基础知识
ipython
Ctrl-D退出
tab自动补全神器
但是ipython默认隐藏了下划线开始的方法和属性,比如魔术方法,“私有”方法和属性,要先输入下划线才看得到
内省:变量名前后使用 ? 显示关于对象的概要信息(包括docstring)
??来显示函数的源代码
?的终极用途:搜索命名空间,比如np.*load*?
% file.py 运行文件中的代码,如果需要参数就加参数如果想让待运行的脚本使用ipython空间中有的变量,用%run -i filename.py
%paste 和 %cpaste (–终止)黏贴代码
一些终端指令:ctrl-L清屏 C+U删除当前行 ….
魔术命令
没有内建到python中去,调用示例:
a = np.random.randn(100,100)
%timeit np.dot(a,3)大部分魔术指令可以用?看到额外的选项
魔术函数在不冲突时可以不加百分号调用,%automagic 可以启用、禁用
一些魔术函数像python函数一样,输出可以赋给一个变量
a = %pwd
%quickref 快速参考卡
%magic 探索所有魔术命令
%debug从最后发生报错的底部进入交互式调试器 %pdb出现任意报错自动进入调试器
%hist
%paste %cpaste
%reset 清空所有变量/名称 %xdel variable 删除变量和相关引用
%page OBJECT 通过分页器更美观的打印一个对象
%run %prun statement 使用CProfile执行语句,报告输出
%time 报告单个语句执行时间 %timeit 多次运行单语句,计算平均执行时间,用于估算代码最短执行时间
%who %who_ls %whos 依次更加详细的展示变量jupyter
核心组件是 notebook 交互式的文档类型
python的jupyter内核使用ipython系统进行内部活动
集成matplotlib:
- 在ipython命令行中 %matplotlib
- 在jupyter中 %matplotlib inline
python
一切皆为对象,对象模型的一致性!!!
几乎所有的python对象都有内部函数,称为方法
python虽然没有显示声明类型,但却是强类型语言,比如’5’+5会报错,而不是像很多语言一样发生隐式转换
只有在特定,明显的情况下才会发生隐式转换比如float + int
tips: isinstance(a,(int,float))检查对象类型是否在右边的元组中
python。。。鸭子类型,不管具体类型,只要它拥有某个特殊的方法,就一定有某种属性
iter(x)检查可否迭代
if not isinstance(x,list) and isiterable(x):
x = list(x) 不是列表就转换为列表
None 是NoneType类型的唯一实例,如果函数没有显式返回值,那就返回None
三元表达式
x = 5
'a' if x == 5 else 'b'
'a'datetime
from datetime import datetime,date,time
dt = datetime('2021,5,1,21,8,30')
dt.year,month,day,hour,minute,second
dt.date()输出前三个
dt.time()输出后三个
dt.strftime('%x%x%x')
datetime.strptime('202151',"%Y%m%d")#转换为datetime对象
datetime相减会产生datetime.delta对象
delta = datetime2 - datetime1
delta == datetime.timedelta(99,7179) #间隔99天,7179秒
timedelta和datetime可以做加减得到新的datetime
%y 两位数的年份表示(00-99)
*%Y 四位数的年份表示(000-9999)
*%m 月份(01-12)
*%d 月内中的一天(0-31)
*%H 24小时制小时数(0-23)
*%I 12小时制小时数(01-12)
*%M 分钟数(00=59)
*%S 秒(00-59)
*%a 本地简化星期名称
*%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身数据结构
tuple
可以用tuple函数将任意序列或迭代器转换为元组,比如tuple(‘ab’)->(‘a’,’b’)
同样可以使用 + 来连接,可以使用 * 来组成大元组
嵌套元组拆包(为啥python不用临时变量的原因)
tup = 4,5,(6,7)
a,b,(c,d) = tupcollections有很多封装好的数据结构,比如collections.deque
他们适合不同的场景,拥有特定的操作和某些特性下的加速,比如deque是双端数列,头尾插入快
list的remove很方便,但是内存占用比较高,还有insert代价比append更高
与字典,集合相比,对列表使用in时非常缓慢
list.extent(元素)比起创建新列表再使用+来连接节省很多内存
bisect模块可用于排序好的序列(实现了二分搜索,已排序列表的插值)
import bisect
c = [1,2,2,2,3,4,7]
bisect.bisect(c,5) #5要插在哪
--6
bisect.insort(c,6)
c
[1,2,2,2,3,4,6,7]序列函数enumerate,zip,sorted,reversed
zip取决于最短的那一项,enumerate,zip,reversed都返回生成器
字典的keys values items 返回的是迭代器!
