【如今,工程远远走在了理论的前面,但迟早会有一天有人提出新的理论框架来解释它】
https://zh-v2.d2l.ai/chapter_attention-mechanisms/index.html
https://d2l.ai/chapter_natural-language-processing-pretraining/index.html
前言
Welcome!

机器学习更关心计算,统计学习更关心模型。深度学习比机器学习更加计算。
李沐说大企业主要分这三类:
领域专家了解一些机器学习,但更看重怎么用模型辅助自己的专业知识。
数据科学家关注怎么处理数据成模型可用的数据(特征工程),还有构造模型,把领域专家的认知翻译成机器学习的任务。
数据科学家vsAI:数据科学家俩条路,一个是研究很多领域,研究怎么得到模型;深的走就是成为领域研究很深的人,即AI专家
可解释性略谈:人是不是可理解这个模型;它为什么工作;什么时候不工作;怎样会出现偏差之类的。
深度学习的一个关键优势是它不仅取代了传统学习管道末端的浅层模型,而且还取代了劳动密集型的特征工程过程。
此外,通过取代大部分特定领域的预处理,深度学习消除了以前分隔计算机视觉、语音识别、自然语言处理、医学信息学和其他应用领域的许多界限,为解决各种问题提供了一套统一的工具。
调参术
原则:首先保证你的模型足够大,参数够多,保证了有前途,再通过各种手段降低模型容量避免过拟合。
李沐:实际中调参其实没有那么重要,不建议过度调参,这可能会overfit到目前的数据,实际场景中你可能会有越来越多的数据。(除非竞赛)
较少的过拟合可能表明现有数据可以支撑一个更强大的模型, 较大的过拟合可能意味着我们可以通过正则化技术来获益。
当你调到一个比较好的参数点时,可以上下修改一下,如果结果剧烈波动,可能就调在了噪音上,泛化性不好。
少量高质量数据,可能有个百倍的换算。
通常来说准确率还是个比较主观的东西,你也不能知道你收集这个数据能达到多高准确,只要用户用的好。 用户心理可能有个阈值,低于它,体验就会很差,高过它,够用就行了。
选模型可以参考:https://cv.gluon.ai/model_zoo/detection.html 选择性能比较合适的,每个领域都有一些模型。
选损失函数:通过研究函数形状、梯度形状,尤其离原点远近对比来分析损失函数特性
交叉熵是一个衡量两个概率分布之间差异的很好的度量,它测量给定模型编码数据所需的比特数。
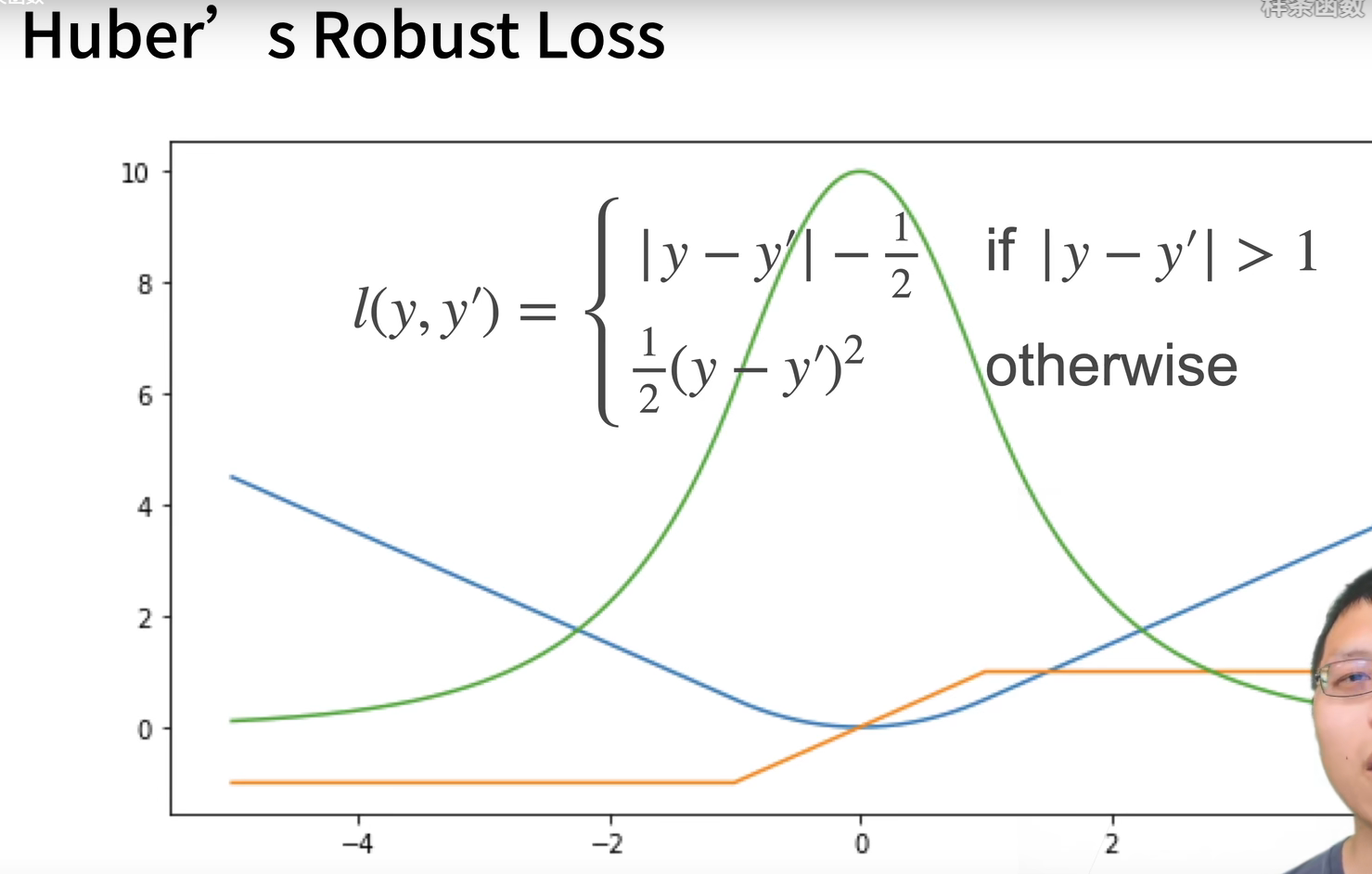
绿:似然函数 蓝:损失函数 橙:导数
Huber结合了L1和L2范数,既不会在数值较大处使得梯度过大,也不会在较小处产生不稳定的突变。
全连接最好是慢慢的减少每层的大小,压小会损失信息,但有时候先压小一些再扩张可以deal with overfitting【靠手感哈哈】
激活函数的种类相对别的超参数没那么重要。
batch太小不适合并行来最大利用计算资源,太大会导致内存消耗(跑不了),浪费时间。但是batchsize较小时会带来噪音,噪音对神经网络是好事情,有助于其泛化性。
一般在没有足够多数据的时候,都使用K-折交叉验证。【深度学习用的不多,传统的用的多】
数据比例要结合真实情况,要是是因为采集而失衡,就要通过修改权重等手段处理。
模型复杂性由什么构成是一个复杂的问题。 一个模型是否能很好地泛化取决于很多因素。 例如,具有更多参数的模型可能被认为更复杂, 参数有更大取值范围的模型可能更为复杂。 通常对于神经网络,我们认为需要更多训练迭代的模型比较复杂
模型容量:拟合各种函数的能力,高容量可以记住更多的数据【主要因素:参数个数,参数值的取值范围】
数据复杂度:也很难衡量,一种直观的感觉和相对的,一些影响因素:
样本个数;每个样本的元素个数;时间、空间结构;多样性
泛化性和灵活性之间的这种基本权衡被描述为偏差-方差权衡(bias-variance tradeoff)。 线性模型有很高的偏差:它们只能表示一小类函数。 然而,这些模型的方差很低
深度神经网络位于偏差-方差谱的另一端。 与线性模型不同,神经网络并不局限于单独查看每个特征,而是学习特征之间的交互
即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。
深度网络的泛化性质令人费解,而这种泛化性质的数学基础仍然是悬而未决的研究问题。
随机初始化⽅法,对于中等难度的问题,这种⽅法通常很有效
初始化⽅案的选择在神经⽹络学习中起着举⾜轻重的作⽤,它对保持数值稳定性⾄关重要。此外,这些初始化⽅案的选择可以与⾮线性激活函数的选择有趣的结合在⼀起。我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。
不必过度迷信初始化,只要一开始不出问题,初始化是不太会影响后面的问题的。
Adam优化器的主要吸引力在于它对初始学习率不那么敏感。
如果预测的值的范围很大,RMSE 会被一些大的值主导。即使你很多小的值预测准了,但是有一个非常大的值预测的不准确,RMSE 就会很大。 先取 log 再求 RMSE(RMLSE),可以稍微解决这个问题。RMSE 一般对于固定的平均分布的预测值才合理。
Conv
核大小比较重要,填充一般取默认的,步幅取决于你的模型复杂度要控制在什么程度
步幅和填充是网络架构的一部分,我们选择某个网络比如“Resnet”,它就告诉了你该如何设置这些
一般很少手写神经网络,都用经典的,Resnet有个系列,除非你的输入特别不一样
网络结构设计中也有很多因素要平衡,而且,网络结构其实没有想象那么重要。
一般work里都是参考经典的网络做架构。
汇聚(pooling)层,它具有双重⽬的:降低卷积层对位置的敏感性,同时降低对空间降采样表⽰的敏感性。
【现在池化层用的越来越少了,李沐:以前池化也用来降低计算量,现在需求小,而数据增强和池化层降低敏感性的功能重复了。】
大图片只能用CNN,MLP和CNN都能用就用简单的MLP试试,调的动就用简单的MLP。
加入全局池化层,降低了模型复杂度,提高了泛化性,但是收敛会变慢,原来的全连接层比较复杂,强大了,能很快的收敛拟合。
Batch归一化含几重噪音,因为标准偏差的缩放和减去均值带来的额外噪音。所以类似于dropout,Batch归一化有轻微的正则化效果,你可以将Batch归一化和dropout一起使用,如果你想得到dropout更强大的正则化效果。
应用了较大的mini-batch,比如说,你用了512而不是64,通过应用较大的mini-batch会减少了噪音,减少正则化效果。
不要把Batch归一化当作正则化。好处是可以加速收敛,学习率可以调大一些,但一般不改变模型精度。
先跟着内存调batch size(增加直到每秒处理样本数不再增大),再调学习率,框架都差不多,epoch调大点,多了就停下。
==验证集准确度波动较大,一般是learning-rate的原因==,batchsize小,你lr就不能太大。
【从泛化性考虑,batch-size小,你一次更新的随机噪声多,就不能一次走太远。】
学习率对均值和方差敏感。
batch-norm和不断地调学习率有异曲同工之处,但是学习率不知道哪里调大哪里调小,不如BN方便。
微调
成员变量output的参数是随机初始化的,通常需要更高的学习率才能从头开始训练。 假设Trainer实例中的学习率为η,我们将成员变量output中参数的学习率设置为10η。
找pretrained的model时也得找相应领域的,判断癌症的就找医学领域的sei。
微调对学习率不敏感,可以选一个比较小的就行了,比如沐神用的1e^-5
预备知识
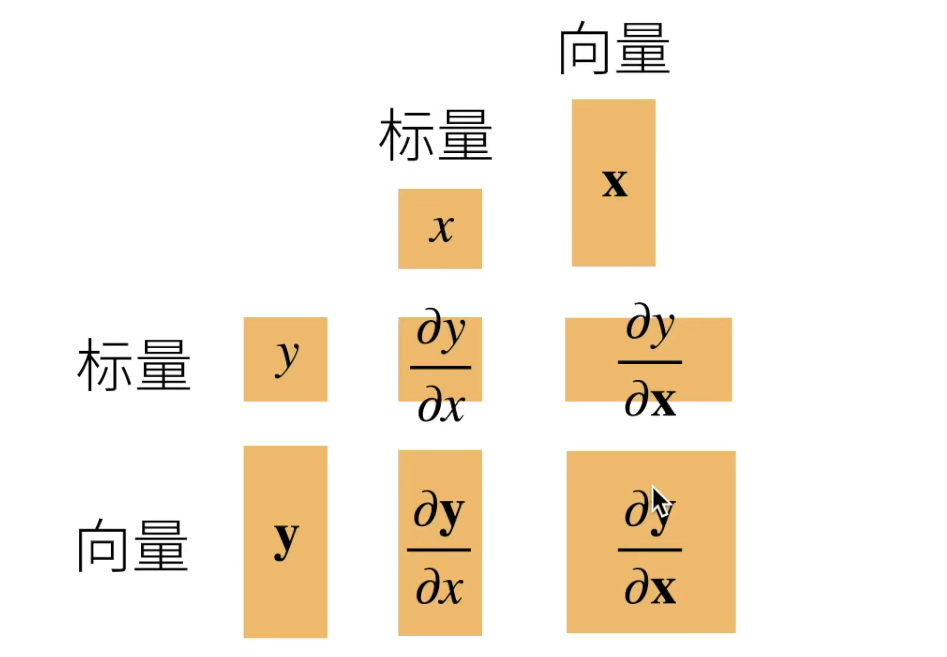
矩阵计算(求导)
亚导数,将导数拓展到不可微,便于计算机处理

