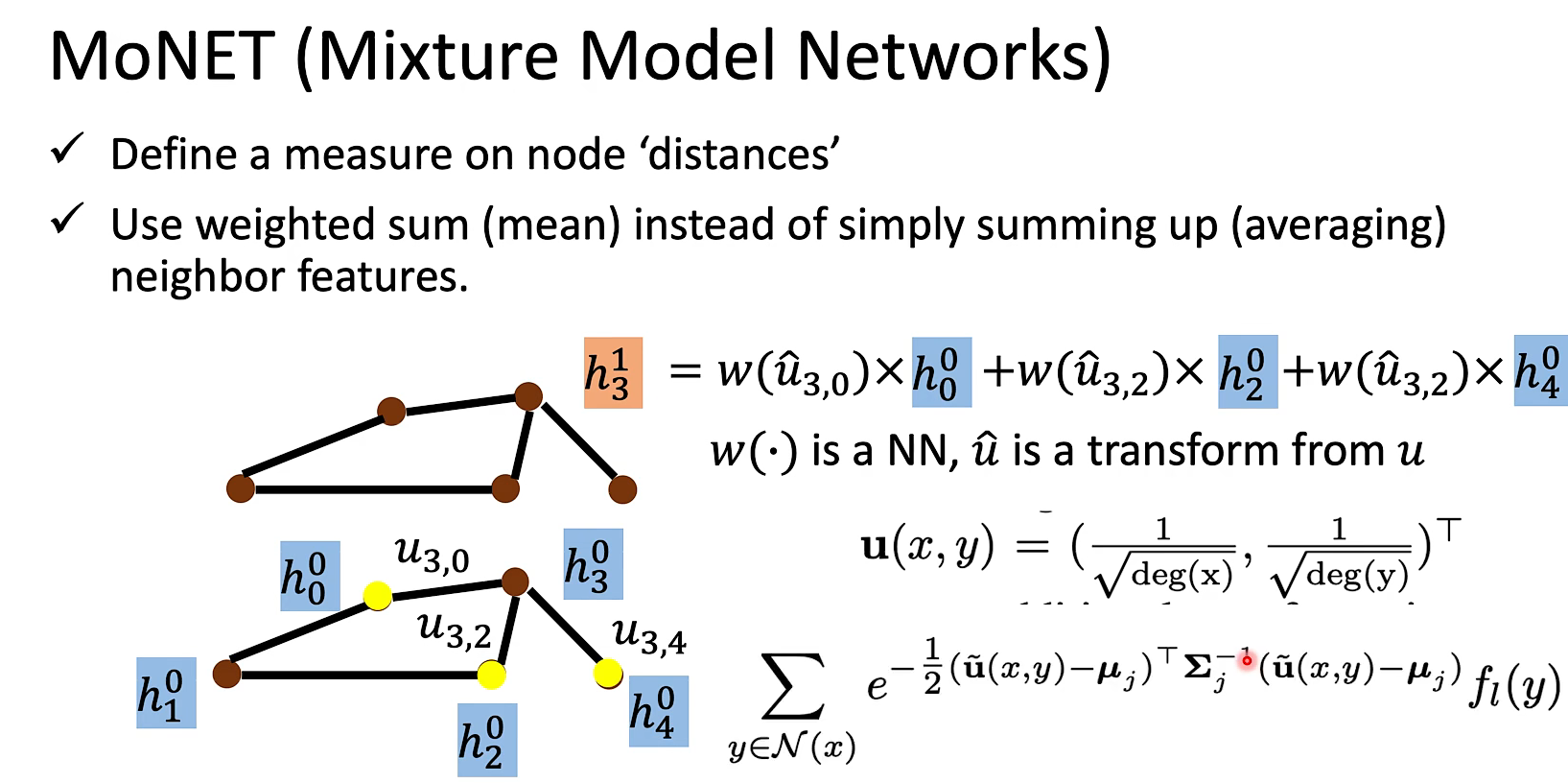
MoNET就是处理了NN4G最后相加这个手法太粗糙的问题。(定义了一个距离的概念充当权重)
但是,凡是能自己定的,为什么不让model自己学呢,后面会讲到。
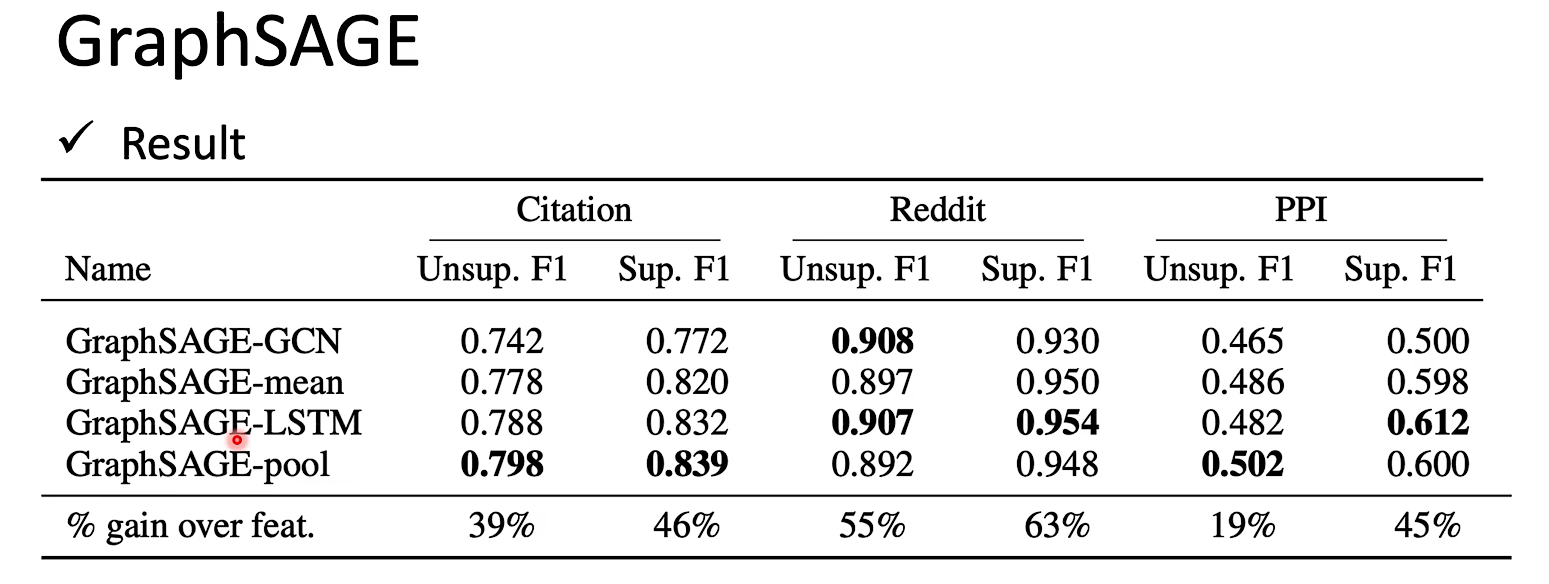
GraphSAGE有好几种aggregate方式,甚至可以把邻居的feature喂到LSTM里,最后输出一个hidden stage用来做aggregate。【当然LSTM在实际测试结果不见得特别好。】
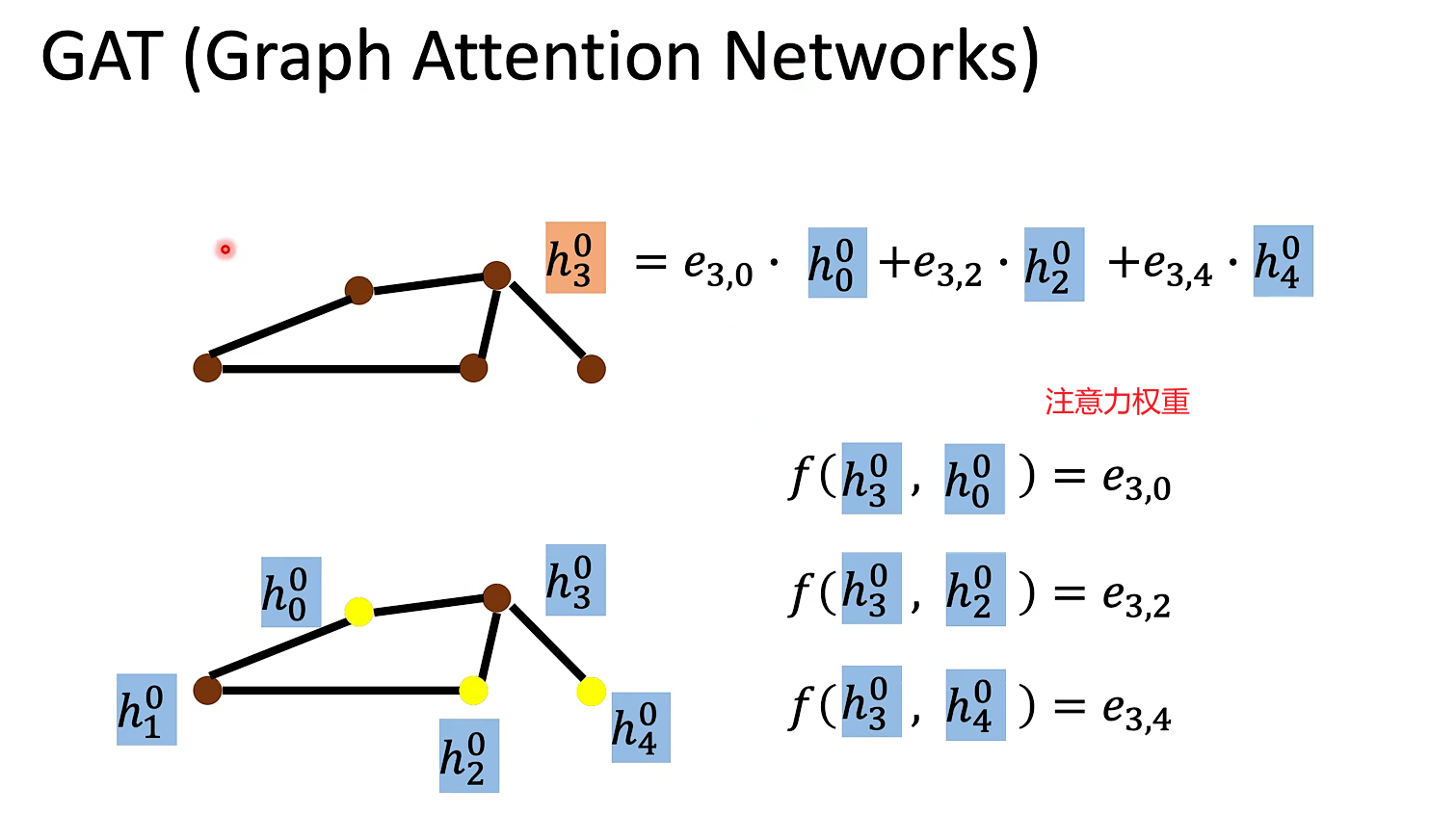
GAT(Graph Attention Networks)
对邻居做attention
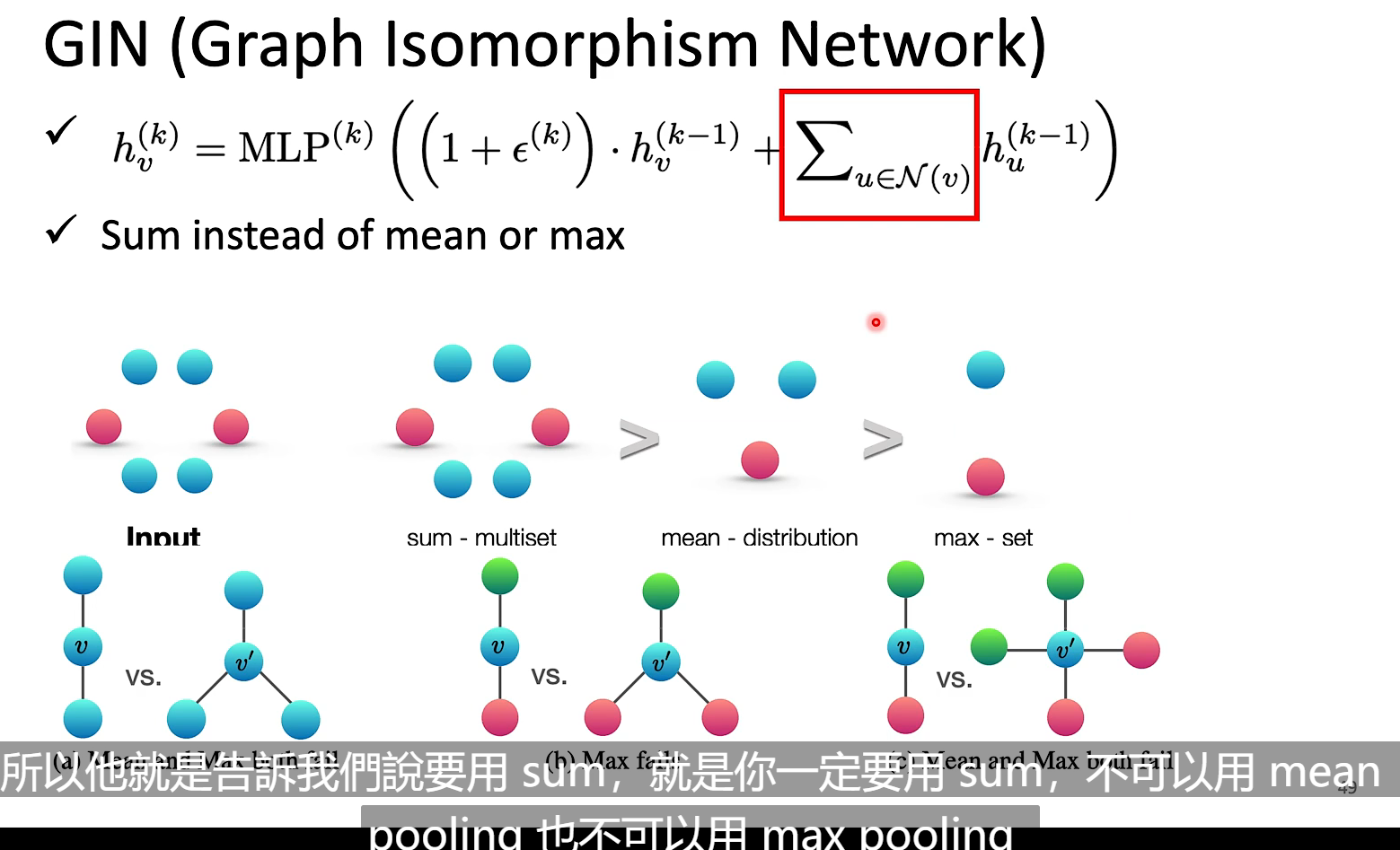
GIN给出了一些理论证明,结论是要用sum,不用mean或者max pooling【todo】
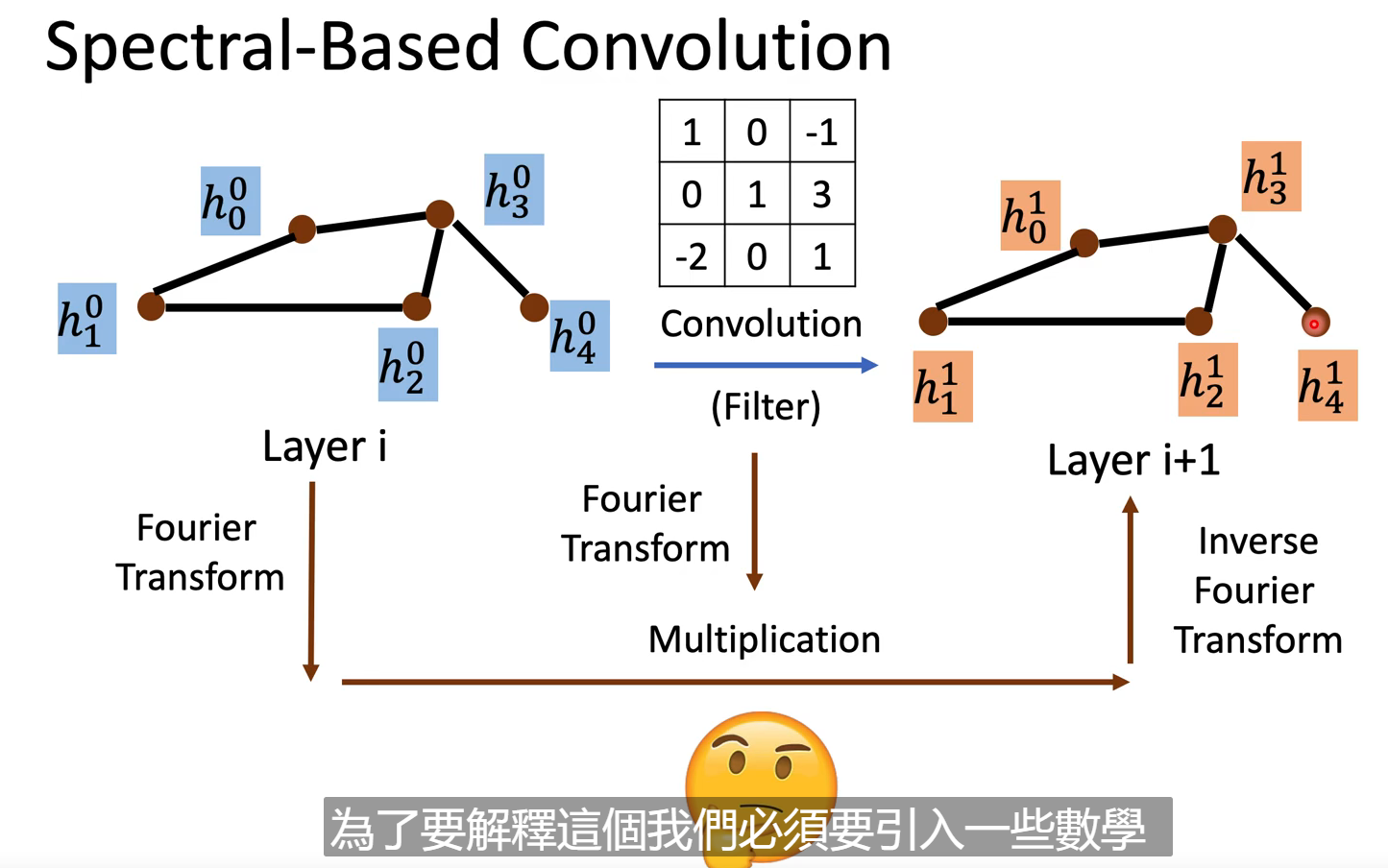
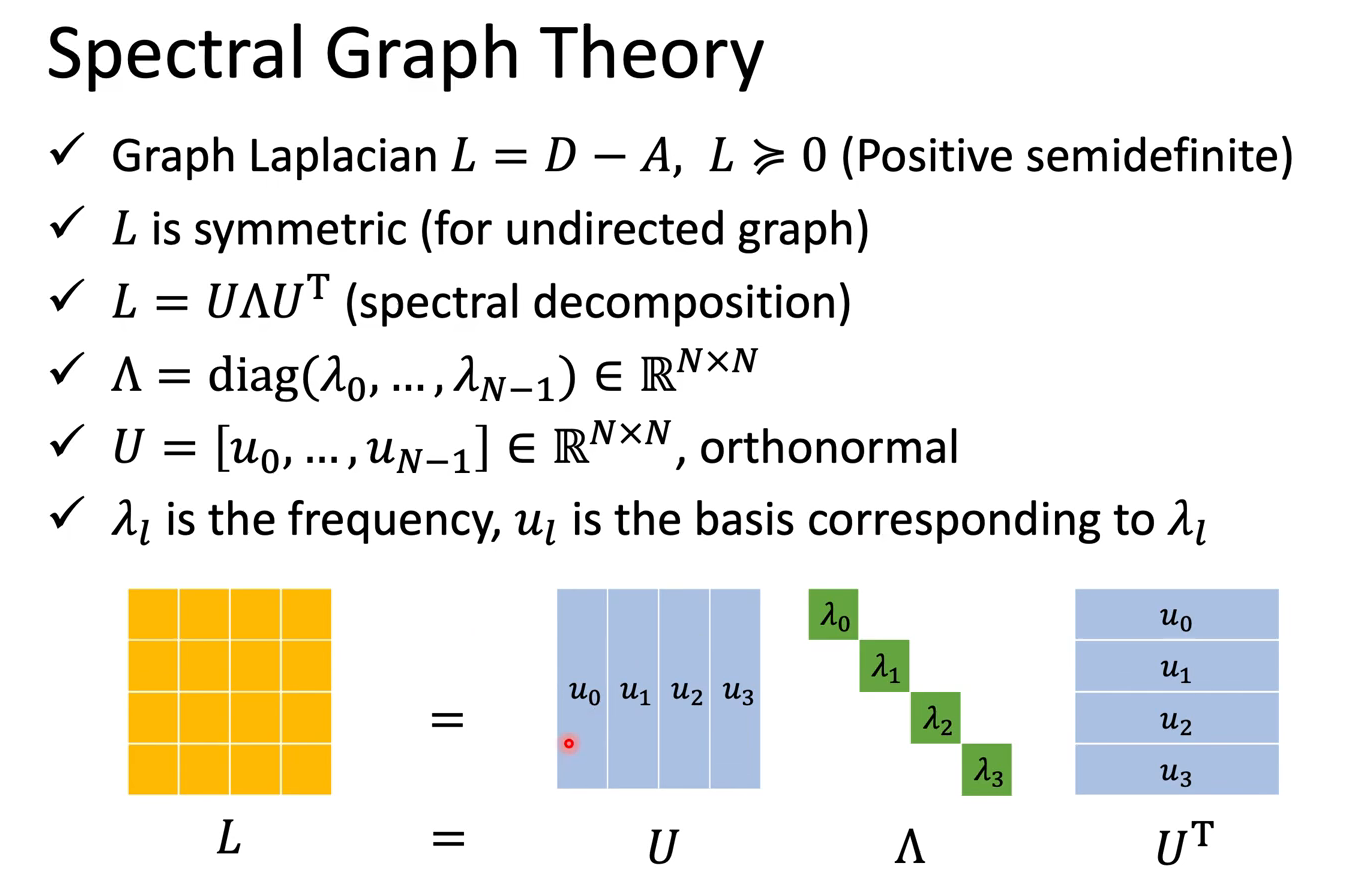
Spectral
CNN要做的是学出一个filter,这相当于频域里的一个乘法,那么在GNN中该如何实现呢?请看理论解释:
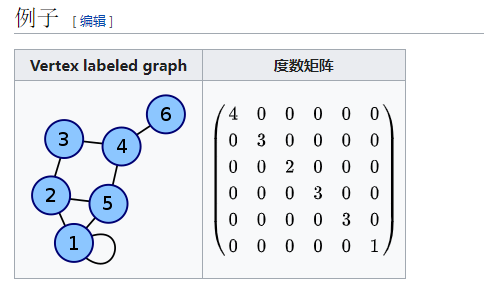
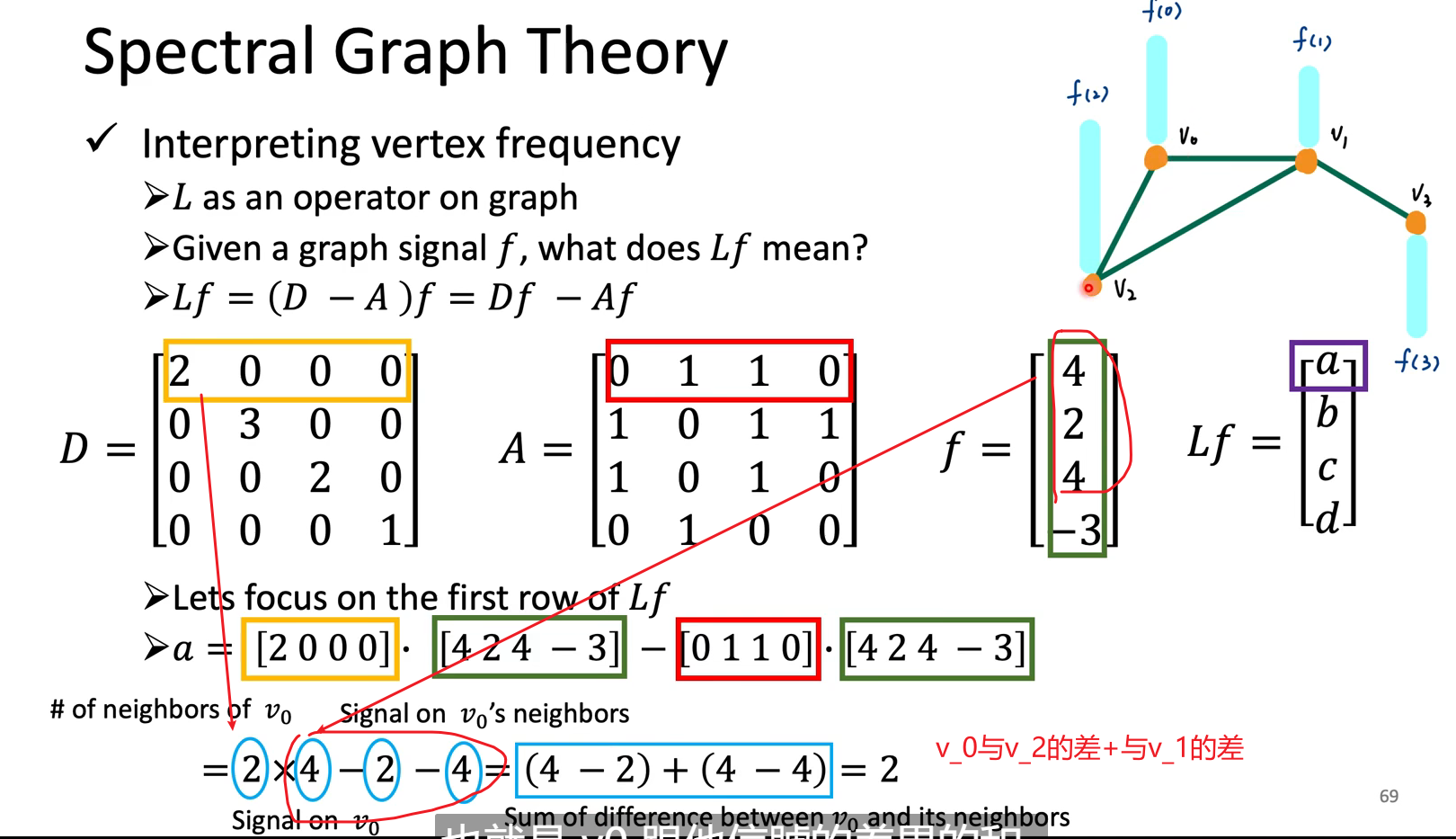
一些相关背景知识:A连接矩阵代表哪些节点相连(假设对称),D度数矩阵代表每一个节点有几个邻居,节点向量 f 代表signal

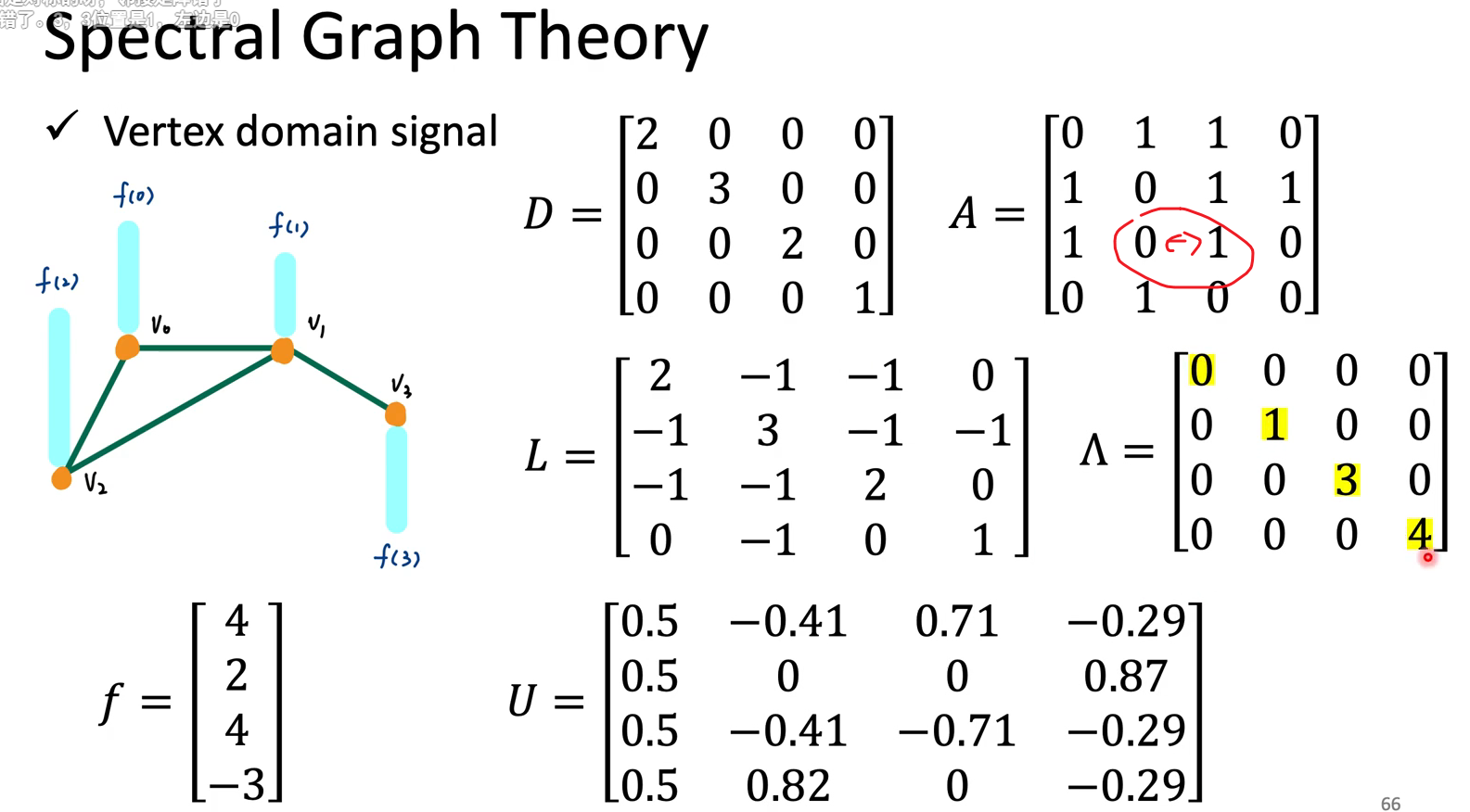
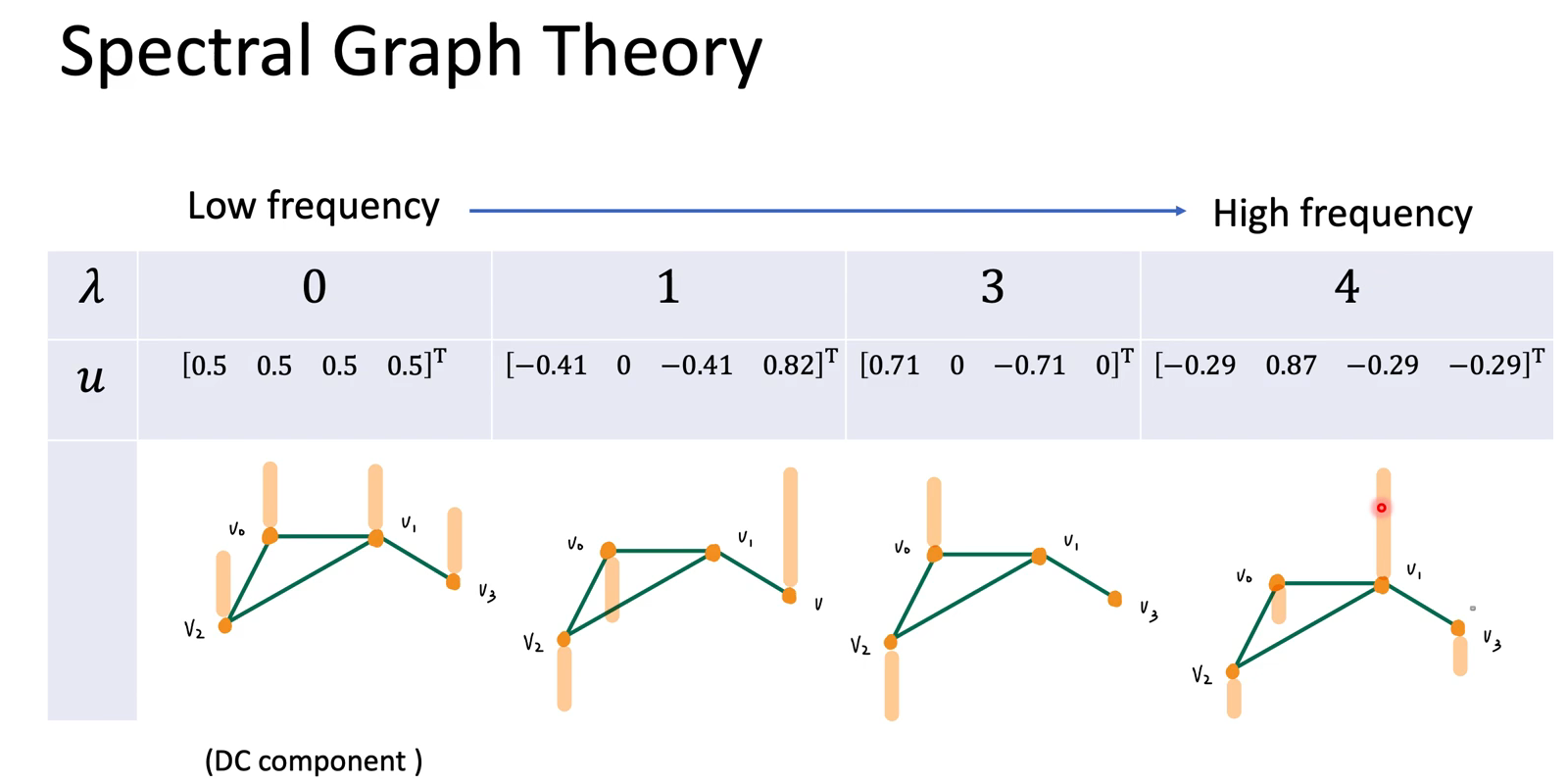
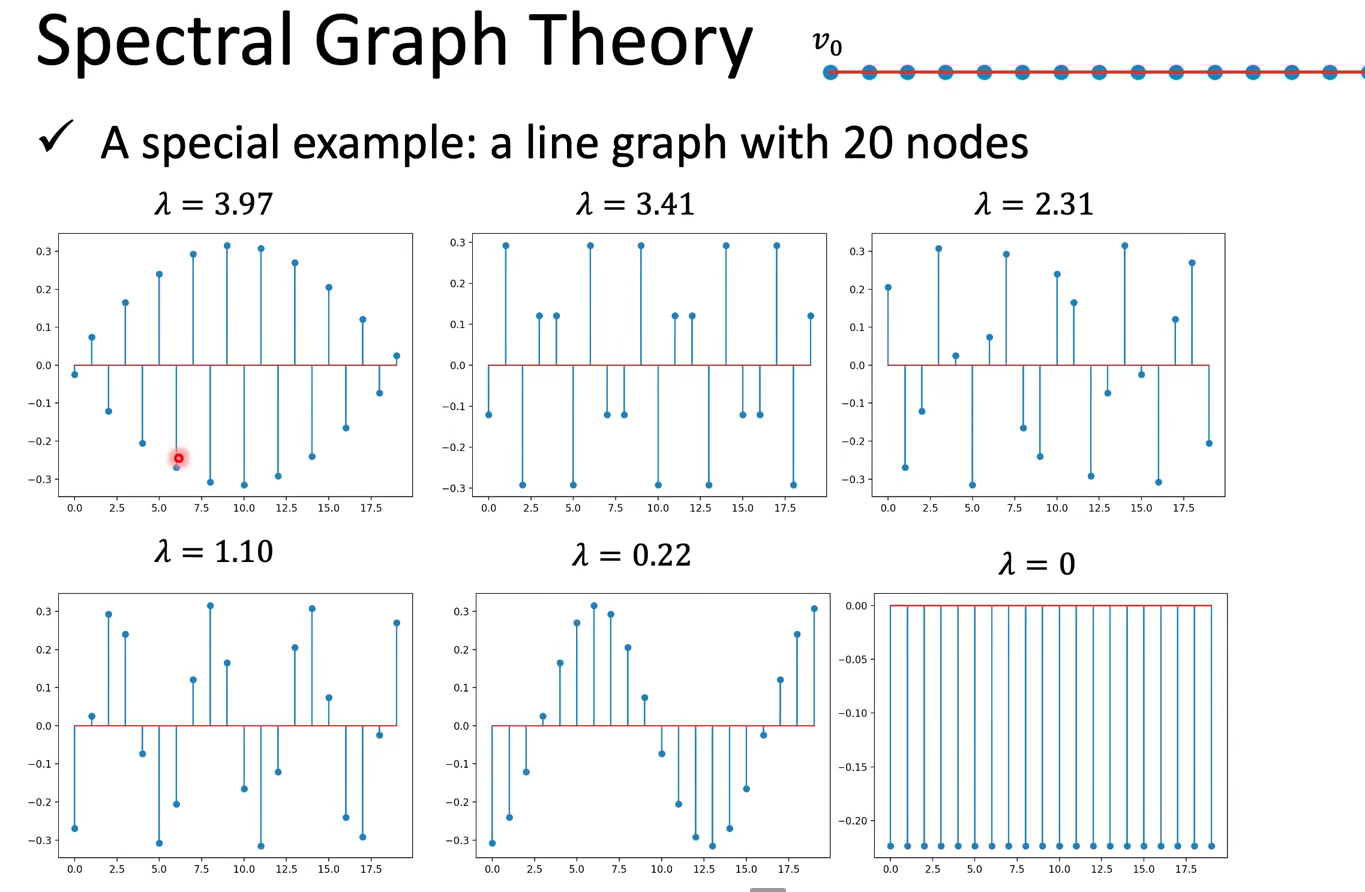
重要概念:频率越大,相邻两点间信号变化量越大。
理论👇:$f^TLf$代表了这个graph相邻结点的信号能量差,也就是signal有多smooth,以量化graph signal的频率大小,