a.update({xxxxxx})可以合并字典,如果冲突,则原来的被覆盖
由于字典本质是2-元组(含有两个元素的元组)的集合,字典可以接受一个2-元组为参数
dictionary = dict(zip(range(5),reversed(range(5))))
value = dict.get(key,default_value),不加默认值就返回None,pop也可以,不过默认抛出异常
dict.setdefault(key, default=None)查找key,如果不存在就设置为default,可以用[]
by_letter = {}
for word in words:
letter = word[0]
by_letter.setdefault(letter,[]).append(word)
#设置首字母序列
#也可以直接from collections import defaultdict字典的键必须是不可变,它们将被哈希化,用hash(x)检查能否哈希化
为了将列表作为键,可以转换为元组,元组只要内部元素可以哈希化,它自身就可以哈希化
d = {}
d[tuple([1,1,1])] = 5
d
{(1,1,1) : 5} #...真的有必要把元组作为键吗#集合操作
a.add(x)
a.clear()#清空
a.remove(x)
a.pop()#移除任意元素,空的则抛出keyerror
a|b
a&b
a-b
a^b
#这几个都可以 a x= b
a.issubset(b) a包含于b则返回ture
a.issuperset(b) 如果a包含b返回true
a.isdisjoint(b) ab没有交集返回true
a.copy()用于赋值,免得指向同一个字典,集合都有推导式!推导式和map功能有些重复
#字典示范
dictionary = {val:index for index,val in enumerate(strings)}嵌套列表推导式的for顺序排列,要区别于列表推导式中的列表推导式
some_tuples = [(1,2,3),(4,5,6)]
flattend = [x for tuple in some_tuples for x in tuple]
flattend == [1,2,3,4,5,6]
[[x for x in tuple] for tup in some_tuples]
[[1,2,3],[4,5,6]]函数
global
返回多个值是以元组形式,甚至可以返回一个字典,啥都行
将函数作为参数传递,这种更函数化的编程有更强的复用性和通用性
def complex(a,ops):
for op in ops:
op(a)
operation = [str.title,str.strip]
complex('wocao',operation)
妙啊!lambda本身没有显式的__name__属性
柯里化
通过部分参数应用的方式从已有的函数里衍生出新的函数
from functools import partial
add five = partial(add_numbers,5)生成器表达式可以作为函数参数用于替代列表推导式
sum(x ** 2 for x in range(100))
itertools
适用于大多数数据算法的生成器集合
可以查一下手册,需要的时候
except(xx,xx)来结合多个异常
文件
read([size])
seek(pos)
tell()
#随机三件套
readlines([size])
write(str)
writelines(strings)
close
flush #将内部I/O缓冲区内容刷新到硬盘
closed
在文本模式下,f.read(10)#读取了10个字符所需要的字节并解码
而在二进制模式下,f.read(10)#读取了10个字节,并未解码,显示b'xxxx'
解码如果不完整,则会报错
文本模式配合open的encoding参数读取不同编码类型
with open(path,'xt',encoding = 'utf-8') as f:Numpy
数组和向量化计算
- 高校多维数组,提供数组算术操作和灵活的广播(不同尺寸数组)
- 线性代数,随机数,傅里叶变换
- 提供非常易用的C API,使得调用底层语言变得极其简单
- 诸多外部库都基于Numpy,这是数值计算最重要的python库
Numpy的方法比python方法快10-100倍,并且使用的内存也更少
核心特征ndarry 快速,灵活的大型数据集容器,允许使用类似标量的操作语法在整块数据上进行数学计算
生成
array(列表,元组,数组)
asarray()将输入转换为ndarray??