这个是分子布局法,在x是标量时有体现。


虽然用不到,但得大概明白形状是咋变化的。

机器学习不关心p的问题,只关心np问题,所以不必纠结最优解,大部分情况也不是凸函数:joy:
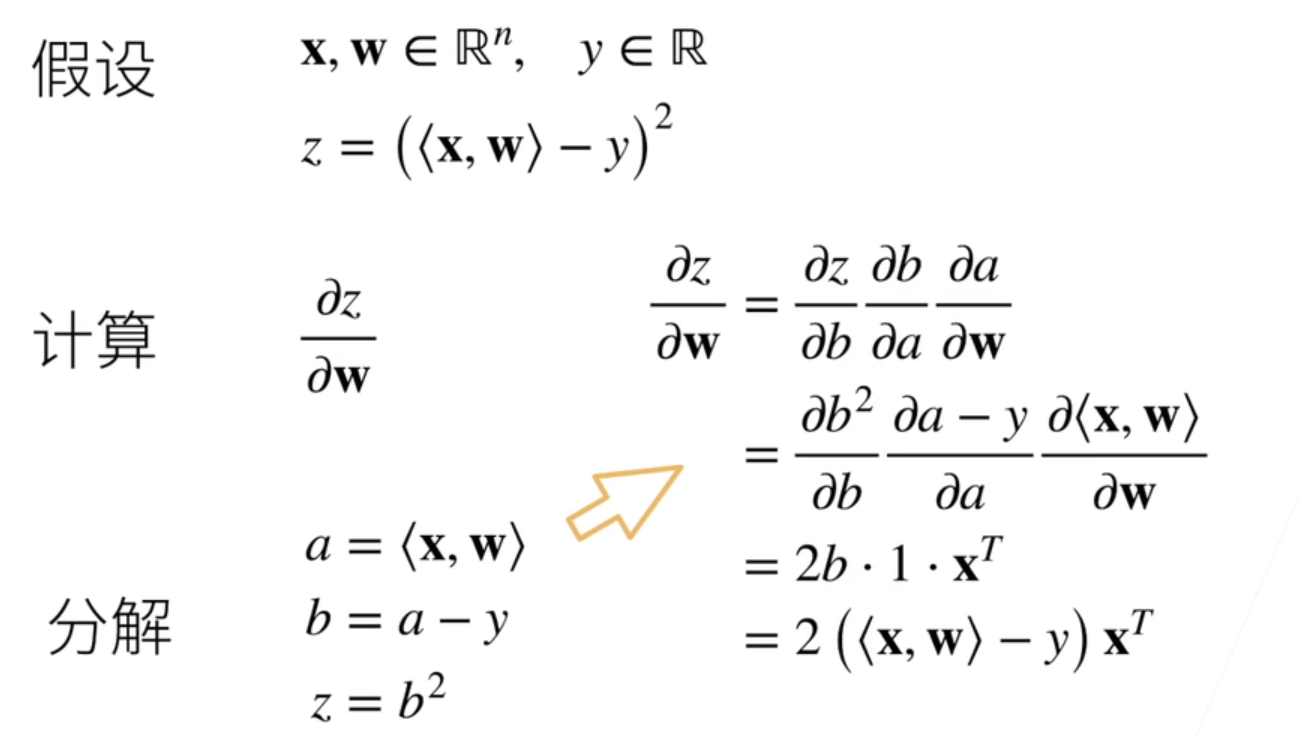
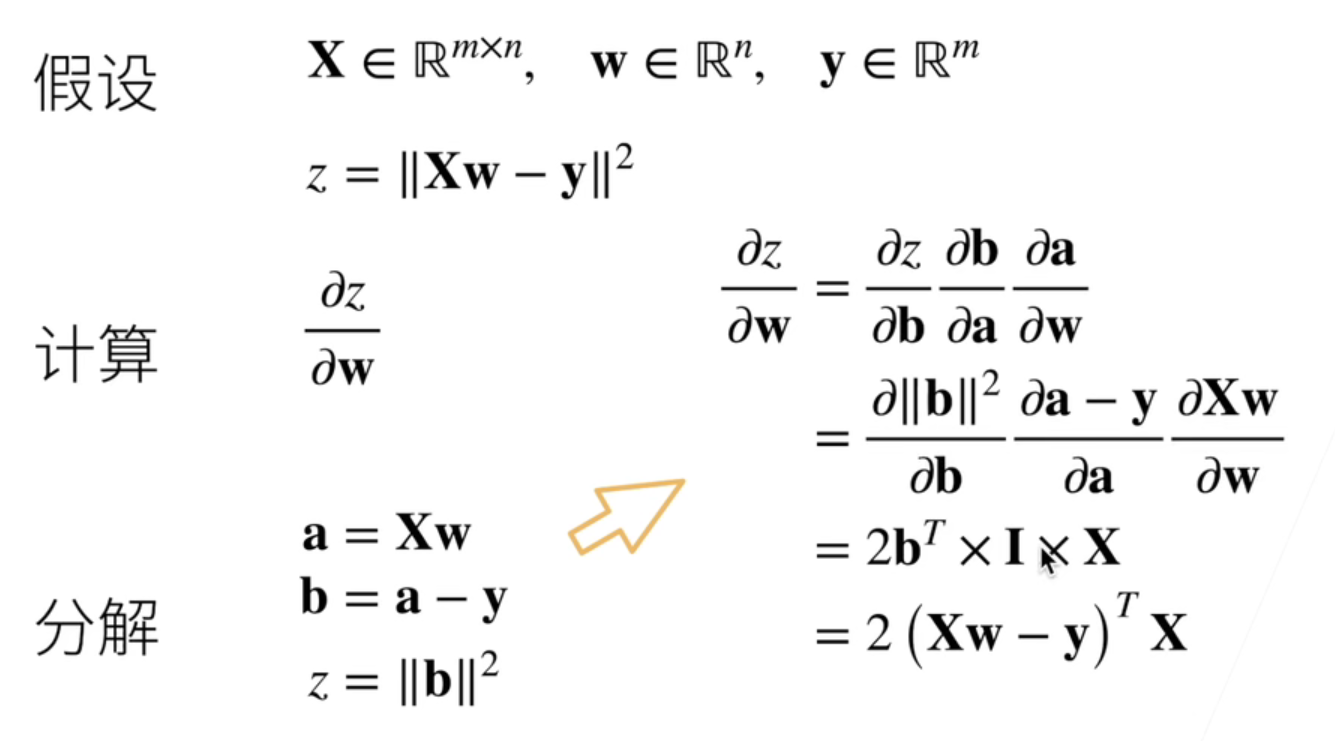
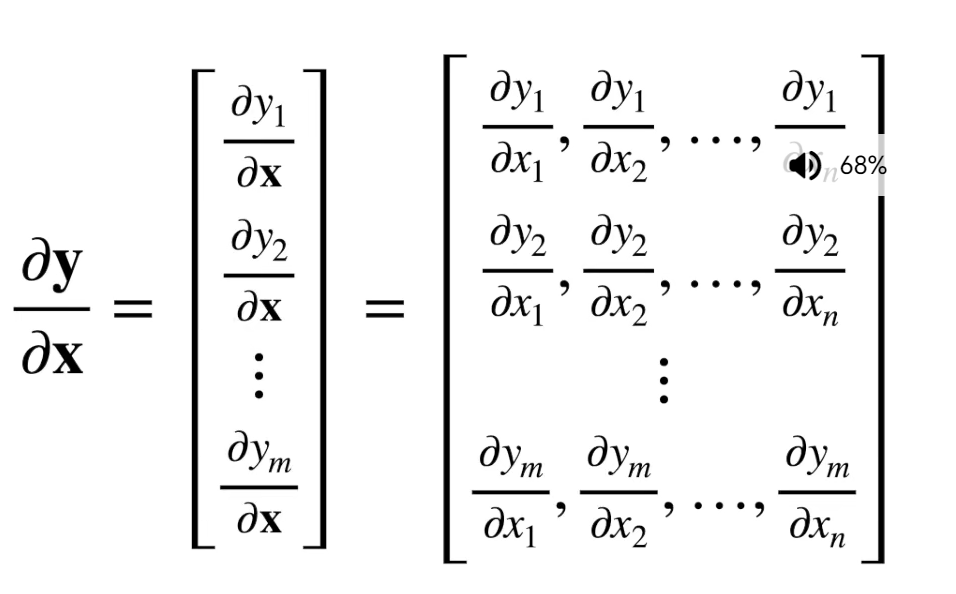
上面两个例子是向量、矩阵求导的例子
【计算图】
在框架中,我们用的是自动求导【计算图】。