也就是说,特征值$\lambda$可以代表特征向量变化频率的大小
那么怎么定义fourier transform,也就是怎么把一个图上的信号转到频域去呢,如下:
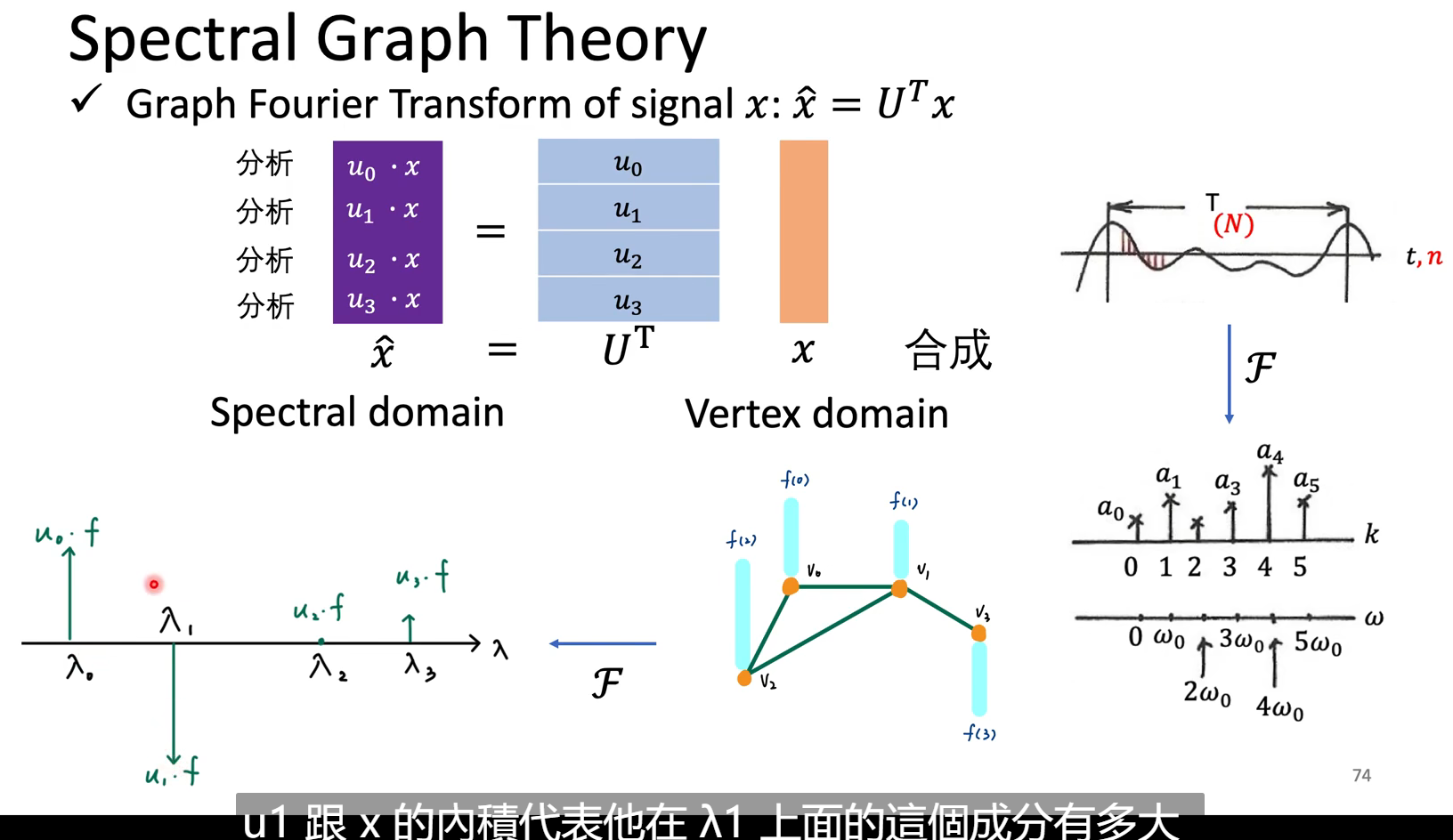
逆过程参考时域的积分:Amazing!
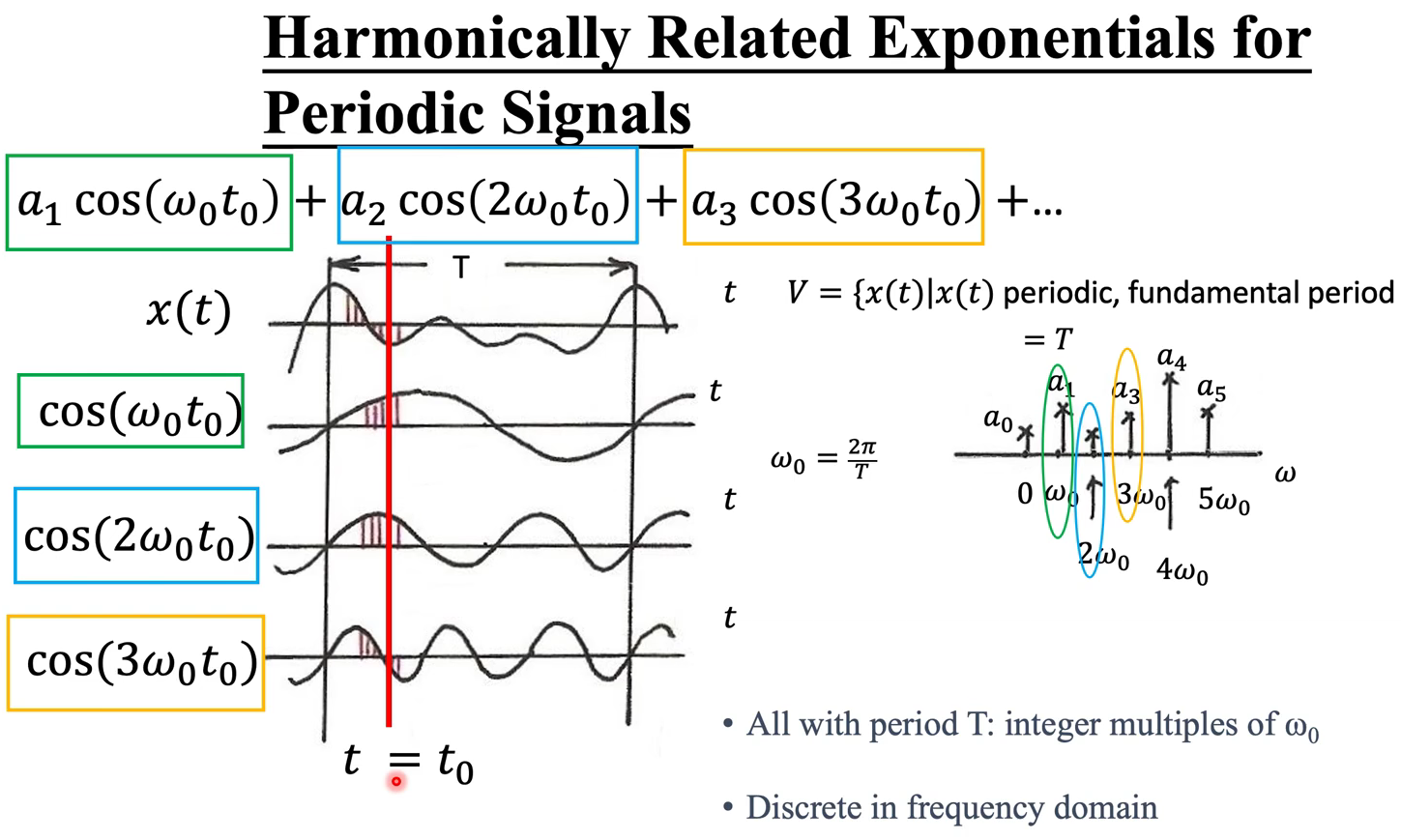
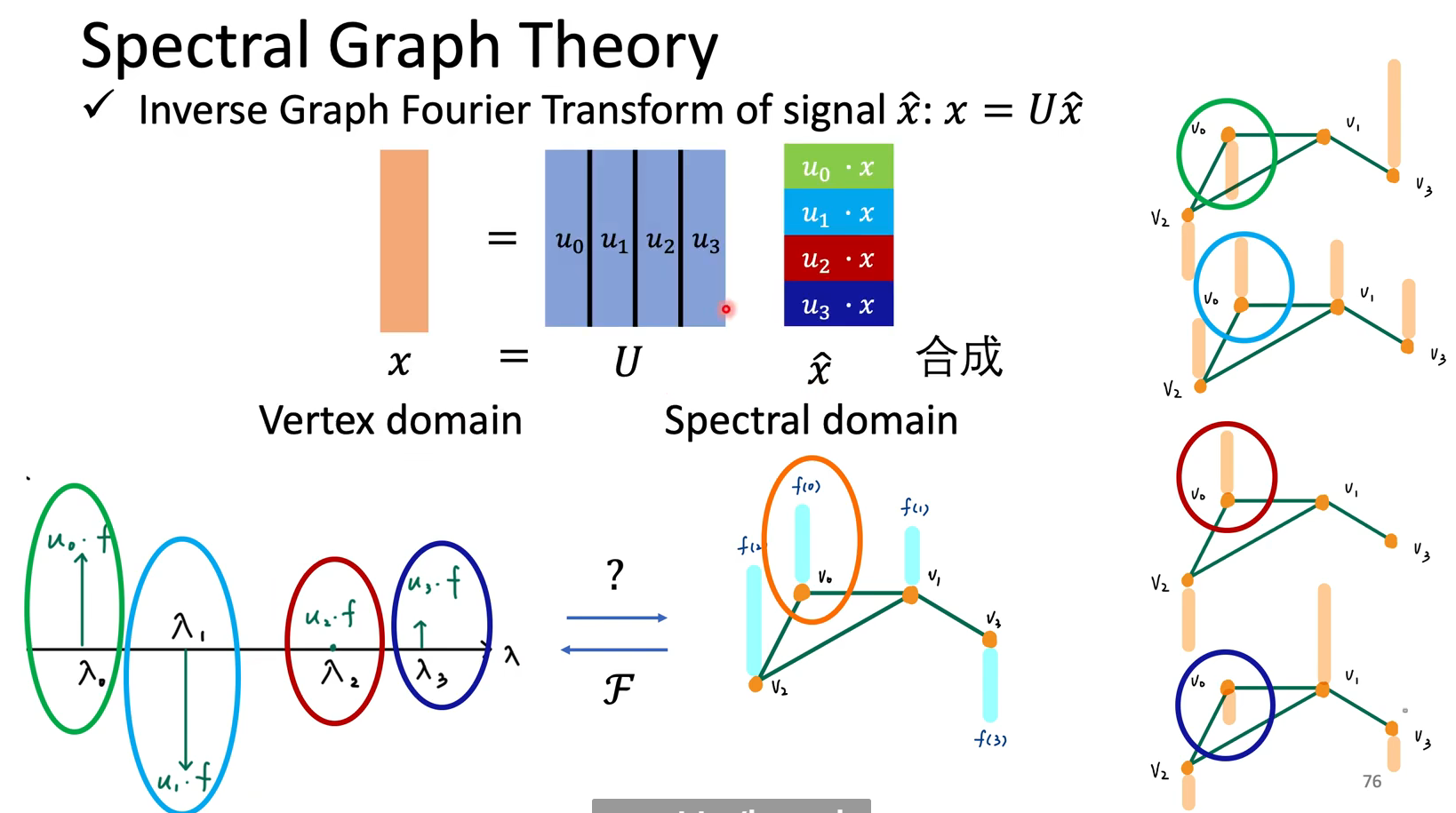
而频域的filter其实就是对角矩阵,与之前转到频域的结果$\hat{x}$相乘(multiplication),最终的得到的新结果$\hat{y}$
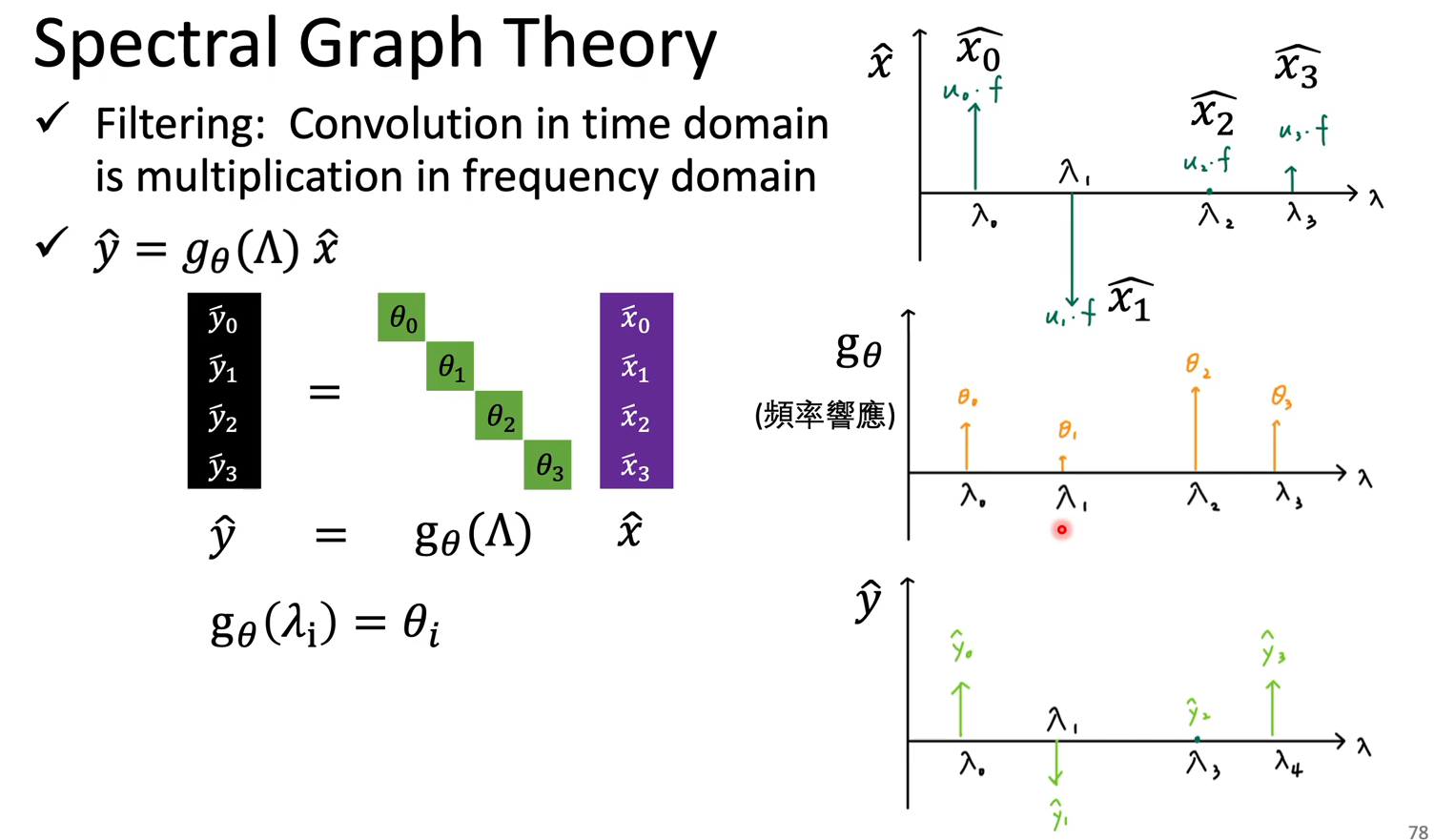
可见,我们最终要学的就是这个$g_\theta()$,也就是对拉普拉斯矩阵的函数,其中只关心对角(设了A和D对称),参数量为$N$
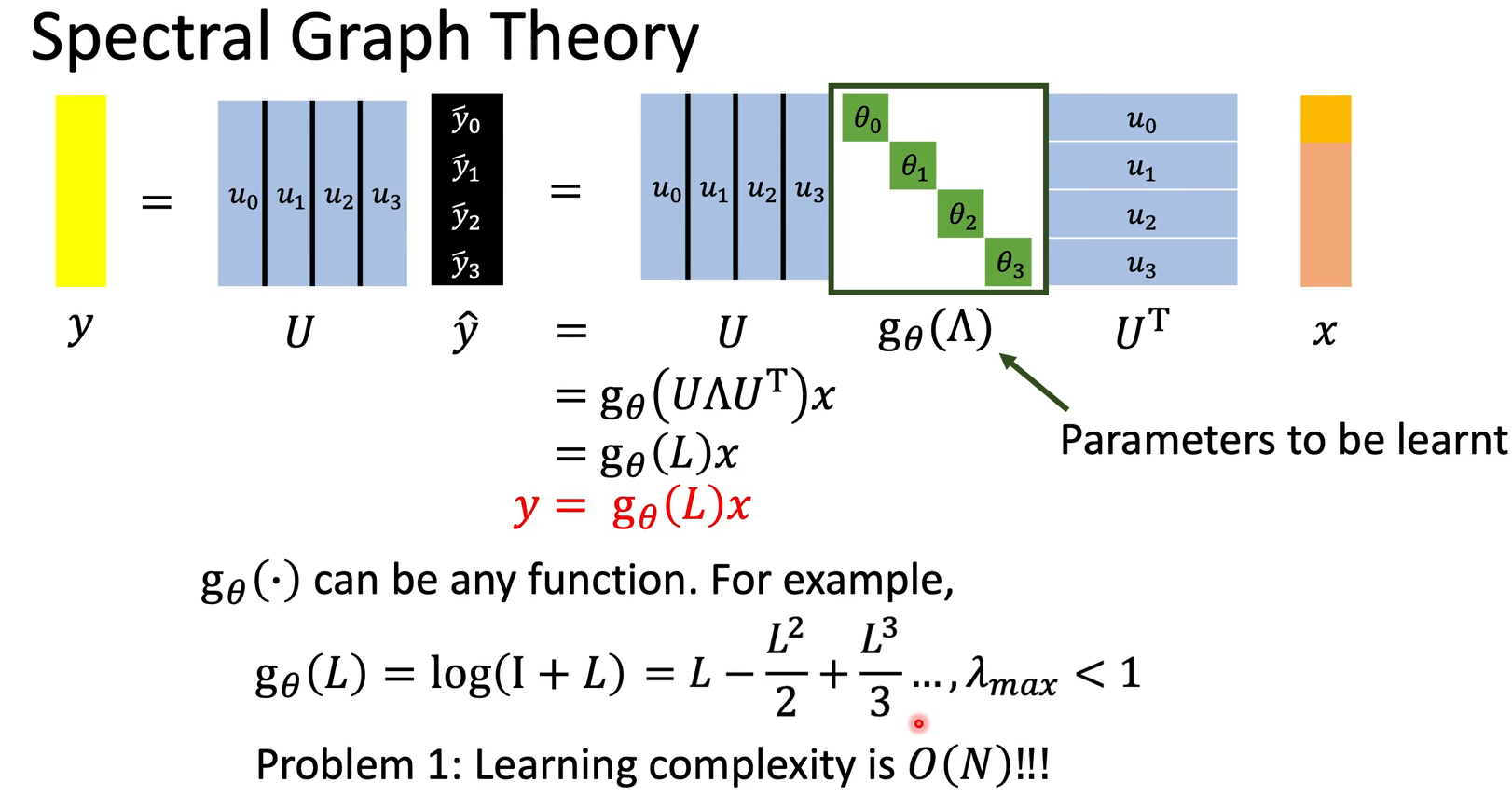
第一个问题,这个函数的shape与输入有关。
第二个问题,他不是localize的。
根据数学上给出的定理,$L^N$每一项都不为零,此时的感受野是全局,但我们希望像CNN的卷积核一样看到局部的信息。
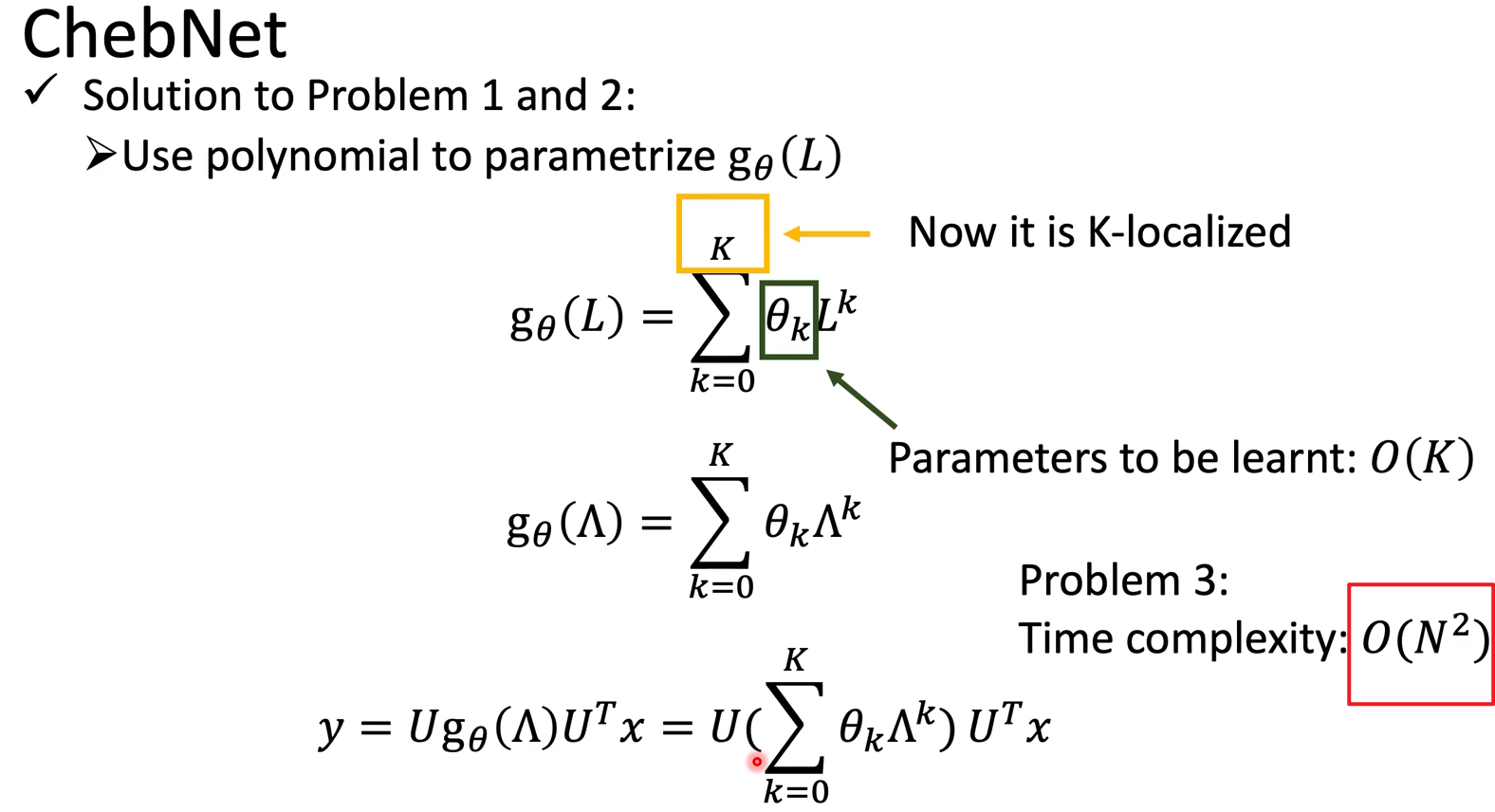
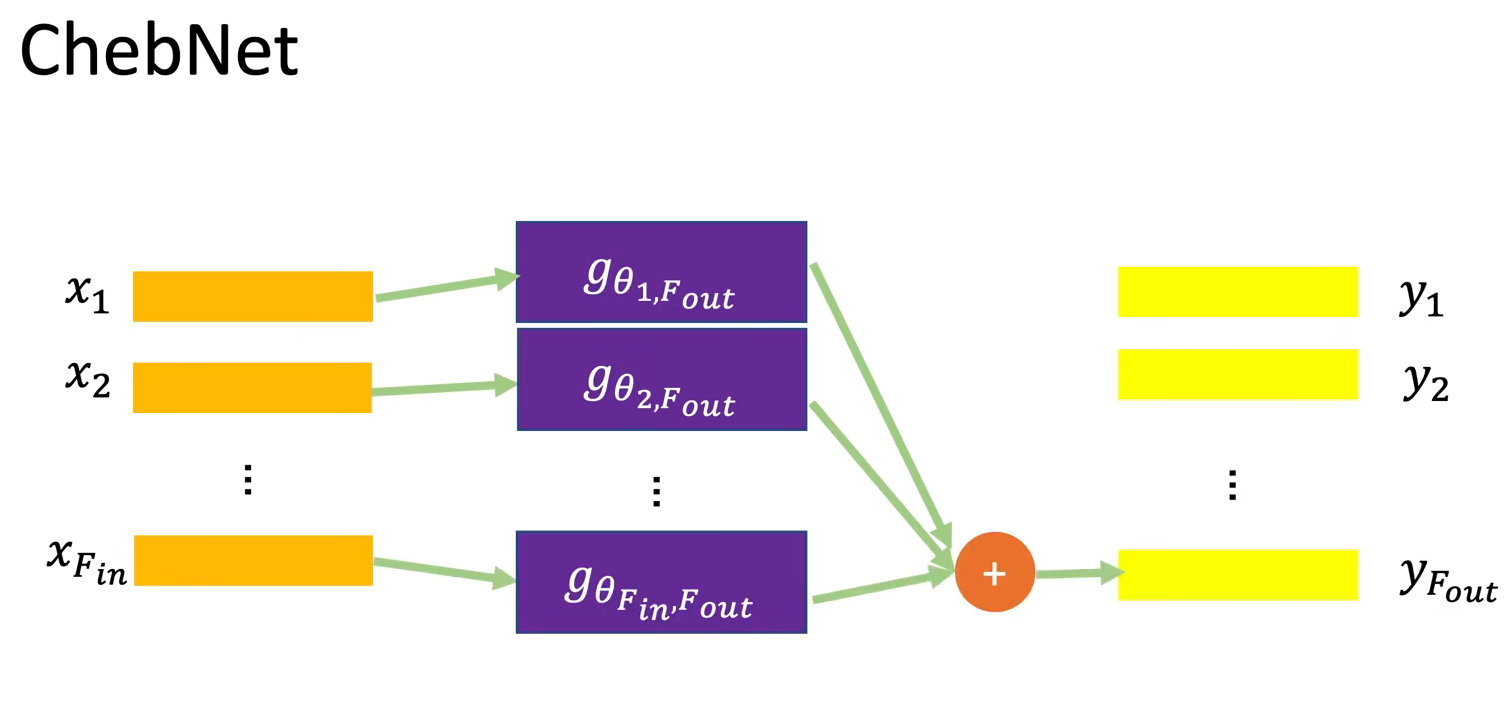
ChebNet
很快,解决了上述的两个问题。其实就是限制了多项式的级数到K。然而这带来了计算成本高昂的问题。
ChebNet引入了数学上的技巧解决计算成本,把$\lambda$化为新的多项式表示,综合除法👇,此时会很好算。