arrange
ones/zeros/empty/full+/_like
eye/identitydtype
能和吉他系统数据灵活交互的原因
dtype和astype(new type)方法
转换时小数->整数截断,string转换为合适的,
但在用numpy.string_作数据时,numpy会修正大小或删除输入而不发出警告
数组算术
所谓向量化运算,逐元素操作。
索引
ndarray可以用”切片”赋值b[1:4] = 5把b的2-4号元素都赋值5
ndarray的切片事原数组的视图,而不是复制!!!不然得多慢,要想复制得:arr[5:8].copy()
高维索引:可以arr2d[2][1] 也可以arr2d[2,1]
切片配合索引可以很好的进行切片,全选用单独 :
布尔索引
names是一个字符串ndarray
names == 'Bob'
array([True,False,False],dtype = bool)#输出一个布尔值数组
可以将布尔数组当作数组的索引,但是其长度必须和数组轴索引长度一致,不一致时不会报错,要小心
date = np.random.randn(7,4)
date[date<0] = 0 #好厉害的功能布尔索引也能配合切片使用
布尔索引总是生成数据的拷贝
~()表示对某个通用条件取反
神奇索引
真的很神奇。。使用整数数组进行数据索引(Numpy专用)
相当于是一维一维的选择数据,也可以把每个数组的对应位置组合起来看成索引
神奇索引的结果总是一维的,他也总是复制数据到新的数组中
假设arr是二维数组
arr[:,[2,1,0]] 相当于是把前三列倒过来再复制出来,很奇怪的用法
换轴:arr3d.transpose((1,0,2)) 换了轴的次序,有点抽象
arr.swapaxes(1,2)交换俩轴,返回视图而不是复制
通用函数
快速的逐元素数组函数
一元
abs/fabs
sqrt
square
exp
log log10 log2 log1p()#返回ln(1+x)
sign #返回符号值,正数1,0为0,负数-1
ceil floor
rint #保留整数,保持dtype
modf #分别返回小数部分和整数部分
isnan #返回布尔数组
isfinite #既非inf又非NaN
isinf
cos,cosh,sin,sinh,tan,tanh
arc*6
logical_not()#按位取反二元
add subtract multiply divide/floor_divide
power(x,y)#每项依次xi ** yi
maximum/minimum/fmax/fmin #后两个忽略NaN
mod()#模
copysign #将第一个数组的符号值改为第二个数组的符号值
greater.....不如直接用操作符数学和统计
用数组表达式完成多种数据操作任务,代替显式循环,称为向量化,速度会快很多
np.where(布尔数组,标量/向量,标量/向量)是向量界的三元表达式
sum(array,axis = )
mean
std,var 标准差/方差 ,可以选择自由度调整
min max
argmin argmax 最小值和最大值的位置#axis可以省略,直接写维度
cumsum cumprod 累和 和 累积 有中间结果#
sort布尔数组妙用
arr = np.random.randn(100)
(arr>0).sum()正值的个数
还有bools.any()检查是否至少一个true
bools.all()检查是否每个值都是True,里面可能放轴
唯一值与其他集合逻辑
有一些针对一维ndarray的基础集合操作
unique(array)#对唯一值排序
intersect1d(x,y)交集
union1d(x,y)并集
in1d(x,y)x项是否在y中,返回布尔数组
setdiff1d(x,y)返回x-y
setxor1d(x,y)返回x^y 不共有的文件
numpy可以将数据以文本/二进制文件形式存入硬盘或载入,pandas或其他来载入文本/表格更被人们推崇
#默认后缀是.npy
arr = np.arange(10)
np.save('Iamfile',arr)
np.load('Iamfile.npy')
#多个就是
np.savez('Iammanyfile',a = arr, b = arr)
#load以后变成一个字典对象
arch = np.load('Iammanyfile.npy')
arch['b'] == array([0,1,2,3,4,5,6,7,8,9])
#如果数据已经压缩好了,仍能存入压缩的文件
np.savez_compressed('small.npz',a = arr, b = arr)点乘
a.dot(b)
np.dot(a,b)
a @ b
linalg
顾名思义,numpy.linalg 拥有一个矩阵分解的标准函数集,以及其他常用函数比如求逆/行列式
这都是通过在MATLAB和R等其他语言使用的行业标准线性代数库实现的。
from numpy.linalg import inv,qr
diag()#返回方针的对角元一维数组,一维数组就准换为对角矩阵
dot
trace #考考你“迹”
det
eig #方阵特征值和特征向量
inv 逆矩阵
pinv Moore-Penrose伪逆
qr QR分解
svd 奇异值分解
solve 求解x的线性系统Ax = b,其中A是方阵
lstsq 计算Ax = b的最小二乘解伪随机数生成
np.random.seed(1234)这个设置的是全局随机数种子
rng = np.random.RandomState(123)
arr = rng.randn(10) #这样生成的就是独立的
seed
permutation(arr) # 返回一个序列的随机排列
shuffle # 随机排列一个序列,直接更改原来的
rand #从均匀分布[0,1)中抽取样本
randint #根据给定的从低到高的范围抽取随机一个整数
randn #从均值0方差1的正态分布
normal(x1,x2,(shape))#平均值,标准差,shape
binomial #从二项分布中抽取样本
beta #从beta分布中抽取样本
chisquare #从卡方分布中抽取样本
uniform(x1,x2,(shape)) #从均匀分布中抽取样本
gamma #从伽马分布中抽取样本随机漫步
Pandas
numpy像序列化好的矩阵,序列,pandas相当于是字典(有名称的数据)
numpy适合处理同质型的数值类数组数据