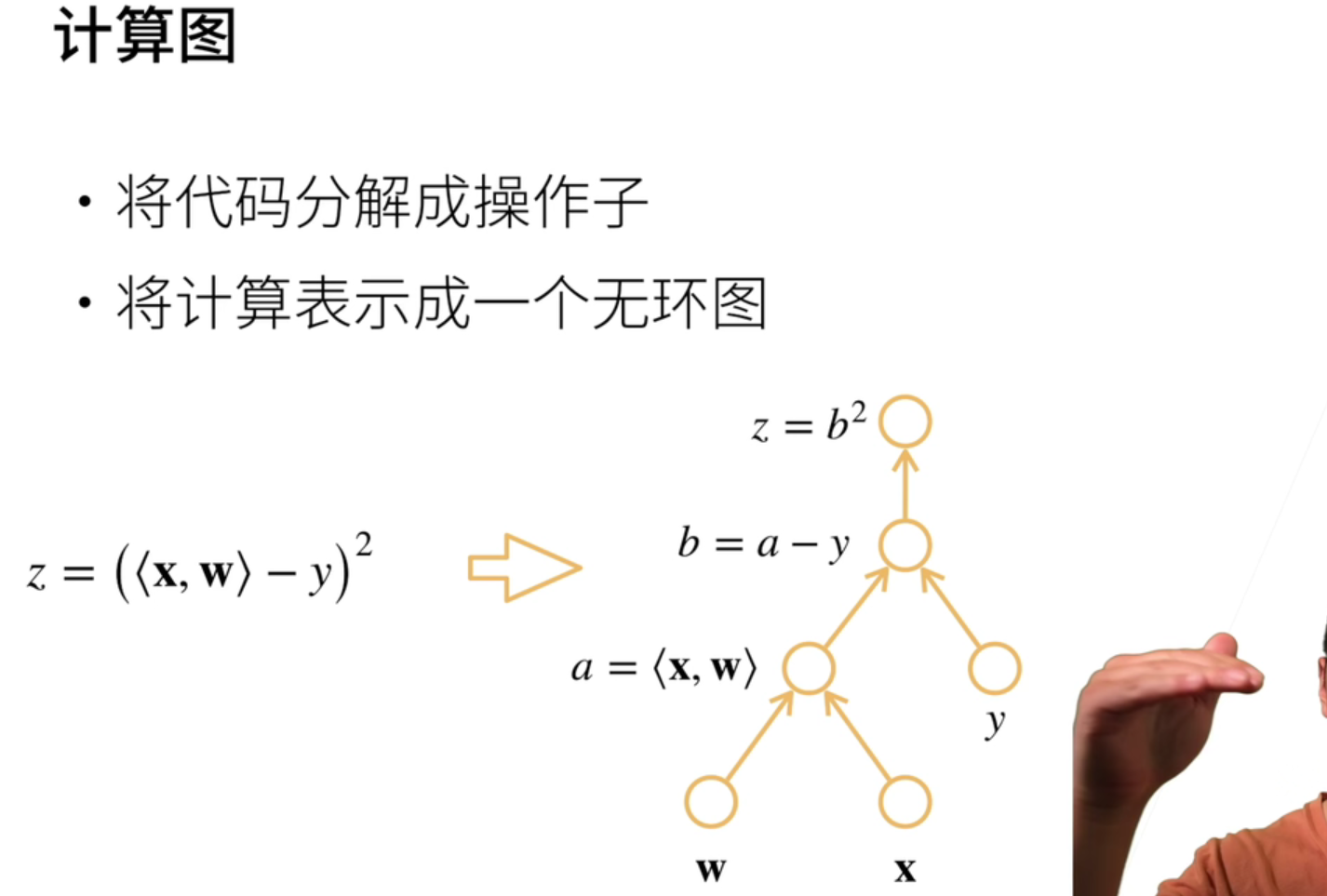
显式构造需要自己定义中间变量等。隐式则会根据你的计算流程【包括python控制流】自动生成计算图,不用操心。
Pytorch用的是隐式构造(更慢),tensorflow和数学上都用的是显式构造。
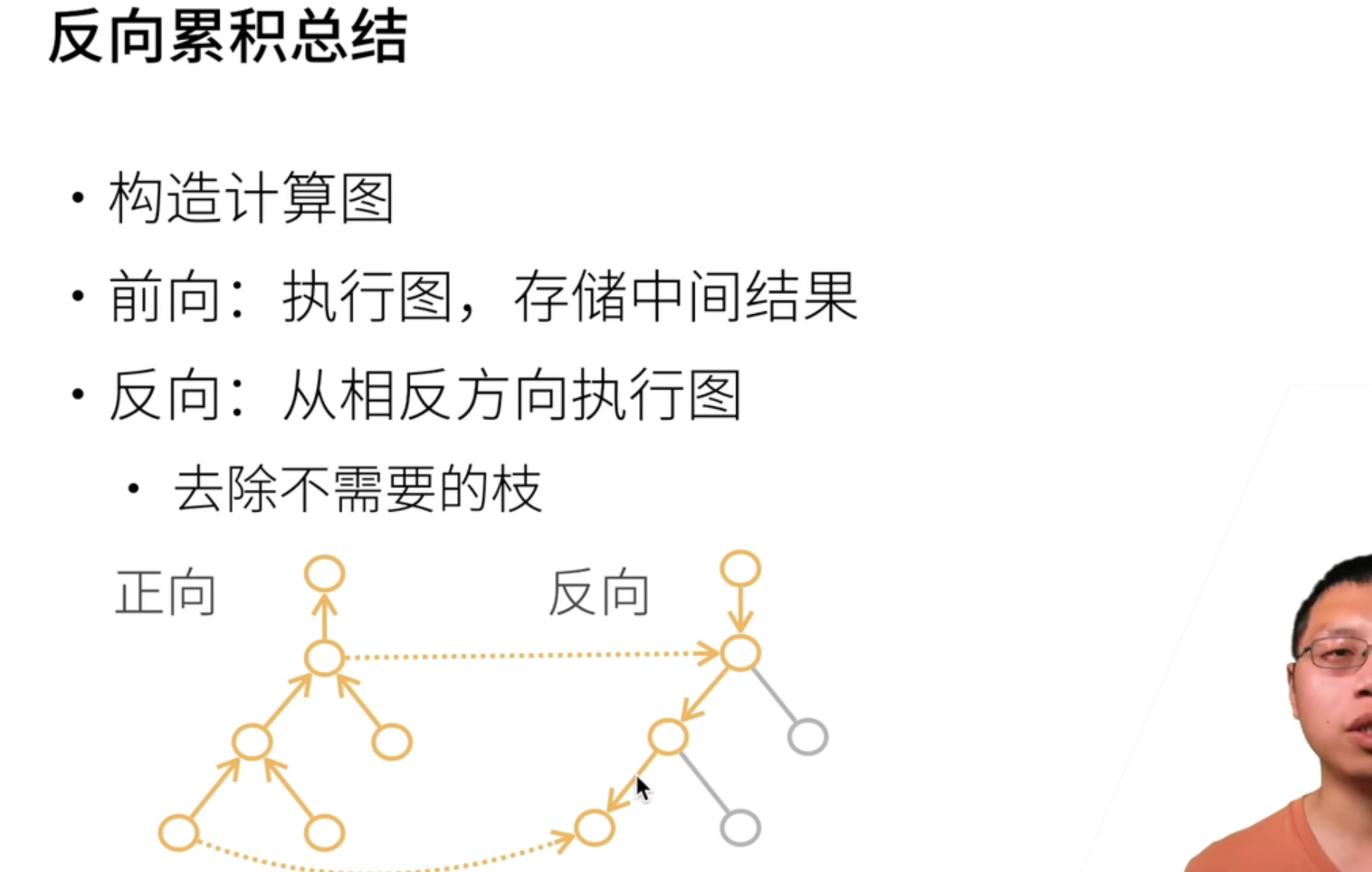

反向传播是拿内存换时间,因为需要存储正向的中间结果!果然时空不可兼得。【这也是内存爆炸祸源】
一般深度学习里很少用向量函数求导,都是标量求导,所以需要用sum函数处理后,再进行backward();如果维数特别多,求导后会变成非常巨大的张量矩阵,因此loss()函数也常设置为标量。
虽然支持高维向量求导,但是很慢,而且一般用不到。
需要反向传播的数值要为浮点型,不可以为整数
线性
绝对值和平方损失没太大的区别,一开始用平方是因为方便求导。
损失除以n变成平均是防止样本规模影响学习率的调整,不然又多一个超参数,还不正交。
样本大小不是批量的整数倍:丢弃、从下一个epoch补全、更改除数。
确认你读数据的速度要比模型训练的快,这是个常见的性能瓶颈。
SoftMax
通过将softmax和交叉熵结合在一起,可以避免反向传播过程中可能会困扰我们的数值稳定性问题。
因为softmax公式里的exp和交叉熵公式里的log可以相互抵消,避免做log和exp运算时出现inf和Nan
我们没有将softmax概率传递到损失函数中, 而是在交叉熵损失函数中传递未规范化的预测,并同时计算softmax及其对数, 这是一种类似“LogSumExp技巧”的聪明方式。
Mnist手写数字识别(10类) ImageNet自然物体分类(1000类)
从回归到多类分类——无校验比例:要求预测的最大可能选择比其他的有显著差距
从回归到多类分类——校验比例:就是多项逻辑斯蒂,也称softmax,输出的是匹配的概率。
如果把熵$H(P)$想象为“知道真实概率的人所经历的惊异程度”,那么什么是交叉熵?交叉熵从$P$到$Q$,记为$H(P, Q)$。
你可以把交叉熵想象为“主观概率为$Q$的观察者在看到根据概率$P$生成的数据时的预期惊异”。
当$P=Q$时,交叉熵达到最低。在这种情况下,从$P$到$Q$的交叉熵是$H(P, P)= H(P)$。简而言之,我们可以从两方面来考虑交叉熵分类目标:
(i)最大化观测数据的似然;(ii)最小化传达标签所需的惊异。
sofxmax输入是向量,再把图片拉长成向量时会损失许多空间信息,而卷积神经网络则不会。
.numel()直接获取tensor中元素个数
定义了展平层(flatten),来调整网络输入的形状nn.Flatten()第零维度保留,其他全部压到第一维。
net.apply(f)深度优先遍历并应用这个函数。
默认的误差其实是softlabel,把正确的那一类概率记作0.9,其他的是$\frac{1}{n-1}$,这样就有逼近的可能,而不是要趋于无穷。
可以认为logistic是softmax的二分类特例。
代码中有部分冗余,因为pytorch版本或历史原因!
在net.eval()测评模式下,就不会算梯度相关的东西了,效率更好
多层感知机
感知机其实等价于使用批量大小为1的梯度下降,而损失函数为
$$
l(y,x,w) = max(0,-y\langle w,x \rangle)
$$
当年发现感知机不能拟合XOR,是“第一次AI寒冬”,导致很多人转行哈哈,但后来有了多层感知机。【多个线性结合】
【深度学习在2014之前好像都是旧东西重命名哈哈哈】
- figsize: 指定figure的宽和高,单位为英寸
- dpi: 指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80, 1英寸等于2.5cm, A4 纸是 21*30cm的纸张
最好是慢慢的减少每层的大小,压小会损失信息,但有时候先压小一些再扩张可以deal with overfitting【没有太多科学,靠手感哈哈】
torch.relu()/sigmoid()/tanh()
沐神:所以不用SVM用mlp,其实是因为效果不好可以很容易换到CNN、RNN,代码结构变动小很多。
SVM对超参数不敏感,而且更容易优化,用起来更简单,有很漂亮的数学理论。现在也好,但是MLP改代码实在方便。
SVM在参数较多时,计算麻烦,还有可调性不强
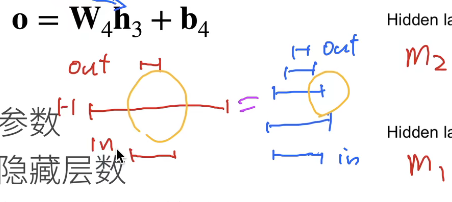
这俩效果能近似,但是左边的不好学,容易over fitting,右边的就叫“深层”,而且数量之上是指数倍增的。
激活函数的种类相对别的超参数没那么重要。
要保持鲁棒性,数据受干扰时,结果分类应该不变,这也是个很重要的问题。
模型
由于泛化是机器学习中的基本问题, 许多数学家和理论家毕生致力于研究描述这一现象的形式理论。
在同名定理(eponymous theorem)中, 格里文科和坎特利推导出了训练误差收敛到泛化误差的速率。
在一系列开创性的论文中, Vapnik和Chervonenkis 将这一理论扩展到更一般种类的函数。 这项工作为统计学习理论奠定了基础。
在接下来的章节中,我们将讨论因违背独立同分布假设而引起的问题。
原则:首先保证你的模型足够大,参数够多,保证了有前途,再通过各种手段降低模型容量避免过拟合。
一般在没有足够多数据的时候,都使用K-折交叉验证。【深度学习用的不多哈哈,传统的用的多】
K折三种做法:选出的超参数在整个数据集全部重算;或者把最好的所有的模型拿下来,以后就用这个算,结果取均值【模型稳定性好】;要么就选其中的一个,比如最好的模型。