最终计算方式是递回的。。:
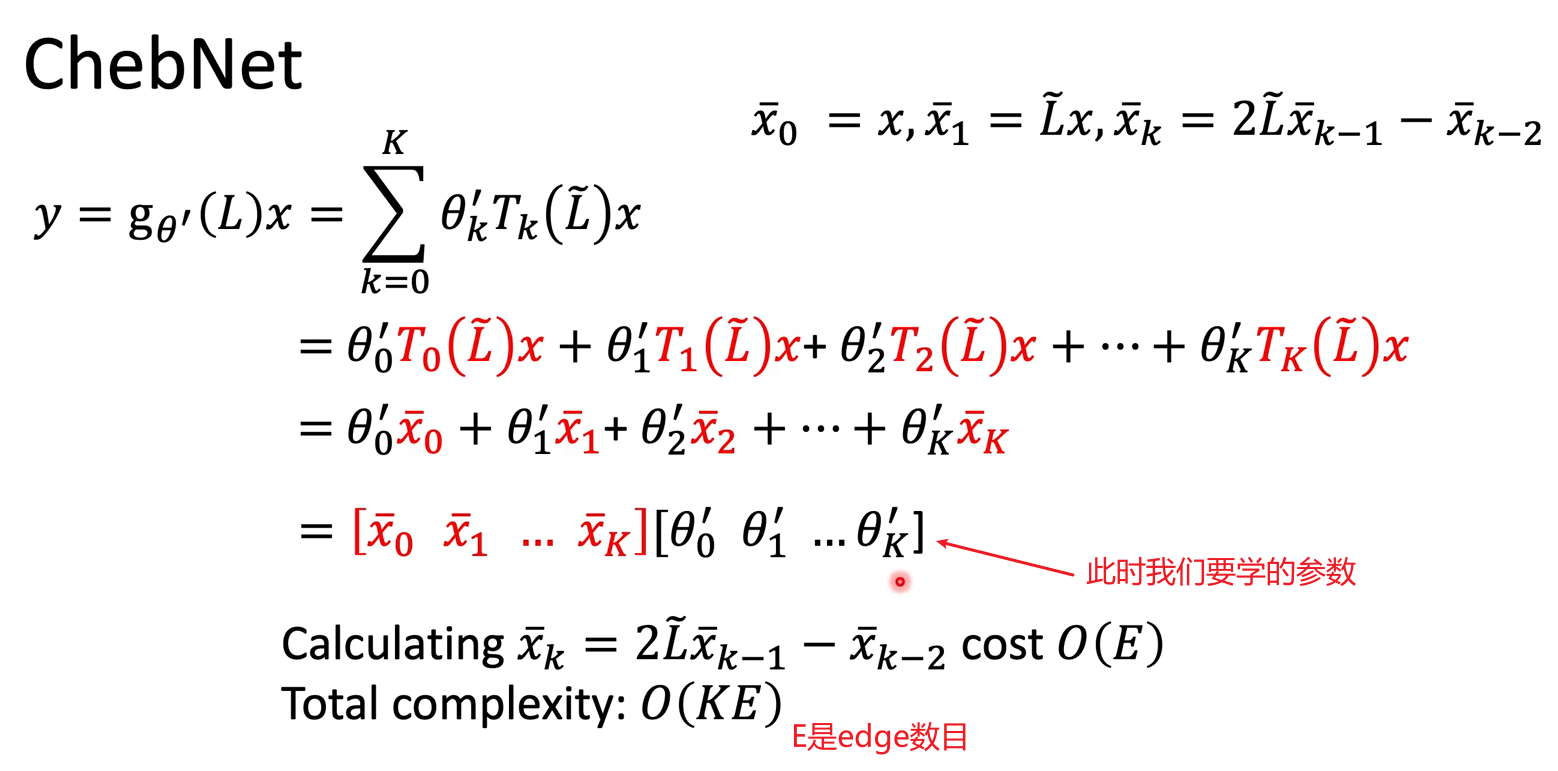
GCN
简单直观,有一些数学基础。
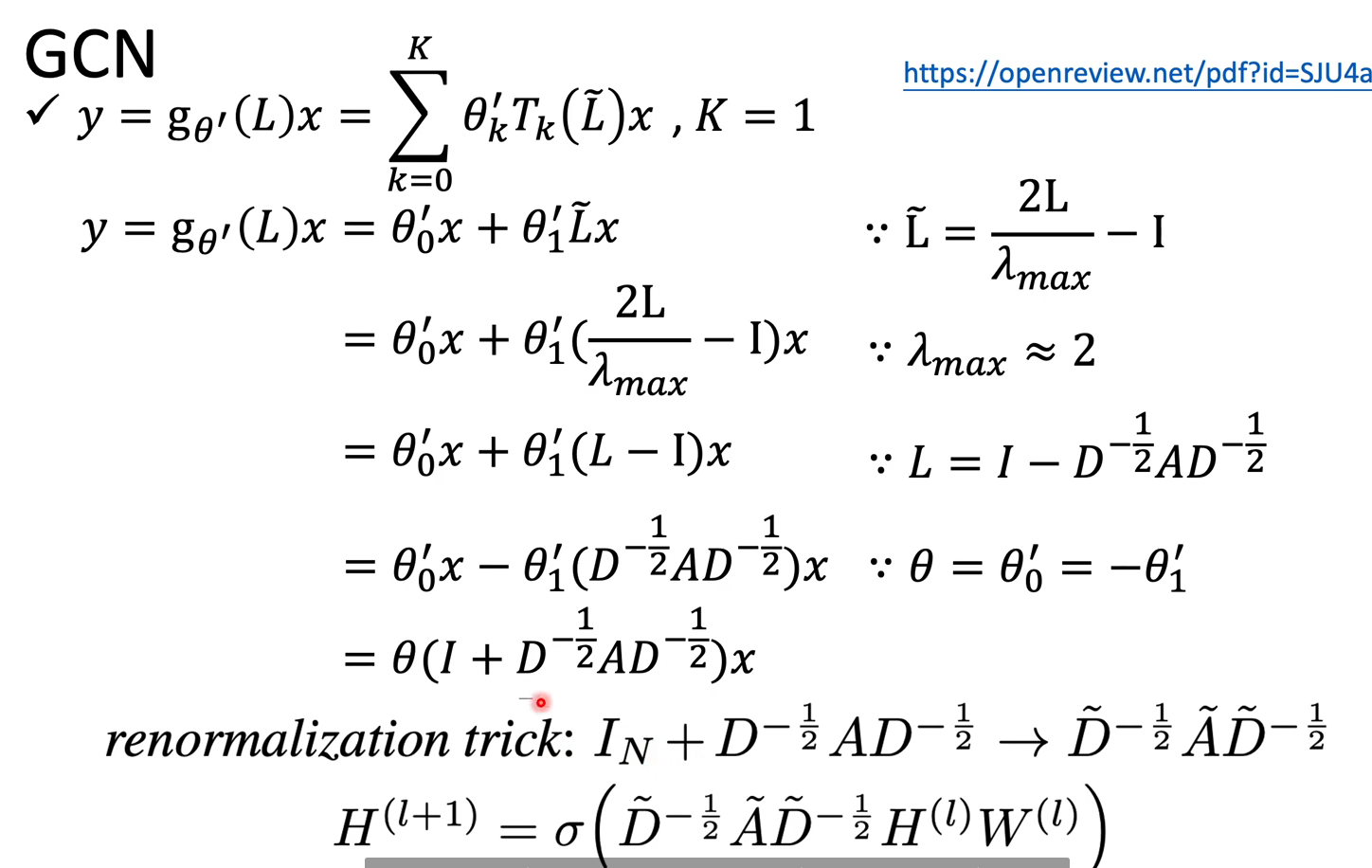
最终更新的式子就变成,把所有的neighbor经过transform相加取平均,加上bias
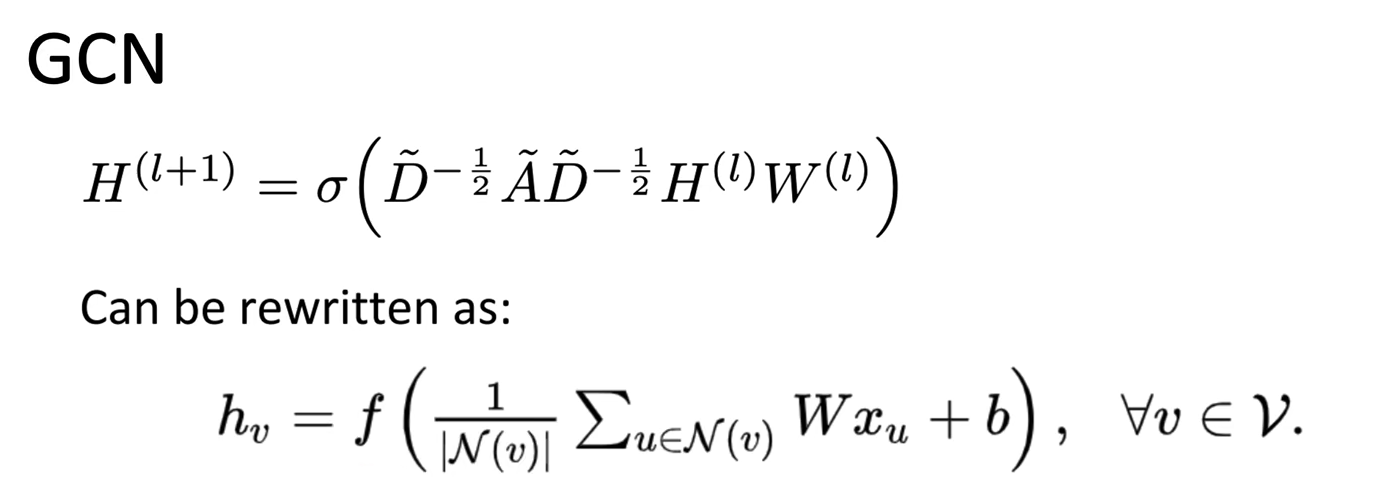
接下来就是一些图领域的东西了。

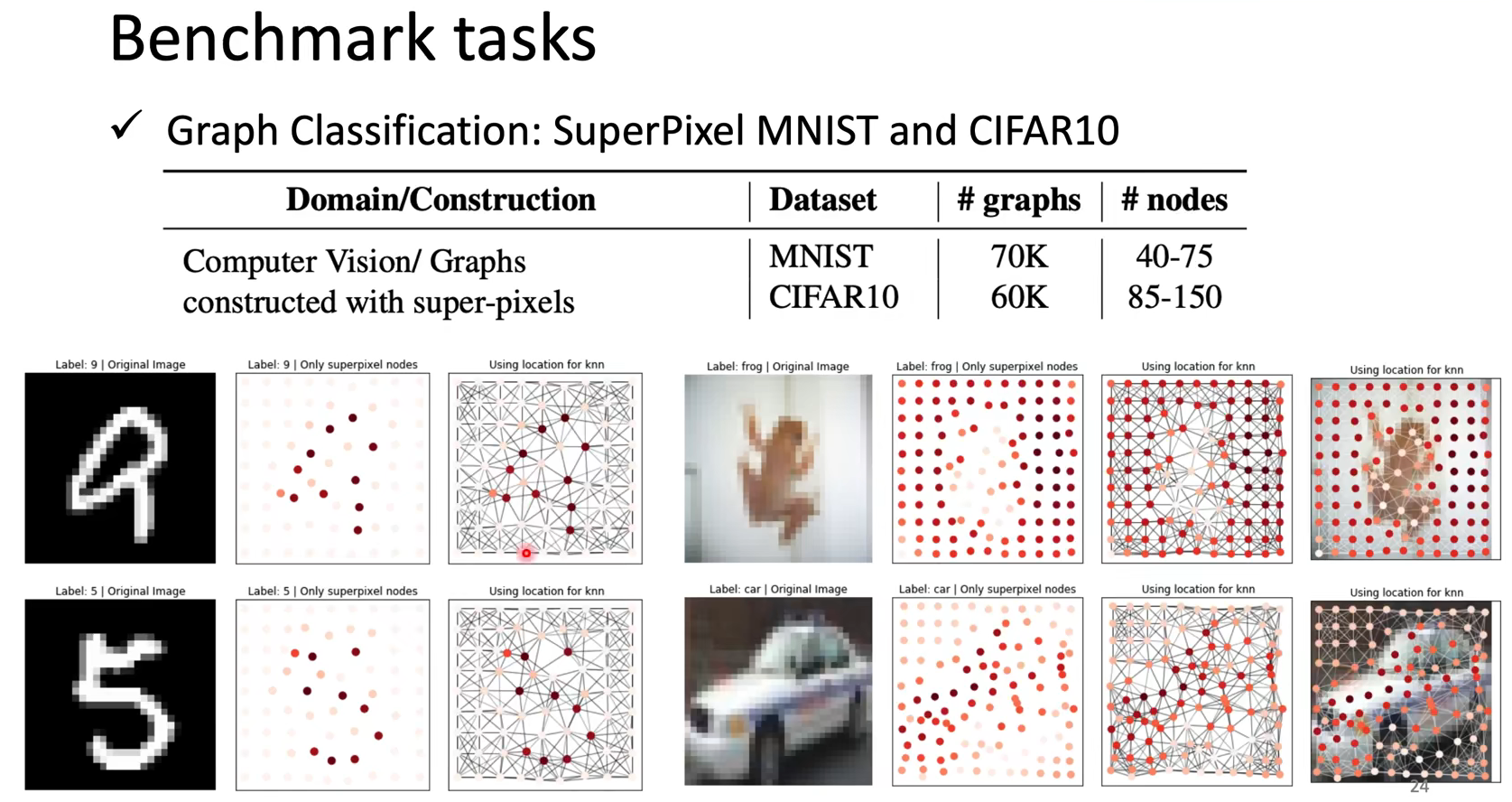
但是结果看上去GCN很惨:
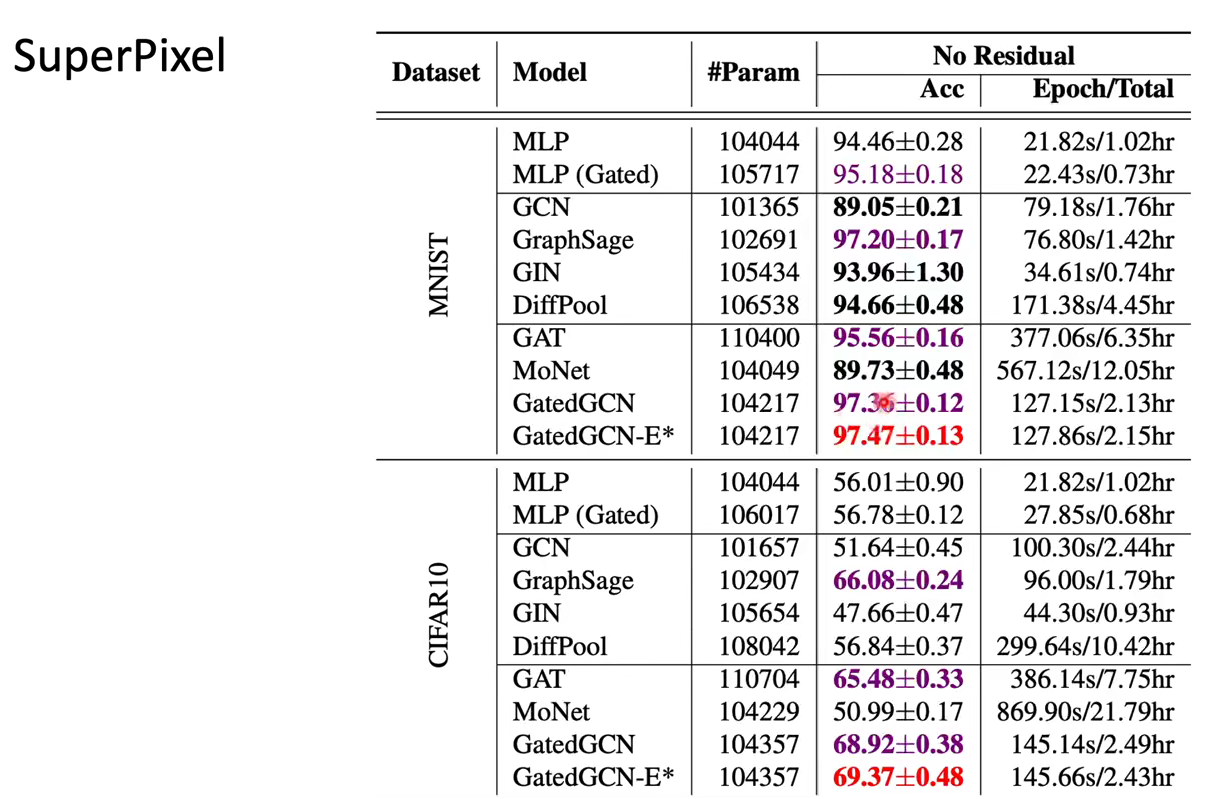
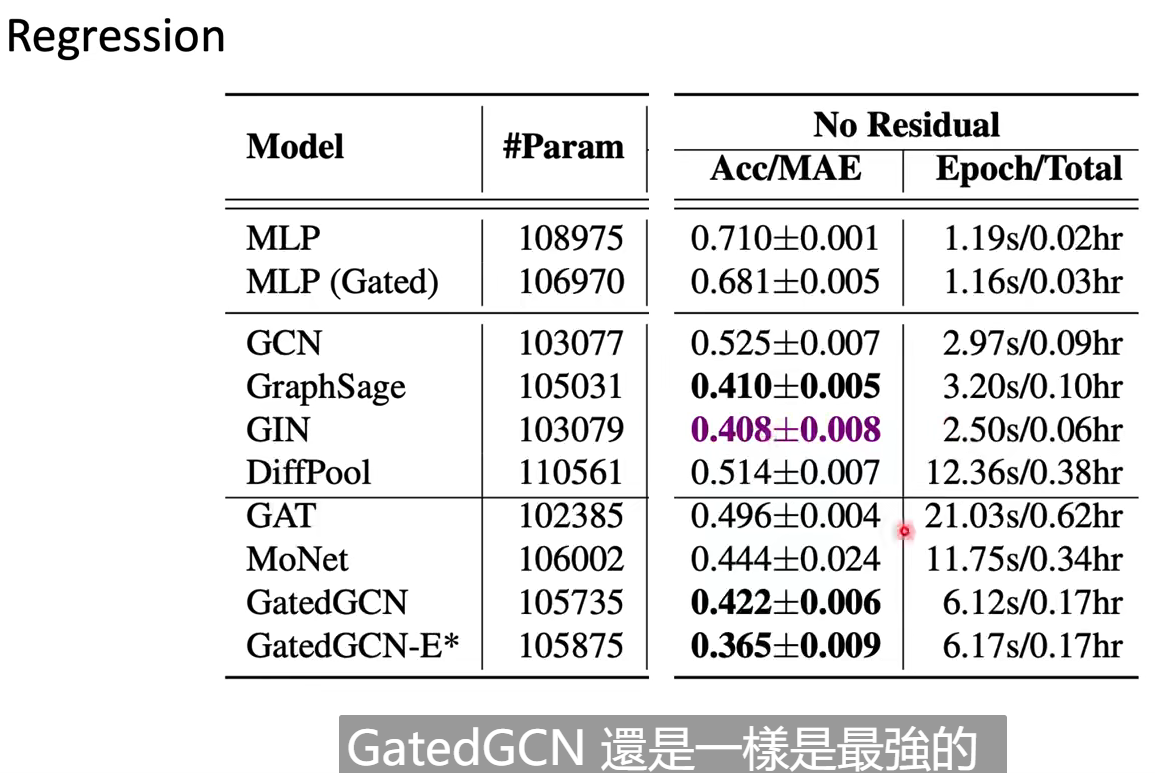
做了weighted-sum的model一般结果好很多。
有人用理论证明说GCN在层数很多时,同一个子图内的edge会收敛到同一处。【只要Dropout就能解决这个问题】,但事实上,还是比浅一点的model要来的烂,有点离谱。至今还有待解决。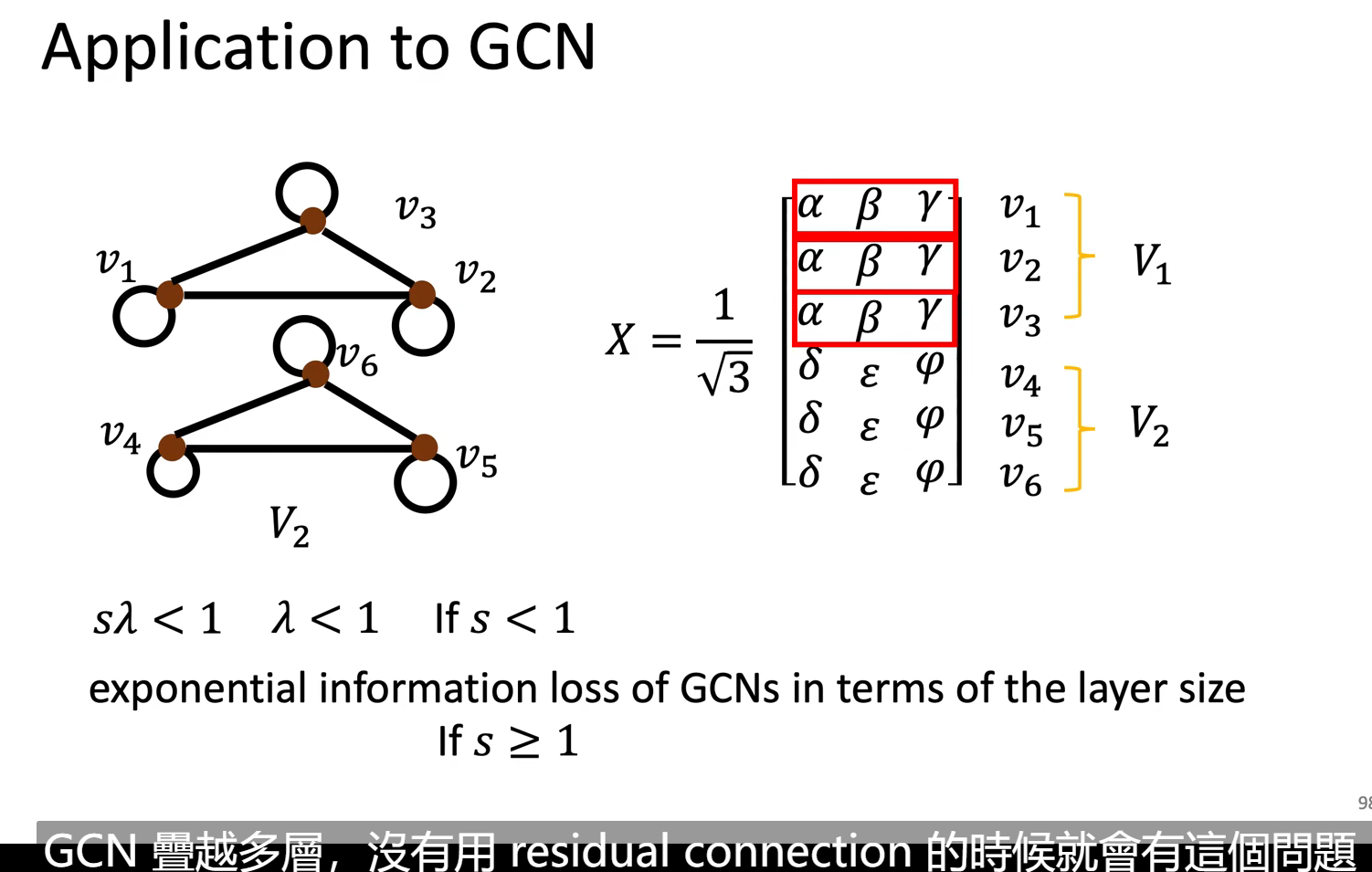
最后,GNN还可以用于generation,而且在NLP上有很多应用(比如知识图谱什么的)。

Generation
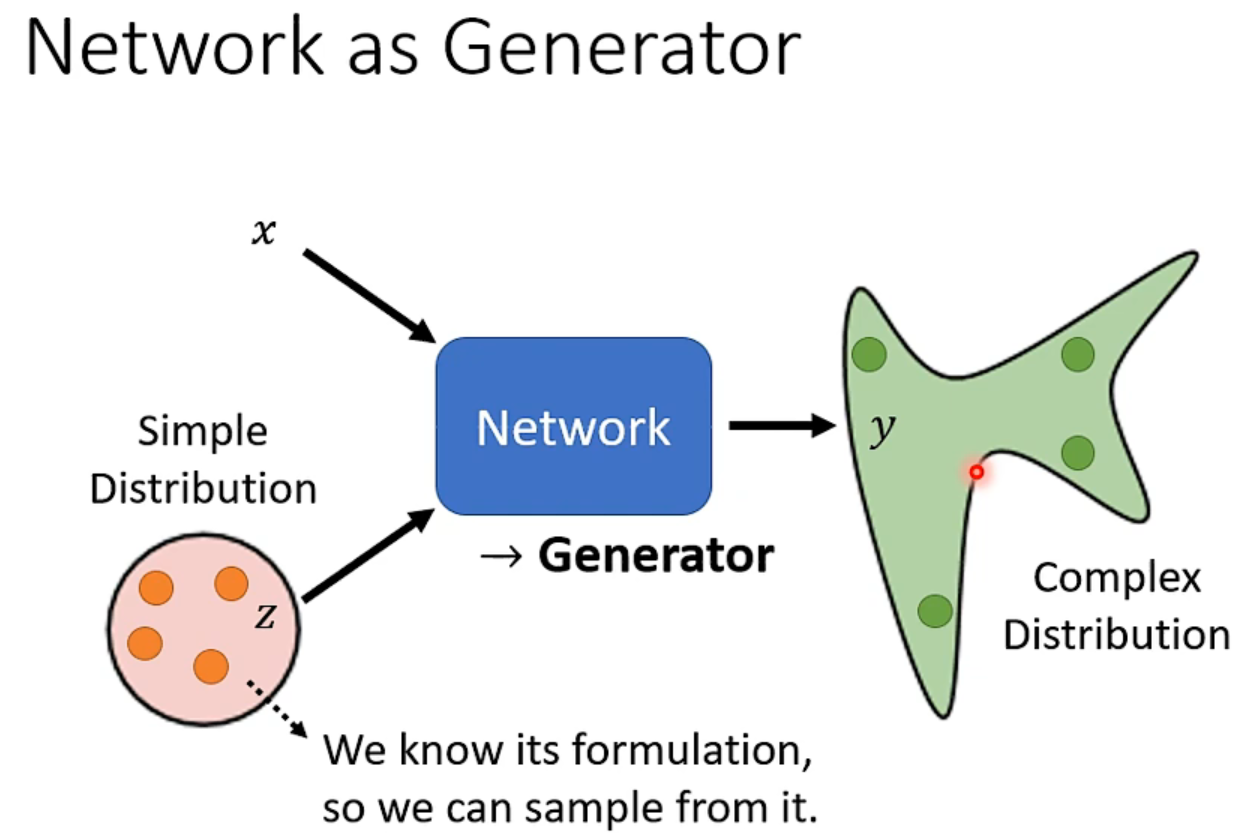
why generator?
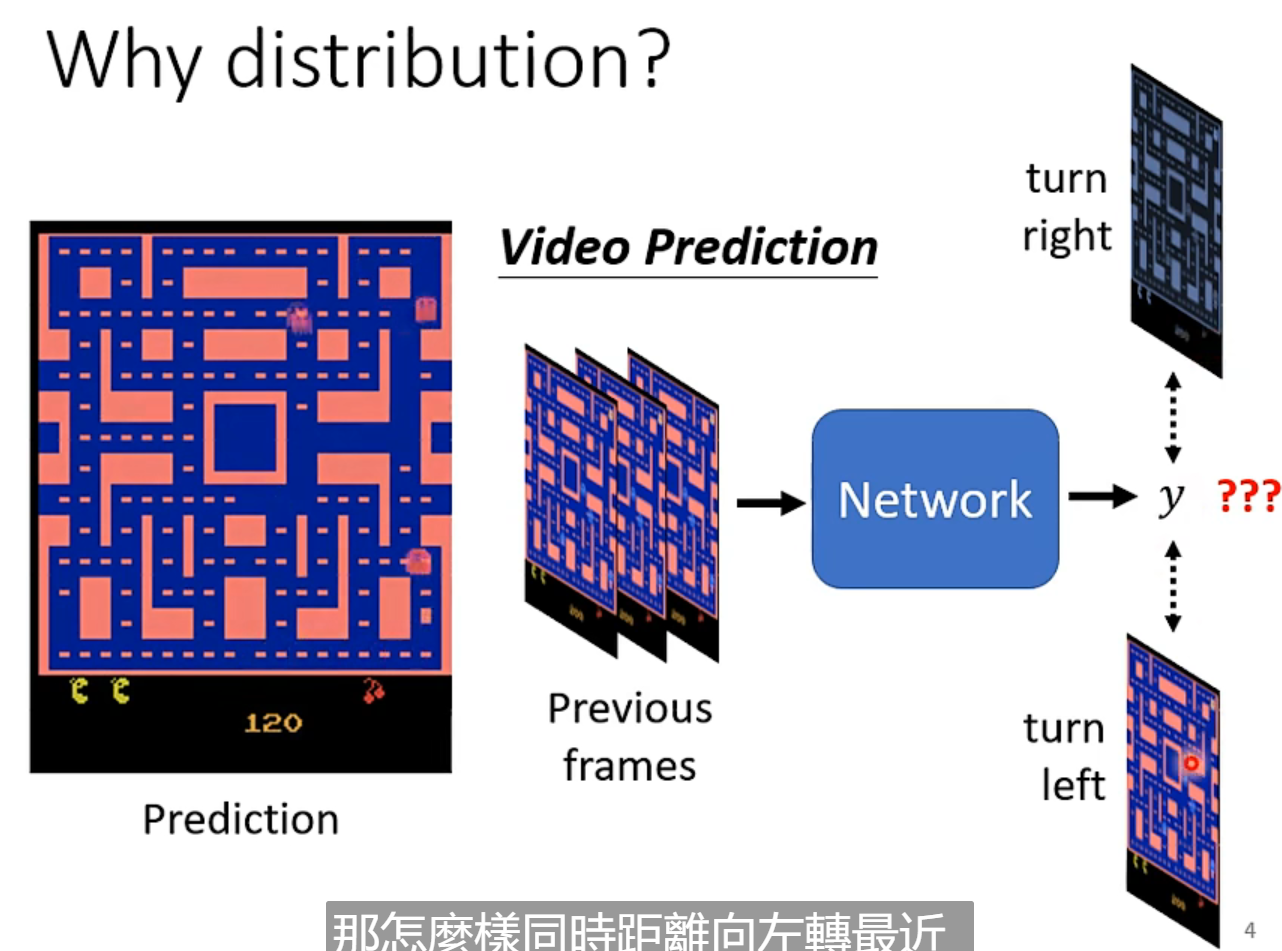
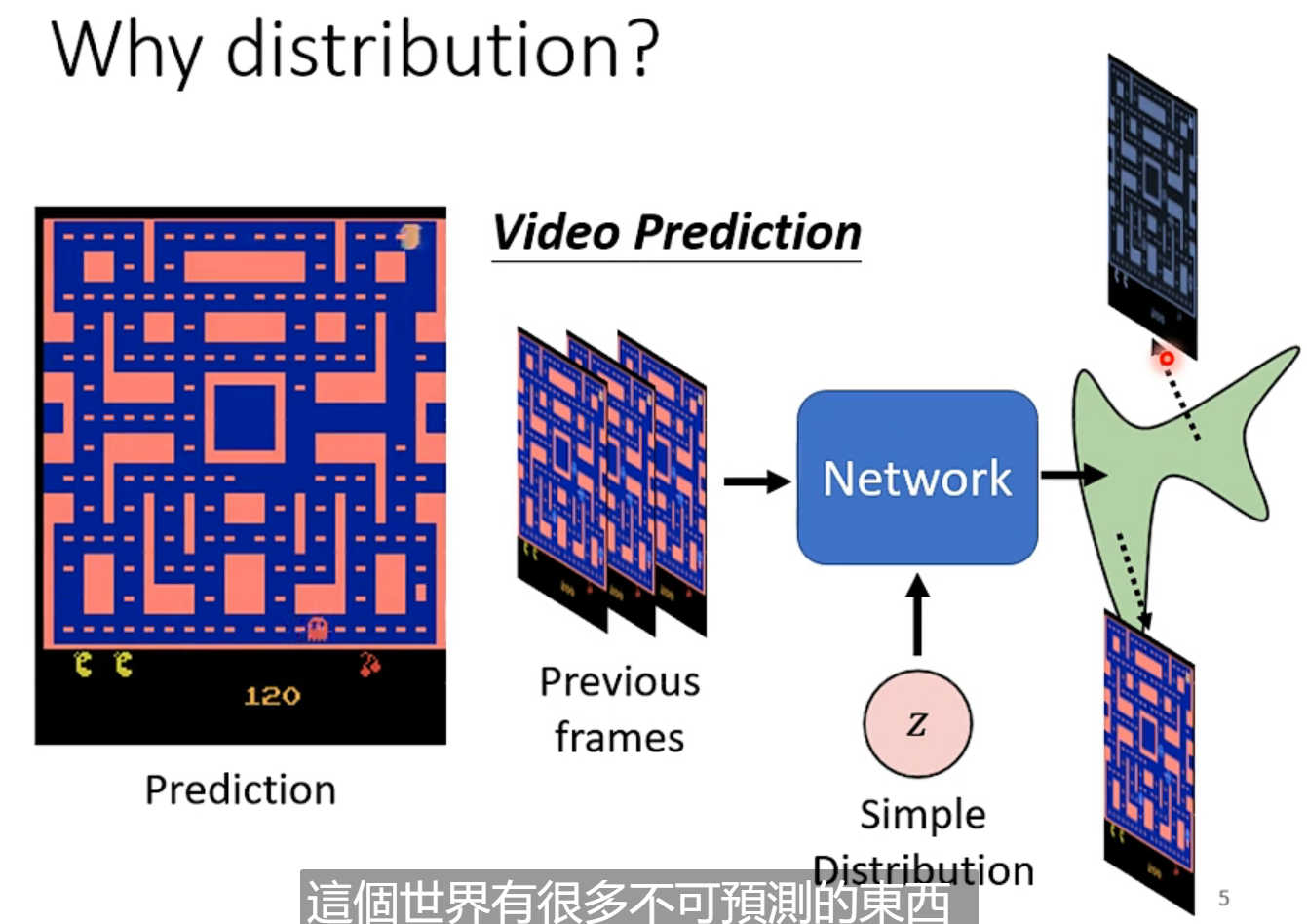
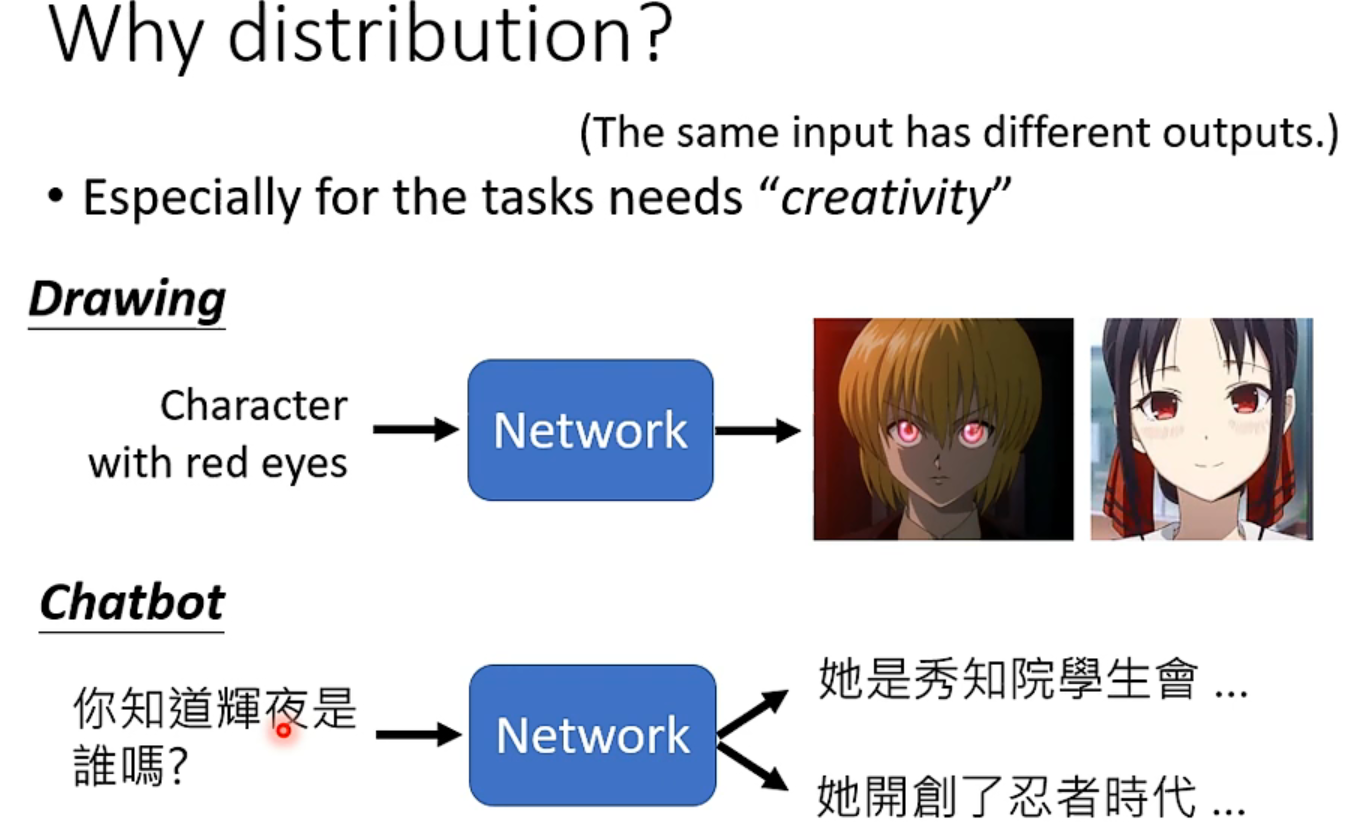
当我们的任务需要一点“创造性”,同一个输入,可能有很多不同的输出,而都是对的。(我笑死,老师太好玩了)
GAN
GAN实在太多啦!