pandas用来处理表格型或异质性数据
Series
一维的数组型对象,包含一个值序列(类似numpy),和数据标签(索引 index)
默认索引0 - N-1 ,用values和index得到其值和索引
比numpy数组特殊的是可以用标签来索引:
In [5]: obj2.index
Out[5]: Index(['d', 's', 'c', 'a'], dtype='object')
In [6]: obj2.values
Out[6]: array([ 4, 7, -5, 3], dtype=int64)
In [8]: obj2[['d','s']]
Out[8]:
d 4
s 7
dtype: int64可以考虑它是一个长度固定且有序的字典,在可以使用字典的上下文中Series都能用
使用numpy的函数或按numpy风格的操作,比如布尔数组索引,数学函数,都能用,且保存索引值链接
还能把字典变成Series pd.Series(dict)
obj3 = pd.Series(list1,[index = list])如果list里没有,则被舍弃,如果list里有没对上的,就NaN
Pandas用 isnull 和 notnull检查数据,也返回类似布尔值Series的东东
自动对齐索引是非常有用的
Series对象自身和其索引都有name属性
In [10]: obj2.name = 'population'
In [11]: obj2.index.name = 'state'
In [12]: obj2
Out[12]:
state
d 4
s 7
c -5
a 3
Name: population, dtype: int64索引可以通过按位置赋值的方式进行改变 obj.index = [new list]
DataFrame
表示矩阵的数据表,它包含已排序的列集合,每一列可以是不同的值类型(数值,字符串,布尔值等),DataFrame既有行索引,又有列索引
在DataFrame中数据被存储为一个以上的二维块。
可以利用分层索引在DataFrame中展现更高层次的维度。
构建
利用包含等长度列表或numpy数组的字典
在jupyter notebook里面dataframe对象会展示一个更好康的HTML表格
data = {'a':[],"b":[],"c":[]}
frame = pd.DataFrame(data)
frame2 = pd.DataFrame(data,columns = ['b','a','c'],index = ['first','second','third'])
colunmns指定列的顺序,索引指定索引。。如果columns里出现data没有的列,则填充缺失值NaNframe2[‘a’] == frame2.a 这是一个Series对象,frame2.a只在a是有效变量名时可用,前者则总可用
也可以用这个更改一列👆,用列表/数组赋值时请确保长度匹配,
将Series付给一列时,索引会尝试匹配,空缺补缺失值,如果a(被赋值的列)不存在,会产生新列(此时不能用frame2.a的语法!!),可以用del关键词来删除dataframe的列
返回的Series对象索引继承dataframe的,而且name属性被设置成字典的索引
从DateFrame中选的列同样是数据的视图,拷贝得用.copy()
另一种常用的数据形式是包含字典的嵌套字典:
pandas会将字典的键作为列,将内部字典的键作为行索引,自动补全NaN
可以用Numpy语法转置 frame3.T
内部字典的键会被联合,排序,但是如果显式指明索引,键不会被排列
frame3.index.name 和 frame3.columns.name 也是可以设置的
如果列是不同的dtypes,那么values的dtype会自动选择适合所有列的类型
基本功能
reindex([]) 创建一个符合新索引的新对象
In [7]: obj3 = pd.Series(['blue','yellow','green'],index=[0,2,4])
In [8]: obj3
Out[8]:
0 blue
2 yellow
4 green
dtype: object
In [9]: obj3.reindex(range(6),method = 'ffill')
Out[9]:
0 blue
1 blue
2 yellow
3 yellow
4 green
5 green
dtype: object
#ffill会将值向前传递reindex方法的参数
index #作为默认参数,可以省略
columns = xx #此关键字用于重建列的索引
ps:可以用frame.loc[[行索引],[列索引]]
method #ffill前向,bfiil后向填充
fill_value #选择缺失时使用的替代值
limit #前后填充时,填充的最大元素数量
tolerance #前后填充时,填充的最大绝对数字距离
copy #True时总是复制底层数据,False在索引相同时不复制数据删除
data.drop([xxx])删除索引,默认是轴9
data.drop([xxx],axis = 1) #也可以写axis = ‘columns’ 只删除一个的就不用列表
像drop这类函数会修改Series或DataFrame的尺寸或形状,直接操作原对象,不返回新对象
索引对象
不可变的,用obj.index拿出来,构造Series和DataFrame时,内部产生索引对象
可以用pd.Index([list])显式生成
它具备集合的特征,比如使用 in方法
但是它可以包含重复标签,根据重复标签筛选会选取所有匹配的
append()
difference
intersection
union
isin
delete(i)#删除位置i的索引并产生新的索引
drop('xx')#删除xx索引并产生新的索引,可以传递列表来删除多个
insert(i)
is_monotonic #是否递增
is_unique #是否唯一
unique #得到索引的唯一值序列Series 既可以使用obj[2:4]这样传统的顺序,也可以使用obj[[‘b’,’c’]]用索引里截取的列表来
甚至可以obj[‘b’:’c’] 而且这个是包含尾部的,series只有一列,这些都是选择行
对dataFrame可以直接用obj[‘two’]来索引某一列或用一个列表来选择!这是列选择语法
但是切片语法obj[2:4]时选择行的(这才是特殊的),传入单个/列表只能选择列!!!