模型复杂性由什么构成是一个复杂的问题。 一个模型是否能很好地泛化取决于很多因素。 例如,具有更多参数的模型可能被认为更复杂, 参数有更大取值范围的模型可能更为复杂。 通常对于神经网络,我们认为需要更多训练迭代的模型比较复杂
模型容量:拟合各种函数的能力,高容量可以记住更多的数据【主要因素:参数个数,参数值的取值范围】
VC维:统计学习理论的核心思想

数据复杂度:也很难衡量,一种直观的感觉和相对的,一些影响因素:
样本个数;每个样本的元素个数;时间、空间结构;多样性
这个总结,揭露了更深的理论。

我们很难比较本质上不同大类的模型之间(例如,决策树与神经网络)的复杂性。 就目前而言,一条简单的经验法则相当有用: 统计学家认为,能够轻松解释任意事实的模型是复杂的, 而表达能力有限但仍能很好地解释数据的模型可能更有现实用途。
沐神:神经网络的最大优点是——它更像一种语言。可编程性特别好,能解决的问题也很多
CNN、RNN通过更好的结构辅助网络更方便的训练出数据的模式,所以是尽量用神经网络的方法去描述数据的特性!【比如CNN是为了告诉神经网络,我觉得这个数据有空间信息】很多经典的论文一开始找的理由都是错的。
艺术:我不知道为什么,但这样做好看。神经网络就有50%是艺术xs
整个工科其实背后逻辑差不多。不如就学现在流行的东西【现在是深度学习】,以不变应万变。
将随机森林结合进深度学习比较少,参数不好传。
数据要结合真实情况,如果符合现实情况,那比例如何都没问题,要是是因为采集而失衡,就要通过修改权重等手段处理。
权重衰退
常用的控制过拟合的方法【即缩减每个参数的取值范围以减小模型容量】。L2正则,dropout都是
最离谱就是直接强行约束$||w||^2 \leq \theta$,但不怎么用,用的是等价形式——L2正则。
命名原因,在更新参数时w相当于多乘了个参数$(1-\eta \lambda)$
因为数据中存在噪音,在学习的时候会增加参数的震荡?所以学到的参数可能比实际的偏大,加入罚项拉回来?反正就那个意思
dropout【暂退法】
效果一般比权重衰减更好。但只能用在全连接层【注意每一次丢弃的结果是不一样的,不是永久丢弃,是暂退】
思想来自随机森林,但是从实验上来看,起到的作用和正则很像而非投票。
泛化性和灵活性之间的这种基本权衡被描述为偏差-方差权衡(bias-variance tradeoff)。 线性模型有很高的偏差:它们只能表示一小类函数。 然而,这些模型的方差很低
深度神经网络位于偏差-方差谱的另一端。 与线性模型不同,神经网络并不局限于单独查看每个特征,而是学习特征之间的交互
即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。
深度网络的泛化性质令人费解,而这种泛化性质的数学基础仍然是悬而未决的研究问题。
经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。 简单性以较小维度的形式展现
简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。
$$
\begin{aligned}
h’ =
\begin{cases}
0 & \text{ 概率为 } p \
\frac{h}{1-p} & \text{ 其他情况}
\end{cases}
\end{aligned}
$$
此模型期望不变。
在代码实现中有个效率技巧:做乘法(用掩码)比用索引(比如布尔)来的快,用一个float把布尔矩阵转成0.0,1.0矩阵。
dropout效果又好又好调,mlp现在用的越来越少了。
learning rate主要对期望、方差敏感。
数值稳定性
现在tanh函数在所有场合都优于sigmoid函数,但这俩再绝对值大时梯度消失,除非二分类,就在输出用一个,不然还是relu。
由于计算性能需要,一般GPU用16位浮点数,也就是[6e^-5,6e^4]
爆炸和消失的问题是在反传的过程中发生的



权重初始化
随机初始化⽅法,对于中等难度的问题,这种⽅法通常很有效
初始化⽅案的选择在神经⽹络学习中起着举⾜轻重的作⽤,它对保持数值稳定性⾄关重要。此外,这些初始化⽅案的选择可以与⾮线性激活函数的选择有趣的结合在⼀起。我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。
深度学习框架通常实现十几种不同的启发式⽅法。此外,参数初始化⼀直是深度学习基础研究的热点领域。其中包括专⻔⽤于参数绑定(共享)、超分辨率、序列模型和其他情况的启发式算法。例如,Xiao等⼈演示了通过使⽤精心计的初始化⽅法 [Xiao et al., 2018],可以⽆须架构上的技巧而训练10000层神经⽹络的可能性。
==Xavier==:沐神从均值和方差不变推导,得出了不可兼得,所以折中。
每层的W初始化
$$
\left(-\sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}, \sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}\right)
$$
模型一炸,准确率就变成50%左右了哈哈
沐神:虽然深度学习对数学要求比较低,但你还是得学,不然很多东西做不了,理解不了,光会写代码也没用。
高维损失的“可视化”,目前虽然有一些工作,但还比较原始。
数值被压缩到某个区间,数学上是不会影响到模型的表达性的,因为是总体的偏移。
不必过度迷信初始化,只要一开始不出问题,初始化是不太会影响后面的问题的。
pytorch默认初始化:
from torch.nn import init
#define the initial function to init the layer's parameters for the network
def weigth_init(m):
if isinstance(m, nn.Conv2d):
init.xavier_uniform_(m.weight.data)
init.constant_(m.bias.data,0.1)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0,0.01)
m.bias.data.zero_()分布偏移
首先,一旦模型开始根据鞋类做出决定,顾客就会理解并改变他们的行为。 不久,所有的申请者都会穿牛津鞋,而信用度却没有相应的提高。 总而言之,机器学习的许多应用中都存在类似的问题: 通过将基于模型的决策引入环境,我们可能会破坏模型。
协变量偏移、标签便宜、概念偏移。
在另一些情况下,标签偏移和协变量偏移假设可以同时成立。 例如,当标签是确定的,即使𝑦导致𝐱,协变量偏移假设也会得到满足。 有趣的是,在这些情况下,使用基于标签偏移假设的方法通常是有利的。 这是因为这些方法倾向于包含看起来像标签(通常是低维)的对象, 而不是像输入(通常是高维的)对象。
当分布变化缓慢并且模型没有得到充分更新时,就会出现更微妙的情况: 非平稳分布(nonstationary distribution)
偏移纠正
在相应的假设条件下,可以在测试时检测并纠正协变量偏移和标签偏移。在测试时,不考虑这种偏移可能会成为问题。
概念偏移很难用原则性的方式解决。 例如,在一个问题突然从“区分猫和狗”偏移为“区分白色和黑色动物”的情况下, 除了从零开始收集新标签和训练,别无妙方。 幸运的是,在实践中这种极端的偏移是罕见的。 相反,通常情况下,概念的变化总是缓慢的。

标签偏移的一个好处是,如果我们在源分布上有一个相当好的模型, 那么我们可以得到对这些权重的一致估计,而不需要处理周边的其他维度。 在深度学习中,输入往往是高维对象(如图像),而标签通常是低维(如类别)。
为了估计目标标签分布,我们首先采用性能相当好的现成的分类器(通常基于训练数据进行训练), 并使用验证集(也来自训练分布)计算其混淆矩阵。

环境
在某些情况下,环境可能会记住自动操作并以令人惊讶的方式做出响应。在构建模型时,我们必须考虑到这种可能性,并继续监控实时系统,并对我们的模型和环境以意想不到的方式纠缠在一起的可能性持开放态度。
环境变化的速度和方式在很大程度上决定了我们可以采用的算法类型。 例如,如果我们知道事情只会缓慢地变化, 就可以迫使任何估计也只能缓慢地发生改变。 如果我们知道环境可能会瞬间发生变化,但这种变化非常罕见, 我们就可以在使用算法时考虑到这一点。 当一个数据科学家试图解决的问题会随着时间的推移而发生变化时, 这些类型的知识至关重要。
伦理
最后,重要的是,当你部署机器学习系统时, 你不仅仅是在优化一个预测模型, 而你通常是在提供一个会被用来(部分或完全)进行自动化决策的工具。 这些技术系统可能会通过其进行的决定而影响到每个人的生活。
从考虑预测到决策的飞跃不仅提出了新的技术问题, 而且还提出了一系列必须仔细考虑的伦理问题。 如果我们正在部署一个医疗诊断系统,我们需要知道它可能适用于哪些人群,哪些人群可能无效。 忽视对一个亚群体的幸福的可预见风险可能会导致我们执行劣质的护理水平。 此外,一旦我们规划整个决策系统,我们必须退后一步,重新考虑如何评估我们的技术。 在这个视野变化所导致的结果中,我们会发现精度很少成为合适的衡量标准。
通常,在建模纠正过程中,模型的预测与训练数据耦合的各种机制都没有得到解释, 研究人员称之为“失控反馈循环”的现象。 此外,我们首先要注意我们是否解决了正确的问题。 比如,预测算法现在在信息传播中起着巨大的中介作用, 个人看到的新闻应该由他们喜欢的Facebook页面决定吗? 这些只是你在机器学习职业生涯中可能遇到的令人感到“压力山大”的道德困境中的一小部分。
Pytorch
块
事实证明,研究讨论“⽐单个层⼤”但“⽐整个模型小”的组件更有价值。例如,在计算机视觉中⼴泛流⾏的ResNet-152架构就有数百层,这些层是由层组(groups of layers)【==块==】的重复模式组成。这个ResNet架构赢得了2015年ImageNet和COCO计算机视觉⽐赛的识别和检测任务 [He et al., 2016a]。⽬前ResNet架构仍然是许多视觉任务的⾸选架构。在其他的领域,如⾃然语⾔处理和语⾳,层组以各种重复模式排列的类似架构现在也是普遍存在。
Sequential类使模型构造变得简单, 允许我们组合新的架构,而不必定义自己的类。 然而,并不是所有的架构都是简单的顺序架构。 当需要更强的灵活性时,我们需要定义自己的块,自定义计算。,我们⼀直在通过net(X)调⽤我们的模型来获得模型的输出。这实际上是net.__call__(X)的简写
在实现我们自定义块之前,我们简要总结⼀下每个块必须提供的基本功能:
- 将输⼊数据作为其前向传播函数的参数。
- 通过前向传播函数来⽣成输出。请注意,输出的形状可能与输⼊的形状不同。例如,我们上⾯模型中的
第⼀个全连接的层接收⼀个20维的输⼊,但是返回⼀个维度为256的输出。 - 计算其输出关于输⼊的梯度,可通过其反向传播函数进⾏访问。通常这是⾃动发⽣的。
- 存储和访问前向传播计算所需的参数。
- 根据需要初始化模型参数。
只要继承nn.Module,我们的实现只需要提供我们⾃⼰的构造函数(Python中的__init__函数)和前向传播函数。不必担⼼反向传播函数或参数初始化.
块的⼀个主要优点是它的多功能性。我们可以⼦类化块以创建层(如全连接层的类)、整个模型(如上⾯的MLP类)或具有中等复杂度的各种组件。
每个Module都有⼀个_modules属性?以及为什么我们使⽤它而不是⾃⼰定义⼀个Python列表?简而⾔之,_modules的主要优点是:在模块的参数初始化过程中,系统知道在``_modules`字典中查找需要初始化参数的子块。
【可以嵌套】
Conv
在图片里找模式的原则(启发了卷积):
平移不变性,模型在图片任何位置,得到的结果应该一致。
局部性,只需要局部的信息就能判断。
卷积核则满足,参数与位置信息i,j无关;而卷积核只关注周围的几个元素。
卷积核较小,层数较深类似每层参数较少的MLP,也是同样的好处。
很少用偶数的卷积核。