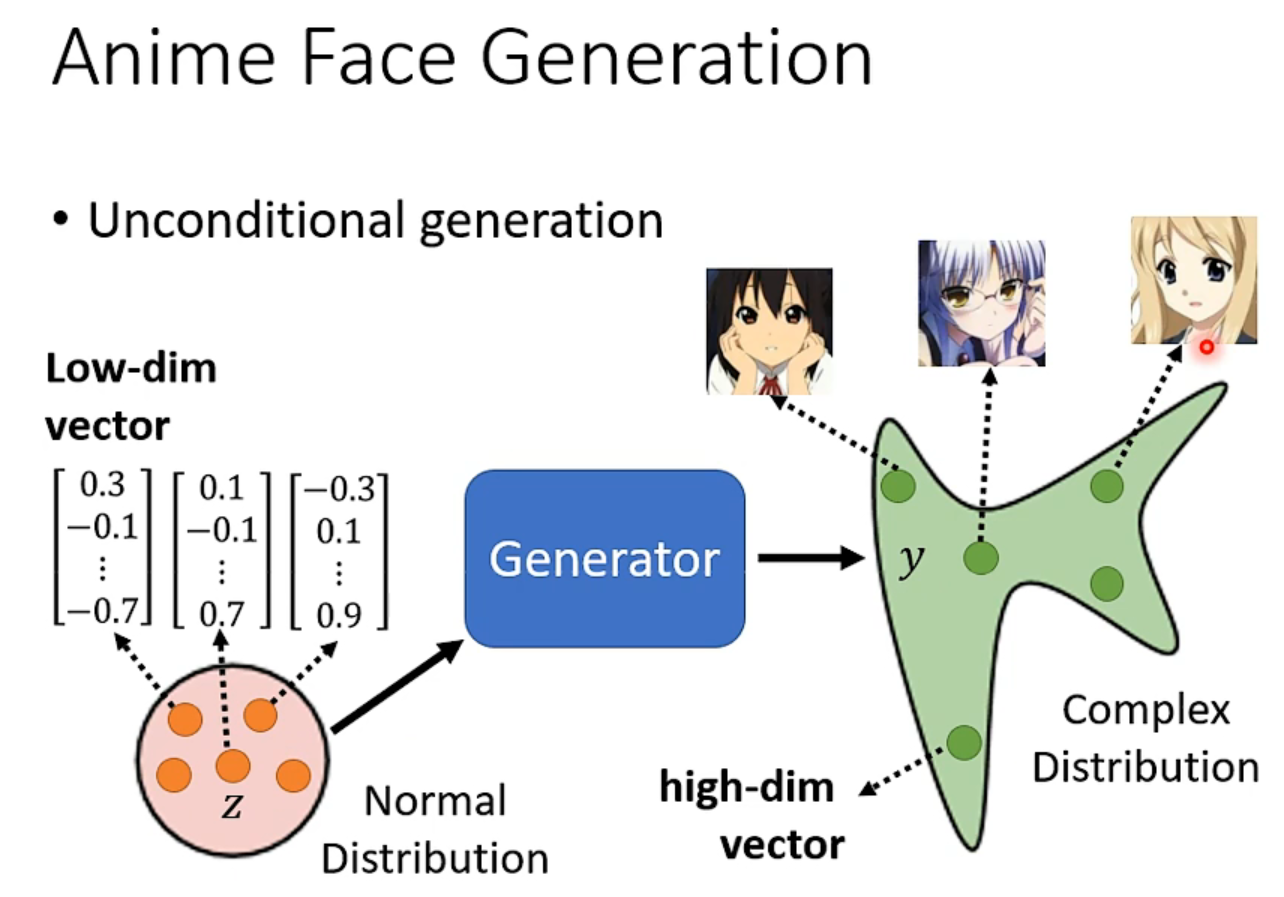
希望效果:从normal-distribution中sample不同的低维向量,都能由generator生成动画人脸(图片其实就是高维向量)
simple distribution的选择没有那么重要,generator负责把简单的distribution对应到复杂度distribution
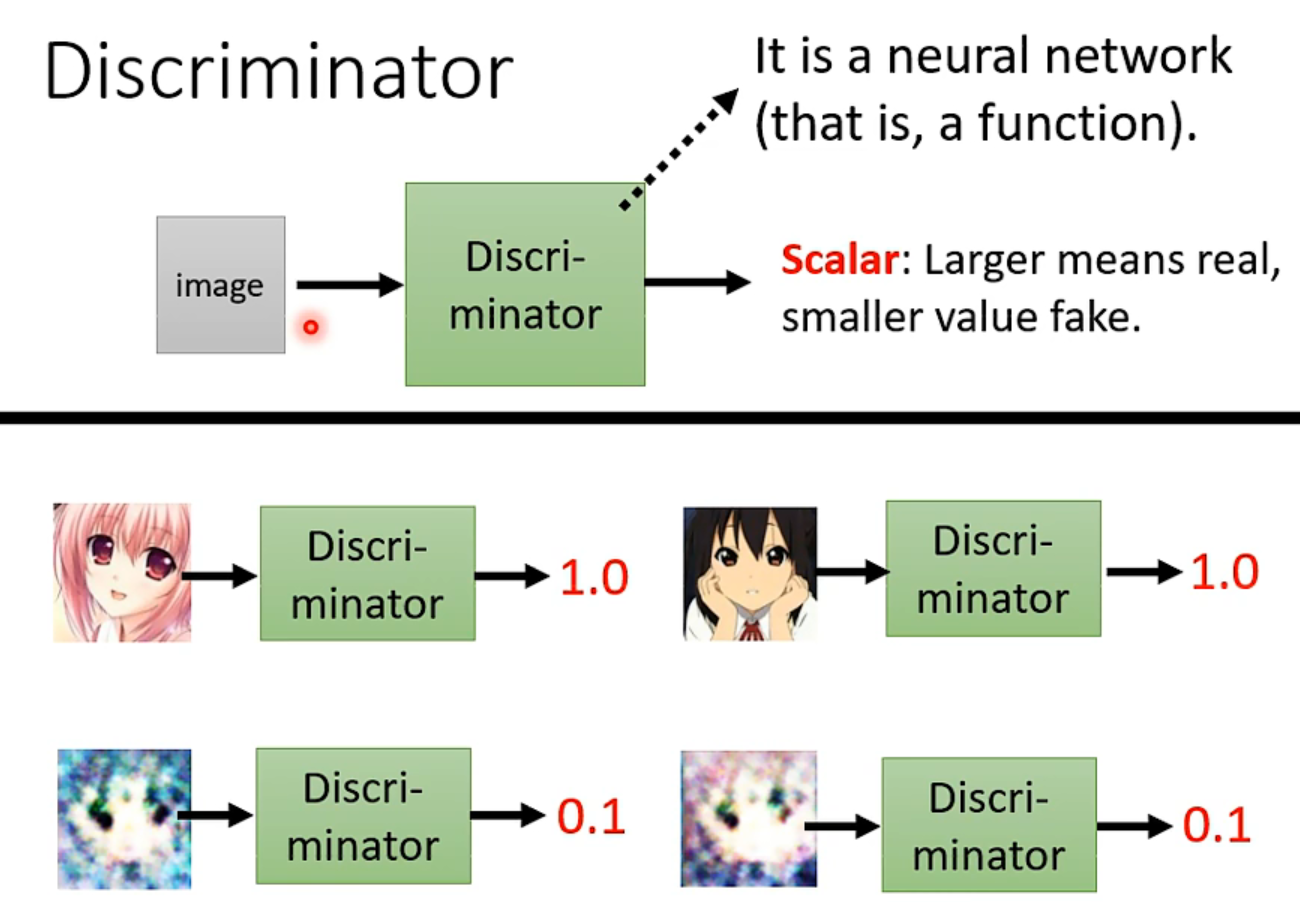
generator和discriminator都是神经网络,只要能达到你想要的作用,用什么架构完全由你决定(我好像明白为啥那么多version了)
Basic idea
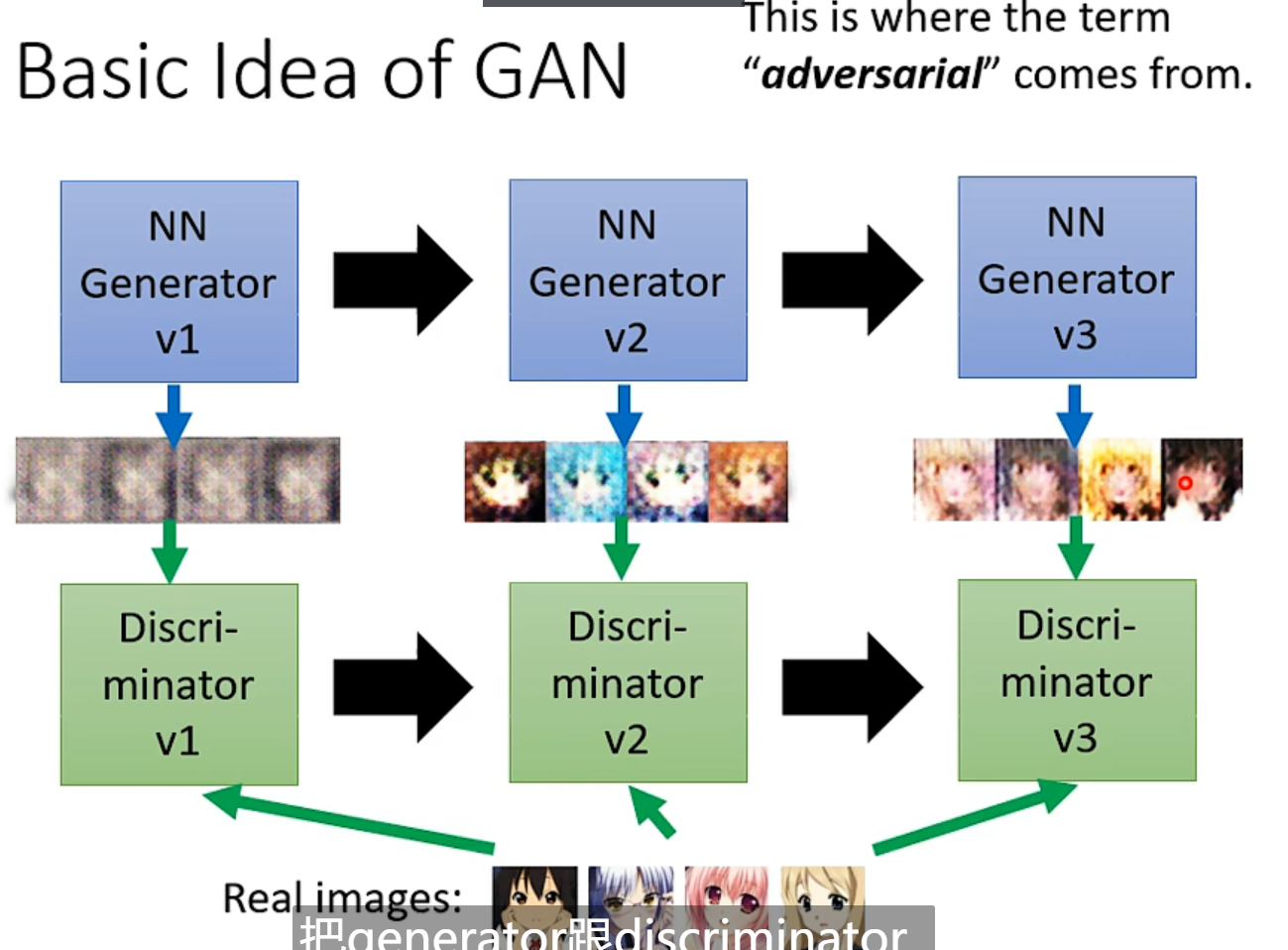
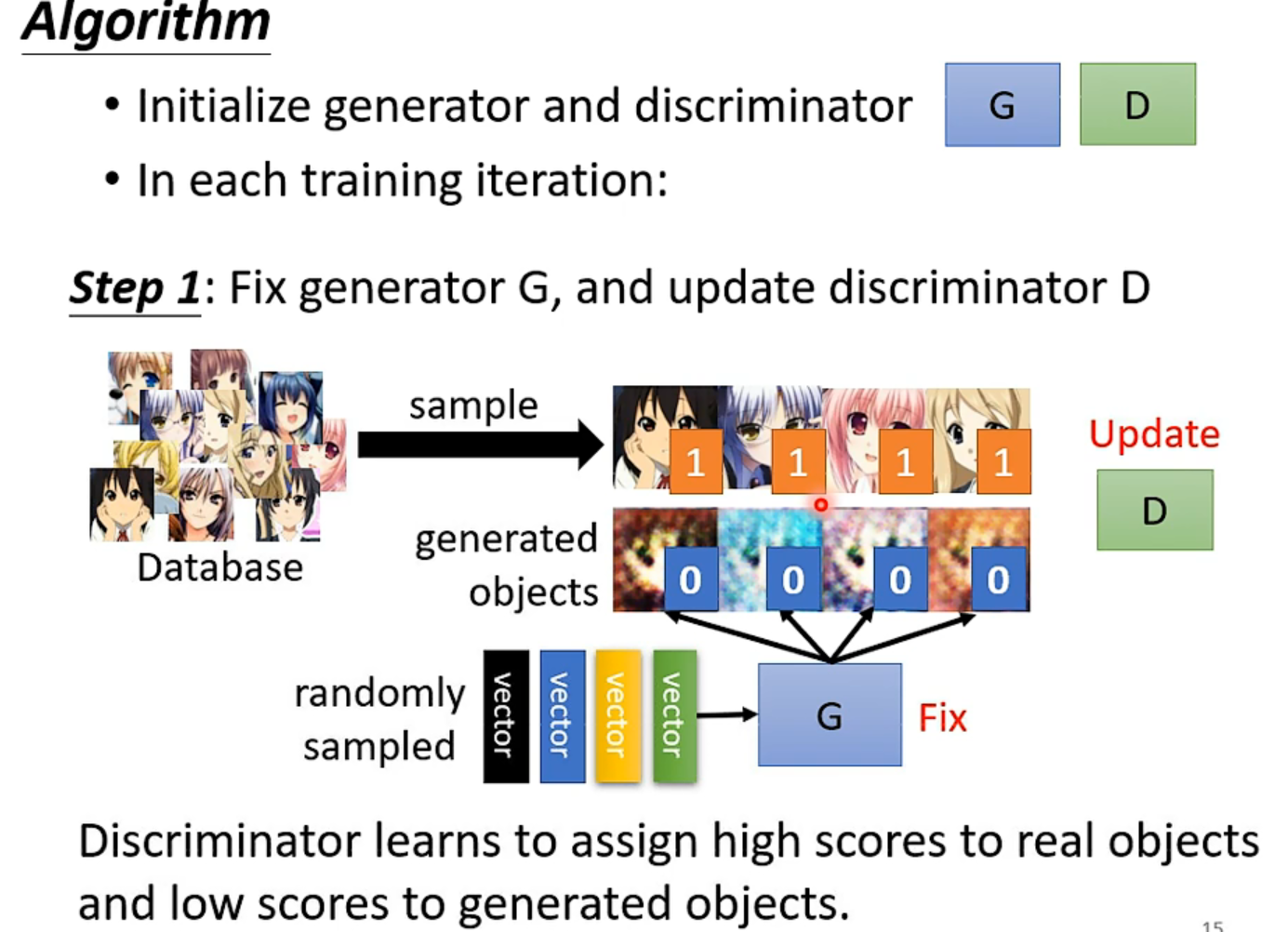
轮流固定,训练另一方。
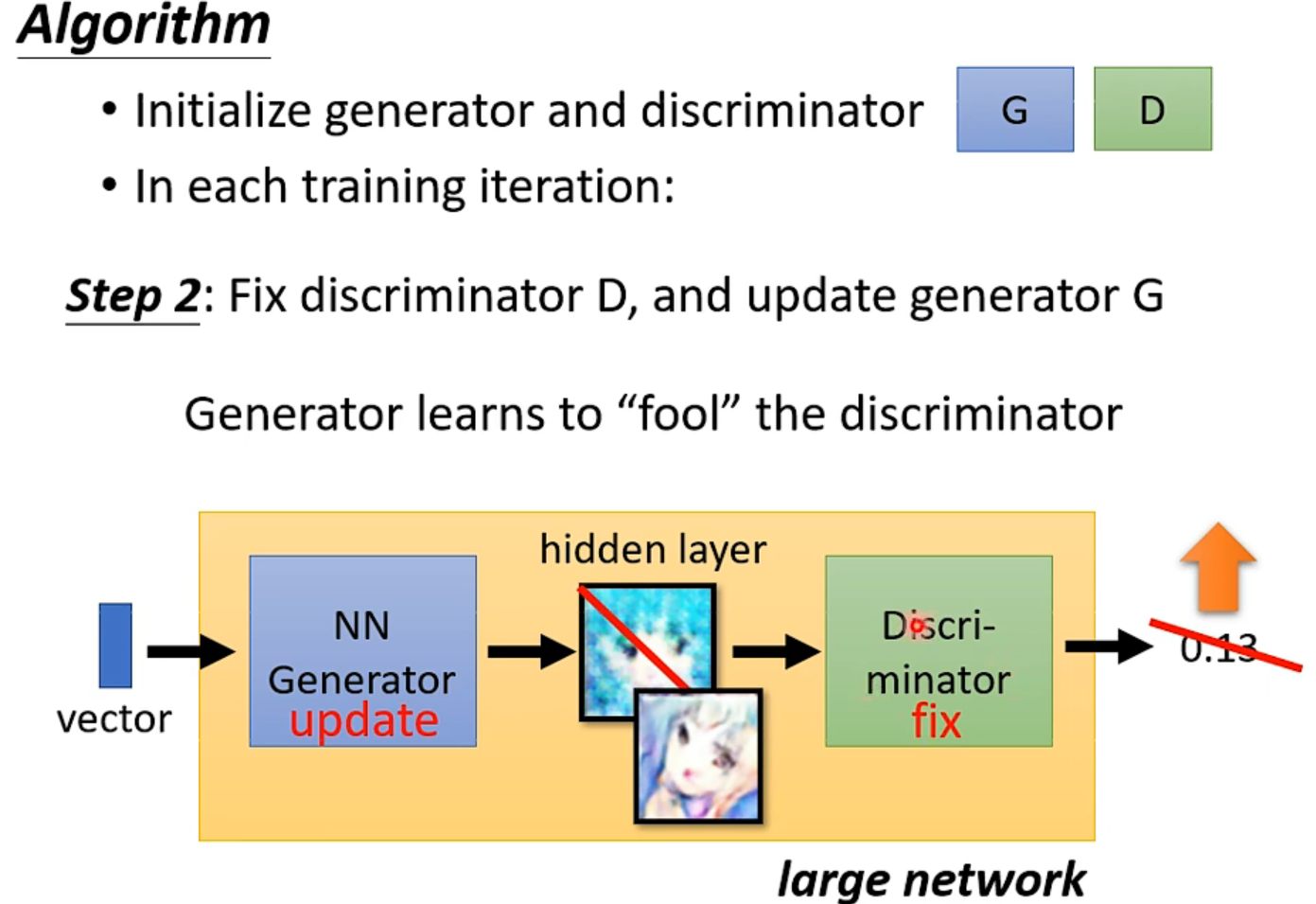
可以看成是一个大network,所谓的内插👇(吸收特征然后组合?!)


Theory
目标是学到$P_data$的分布,要用到概率论咯。
GAN牛逼的地方在于,解决了不知道怎么计算复杂的Diversion这个问题,只要你能从$P_G$ and $P_{data}$中采样,不需要知道这两个分布的formulation,就能算出divergence的逼近。
如右图,最终理论推导出这个$maxV(D,G)$竟然和divergence有关,【注意不是V这个值本身,而是穷举能得到的最大值!】本来作者选这个目标函数只是为了和分类问题挂钩hh
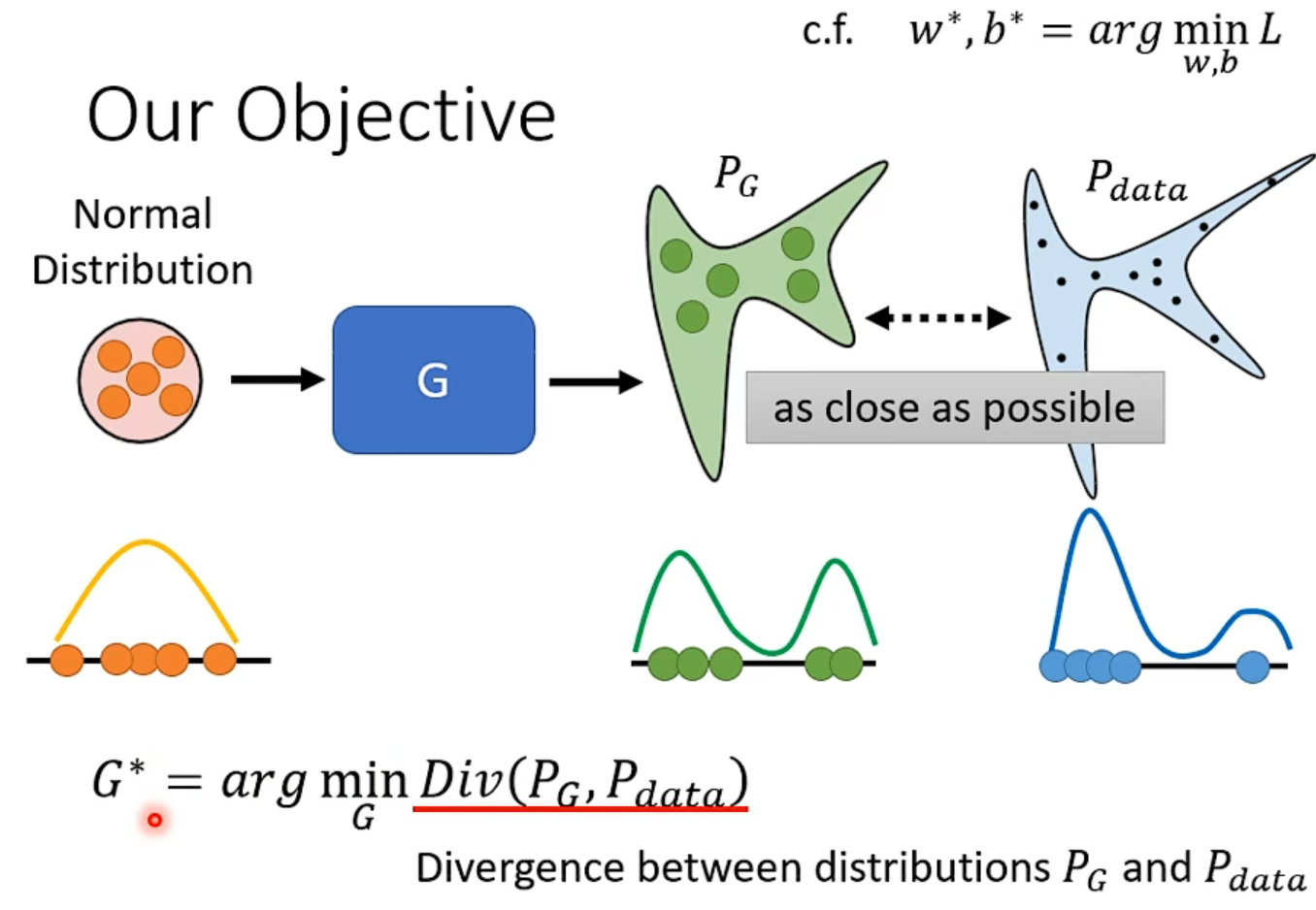

最终变成了一个极小极大值的优化问题:


这篇文章给出了不同divergence的object function,也告诉大家即使很正确的minimize divergence,结果也没有很好。
GAN以不好train闻名哈哈
Tips
GAN有很多很多训练的小技巧。
由于JS divergence的特性,只要没有相交,算出的是定值$log_2$,那在训练中就不能区别好坏。

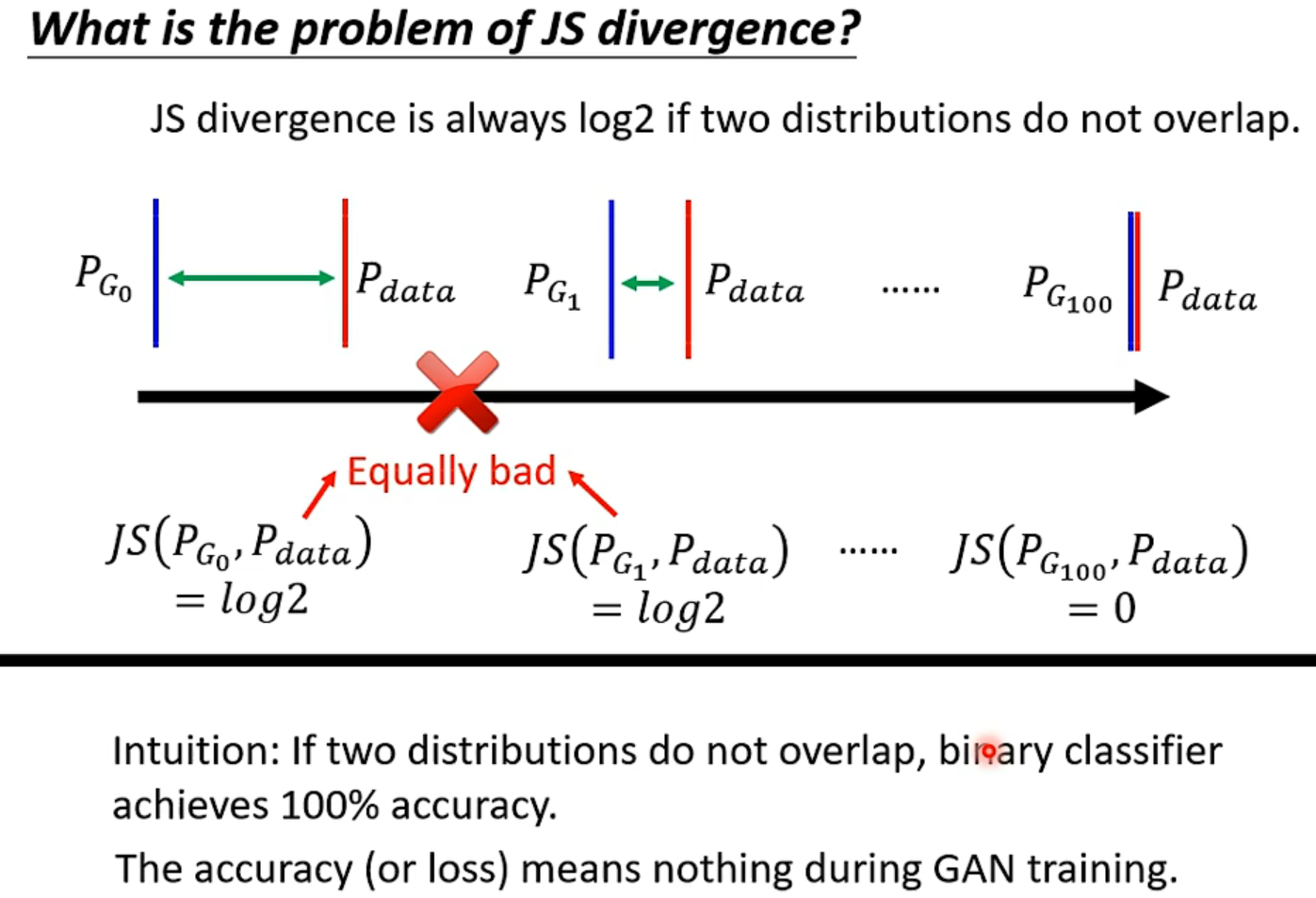
所以训练中accuracy不能提供资讯,以前训练GAN只能画出来人眼看,Wasserstein distance也能衡量分布的差异,但是贼难算,因为当样本很多时,有很多种moving的方式。但是这样确实能拟合分布,能真正优化。
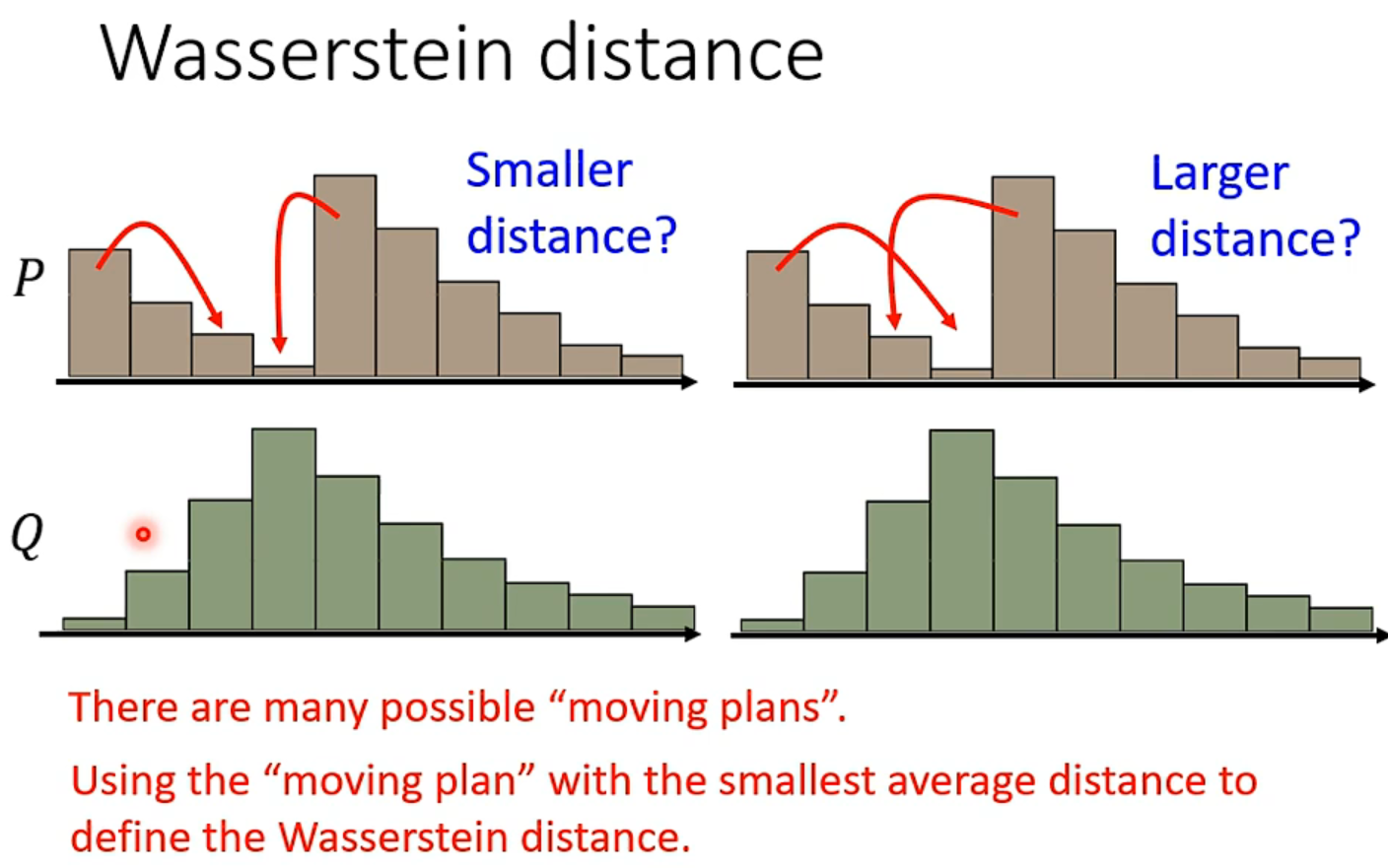
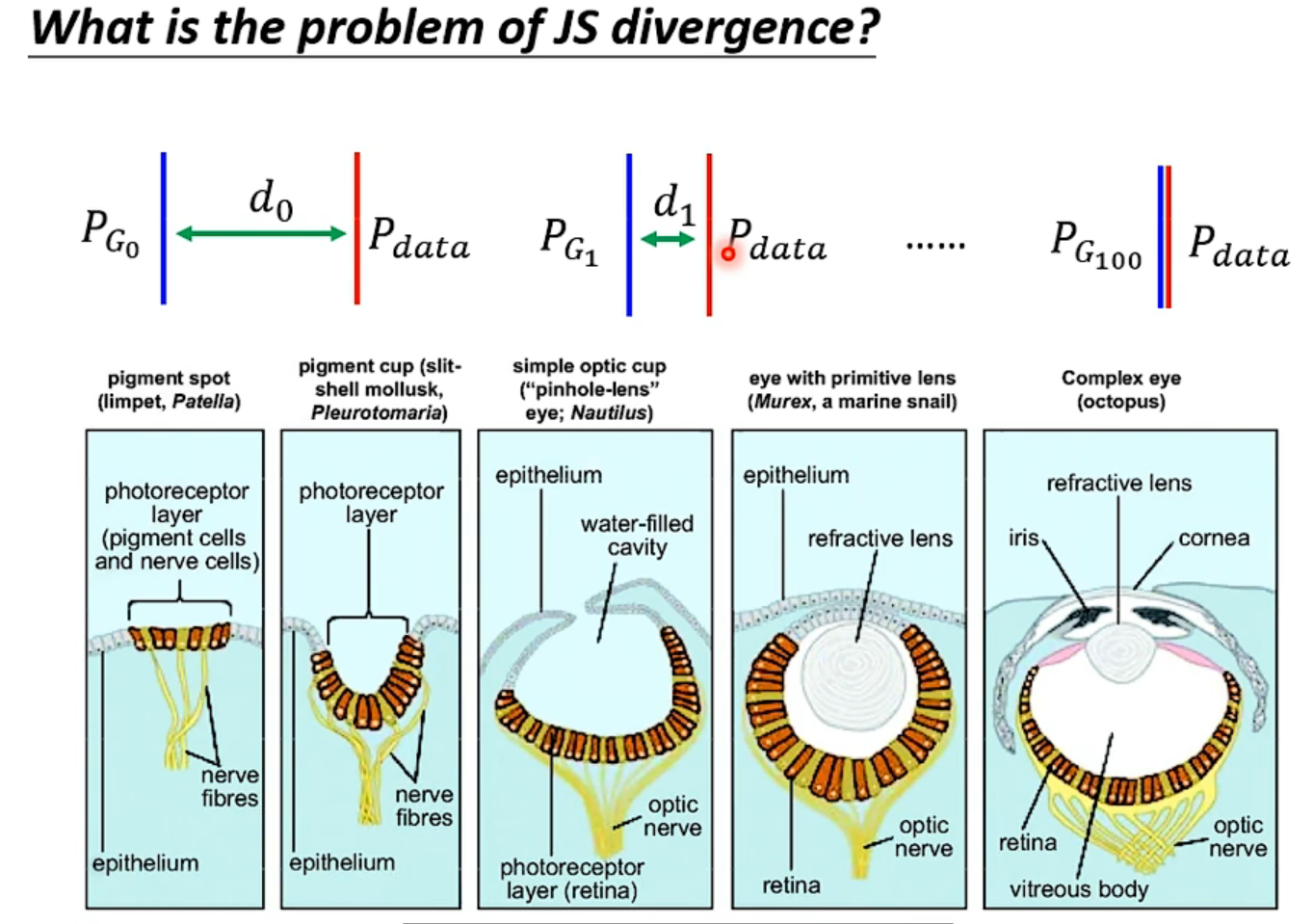