loc和iloc选择(更准确,更无歧义)
date.loc [[],[]] 前者选择行,后者选择列,必须是索引名
date.iloc [ xxx ]就只能用数字索引
当用列表时形式和原来相仿,当选了某一个行时,会发生转置
In [16]: data
Out[16]:
one two three four
OHIO 0 1 2 3
COLORADO 4 5 6 7
UTAH 8 9 10 11
NEWYORK 12 13 14 15
In [17]: data.loc['OHIO',['one','three']]
Out[17]:
one 0
three 2
Name: OHIO, dtype: int32
In [21]: data.iloc[0,[2,1]]
Out[21]:
three 2
two 1
Name: OHIO, dtype: int32这两种方法是可以使用切片的
df[val] 选择单列或列序列,特殊是数字切片选择行
df.loc[val] 选择行
df.loc[:,val] 选择列
df.loc[val1,val2]选择某部分
df.iloc同理
df.ai[label_i,label_j]根据索引选择单个标量
df.iat[i,j]根据位置选择单个标量
get_valueps:当对标签使用切片时是包含尾部的,比如loc里面和series的标签切片,即使有时候标签就是数字
算数和数据对齐
相加对象时,当索引对不同,返回结果的索引将时索引对的并集,没有交叠的部分全都变成NaN
灵活算术方法
add,radd
sub,rsub
div,rdiv
floordiv,rfloordiv
mul,rmul
pow,rpow
参数fill_value设定了以后有必要会保留两边的,带r的都是参数翻转DataFrame和Series间的操作
类似不同维度数组间的操作类似
当arr(np数组)减去一行时,减法依次在每一行进行了操作,这就是所谓的广播机制
二DataFrame和Series之间的操作是类似的,Series的索引和DataFrame的列进行匹配,然后广播到各行
如果索引值不在DataFrame的列中,也不在Series的索引中,对象会重建索引并进行联合。补NaN
如果想在行上匹配,列上广播,必须得用算术方法,然后指定参数axis = ‘index’或axis = 0
Numpy的通用函数们可以直接使用到pandas对象进行逐元素操作
DataFrame的apply方法可以将函数应用到一列或一行上,默认是对每一列调用一次,
用axis = ‘columns’ 或 1来对行调用,索引仍保留对应的,但大部分常用的功能都已经实现了
applymap就是对每个元素使用!
先到这吧
文件
有一大坨,我挑了几个
read_csv 从文件,url,文件型对象读取分隔好的数据,逗号是默认分隔符
read_table从文件,url,文件型对象读取分隔好的数据,制表符是默认分隔符