加法重载:

核大小比较重要,填充一般取默认的,步幅取决于你的模型复杂度要控制在什么程度
步幅和填充是网络架构的一部分,我们选择某个网络比如“Resnet”,它就告诉了你该如何设置这些
一般很少手写神经网络,都用经典的,Resnet有个系列,除非你的输入特别不一样
网络结构设计中也有很多因素要平衡,而且,网络结构其实没有想象那么重要。
一般work里都是参考经典的网络做架构。
机器学习本质上是个极端的压缩、泛化的过程。
3x3卷积用的多,因为10层3x3差不多等于5、6层5x5,但是因为这个计算量是平方增长,所以3x3快很多。
【简单的,就算效果差一点,才能通用】
没有深度学习的时候,需要很多人力的成本调参,调出来效果不好还得换数据,又得人清洗。
深度学习用计算为代价替代了这些成本,总体来看其实成本是下降的,所以才得以流行。
输入通道和输出通道其实没有太多相关性,输出通道数是架构的一部分。
不同通道的卷积核大小一致是为了计算上的好处。
【平时简单调试一下就用notebook就好,大型的采用Pycharm】
3d卷积效果比2d稍好一点点,但是计算复杂度高很多,主要用在视频。
$(\frac{n+2p-f}{s}+1)\times (\frac{n+2p-f}{s}+1)$ 不是整数就向下取整
池化层
我们的机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含⼀只猫呢?”),所以我们最后⼀层的神经元应该对整个输⼊的全局敏感。通过逐渐聚合信息,⽣成越来越粗糙的映射,最终实现学习全局表⽰的⽬标,同时将卷积图层的所有优势保留在中间层。
当检测较底层的特征时(例如 6.2节中所讨论的边缘),我们通常希望这些特征保持某种程度上的平移不变性。例如,如果我们拍摄⿊⽩之间轮廓清晰的图像X,并将整个图像向右移动⼀个像素,即Z[i, j] =X[i, j + 1],则新图像Z的输出可能⼤不相同。而在现实中,随着拍摄⻆度的移动,任何物体⼏乎不可能发⽣在同⼀像素上。即使⽤三脚架拍摄⼀个静⽌的物体,由于快⻔的移动而引起的相机振动,可能会使所有物体左右移动⼀个像素(除了⾼端相机配备了特殊功能来解决这个问题)。
汇聚(pooling)层,它具有双重⽬的:降低卷积层对位置的敏感性(比如3x3,那就允许你的局部特征在高宽上移动俩像素,仍能识别到该模式【与感受野有关】),同时降低对空间降采样表⽰的敏感性。

从语义上看,池化放在卷积后,降低敏感性。
【现在池化层用的越来越少了,李沐:以前池化也用来降低计算量,现在需求小,而数据增强和池化层降低敏感性的功能重复了。】
【尽量不要调用python本身的函数,慢到怀疑人生,但是自带的数据结构内存有优化,可以列表搞好再转成tensor】
Models
LeNet
1989
:star: 核心思想——不断把(空间信息)长宽压缩到越来越长的通道里,最后MLP训练出输出,未来基本都是这个思想。
直观理解:假设输入输出高宽不变,通常不会动通道数。假设输入输出高宽都减半,通道会加一倍。【空间压缩了,把提取的信息在更多的通道存下来】
背模型的参数意义不大,要理解是做压缩操作的思想和模式。
直观理解:本来一个像素识别一个低级特征,压缩到一堆通道后一个像素就能识别一个类别(高级特征)。
大图片只能用CNN,MLP和CNN都能用就用简单的MLP试试,调的动就用简单的MLP。
通常来说准确率还是个比较主观的东西,你也不能知道你收集这个数据能达到多高准确,只要用户用的好。 用户心理可能有个阈值,低于它,体验就会很差,高过它,够用就行了。
时序领域,没有很好的数据集。
迁移学习并不用很大的数据集。
AlexNet
2012之前流行的是 kernels 核方法,有优美的理论支撑,SVM不用调参哈哈。
还有几何学,不断做物理假设,研究地球的规律,但是深度学习做的比他们更好,还有特征工程。
吴恩达是说小规模数据分不出差距,神经网络在大规模数据上有优势,异曲同工吧!
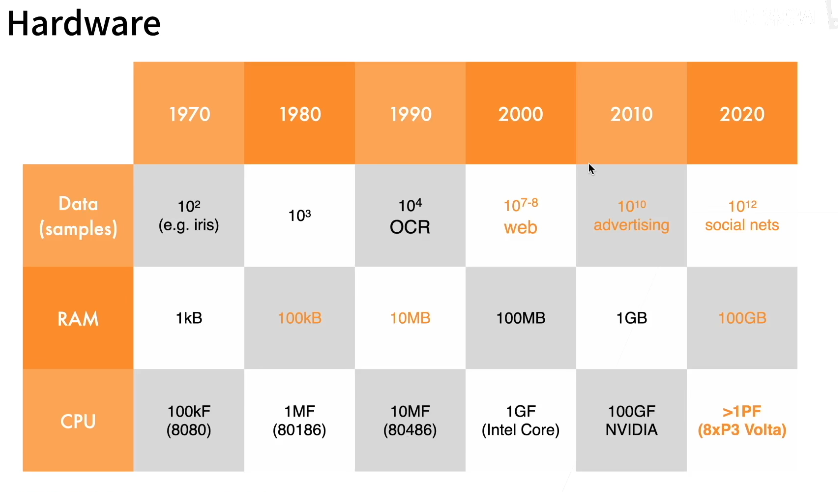
计算能力的增长超过了数据的增长。
90年代,用的还是神经网络,模型比较小,比较便宜;
2000年的时候核方法是主流,简单,有理论支撑,能找到核方法的核;
现在深度学习又是主流,因为计算超过了数据(GPU的兴起),可以构造更深的网络结构,用计算量换取精度。
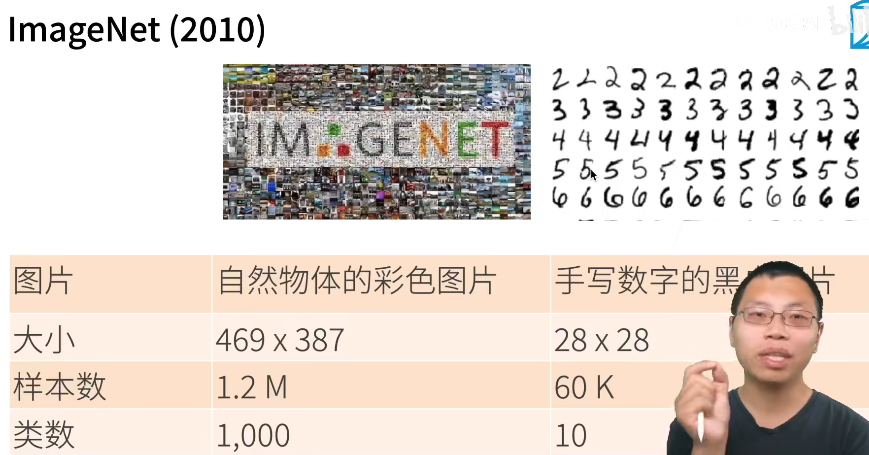 “更深更大的LeNet”:
“更深更大的LeNet”: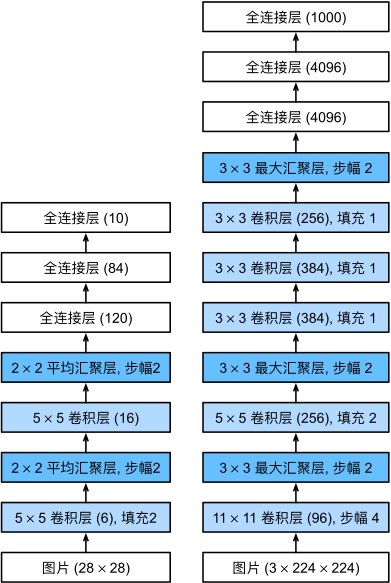
2012年,AlexNet赢了2012ImageNet竞赛。
创新点:丢弃法,Relu的使用,MaxPooling(取值大,梯度大,更好训练)
【由此开启了CNN学习特征而非人工特征的时代,省力高效,更加普适】
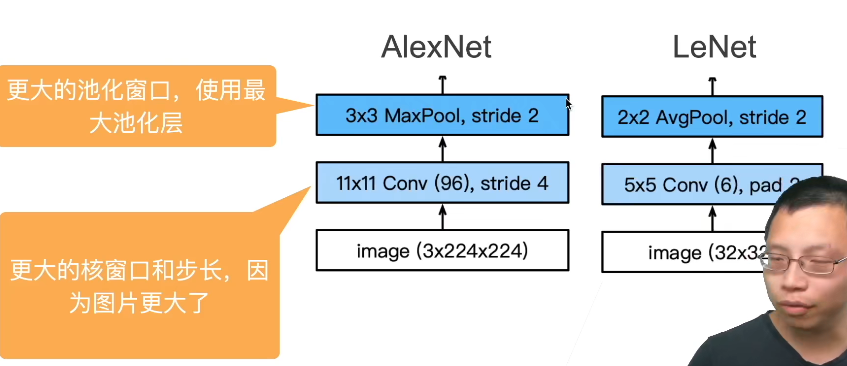
卷积对位置敏感,那就数据增强(非常重要),让你不能记住所有数据。AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合
GPU beats CPU:首先,功耗往往会随时钟频率呈二次方增长。 对于一个CPU核心,假设它的运行速度比GPU快4倍,你可以使用16个GPU内核取代,那么GPU的综合性能就是CPU的16×1/4=416×1/4=4倍。 其次,GPU内核要简单得多,这使得它们更节能。 此外,深度学习中的许多操作需要相对较高的内存带宽,而GPU拥有10倍于CPU的带宽。
Fashion-MNIST图像的分辨率(28×2828×28像素)低于ImageNet图像。 为了解决这个问题,我们将它们增加到224×224224×224(通常来讲这不是一个明智的做法,但我们在这里这样做是为了有效使用AlexNet架构)
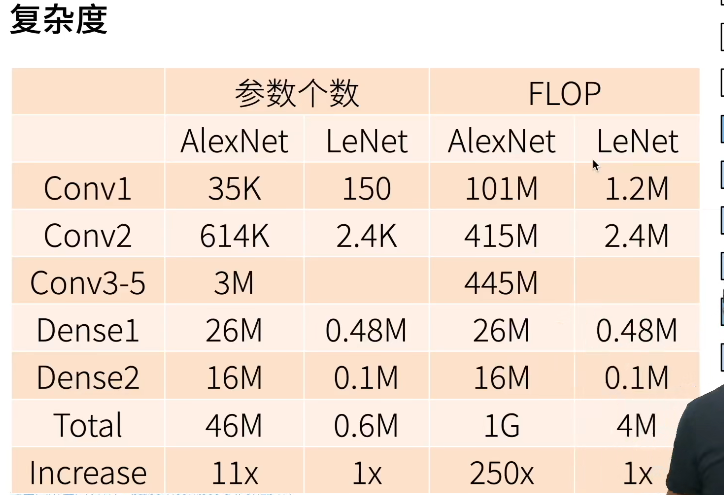
Lenet太小以至于难以利用GPU资源,Alexnet相对好一点,所以虽然计算量差了200倍,但速度只差了20倍
ImageNet仍是当下使用最常用的
现在已经比较成熟,CV新的model难搞,但是落地的demo做的人很多,好做一些。
resize要保持高宽比,一般短边为基线,然后拿出中间的;或随机取5、6个短x短的
VGG
神经网络更深更大自然更好,但是如何组织才能有效的实现呢,太多全连接层太贵,
AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。 在下面的几个章节中,我们将介绍一些常用于设计深层神经网络的启发式概念。
与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象。研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。
通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。
新思想:

学术界一派对另一派的打压。
NiN
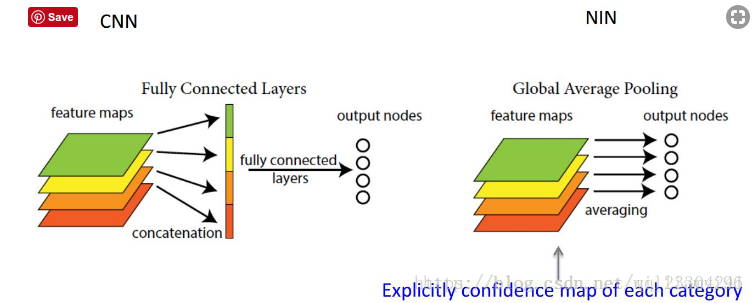
AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。 网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机。
而且1x1能增加非线性性,因为block里有ReLU函数。
1x1卷积核,又称为网中网(Network in Network)
现在已经不怎么流行了。
但是最近那个用MLP代替CNN,以及当年的用CNN代替MLP(参数比较少)的思想其实是类似的。
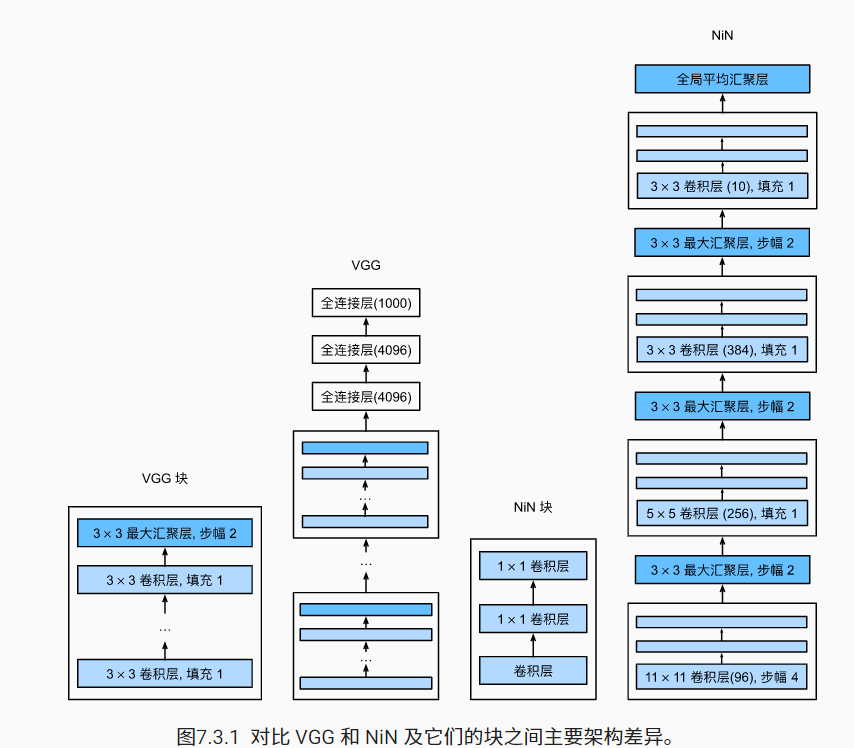

NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。
全连接存在的问题:参数量过大,降低了训练的速度,且很容易过拟合
相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global average pooling layer)(gap),生成一个对数几率 (logits)。NiN设计的一个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
大量1x1卷积会拖慢运行速度,这个一般,后来google更好地使用了这个卷积。
python做service十分容易,写个for loop就行了。
【深度神经网络结构里都没有softmax,因为那个是放在train时的loss里的不是放在网络结构里的。】
加入全局池化层,降低了模型复杂度,提高了泛化性,但是收敛会变慢,原来的全连接层太强大了,能很快的收敛。
预测函数实现的时候,记得把原始labels copy到GPU上,才能计算并做预测;同时预测结果要拿回CPU,与其他的计算。
GoogLeNet
GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。 这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。 本文的一个观点是,有时使用不同大小的卷积核组合是有利的。我们省略了一些为稳定训练而添加的特殊特性,现在有了更好的训练方法,这些特性不是必要的。
《致敬LeNet》——但是其实一点关系都没有,我感觉他们就是皮了,正好le一样吧。设计灵感参考了NiN
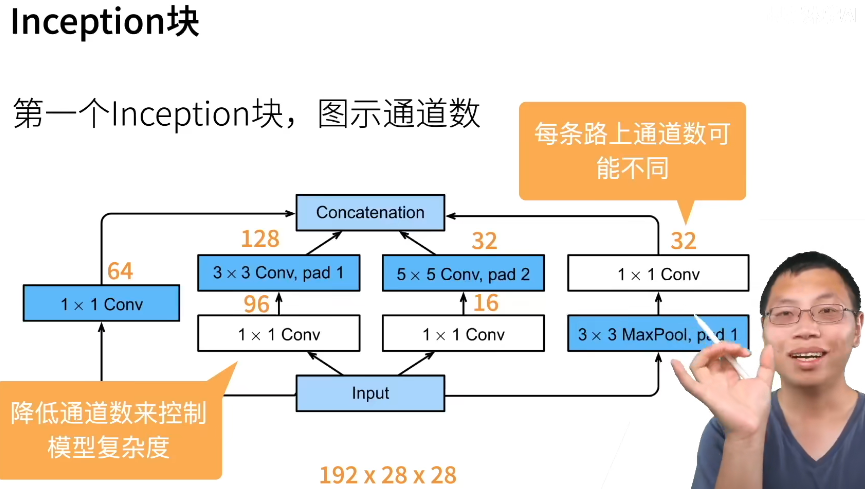
xs,作者从来都没说过这些通道数怎么来的,可能是氪金氪出来的。
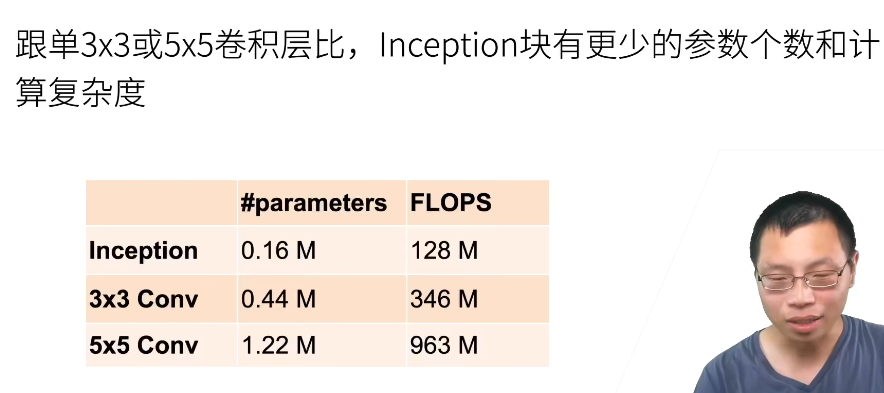
ps:
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
注意在深度学习中,我们用的是FLOPs,也就是说计算量,即用来衡量算法/模型的复杂度。
一个Stage是高宽减半。
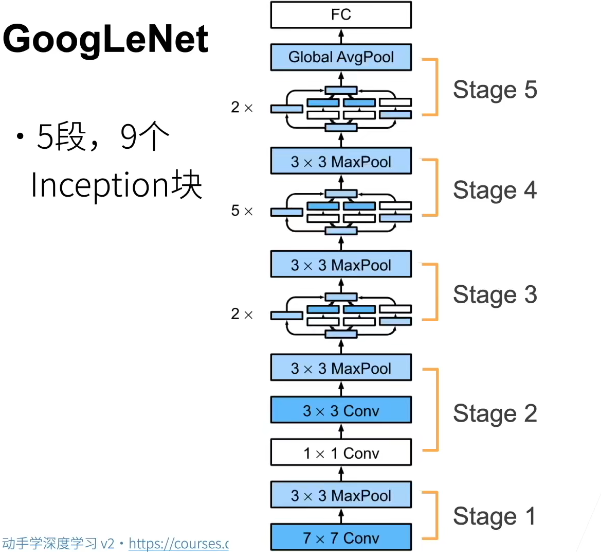
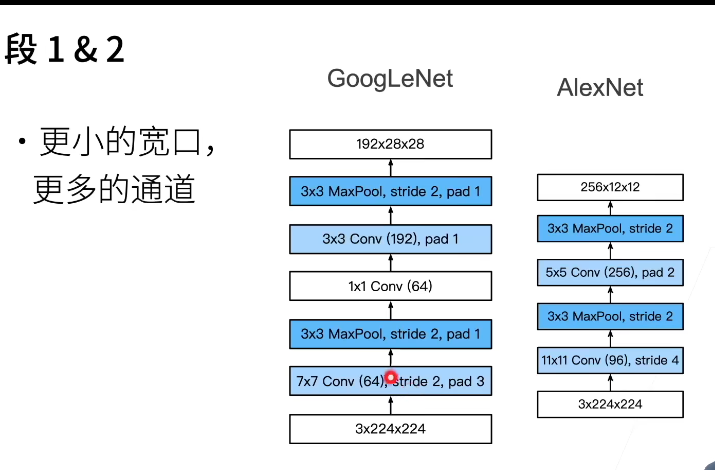
都是把高宽先减下去,然后通道数拉上去便于后面计算,不然计算量太大了。
【更小的卷积层,高宽保留的比Alex还是多一点,能支持后续更深的Network】
v2使用了batch normalization v3修改了Inception块, v4使用残差连接。
v3现在还是很常用,精度不差太多,运算速度也还行。
写这个网络真麻烦。。。虽然结构确实挺好理解,以后还是copy吧。 trick is more important
Modern
Batch Norm
对于很深的层,这个应该是不可或缺的,效果很好。
吴恩达:
Batch归一化减少了输入值改变的问题,它的确使这些值变得更稳定,神经网络的之后层就会有更坚实的基础。即使使输入分布改变了一些,它会改变得更少。它减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习,稍稍独立于其它层,有助于加速整个网络的学习。
Batch归一化含几重噪音,因为标准偏差的缩放和减去均值带来的额外噪音。这里的均值和标准差的估计值也是有噪音的,所以类似于dropout,Batch归一化有轻微的正则化效果,因为给隐藏单元添加了噪音,这迫使后部单元不过分依赖任何一个隐藏单元,类似于dropout,它给隐藏层增加了噪音,因此有轻微的正则化效果。因为添加的噪音很微小,所以并不是巨大的正则化效果,你可以将Batch归一化和dropout一起使用,如果你想得到dropout更强大的正则化效果。
也许另一个轻微非直观的效果是,如果你应用了较大的mini-batch,对,比如说,你用了512而不是64,通过应用较大的min-batch,你减少了噪音,因此减少了正则化效果,这是dropout的一个奇怪的性质,就是应用较大的mini-batch可以减少正则化效果。
说到这儿,我会把Batch归一化当成一种正则化,这确实不是其目的,但有时它会对你的算法有额外的期望效应或非期望效应。但是==不要==把Batch归一化当作正则化,把它当作将你归一化隐藏单元激活值并加速学习的方式,我认为正则化几乎是一个意想不到的副作用。