最终把右图的第一条式子解出来就是衡量divergence的值。
现在最好用的还是$Spectral\ Normalization$
只要某一次一个人开摆,另一个人就玩不下去了。。。所以难train 👇不一定有效

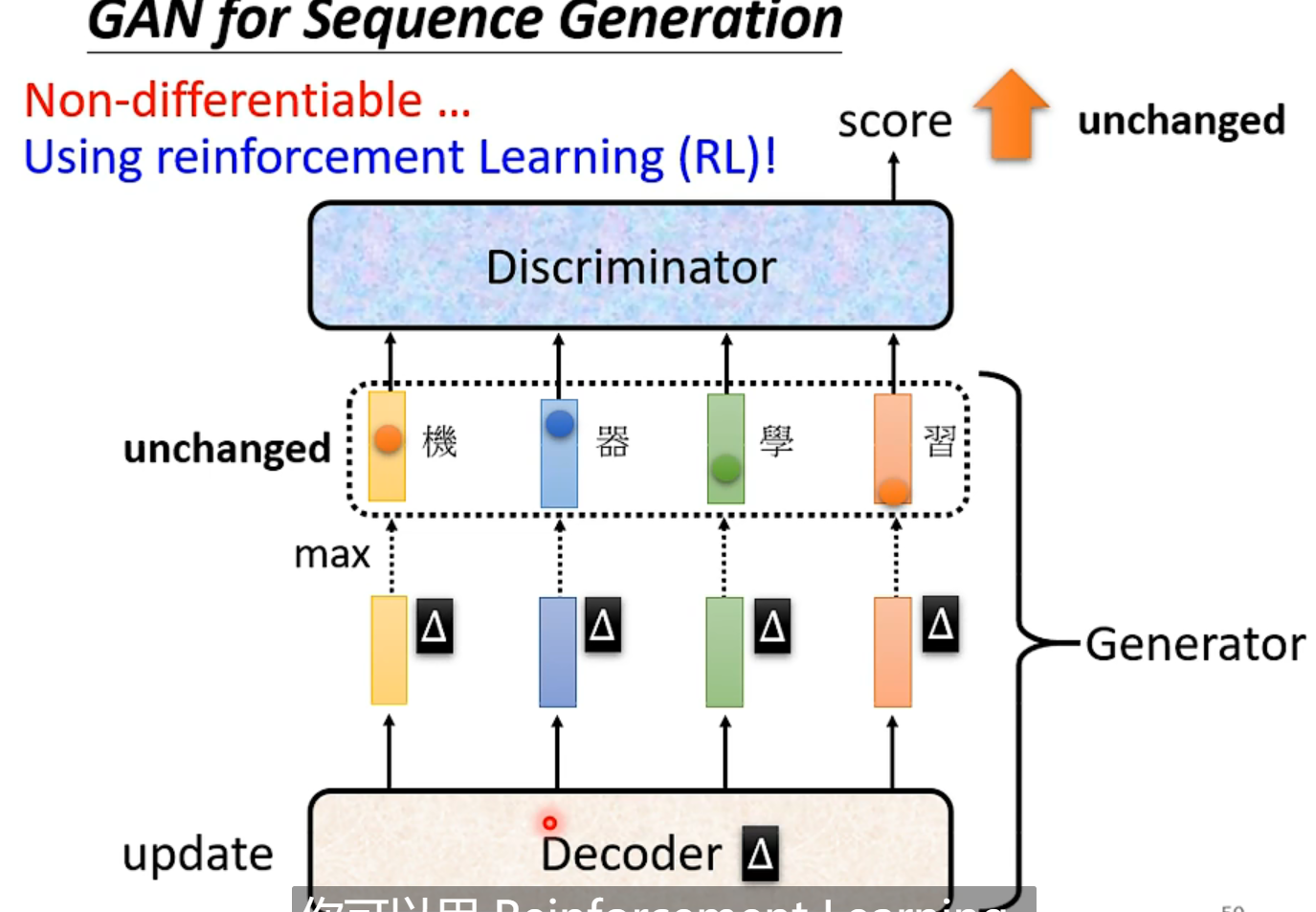
很难用于文字,因为取了个max,你微小的变化根本不改变输出,也就没法传递回去,过去很长时间都没法train
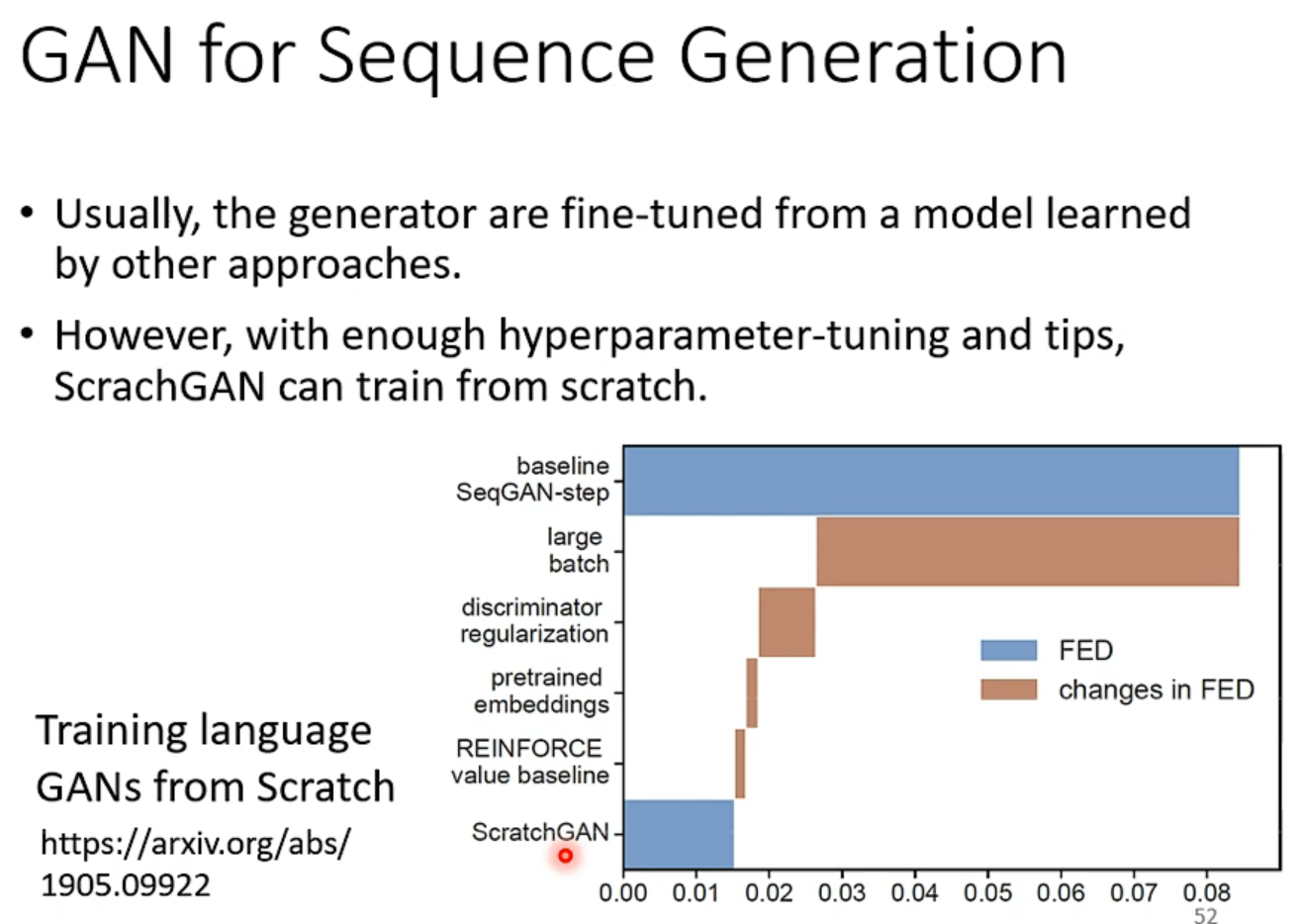
当然有人通过爆改超参数炼起来了。
还有GAN的更详细的一些理论:here的4、5、6
还有其他的generative models,不只是GAN:
甚至generation能当作监督学习问题来做。
Evaluation
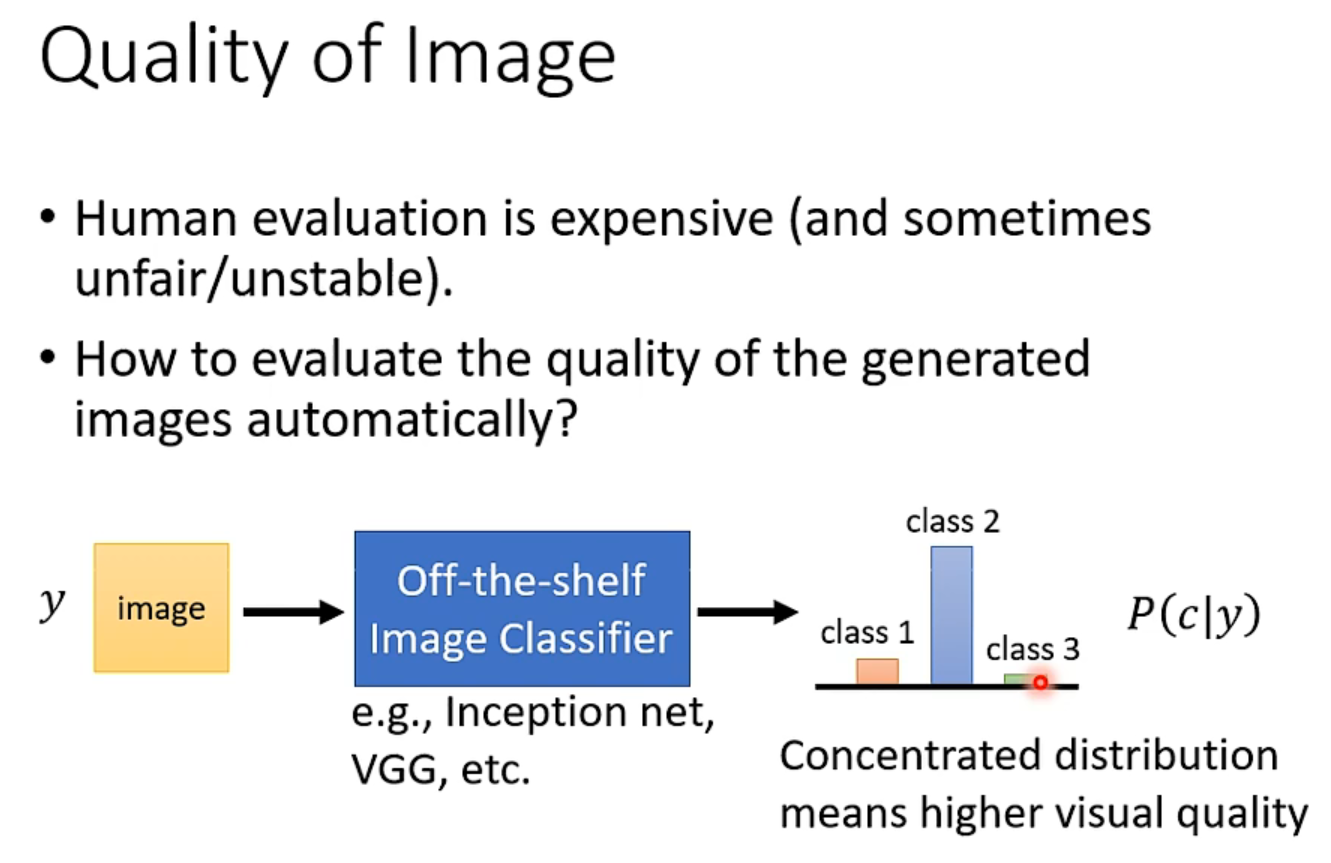

强如google暴搜都没法彻底解决这个问题,只能early stopping了,不过好歹容易侦测。

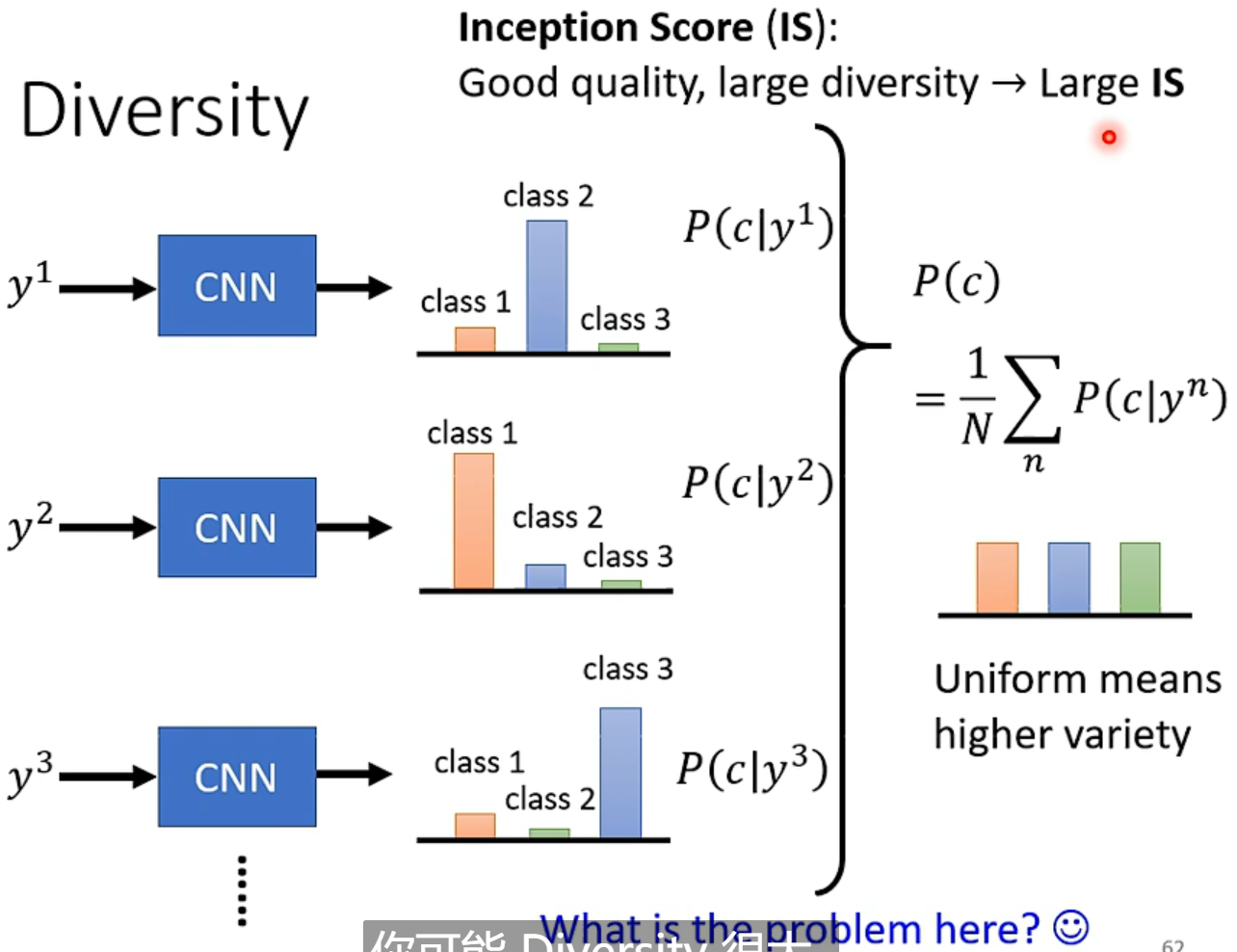
但是inception score对同种多个体的不适用(二次元人脸),作业用的是FID
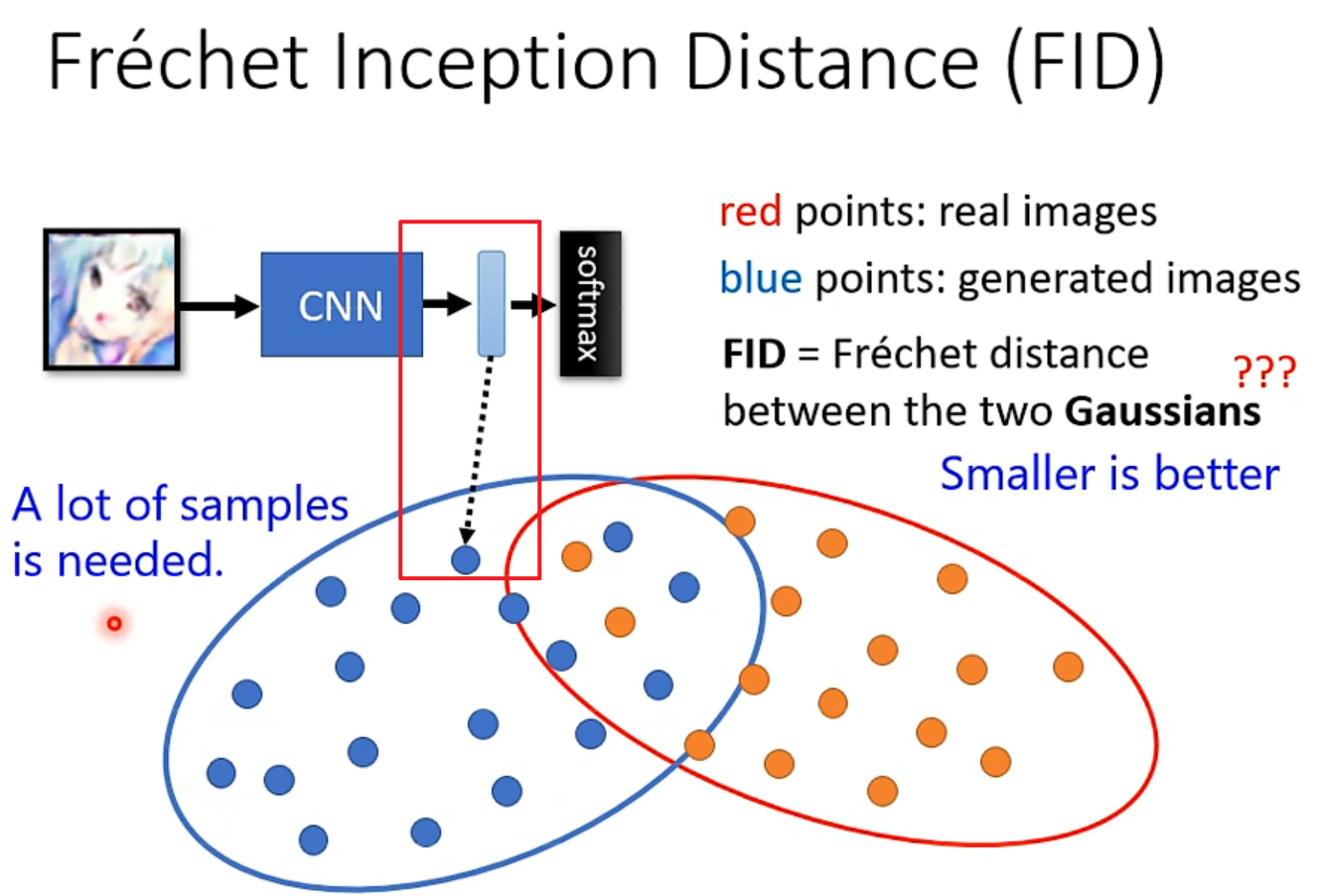

论文:Pros and cons of GAN evaluation measures 列举了很多方式供参考。
应用
Conditional Genaration
想进一步操纵输出,利用x向量输入模型来实现,以前用RNN,现在用transformer的encoder什么的都行。
x是一个控制,最终生成的效果和随机性取决于你sample的z,对应的discriminator也要更改,你训练的数据集要有pair
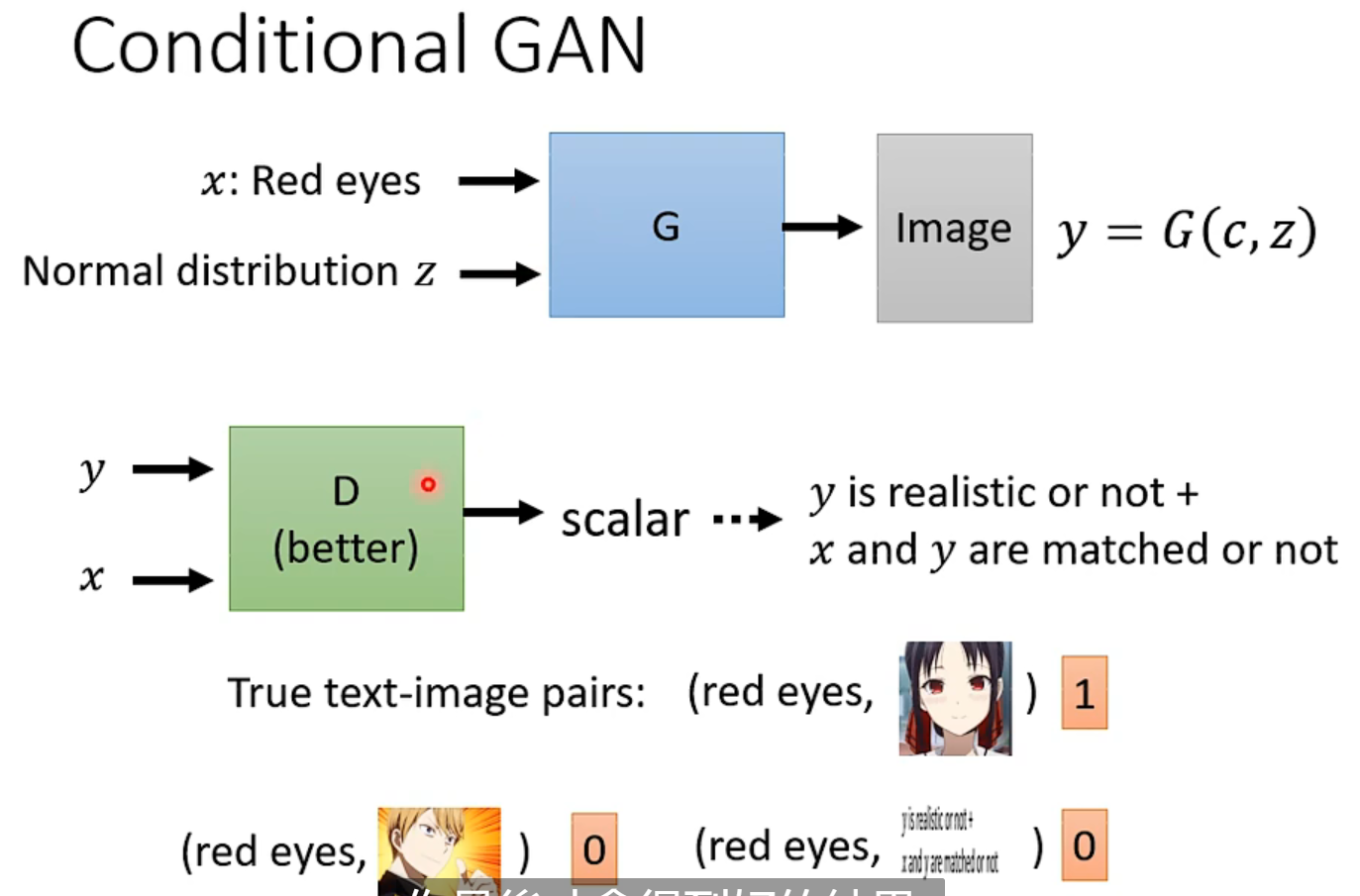
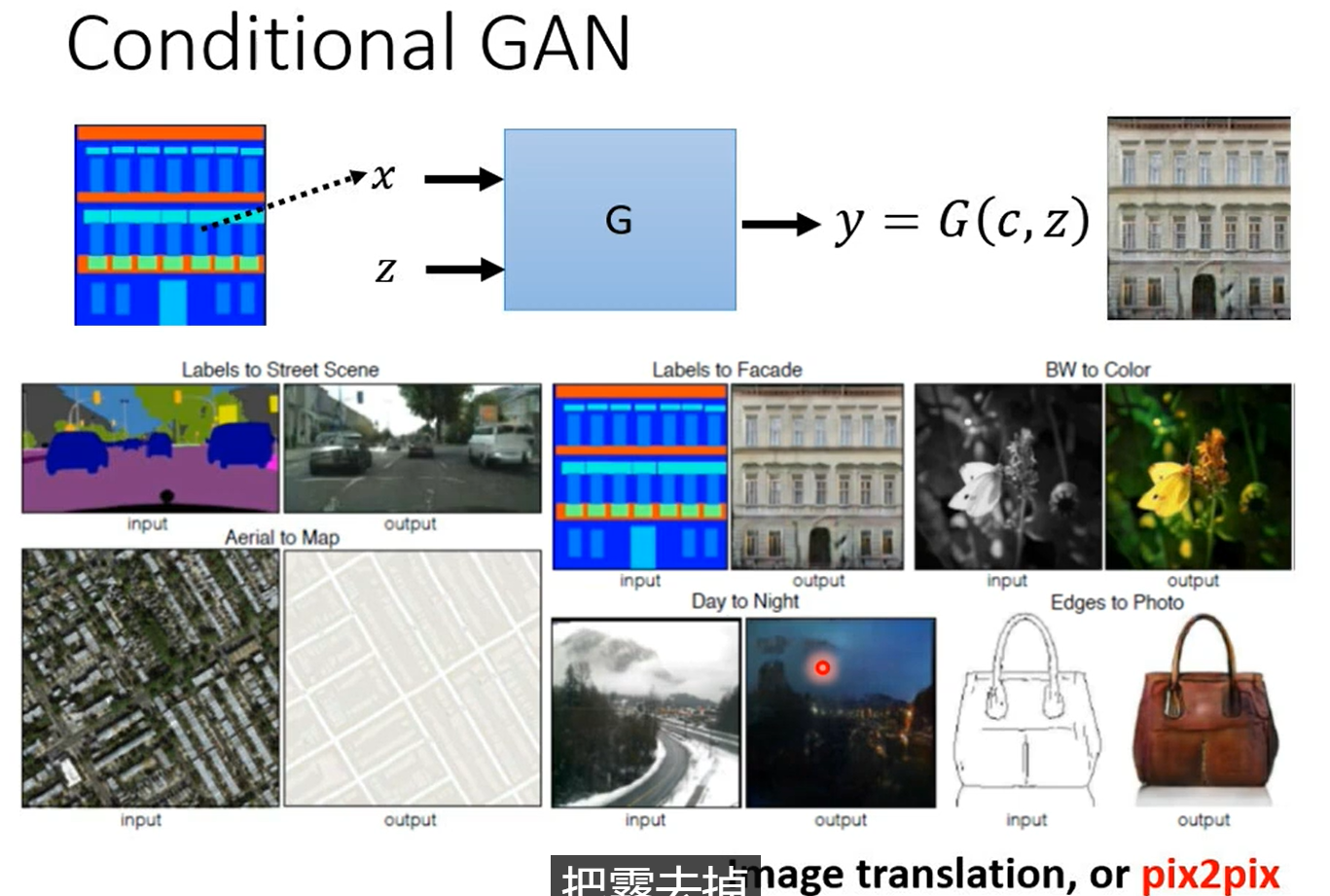
一般同时使用监督学习和GAN效果最好
还有根据声音生成画面的。还有产生会动的图片。
用在unsupervised learning上
你经常可能遇到一种情况,你有一堆x和一堆y,但是他们是不成对的,也就是unlabelled资料,那怎么训练呢?
比如影像风格转换就是这种情况。
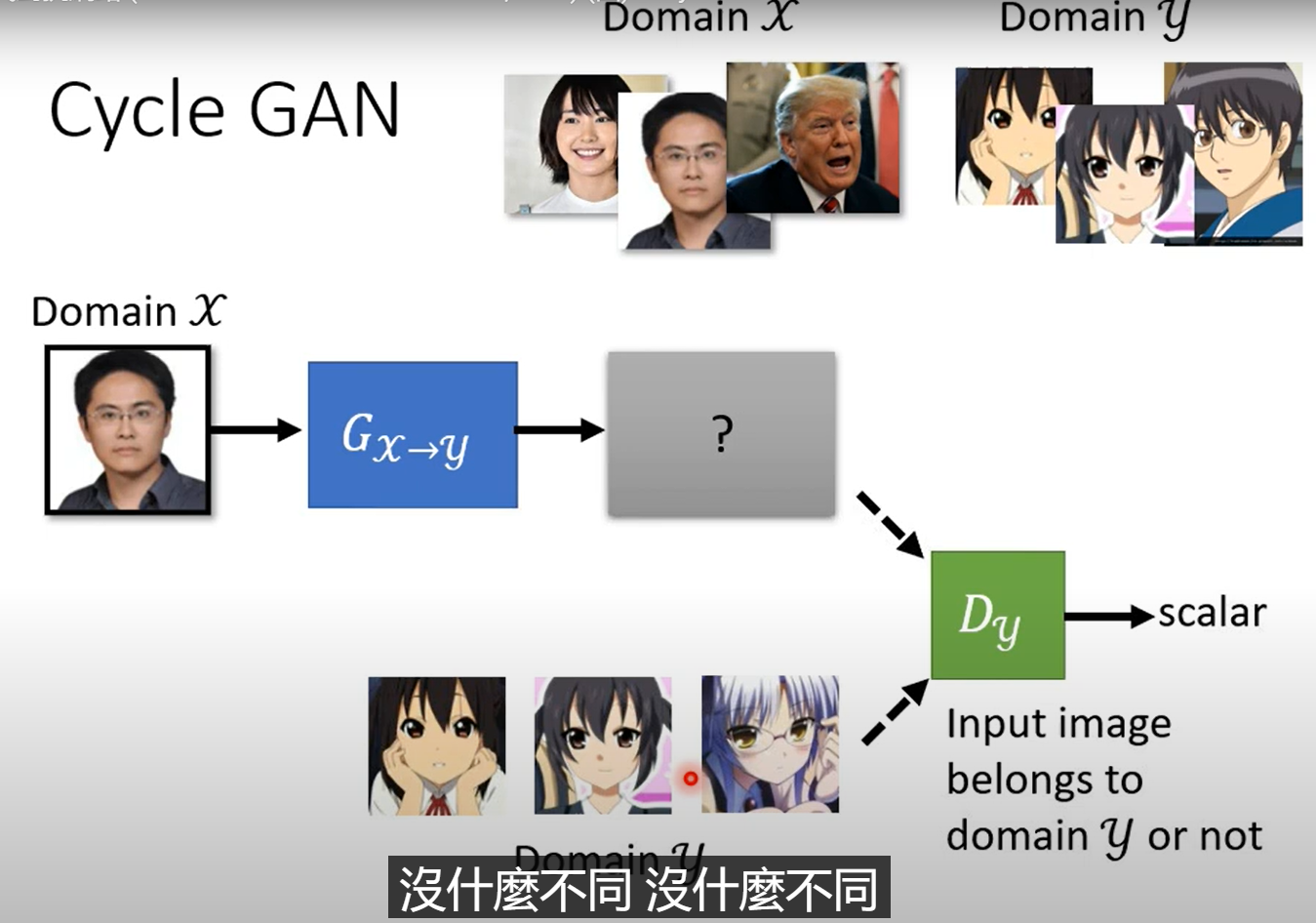
这个跟原来的GAN训练没什么不同,只是原本是从一个简单的分布中sample,现在是从人脸照片里面sample,后续步骤很接近。
但只是这样的话,输入和输出就没什么关系了,我们要强化他们之间的关系。
之前的conditional generation用的是paired资料,但是对这个场景,我们并没有这样的资料。
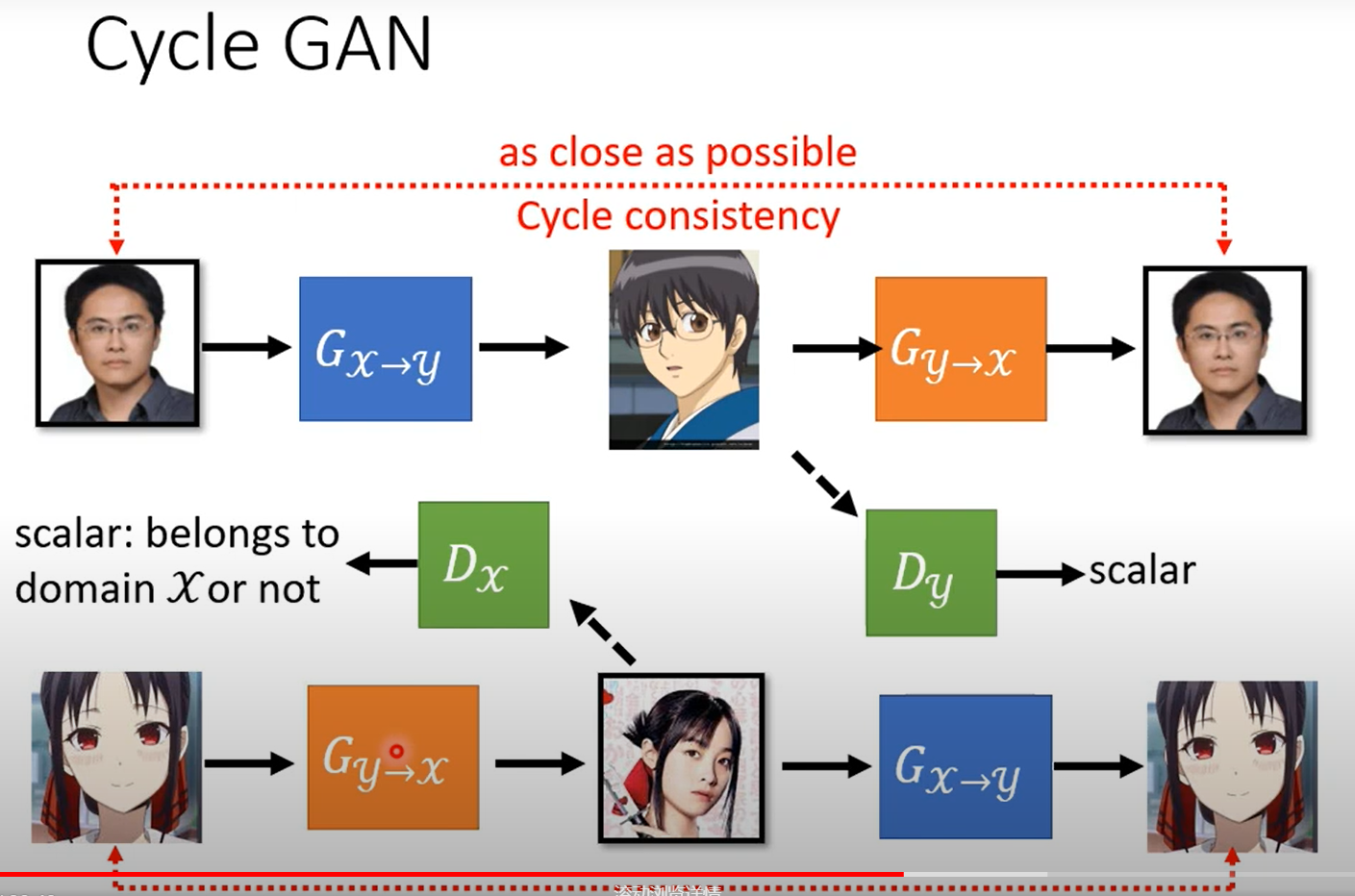
Cycle GAN
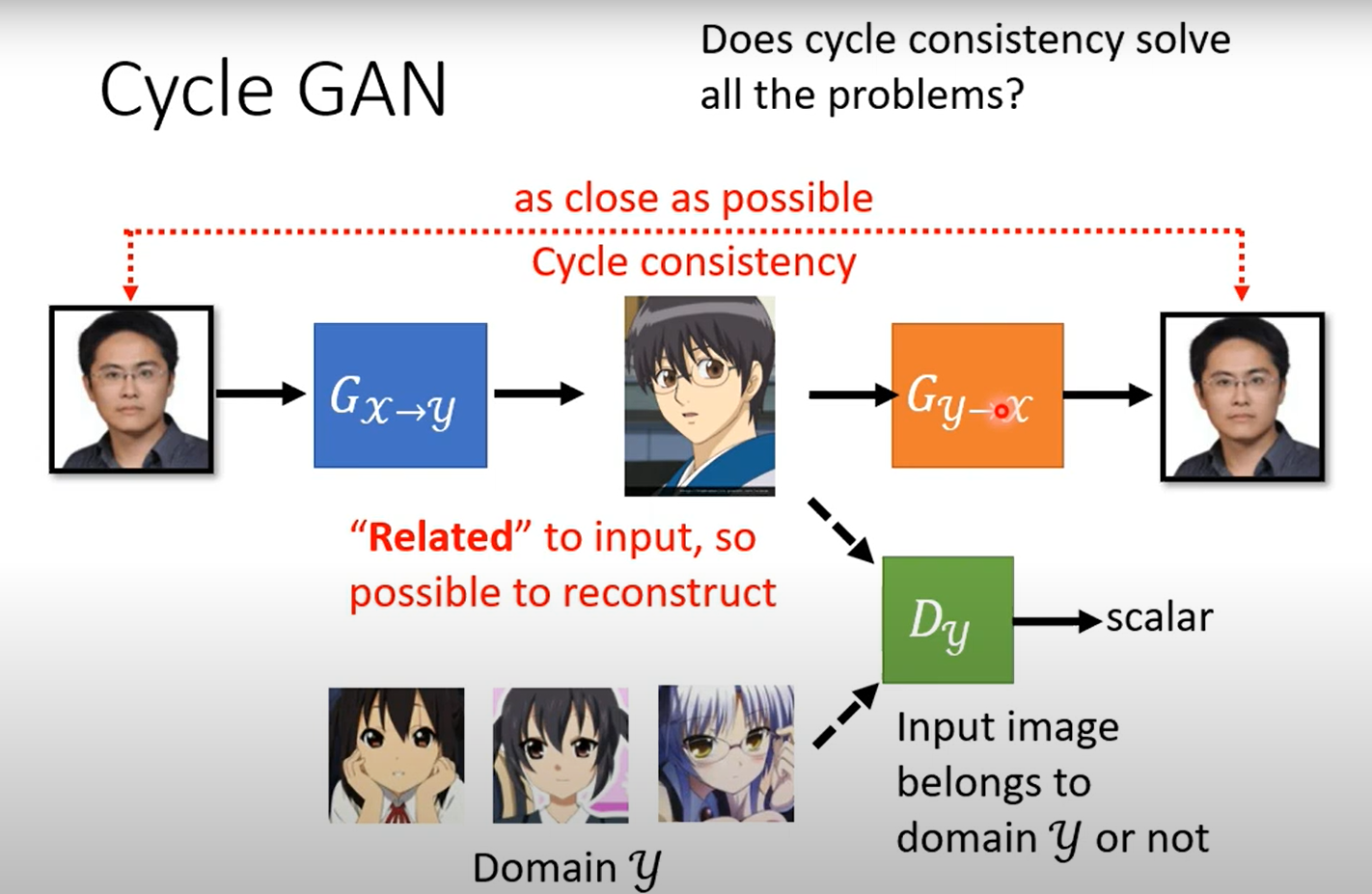
你可能会担心学到一些很奇怪的对应关系,也能满足上述条件,但实际work中一般都能比较好的完成。
甚至是你不用cycle GAN直接上也能train出来network比较懒,一般都会输出比较相近的东西,但理论上没有什么较好的解释。
同时训练三个:
还有更厉害的work:starGAN可以在多种风格之间转换。
还有很多类似的text之间转换的work和领域。
自监督学习
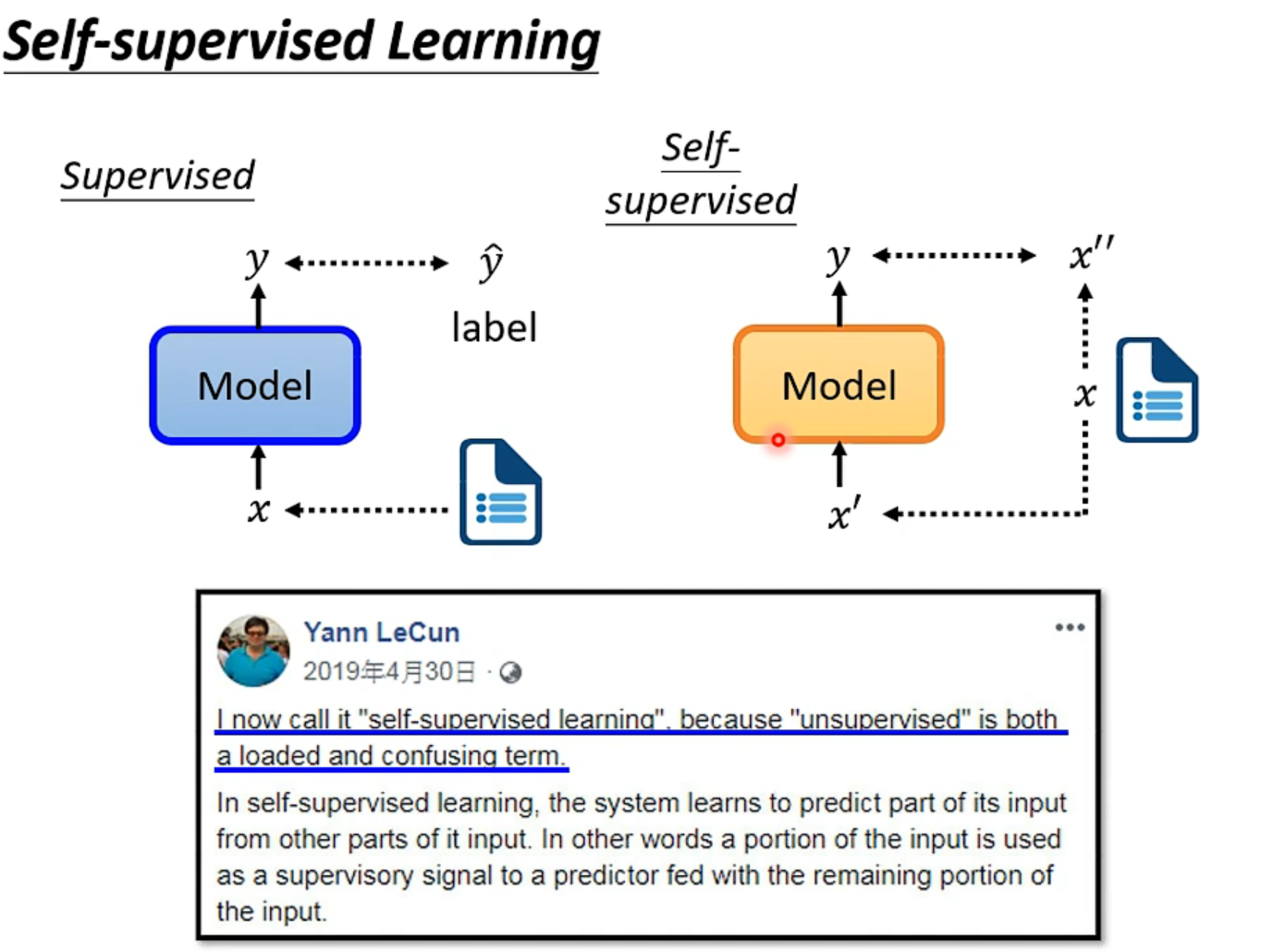
Self-Supervised Learning
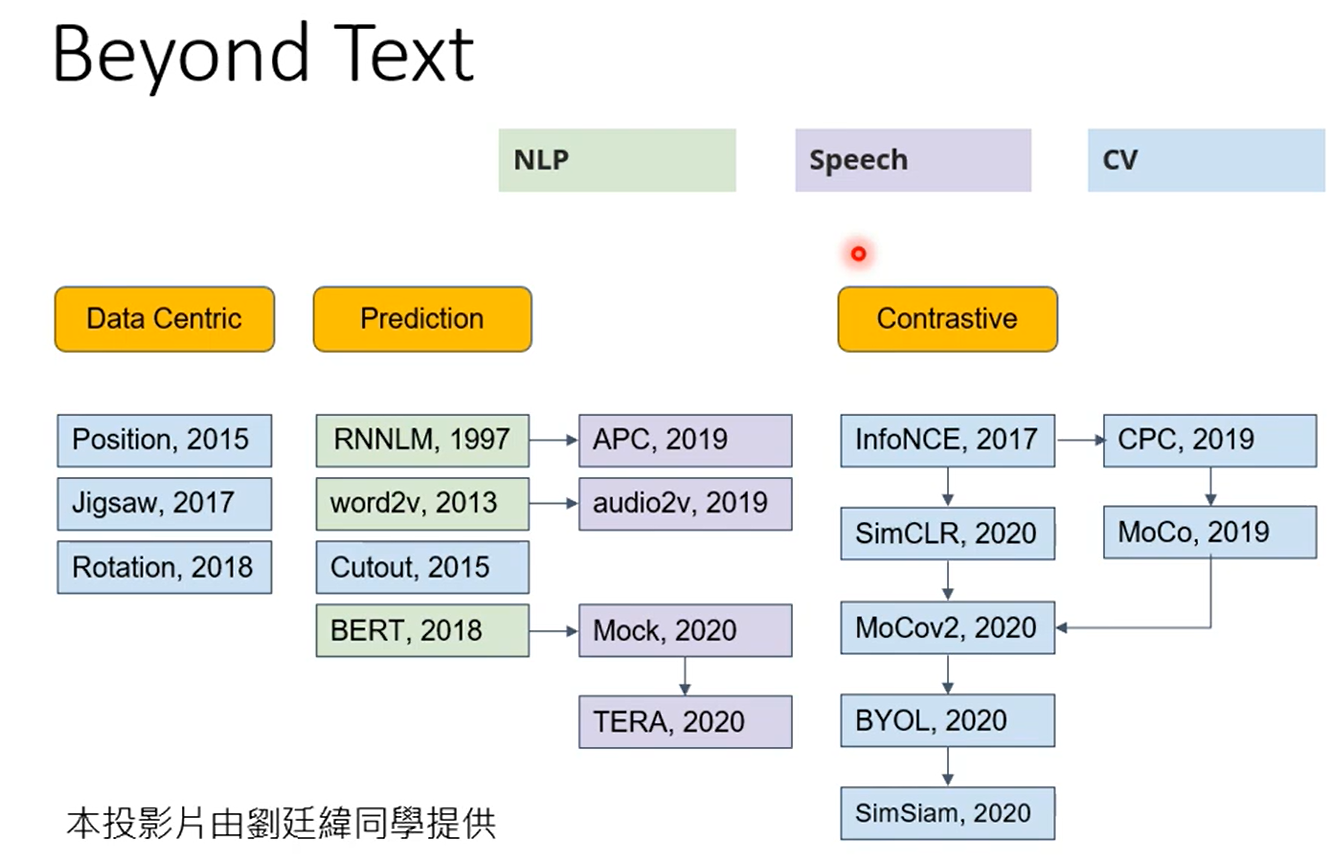
这个领域有许多的内容值得我们探索,见右下图
哈哈哈BERT有340M个参数。就这竟然还不算大的,xswl