read_fwf 从特定宽度格式的文件中读取数据(无分隔符)
read_excel
read_html
read_json由于现实世界的数据非常混乱,随着时间推移,一些数据加载函数的可选参数变得非常复杂,pandas的在线文档中有大量实例展示,可以借鉴
一些参数
path
sep/delimiter 分隔符,可以是正则表达式
header 用作列名的行号
index_col 用作行索引的列好/列名
names 列名列表,必须header = None
............Matplotlib
如果不是用了%matplot notebook/inline,就得用plt.
最终目标可能是构建网络交互式可视化
matplotlib用来制作静态或动态的可视化文件,生成出版级质量图表(一般二维)
matplotlib支持所有操作系统上的各种GUI后端,还可以导出为常见的矢量和光栅图形格式!
现在有了一些matplotlib数据可视化的附加工具包,(调用matplotlib进行底层绘图)比如seaborn
尽管seaborn等库和pandas内建的绘图函数可以处理大部分绘图的普通细节,但是要更好的定制,必须得学习一些maplotlib的API
导入惯例
import matplotlib.pyplot as plt
首先在jupyter notebook 来一句 %matplotlib notebook(Ipython则是%matplotlib)
图片
这些图位于图片(Figure)对象中,可以使用plt.figure()生成一个新的图片
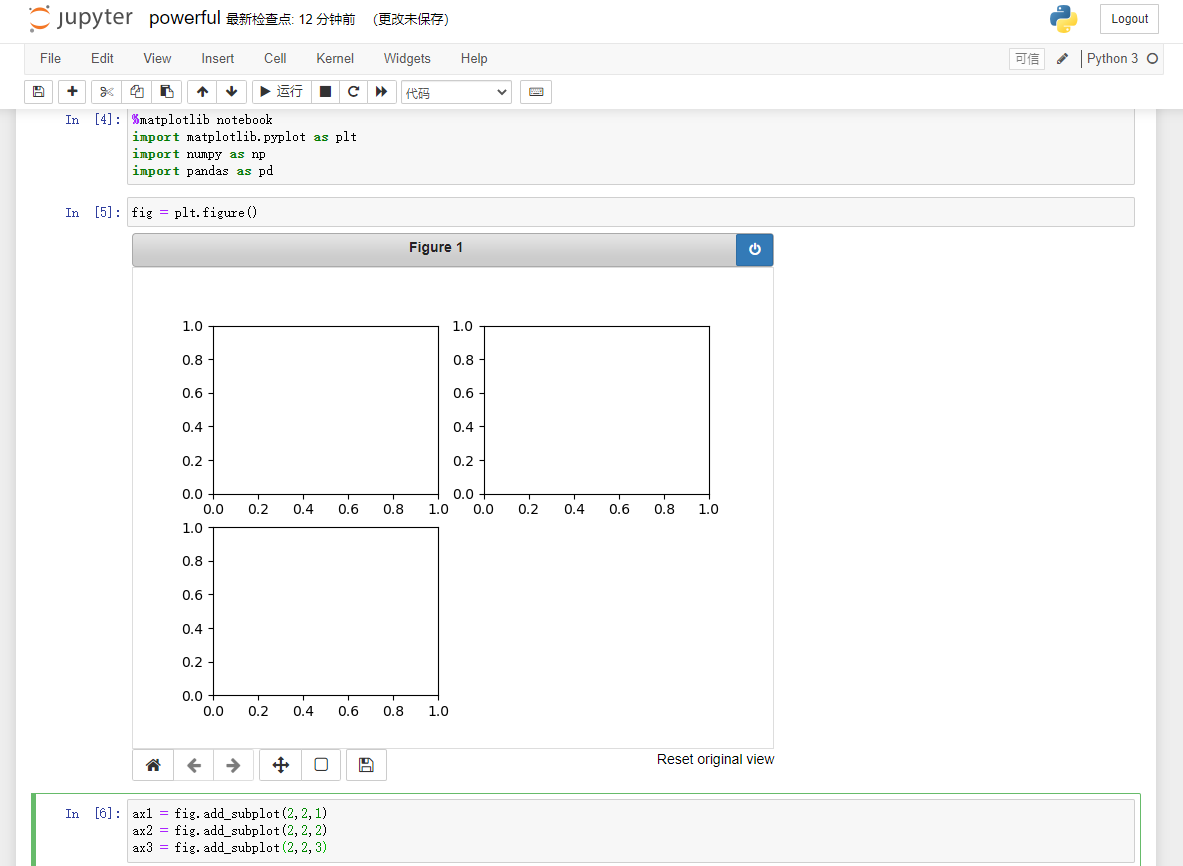
Jupyter好像优化了,不仅可以提前显示,而且在后续单元格执行时不会重置图表
当再绘图时,会在最后一个子图上画画
fig.add_subplot返回的是Axes Subplot对象,可以调用这些对象绘图
可以去matplotlib官方文档找完整的图形类型
使用子图网格创建图片时非常常见的任务,所以有一个方法plt.subplots(size),返回包含了已生成的子图对象的Numpy数组
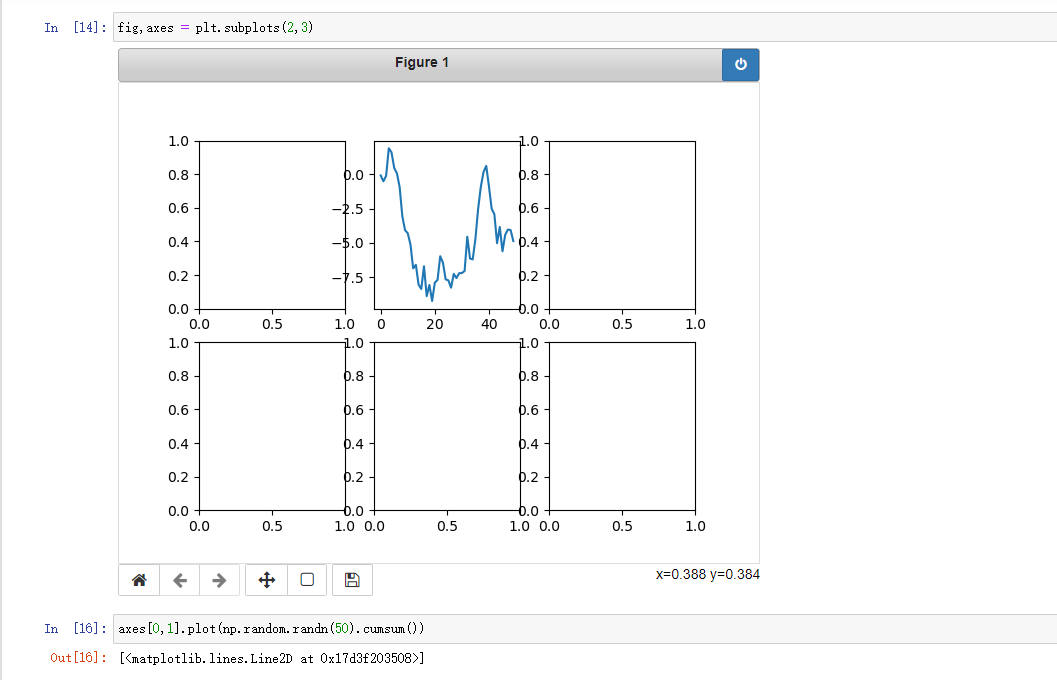
牛批啊,fig是一个尺寸对象Figure,axes则是返回的numpy数组

有几个参数,sharex(True/all False/None) sharey
subplot_kw:可选的,字典类型。包含传递给用于创建子图的调用add_subplot的关键字参数。
gridspec_kw:可选的,字典类型。包含传递给用于创建子图网格的GridSpec构造函数的关键字参数。
**fig_kw:所有传递给matplotlib.pyplot.figure调用的额外关键字参数。
比如plt.subplots(2,2,figsize = (8,6)最后一项传入figure对象
配置