请注意,我们在方差估计值中添加一个小的常量ϵ>0,以确保我们永远不会尝试除以零
对于卷积和全连接的类比,一个像素是1x通道数,可以看成一个样本,通道数=特征维数,样本数=batch*h*w
所以1x1全连接类比全连接就很好理解了。

因为你每次是随机取样,当前的均值和方差相当于随机的。
好处是可以加速收敛,学习率可以调大一些,但一般不改变模型精度。
xavier是初始化,是数值一开始不要炸;BN是在模型训练的whole过程,增加==噪音==。
BN仍然难以解释,但已经被证明是一种不可或缺的方法。它适用于几乎所有图像分类器,并在学术界获得了数万引用。
先跟着内存调batch size(增加直到每秒处理样本数不再增大),再调学习率,框架之间都差不多,epoch调大点,多了就停下。
ResNet
只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。 对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)f(x)=xf(x)=x,新模型和原模型将同样有效。 同时,由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。【通常不会让模型变坏,如果下降了,那就令g(x)为0,直接映射x】
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
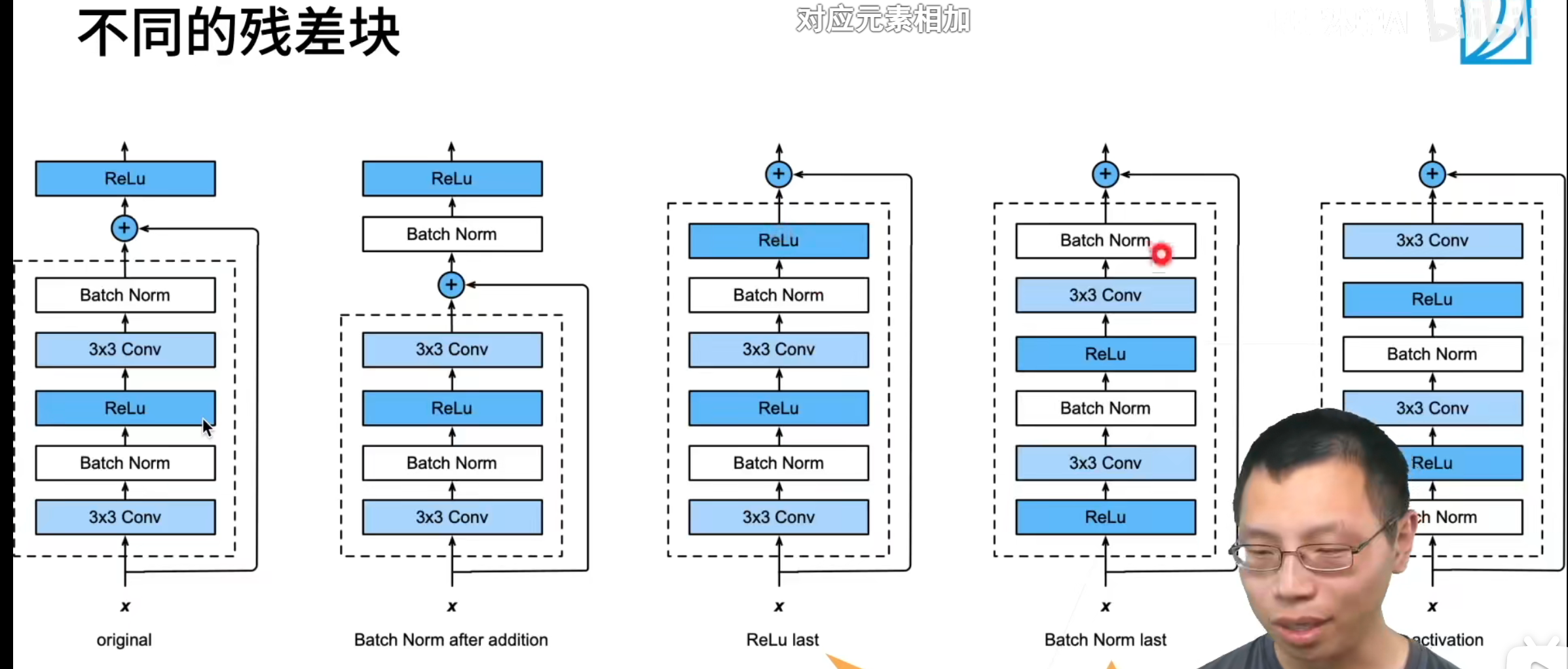
一般用rescnet 34就行了,resnet 152一般用来刷榜。。。实际不怎么用
精度更高的其实都是resnet变种。
乘法变加法,防止梯度出问题。
hardware
一台服务器可以支持多个GPU,高端服务器最多支持8个GPU。更典型的数字是工程工作站最多4个GPU,这是因为热量、冷却和电源需求会迅速增加,超出办公楼所能支持的范围。对于更大的部署,云计算(例如亚马逊的P3和G4实例)是一个更实用的解决方案。
由于Python中的全局解释器锁(GIL),CPU的单线程性能在我们有4-8个GPU的情况下可能很重要。所有的条件都是一样的,这意味着核数较少但时钟频率较高的CPU可能是更经济的选择。
GPU性能主要是以下三个参数的组合:
- 计算能力。通常我们追求32位浮点计算能力。16位浮点训练(FP16)也进入主流。如果你只对预测感兴趣,还可以使用8位整数。最新一代图灵GPU提供4-bit加速。不幸的是,目前训练低精度网络的算法还没有普及。
- 内存大小。随着你的模型变大或训练期间使用的批量变大,你将需要更多的GPU内存。检查HBM2(高带宽内存)与GDDR6(图形DDR)内存。HBM2速度更快,但成本更高。
- 内存带宽。只有当你有足够的内存带宽时,你才能最大限度地利用你的计算能力。如果使用GDDR6,请追求宽内存总线。
在每个系列中,价格和性能大致成比例。Titan因拥有大GPU内存而有相当的溢价。然而,较新型号具有更好的成本效益
提高CPU利用率
V:L1 cache: 3 cycles L2 cache: 11 cycles L3 cache: 25 cycles Main Memory: 100 cycles
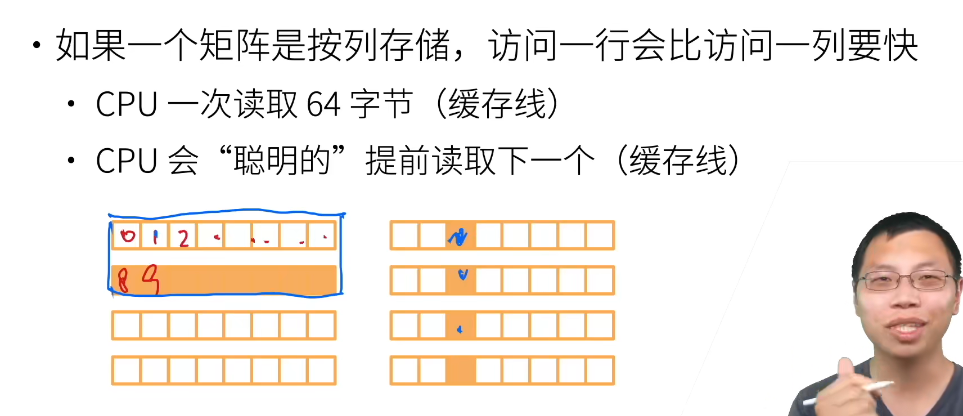
cpu达不到理论计算能力,很大可能是内存访问太慢了。行为样本比列块。。因为CPU是按行存储,速度差距蛮大的。
intelCPU使用了超线程,就是一个物理核变成几个虚拟核,告诉你的是虚拟的。
但是对于计算机密集型,超线程没什么用,因为它们共享寄存器。超线程对于几个不同的任务比较有用。


向量化(c = a+b)这种写法,非常容易并行,能很好地利用CPU的多核
提高GPU利用率
GPU如果内存带宽跟不上,很难跑满,你得去内存里面拿数据,然后进行计算。
所以GPU在运算和带宽上做的很大,代价是内存大不了。而且显存都是高带宽的,很贵,比CPU的贵多了,所以在这上面扣。


神经网络得够大,特征不到几千维,都打不满。
控制语句打比方,一个判断,几千个线程得停下来等(现在有改善,只停一组核,但还是很亏)
因为带宽限制,CPU和GPU少点互传;因为同步的开销,最好一次传完,别一会传一下【可视化和计算loss占用的很少没事】

一般GPU就用来打游戏哈哈,放视频都用不上。要做好高性能,硬件很重要,编译器同等重要,CUDA就投入很多资源。最难的是软件,编译器,和你的生态。
核数和频率与功耗有很大关系。
在深度学习框架内部,对GPU的运算也有很多优化,参数的顺序都是有讲究的,甚至会内部格式化后再参与计算。
计算量发展是指数型的,如果什么东西被发现有效,大家会拼命往上堆。
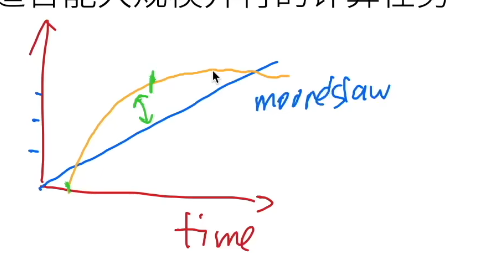
沐神:分久必合,合久必分。硬件增长是线性的,任务确是log增长,在任务超过硬件时,很多人会去做“专用”,比如领域专用,分布式,定制。而任务不是无穷无尽的,ImageNet 100w也够了,等硬件追上来,大家又去做通用的了。
python的multiprocessing做的很拉跨,不如numba go的分布式和这里的分布式理论上有差距,不太适合高性能。
每个语言都有自己的特性,用的人群是有特征的,go都是做网页的那些人,不会关注高性能计算。
要复现论文,80%的论文不能复现,而且作者得把细节写出来,得理解每一句话,有时候会放论文,是很细节,很锻炼能力的事情。
硬件和软件不一样,技术细节不能公布和讨论(TPU公布了)
More Chips