然后还有个Switch Transformer比GPT-3大十倍! 1.6T参数我日
所以自监督学习可以看作是无监督学习的一种。
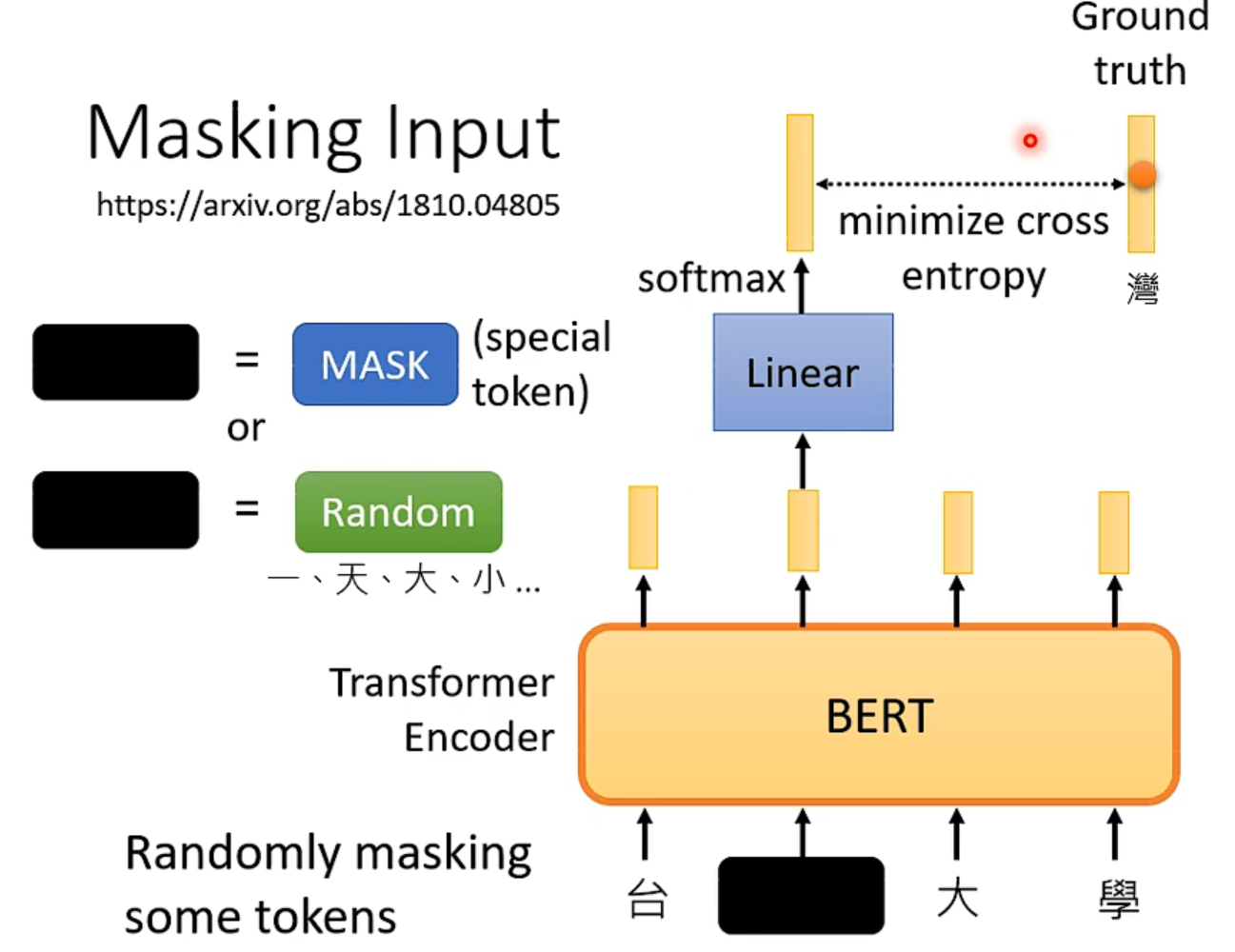
BERT
可以处理序列数据,因此不局限于NLP,还可以是语音、影像等等。
自己遮住某些词元(两种方法都可以),然后当作标签,训练来减少误差。
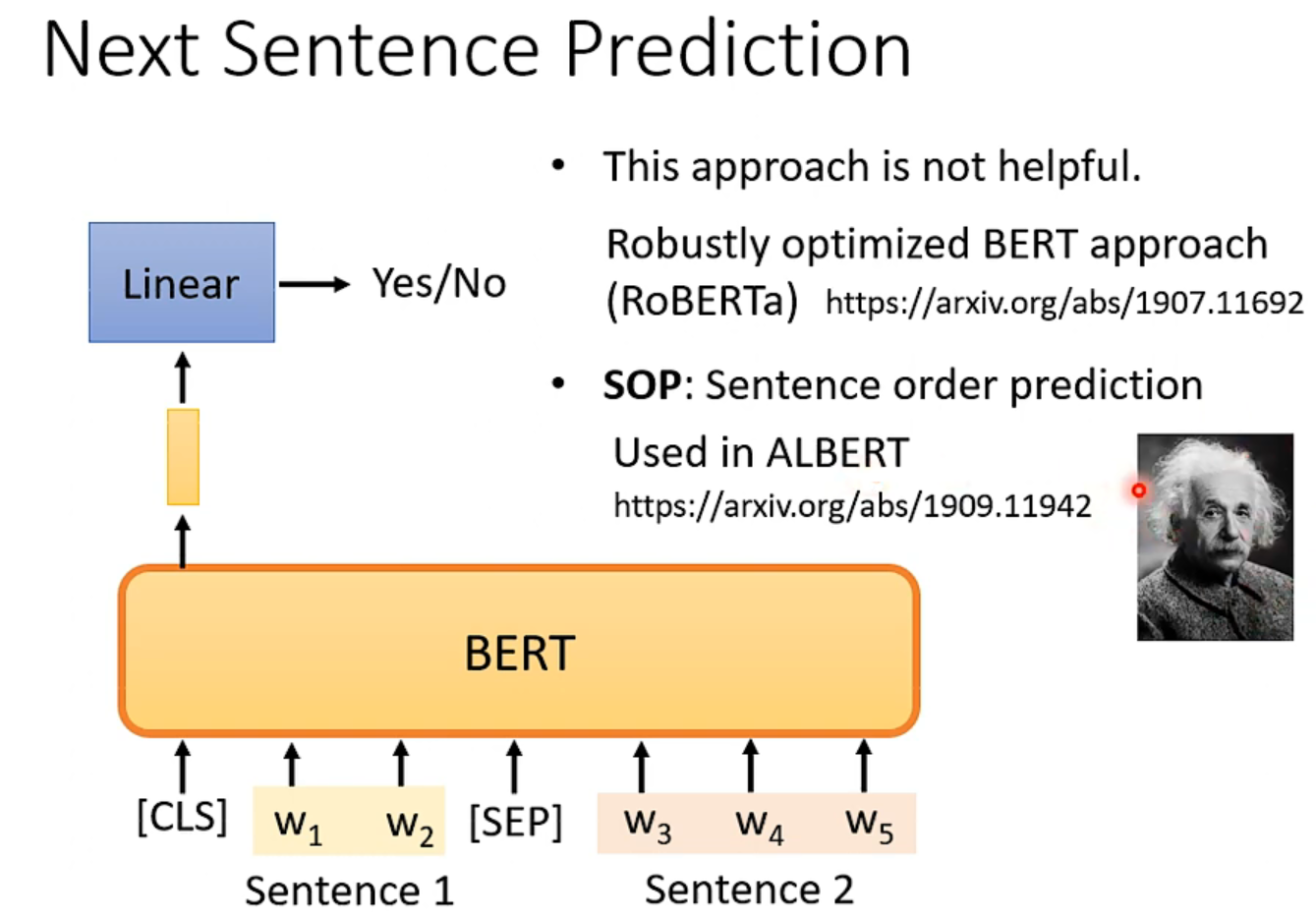
现在大家说,这个什么next sentence prediction没什么用,也有很多文献证明这一点,反倒是SOP那种判断句子顺序的方法,在bert的一个进阶版本albert里就很有用了。
现在bert会做填空题,神奇的是,现在bert能被用在其他别的任务上。而这些任务甚至可能跟填空题没有什么关系。
这些任务被称为是downstream tasks,也就是我们真正在意的任务。
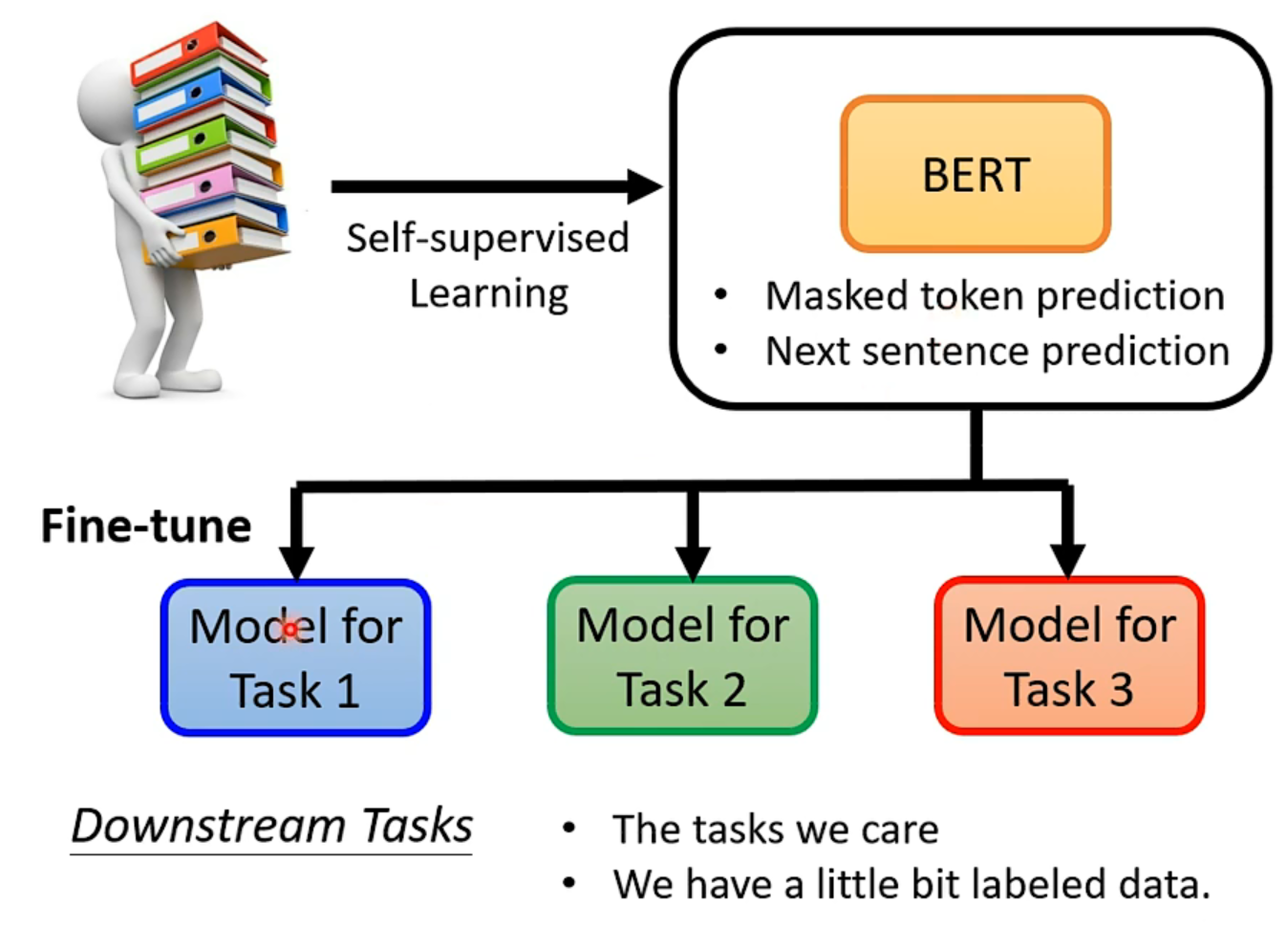
他就像是干细胞,给他一点有标注的资料,他就能学会各式各样的任务,这也叫做Fine-tune
GLUE
由于bert这种特殊性,一般会测试你训练出的这个bert模型在各式各样的任务上的能力。也就是分别微调到9个任务上,然后看看你的模型表现的平均效果。