https://blog.csdn.net/htuhxf/article/details/82863630
https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html
可以用图对象的subplots_adjust方法,或者当作顶层函数用,调整间距
fig.subplots_adjust(left,bottom,right,top,wspace,hspace)
很多配置字符串可以合到一起,也可以分开来使得表达清晰
ax.plot(x,y,'ko--')
等价于
ax.plot(x,y,color ='k',linestyle = 'dashed',marker = 'o')大多数图表修饰工作有两种主要的方式:程序性的pyplot接口或更多面向对象的原生matplotlib API
pyplot接口设计为交互式使用,包含xlim,xticks,xticklabels方法,他们在没有函数参数时返回当前参数值,在传入参数时设置参数值,他们默认在当前活动或最新创建的AxeSubplot上生效。他们分别对应于子图的两个方法,比如xlim对应于ax.get_lim和ax.set_lim,后者更为显式,单独操作子图
#实例
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(np.random.randn(1000).cumsum())
ticks = ax.set_xticks([0,250,500,750,1000])#设置刻度
labels = ax.set_xticklabels(['one','two','three','four','five'],rotation = 30,fontsize = 'small')#设置标签
ax.set_title('My first matplotlib plot')
ax.set_xlabel('Stages')
#也可以这样设置
props={
'title': 'My first matplotlib plot',
'xlabel':'Stages'
}
ax.set(**props)#通用的一种方法
print(ticks)
print(labels)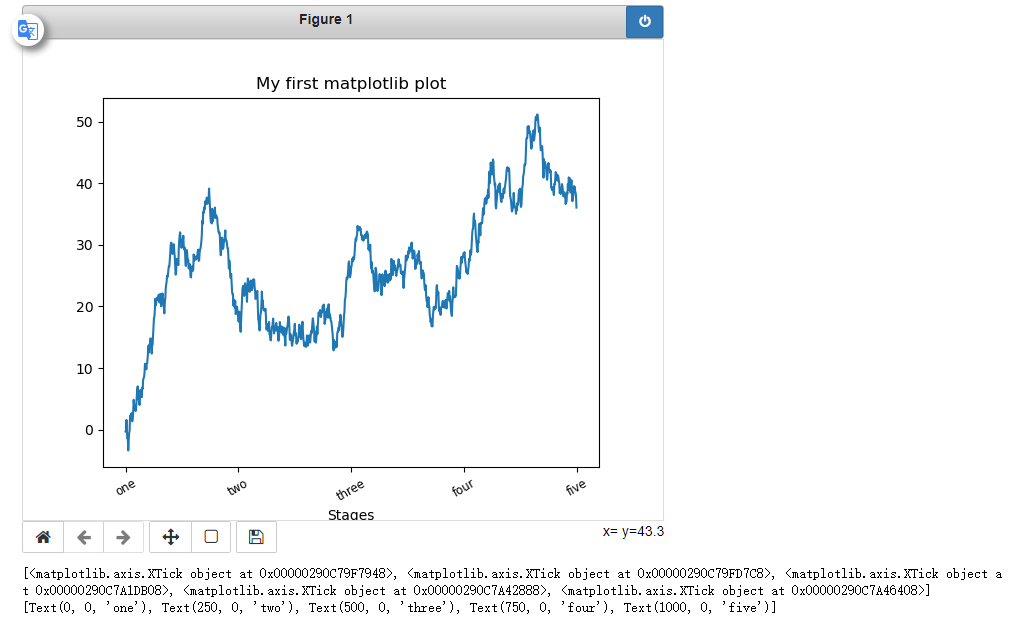
添加图例
最简单的式在添加图表的时候ax.plot(加一个参数label = ‘xx’)
再执行ax.lengend(loc =’xx’)或者plt.legend就能自动生成图例,best会找到最合适的位置
好文章:
注释与子图加工
text,arrow,annote方法可以添加注释和文本
比如:ax.text(x,y,’Hello world!’,family = ‘monospace’,fontsize = 10)
matplotlib含有表示多种常见图形的对象,这些对象的引用时patched。
全集位于matplotlib.patched中,少部分比如Rectangle和Circle可以在matplotlib.pyplot中找到
这个暂时用不到。。先略过吧
保存到文件
使用plt.savefig将活动图片保存到文件,等价于图片对象的savefig实例方法
plt.savefig( ‘ xxx . svg’)文件类型会从文件拓展名自动推断
其他的参数/选项:
fname #默认参数,是一个路径+文件型对象名
dpi #每英寸点数的分辨率,默认100
facecolor,edgecolor #图形背景的颜色,默认是'w'就是白色
format #文件格式,比如'png','pdf',svg,ps,eps啥的,好像时可以覆盖
bbox_inched #要保存的图片范围,如果是'tight',将会去掉图片周围空白的部分matplotlib配置
几乎所有的默认行为都可以通过广泛的全局参数来定制,者通过plt.rc来实现
#第一个参数时要自定义的组件,比如'figure',axes,xtick,ytick,grid,legend
然后其他的就可以自定义了,比如:
font_options = {
'family' : 'monospace',
'weight' : 'bold',
'size' : '5'
}
plt.rc('font', **font_options)使用pandas和seaborn绘图
pandas有很多内建的方法简化dataframe和series对象生成可视化的过程,另一个库时seaborn
导入seaborn会修改默认的matplot配色方案和绘图央视
Series.plot的参数
label
ax 选用的子图对象,默认是当前活动的
style
alpha
kind 默认'line'
logy #在y上使用对数缩放
use_index 使用对象索引刻度标签(默认x,水平图则是y)
rot
xticks
yticks
xlim
ylim
grid #展示轴网格,默认打开DataFrame的plot参数
subplots #将每一列绘制在独立的子图中
sharex/sharey #当独立子图时可以设置的
figsize 生成图片尺寸的元组
title 标题字符串
legend 添加子图图例,默认是True
sort_columns 按字母顺序绘制各列,默认为False折线图
会把Series索引默认当作x轴
DataFrame默认划到一起去,可以设置
注意到DataFrame的列名称(column.name)成为了图例标题
柱状图
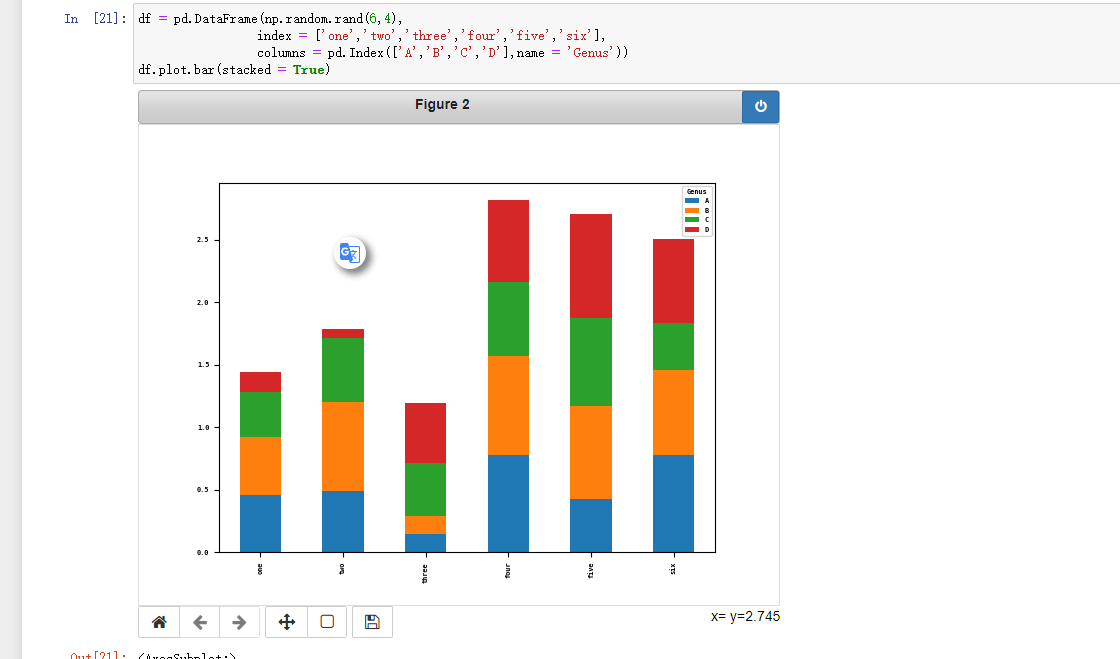
plot.bar() 竖直 plot.barh()水平柱状图,同样索引默认当作x轴、y轴
注意到DataFrame的列名称(column.name)成为了图例标题
stackedd = True 参数可以让DataFrame每一行的值叠在一起
直方图和密度图
hist和density