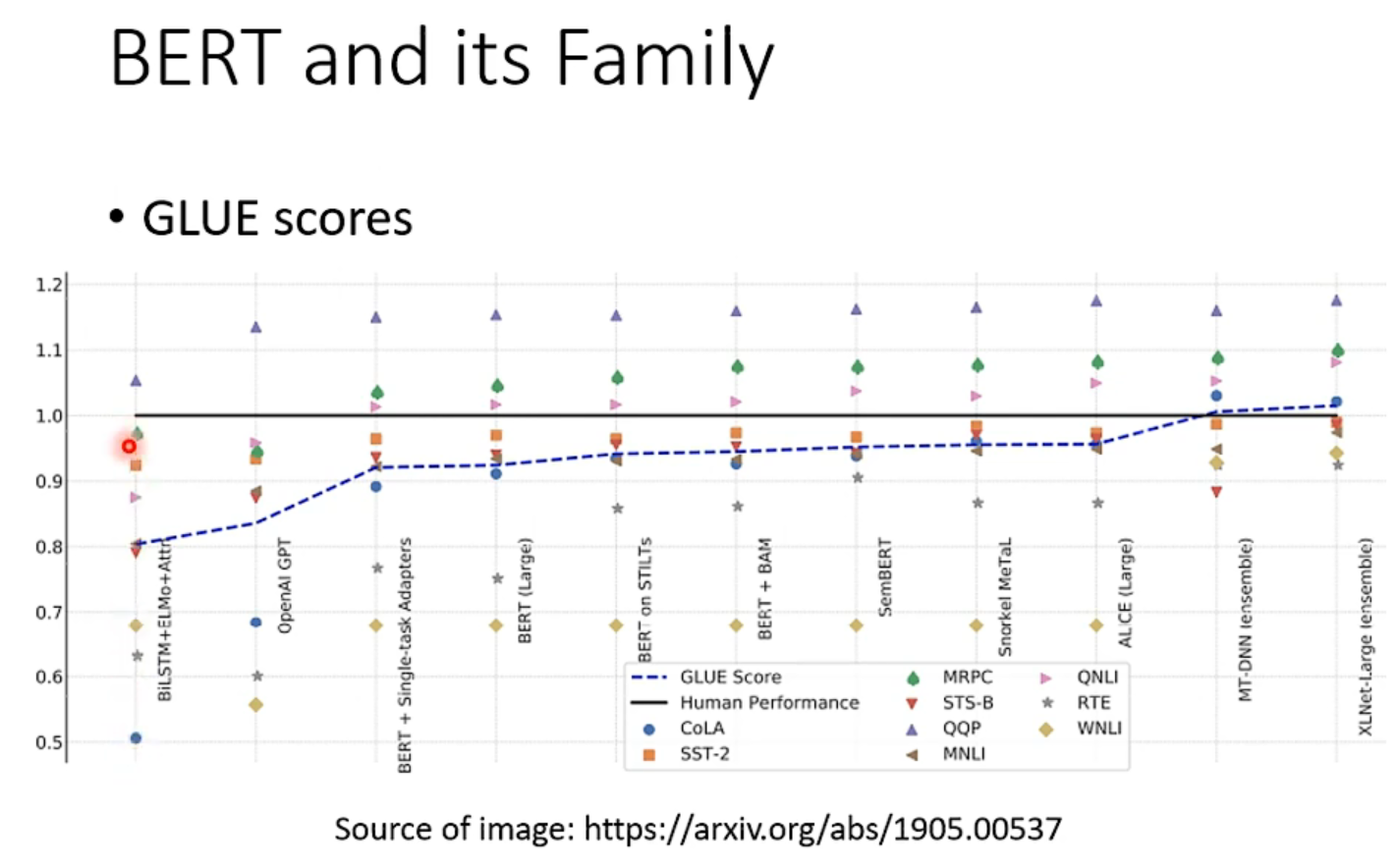
这个基准线是人类能达到的程度,可以看到bert家族的能力逐年攀升。
可以看到模型已经“超越人类”,但显示的是这个资料集被玩坏了,所以就有人创建了更难的数据集,也就是啥super GLUE
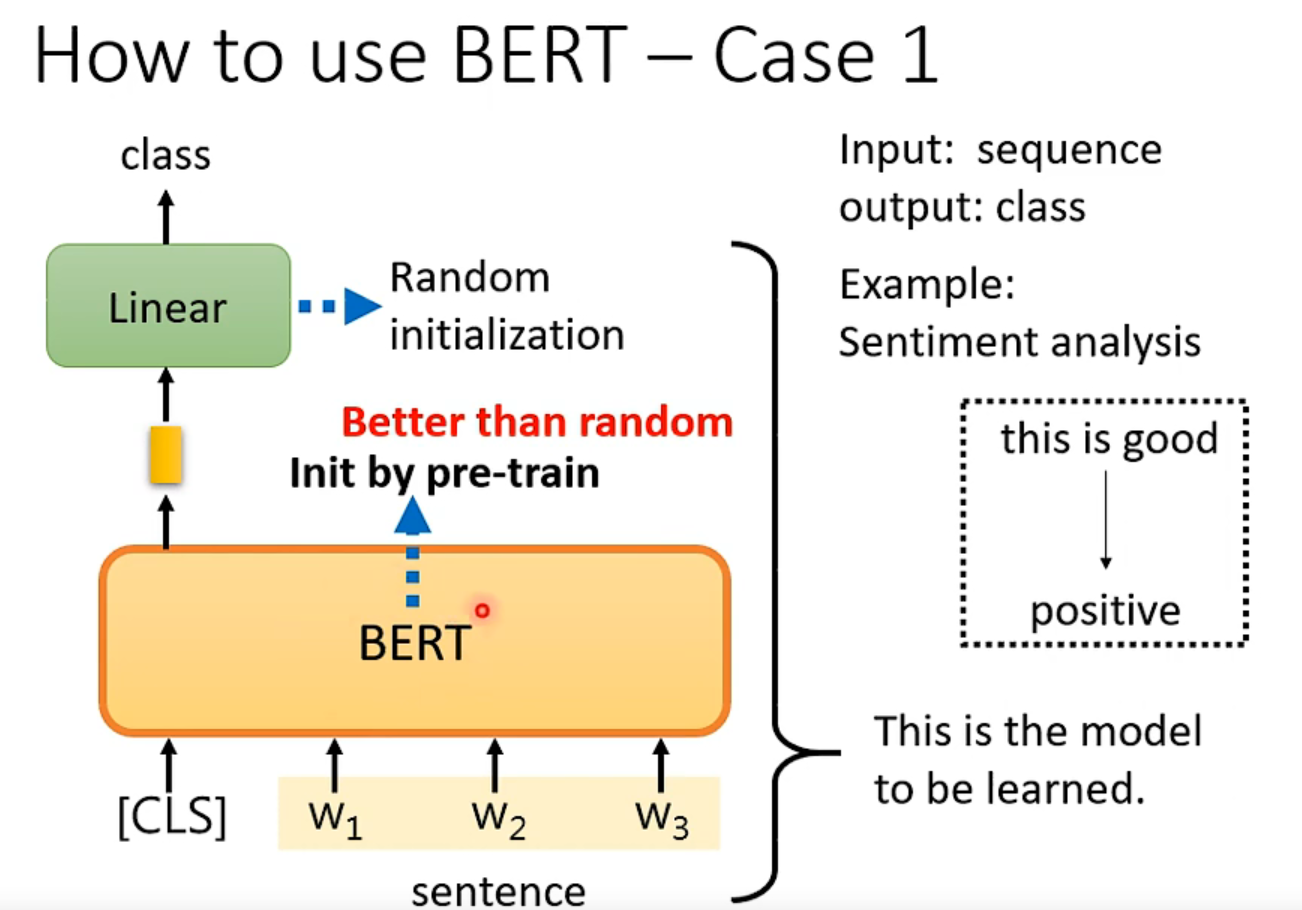
使用流程:
把你做填空题训练出的参数填到BERT模型里,这远比随机初始化的效果好很多。
然后用这个模型来“fine tune”,牛啊!然后就可以分化到各类任务了。
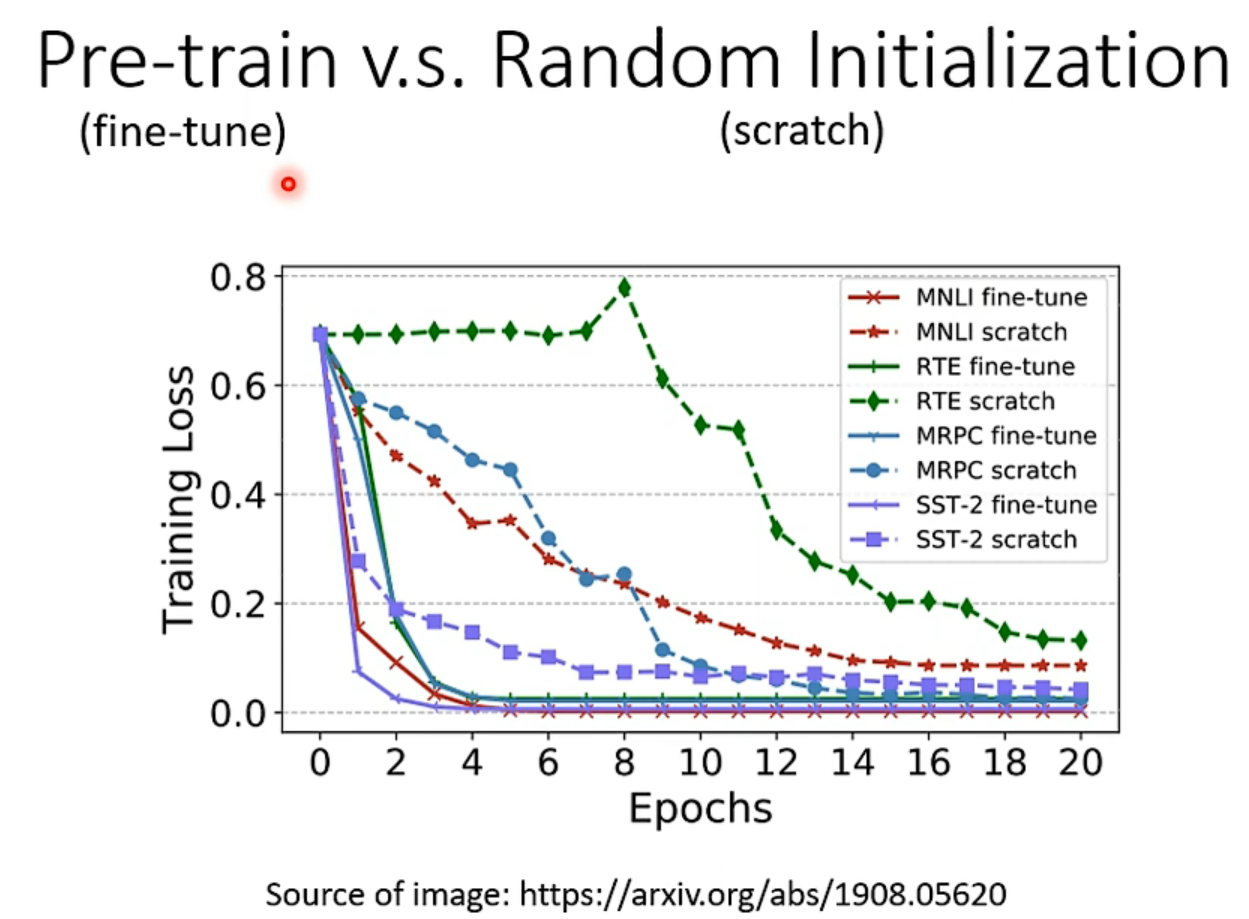
看右边这张表,有了bert初始化的模型,不仅在训练过程中loss下降较快,而且最终的效果也更加好一点。
BERT上游是无监督、下游是有监督,合起来tm叫半监督。。。这着实太敷衍了一点。
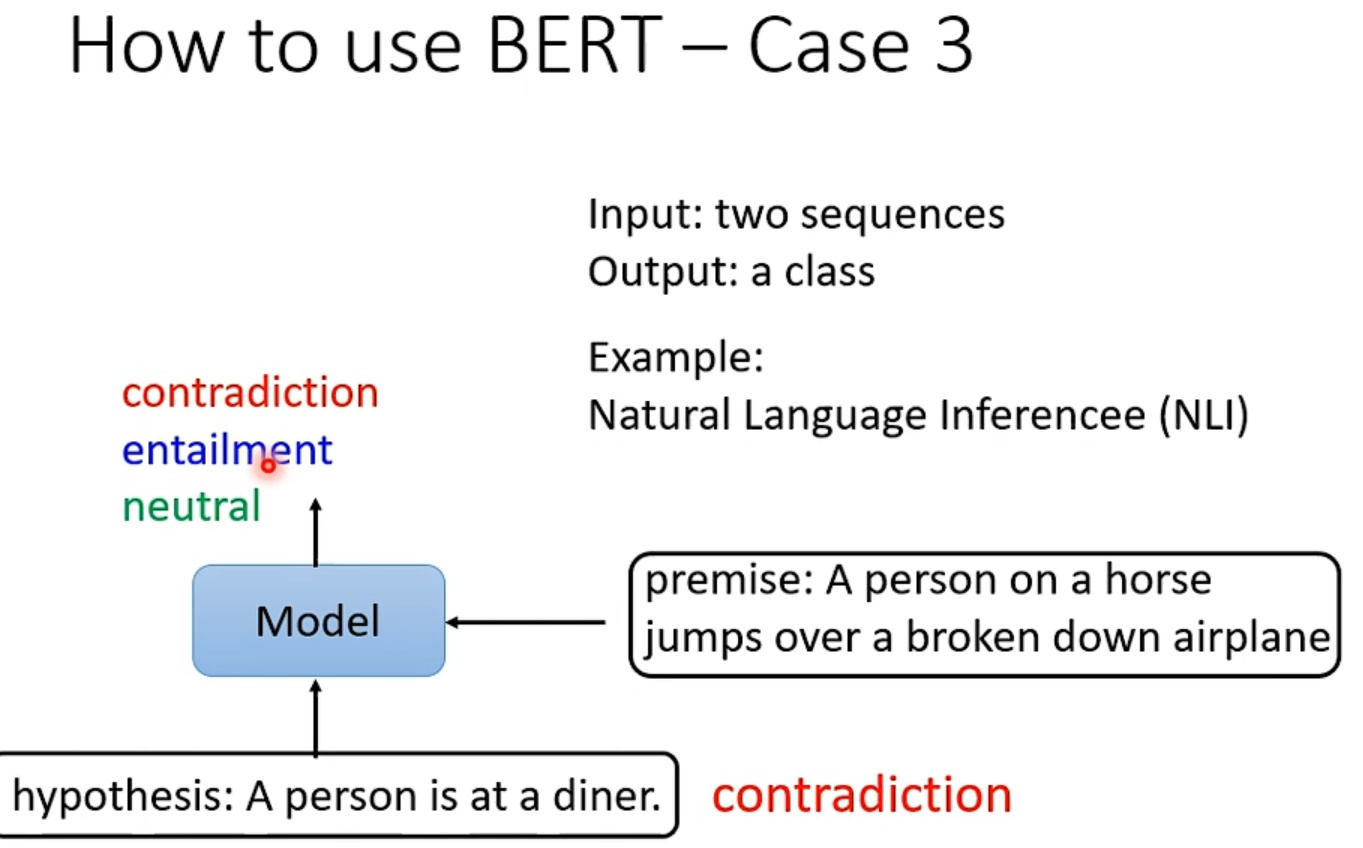
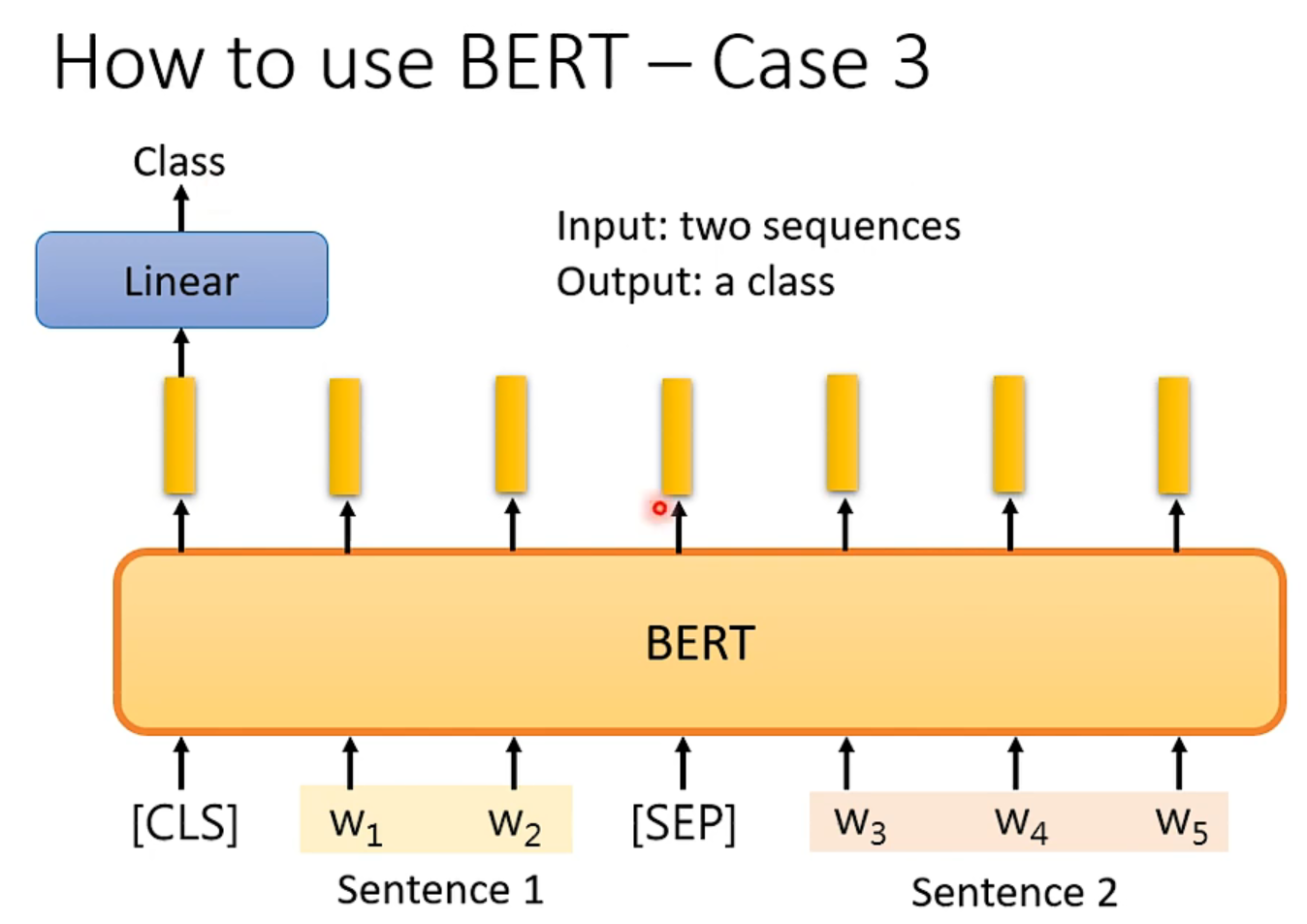

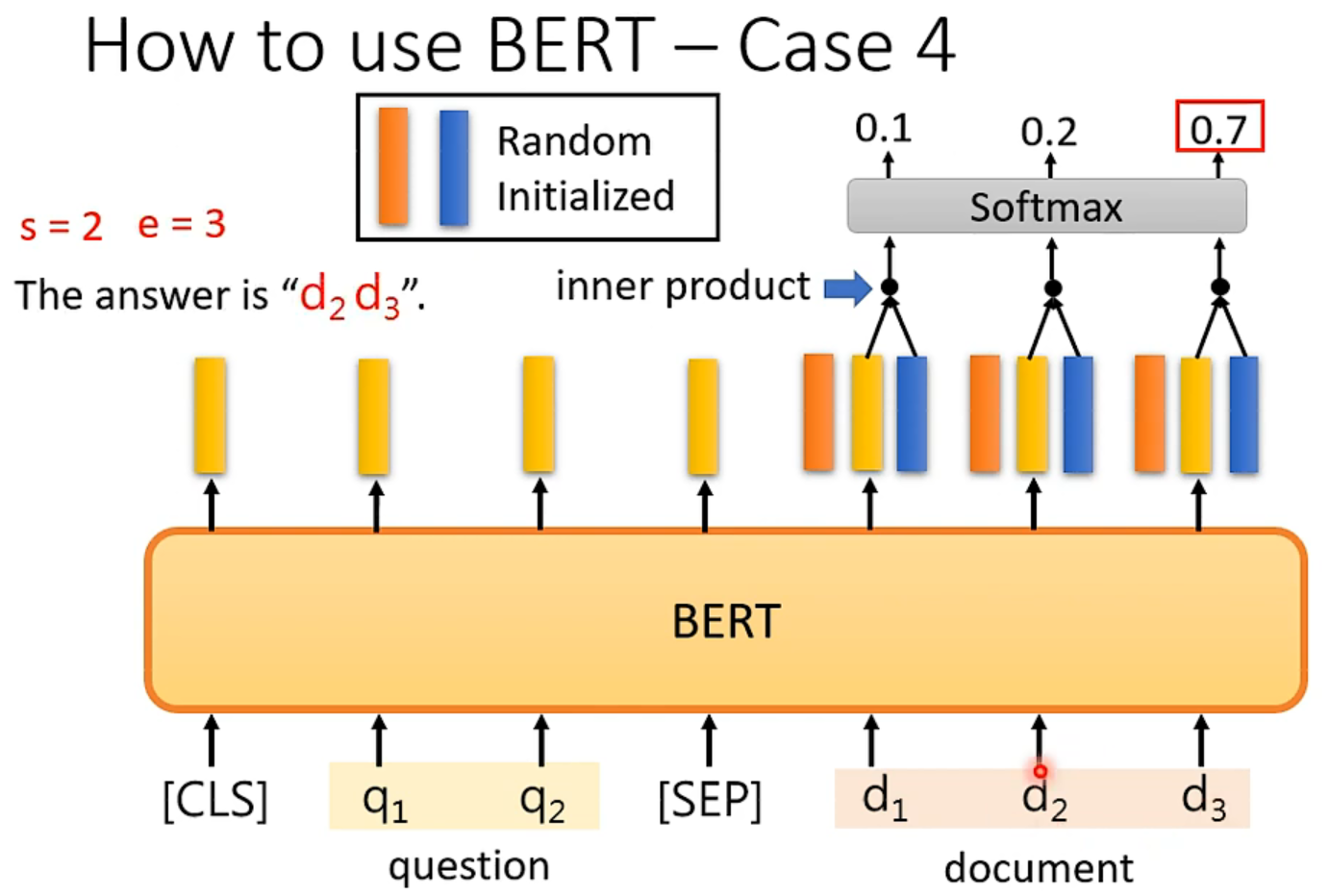
但是要注意,这个问答系统是有限制的,也就是答案一定出现在原文里,上右图理解:随机初始化和BERT输出维度一样的橙色向量和蓝色向量,分别和输出做内积然后做softmax,橙色最大的那个输出的位置代表了答案开始的位置,蓝色是结束的位置。
理论上,BERT是transformer的encoder架构,可以接受任意长度的输入向量,但是从计算量考虑,512已经有些让人吃不消了。
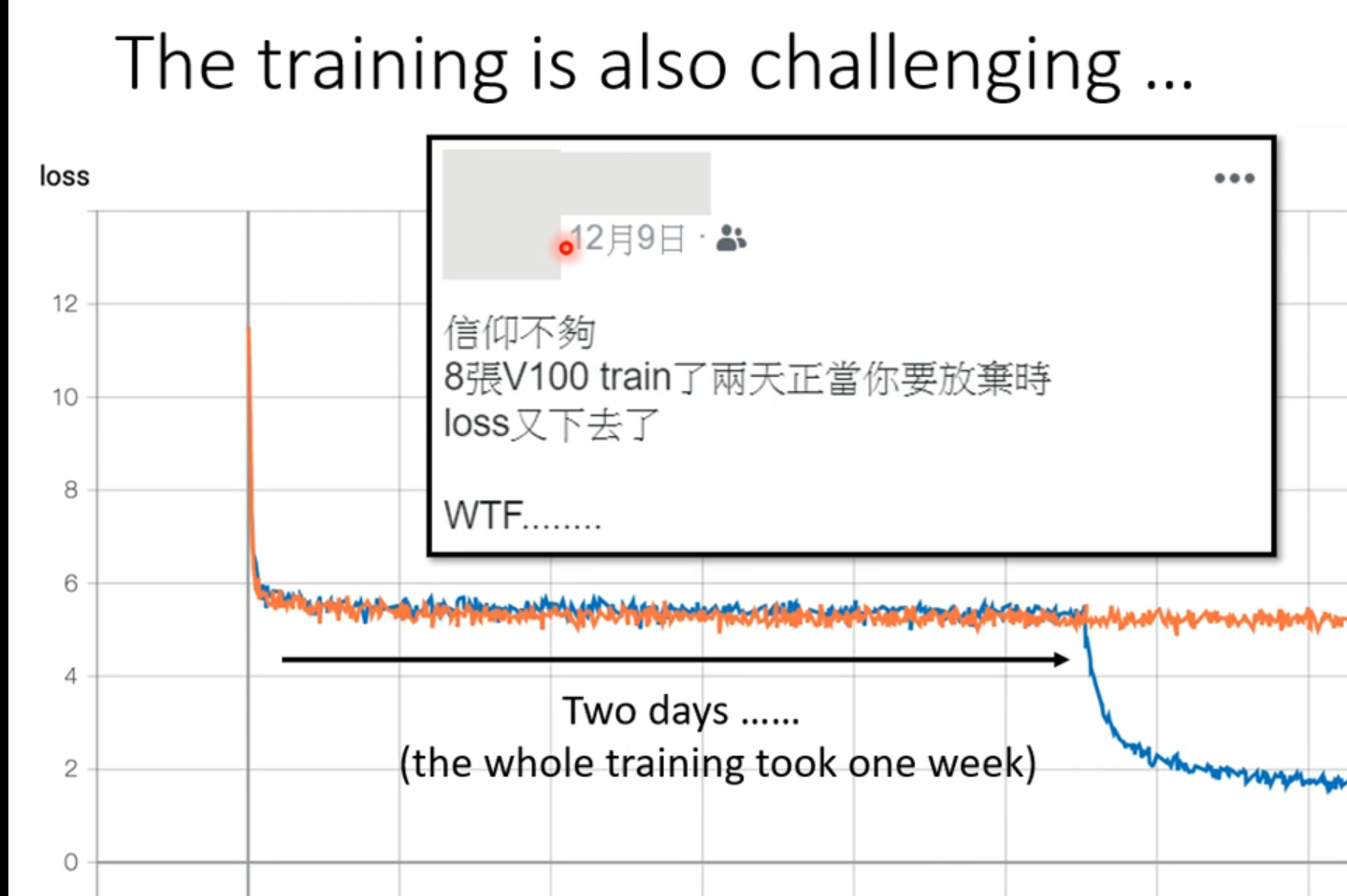
训练成本太高了,如下,李老师的学生跑了100w次,用TPU跑了8天。
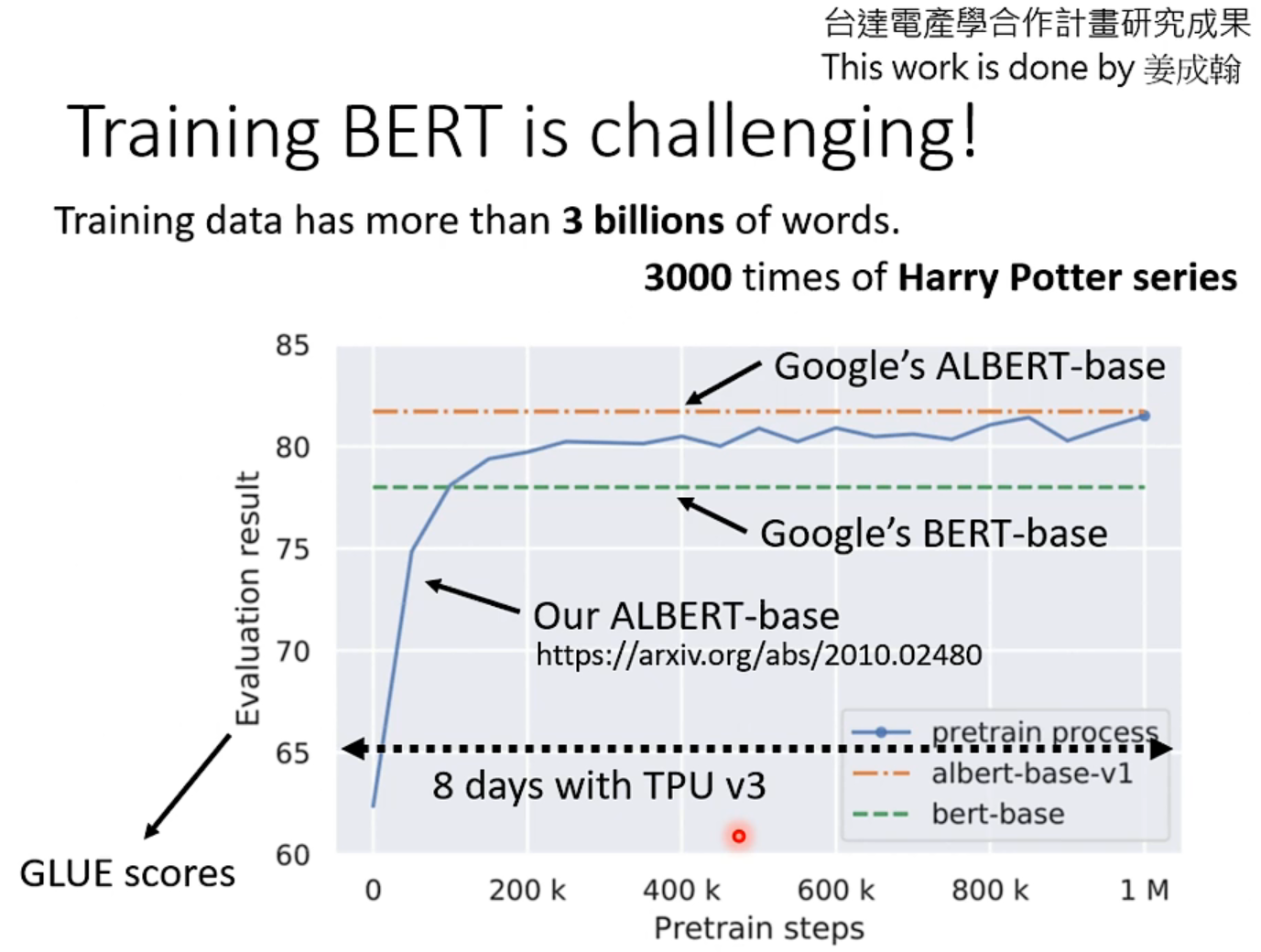
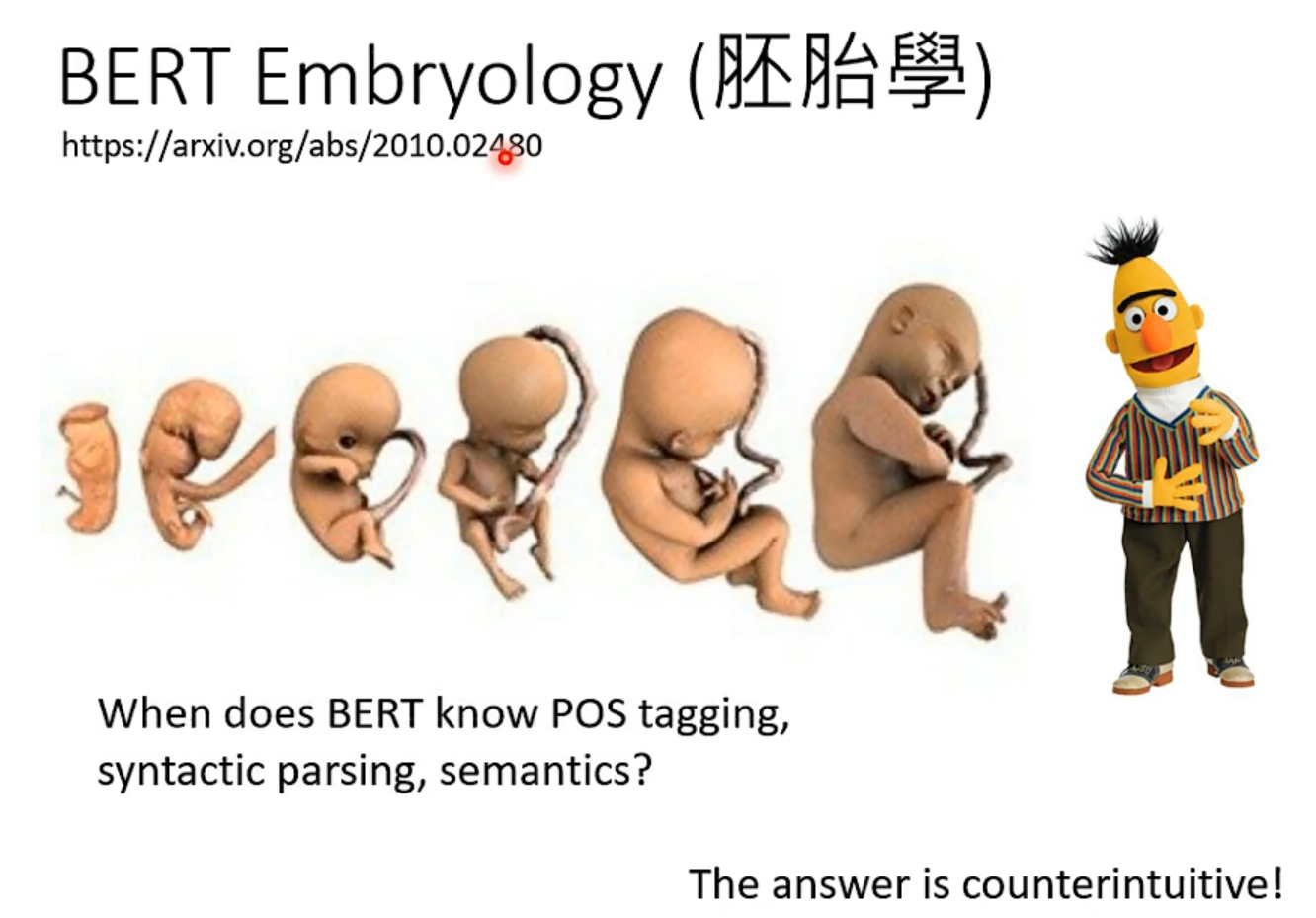
右边那篇论文,介绍了对这个预训练过程的学习和了解,是李老师团队做的,有兴趣可以参考一下。
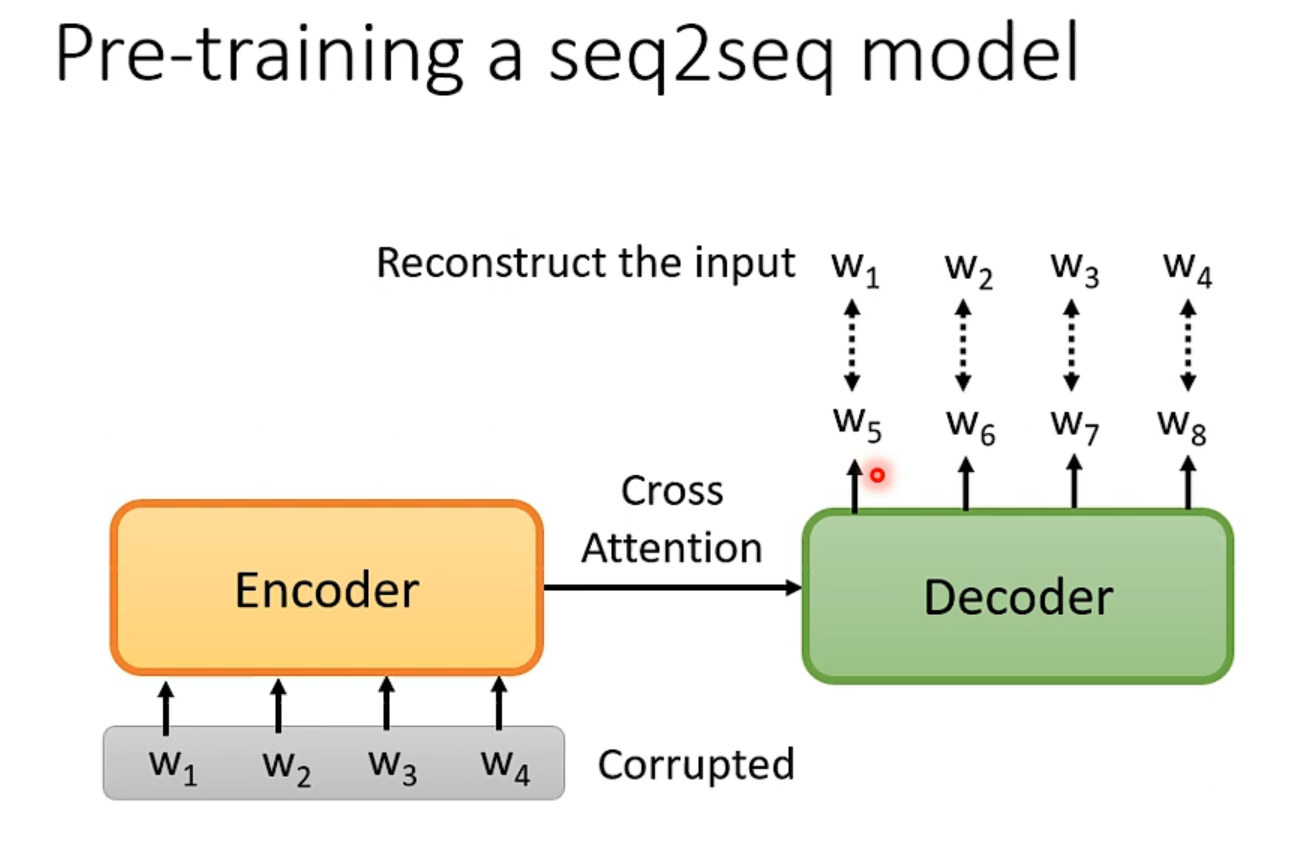
然而上文并没有提到seq2seq的预训练过程,具体怎么做呢?
先把输入的向量弄坏,然后希望decoder能重建弄坏的结果,弄坏的方法多种多样
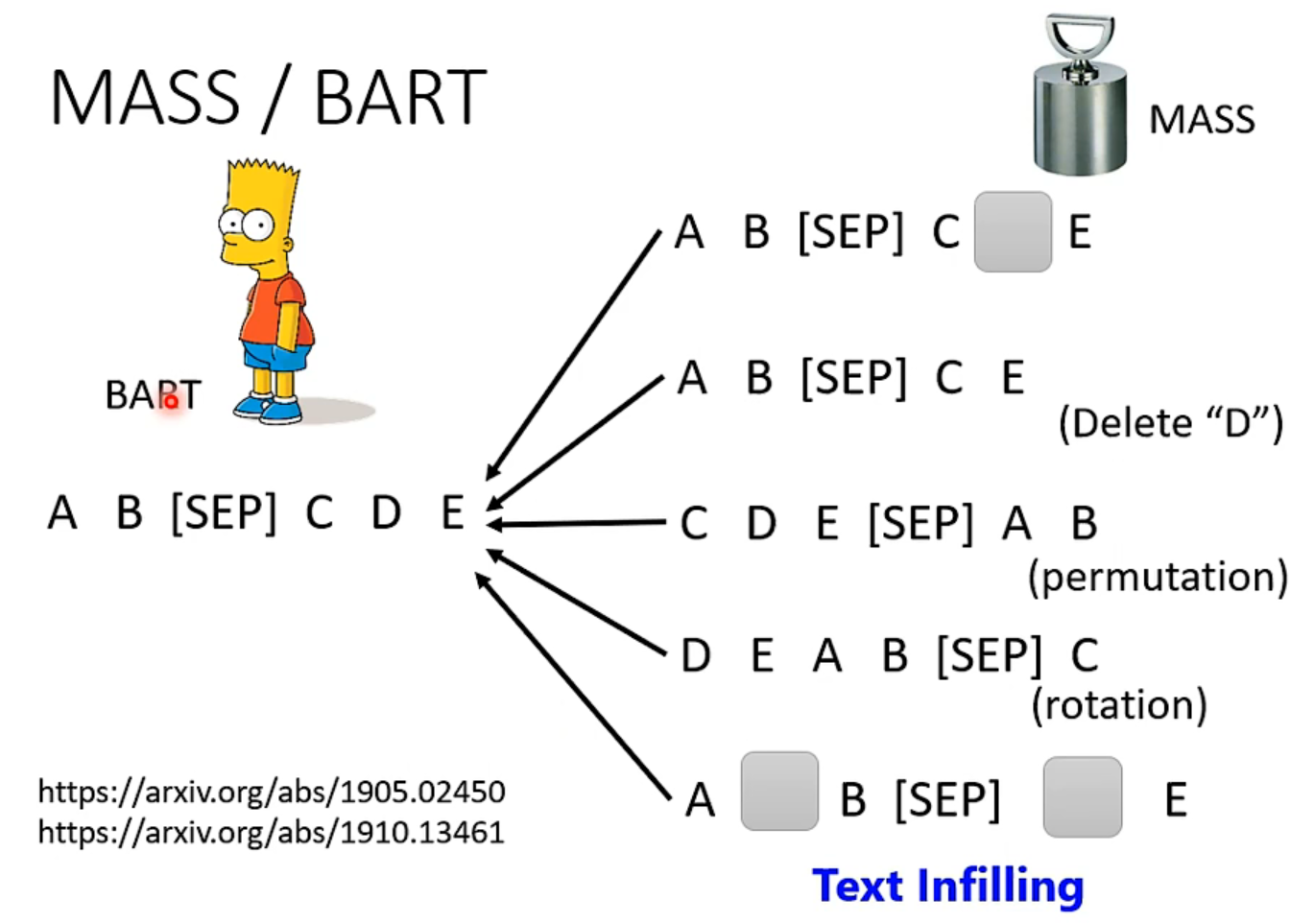
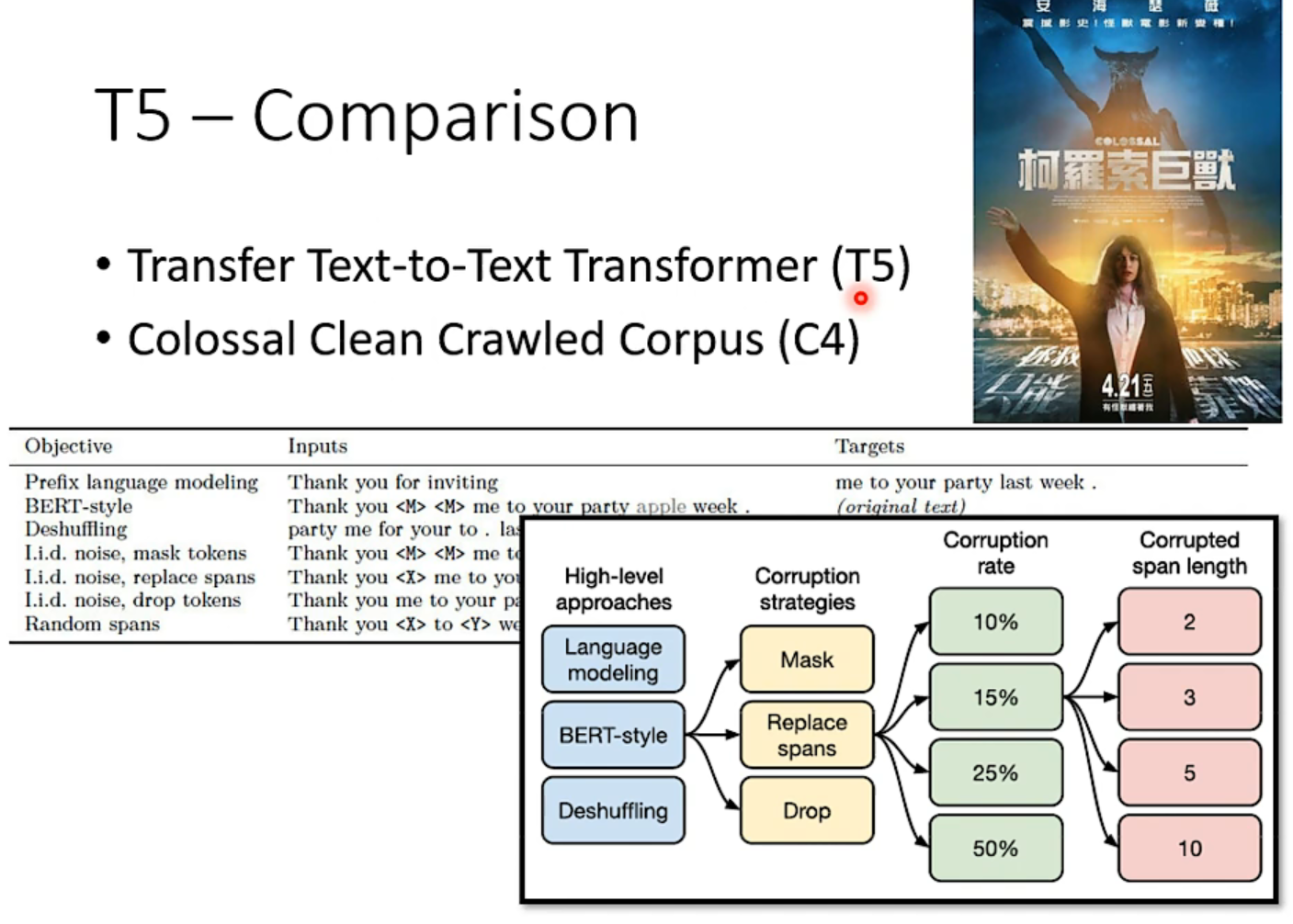
用哪种方法好,google已经尝试过了,详情见下图T5 paper:
至于为什么bert那么有效?可以看上文NLP——预训练的发家史。
相对于以前的词嵌入,bert是会考虑上下文的。
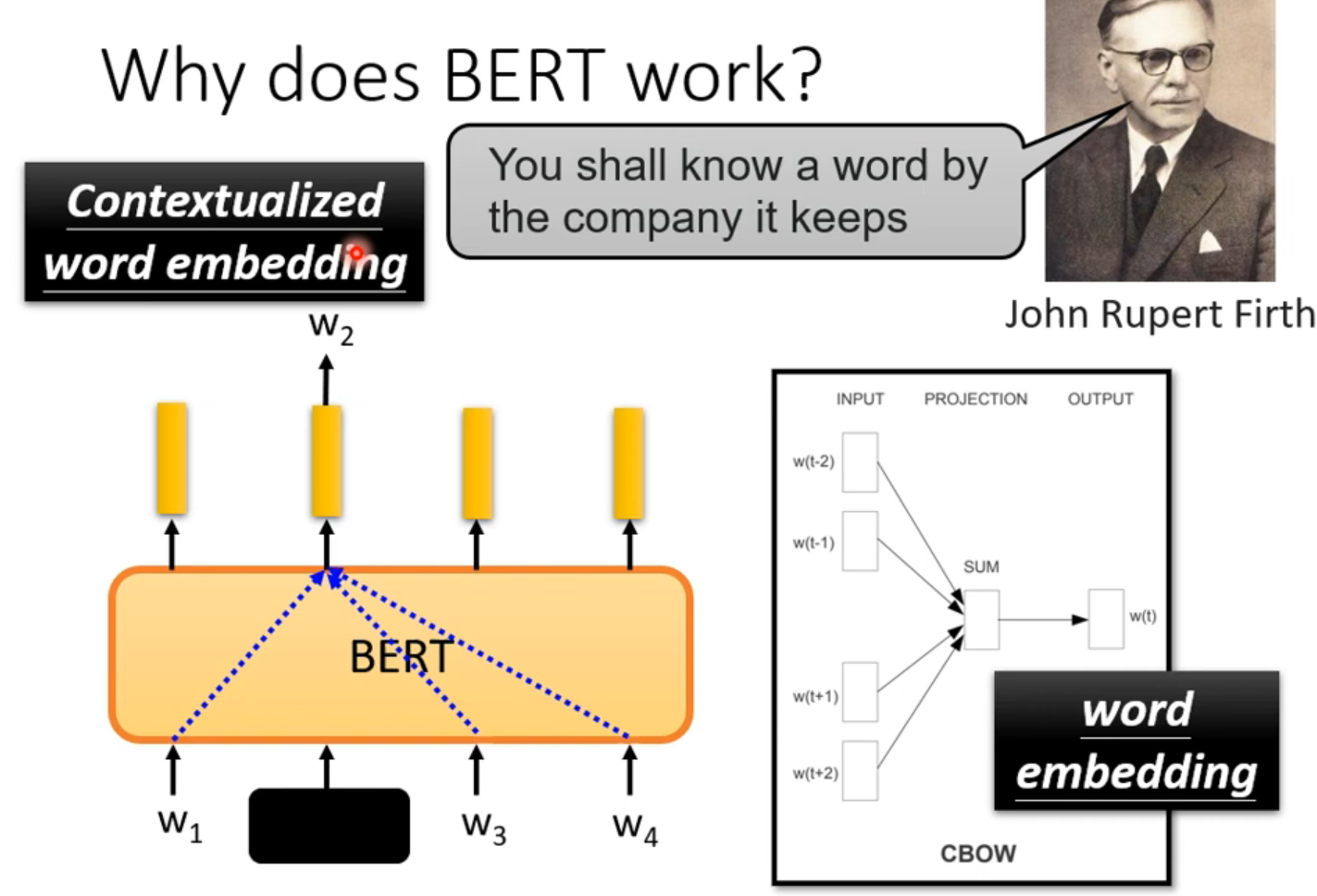
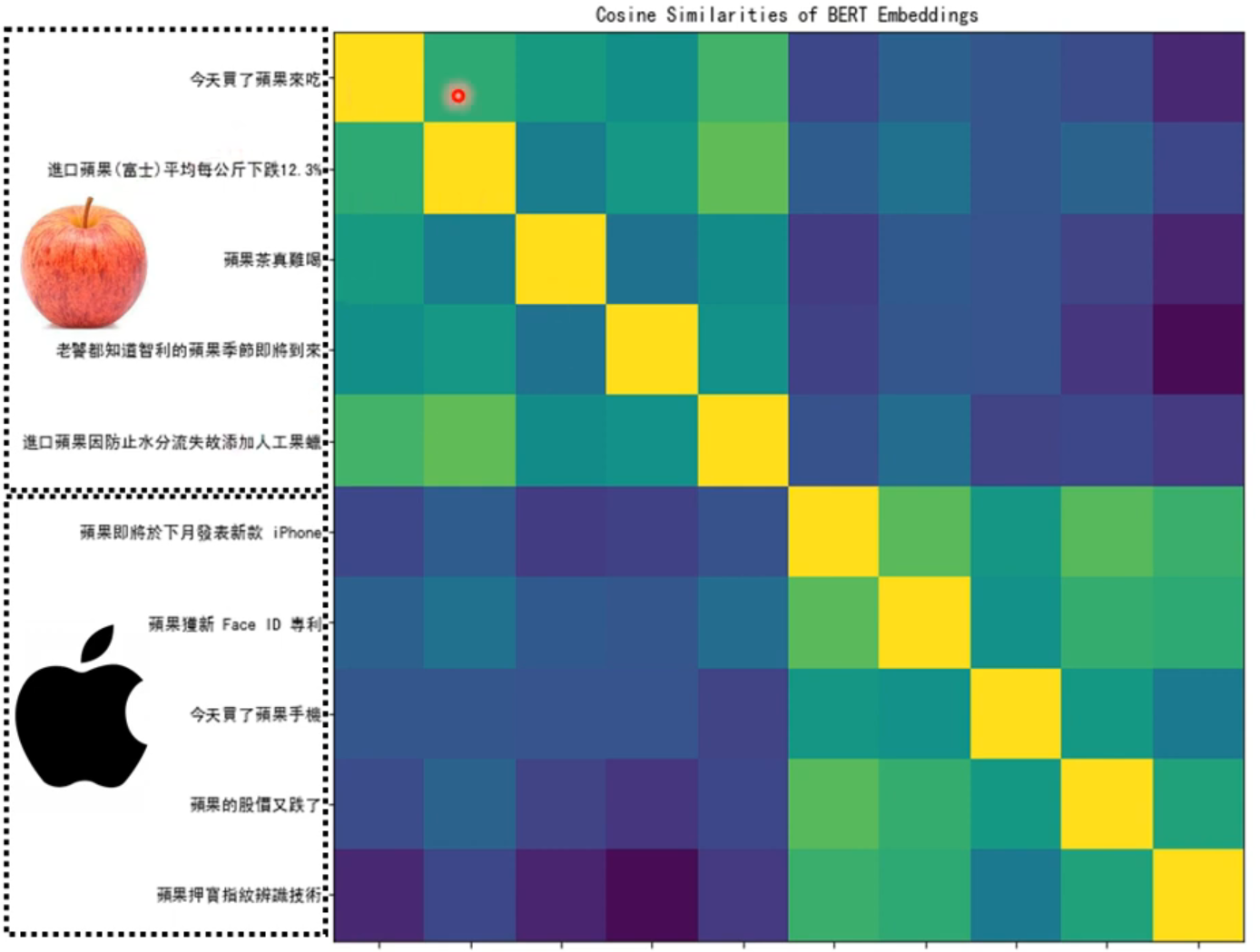
训练bert的过程(做填空题),可以看作是从上下文抽取资讯。
李宏毅:这是你在文献上查到的,但事实真的如此吗?
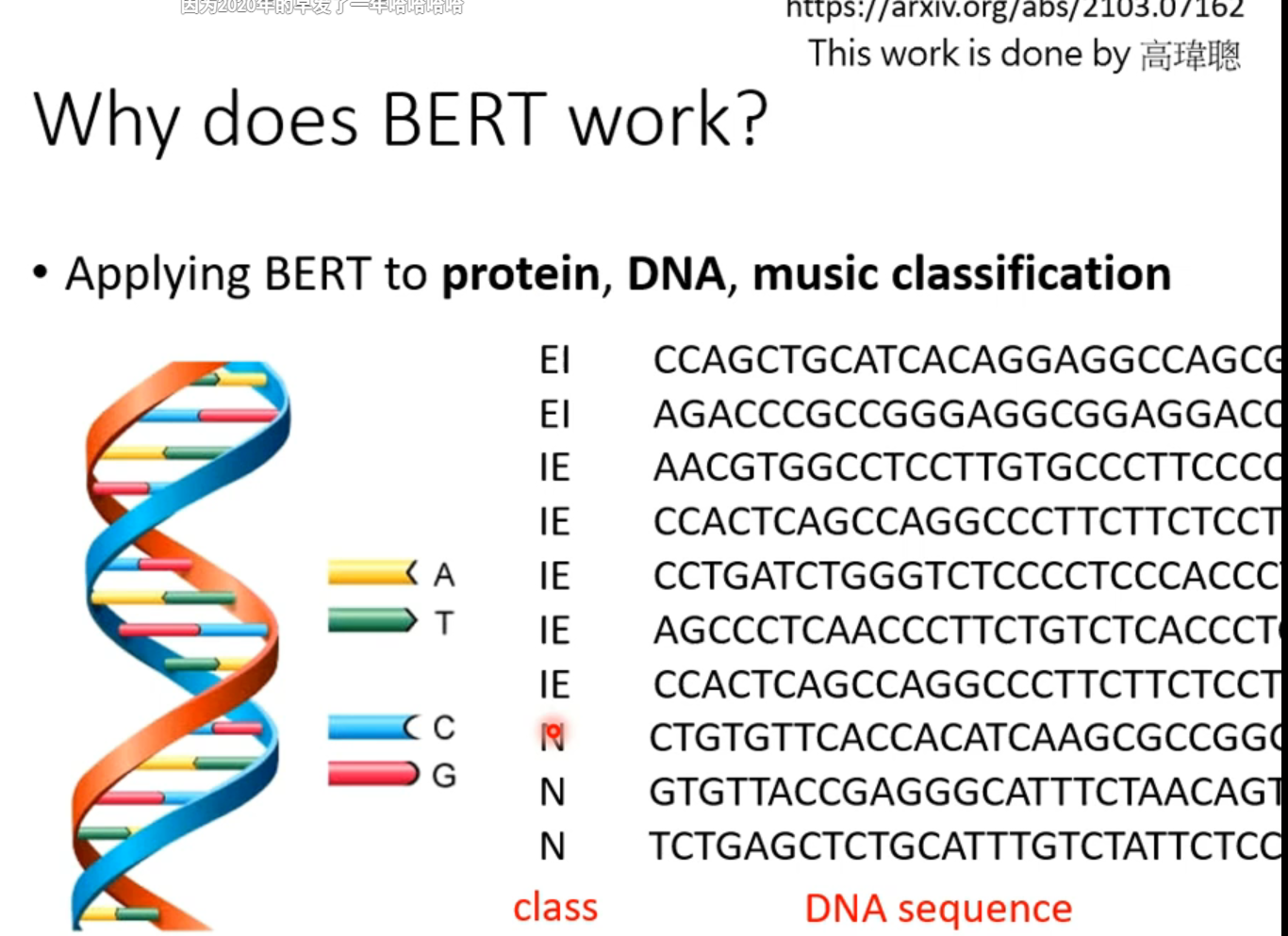
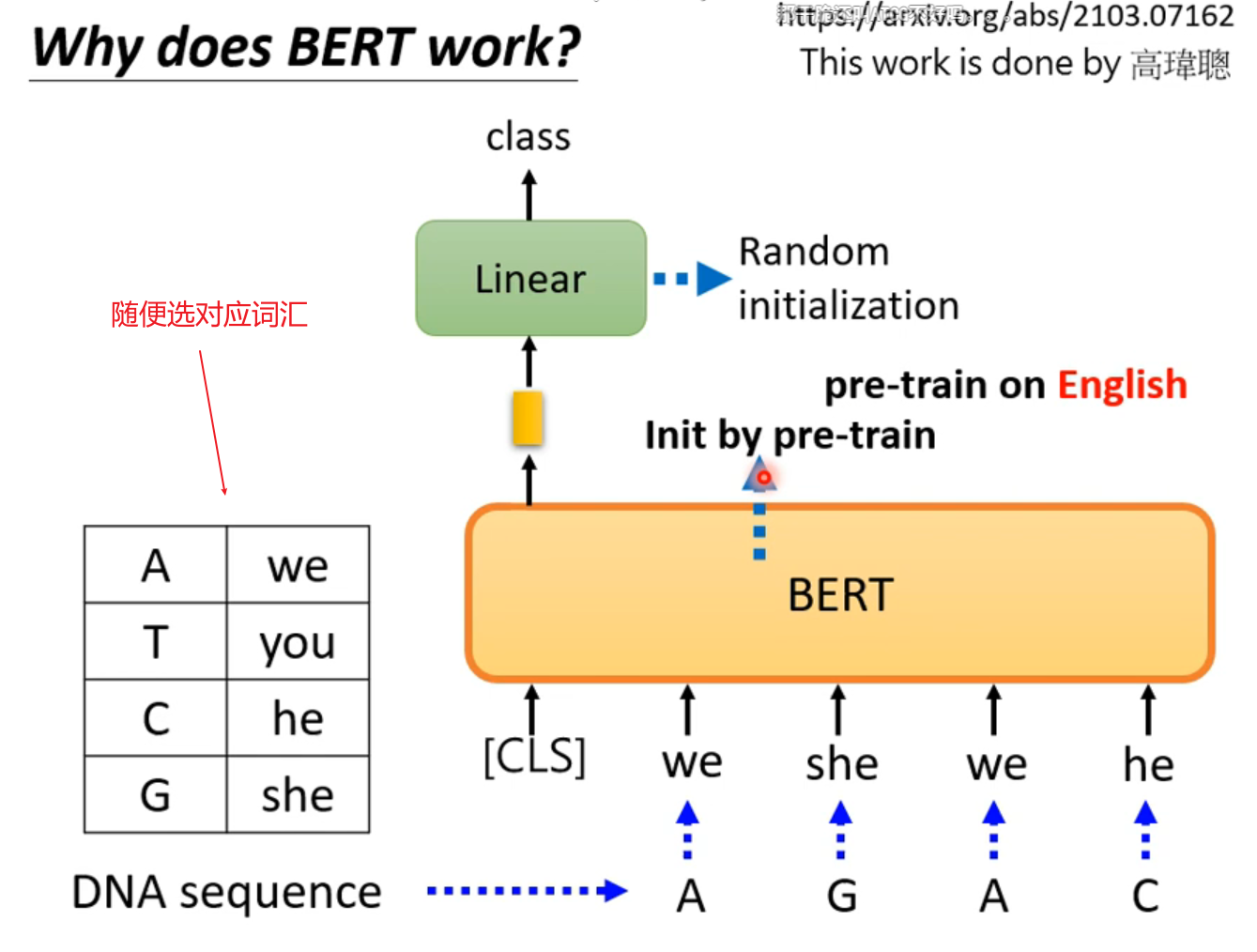

硬train一发,结果依然相当好,这告诉我们它的效果好可能不仅仅是因为“看得懂文章”,甚至可能bert本身就是比较好的初始化参数,适合做这些研究。
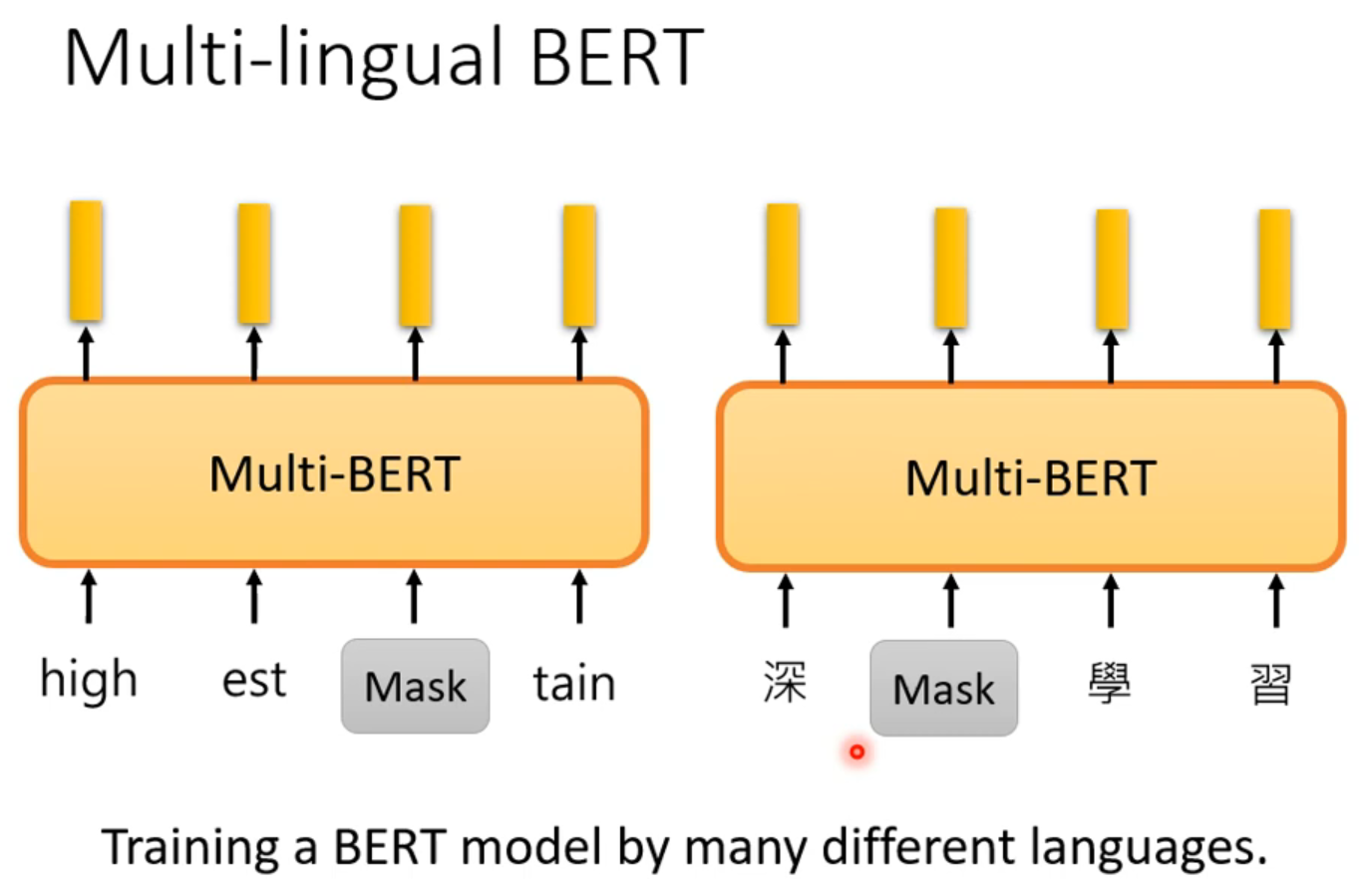
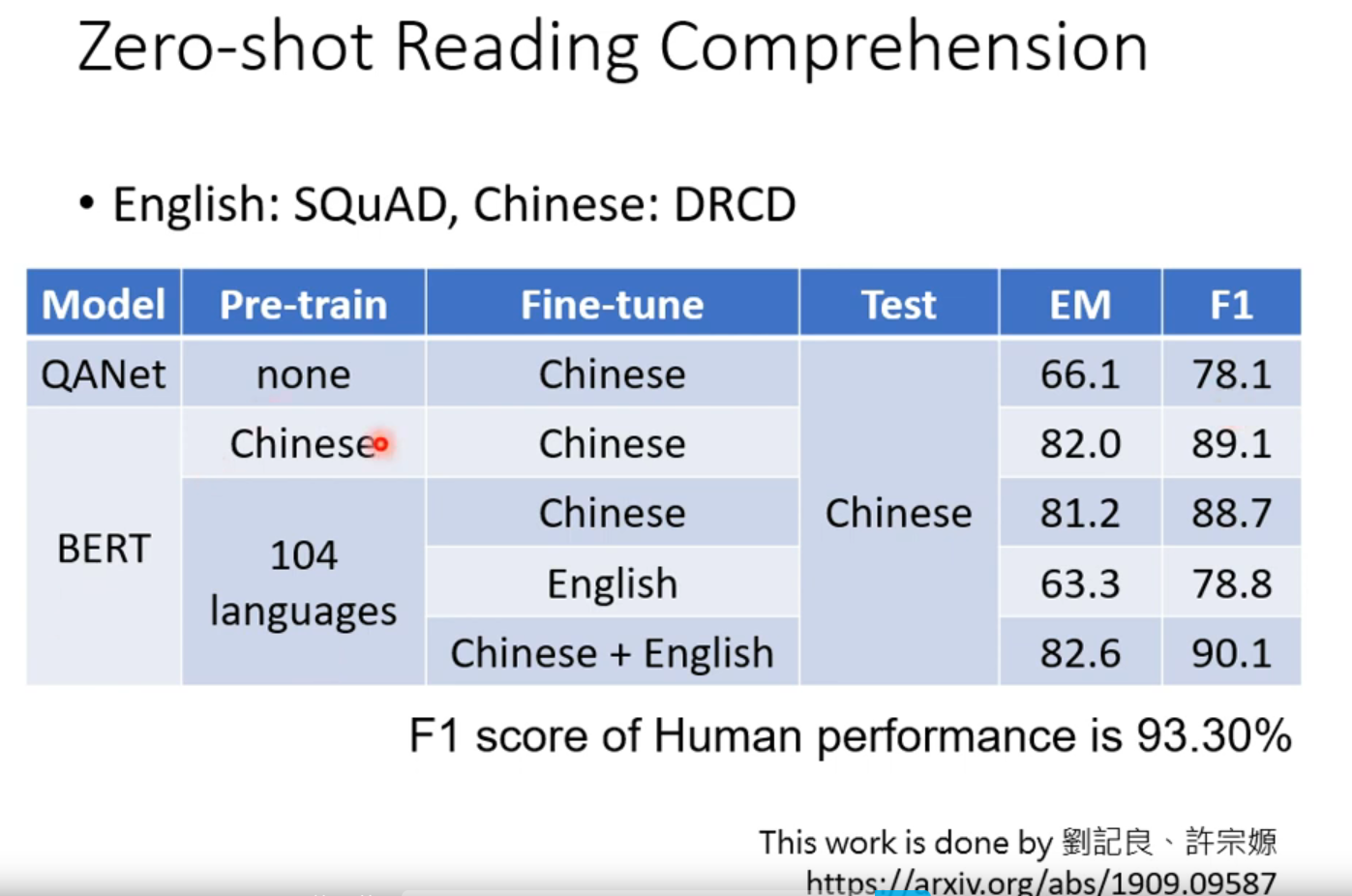
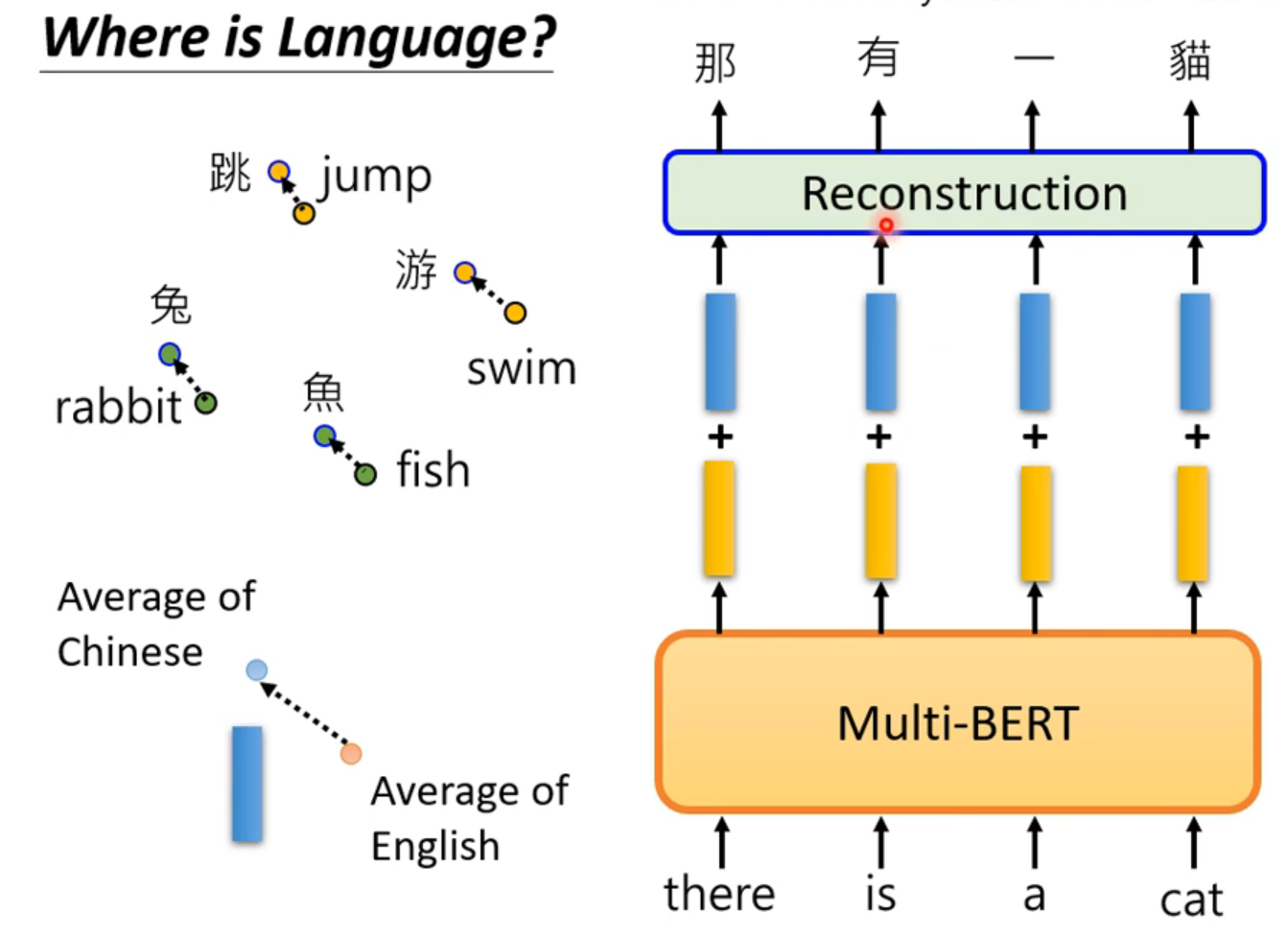
👆可以用多种语言来train 这个work用多语言pretrain,英文微调,直接上中文正确率依然有78.8%。
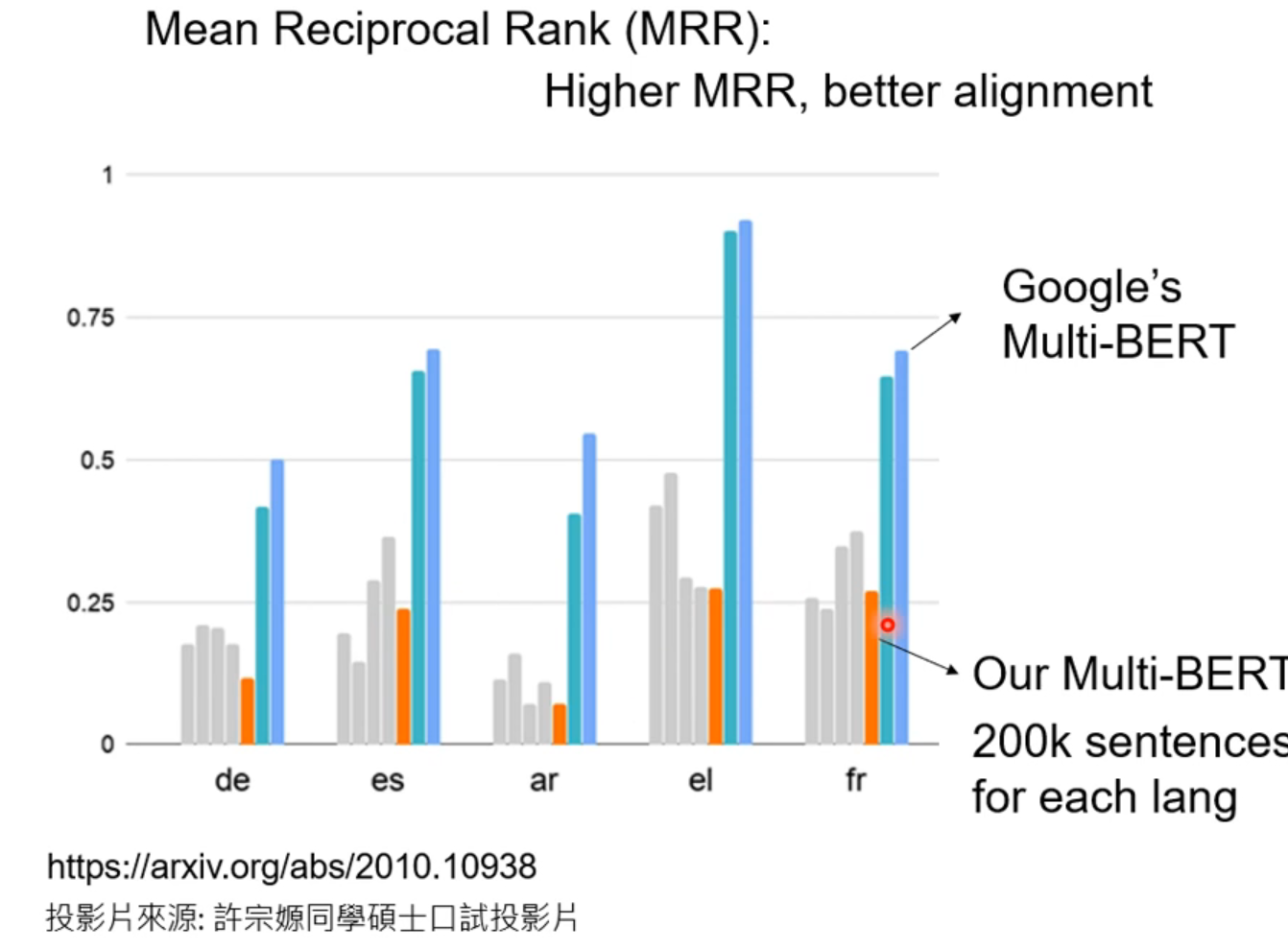
MRR衡量不同语言 同样意思的词汇接近程度。高代表模型能学到不同语言同样意思的符号。
还有李老师的经历:数据够多才出现了这样的现象,后来加多资料量成功了👇
但是肯定有语言的咨询,不然英文填空蹦几个中文不是逆天?那么,语言的咨询藏在哪?
卧槽,英文输入加上平均距离的差,multi-bert模型以为你输入的是对应的中文!所以语言资讯也藏在multi-bert里面
GPT
BERT做的事填空题,GPT做的是预测题,给他之前出现的,让他预测下一个出现的词是什么。很像transformer的decoder部分。可以把一句话补完,这一个小GPT例子:https://app.inferkit.com/demo
怎么use gpt呢,GPT可能太大了,fine-tune都有困难。
这个想法👇太nb了,但是目前看起来并没有做到太好