但是你要是指令用不到那么多计算,那就浪费掉了。
华为用了大量的FPGA,比如路由器,因为不像专用ASIC一样不可更新,其更新换代可以通过烧录进行。
专用

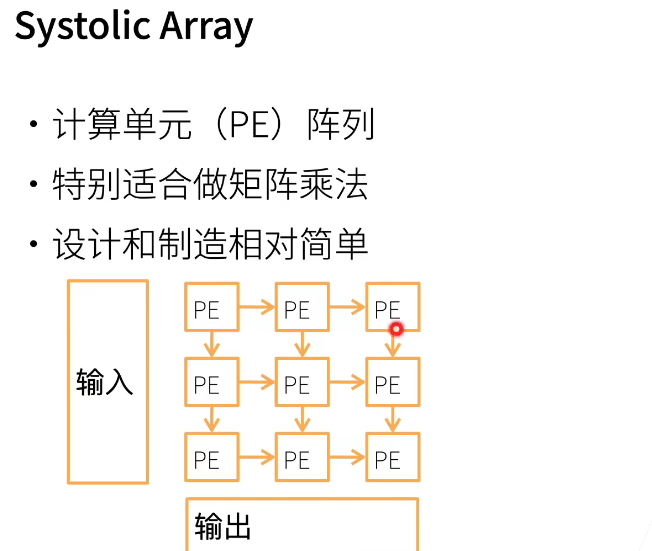
Nvidia盈利:游戏卡赚不了几个钱,但是你学会怎么开发后,到公司里,公司得买server啥的,贼贵,盈利90%
TPU这样的专用芯片,就能省下很多钱。大家都造ASIC是因为不用实现通用,就能省下很多的精力,造的难度骤降,而且便宜。
但可能会担心2,3年做出来,应用已经不火了。

TPU还是用tensorflow跑比较好,pytorch的xla也支持,但是沐神说毕竟不是原生的。
对于云和数据中心,功耗不是大问题,电费不是一个机房的大头,3年才多少钱,还比不上设备换代。
芯片一代用个2,3年就可以啦。
网络设计,首先还是考虑了硬件的能力,所以papers也得fit到硬件上,==软硬是鸡生蛋,蛋生鸡,相互影响==。
比如TPU内存特别大,而且算全连接层很好,所以transformer在TPU上能很好run,它的发明也是受到TPU很大的影响。很多手机厂商号称的ASIC其实是个DSPxs
如果框架:真开源,其实不用担心,只要框架间还在竞争没用垄断,就不用担心,因为付费损失的是开发者。
框架相对来说比较简单???我感觉沐神在凡尔赛。
单机多卡并行


模型并行难优化一些,而且可能有些机器空闲。数据并行性能会变差,因为矩阵变小了,能用的进程↓
显存优化是很难的啦,靠的是框架,pytorch做的还行。
==验证集准确度波动较大,一般是learning-rate的原因==,batchsize小,你lr就不能太大。
batch-norm和不断地调学习率有异曲同工之处,但是学习率鬼知道哪里调大哪里调小,不如BN方便。
如果不同GPU性能不一样,最好算好性能差,按倍率分配任务,最好同时算完并行度好一些,涉及同步机制。
分布式计算
所有机器都能读取样本,数据放在分布式文件结构上。
通常有多个worker,每个worker可能有好几个GPU
还有多个参数服务器,每个服务器存了模型的一部分参数,每次worker都是向所有服务器要。
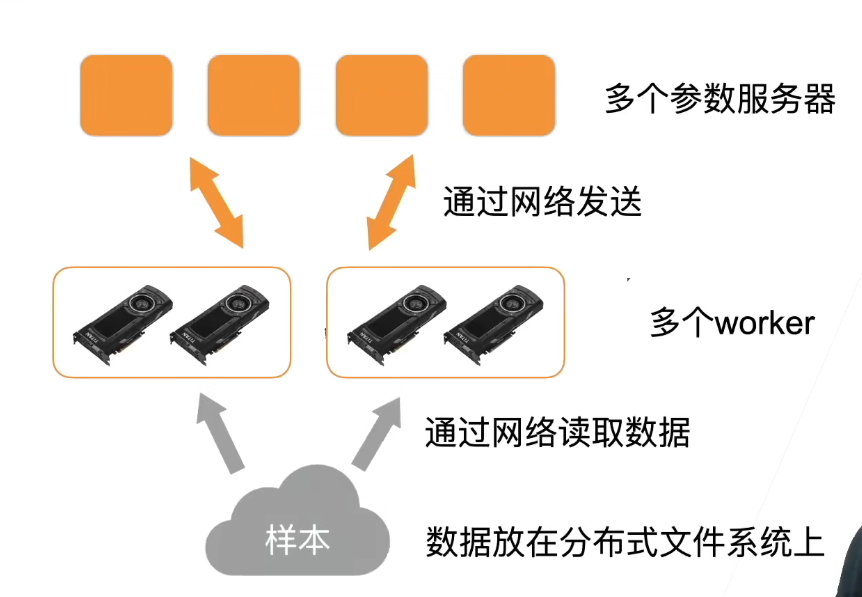
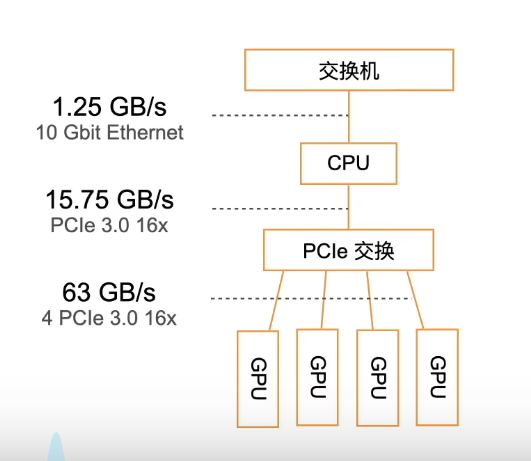
尽量少在机器之间通信,尽量本地。
大致流程:
- 每个计算服务器读取小批量的一块。
- 然后worker进一步将数据切分到每个GPU上
- 每个worker从参数服务器拿到参数,复制到每个GPU上
- 将所有GPU上的梯度求和,在本地做all-reduce,然后把加起来的发出去。(减少通讯次数)
- 每个参数服务器对梯度求和,并更新参数。


$t_1$和batch-size正相关,但是$t_2$不会,因为发送的是参数,为了防止被通信阻碍,选择合适的batch使$t_1$直观上比$t_2$大20%~30%好
取max函数是因为通讯和计算是可以并行的,算一个发一个哈哈类似这种。
但是增加了以后会导致收敛变慢,所以需要更多的epoch。。。所以如果过度,反而会浪费时间,涉及到权衡的问题。

异步的通讯开销会变低。
单机内部用模型并行,一般跨机器都用数据并行
data parralel是一种并行模式,之前讲的是这种模式怎么用于单机和分布式
【沐神:假设分类的类别数是n,那么batch不要超过10*n、20*n,不过很多时候你没那么多GPU哈哈,一般是:GPU尽量加batch,然后看有多少机器,加到没有增益就算了。剩下的跑别的,也不需要全部用上。】
CV
Augmentationi
不是一件太便宜的事情,多开几个num_workers快(取决于CPU),但是windows有问题。。
训练集尽可能地模拟部署时的实际应用场景是提高模型泛化性的好方法。需要人工判断。
一般是随机的增强,在线生成,然后利用新的来训练,当然只是在训练的时候用。
上下翻转不比左右翻转,得考虑到现实中,房子、猫什么的就不能上下吧。。。当然躺着的猫也是可以上下转的。
切割:随机高宽比(不能太离谱,比如取值范围[3/4,4/3])、随机大小(有限制)、随机位置,但是形状大小要一致。
颜色:色调、饱和度、明亮度。一般取值在[0.5,1.5]之间。
对比度:
是画面黑与白的比值,也就是从黑到白的渐变层次。比值越大,从黑到白的渐变层次。比值越大,从黑到白的渐变层次就越多,从而色彩表现越丰富。亮度:
亮度指照射在景物或图像上光线的明暗程度。色调:
色调指的是一幅画中画面色彩的总体倾向,是大的色彩效果饱和度:
饱和度是指色彩的鲜艳程度,也称色彩的纯度。取决于该色中含色成分和消色成分(灰色)的比例。含色成分越大,饱和度越大
imgaug 👈 提供了一堆类似的变化。你觉得他有用,是要从部署的可能性出发的
有时候你数据增强后,测试精度可能比训练精度还高,不过仔细调整后训练精度还是会慢慢上来的。
原始图片多 $\neq$ 多样性好,还是得分析实际部署的分布。
图片增广需要大概人工看一下效果,图片增广的均值很多不变的。
马赛克:是一种遮挡,因为神经网络识别的绝大部分是纹理,特征(部位),而不是像人类一样总体识别比如一只猫
沐神也不知道为啥mix-up增广有用,但效果挺好的
图神经网络训练很难,落地挺让人头疼
微调
CV中对深度学习来讲最important的技术(迁移学习这一大类中的一种算法)


初始化最后一个分类层。【只能手动提取,嫌麻烦也可以不用,一般用的不多】
成员变量output的参数是随机初始化的,通常需要更高的学习率才能从头开始训练。 假设Trainer实例中的学习率为η,我们将成员变量output中参数的学习率设置为10η。
找pretrained的model时也得找相应领域的,判断癌症的就找医学领域的sei。
微调对学习率不敏感,可以选一个比较小的就行了,比如沐神用的e^-5
而且,这个pretrained的模型一旦弄出来,并不是只用于单任务,它实际是抽取特征,可以用到各类任务(分类、预测。。)
torchvision比较经典,但是更新不快。
目标检测
很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。 在计算机视觉里,我们将这类任务称为目标检测(object detection)或目标识别(object recognition)。
相比于图像分类,其实客户更关心的还是图像识别。
图片分类中一定有个主体,但是目标检测里面可能有多个物体,而且还要找出位置。
数据集格式

所以每行可能6个值。
输入参数boxes可以是长度为4的张量,也可以是形状为(n,4)的二维张量,其中n是边界框的数量。
目标检测领域没有像MNIST和Fashion-MNIST那样的小数据集。 为了快速测试目标检测模型,我们收集并标记了一个小型数据集。
无人车不仅仅是视觉,还有许多3D检测器,精度非常高。
首先采集一点数据出来,手标个几十几百张,然后用fine tuning训练一个模型。再用它去预测接下来很多图片,把预测不那么置信的(概率比较低的)拿出来重新标一下,重新迭代。可能最后标个几千张。但如果更高的工业需求就找人吧
几百张数据,如果能找到比较类似的预训练模型,其实已经不错了
一般我们喜欢用 ImageNet 来做网络的预训练,主要有两点,一方面 ImageNet 是图像领域里有超多事先标注好训练数据的数据集合,分量足是个很大的优势,量越大训练出的参数越靠谱;另外一方面因为 ImageNet 有 1000 类,类别多,算是通用的图像数据,跟领域没太大关系,所以通用性好,预训练完后哪哪都能用,是个万金油。分量足的万金油当然老少通吃,人人喜爱。
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。
不同的模型使用的区域采样方法可能不同。 这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。 这些边界框被称为锚框(anchor box)【目前更为主流】
预测每个锚框中是否含有关注的物体,if True,预测从该锚框到真实边缘框的偏移。
每个锚框是个训练样本,每个锚框要么标注成背景(nothing),要么关联一个真实边缘框,可能生产一堆锚框,导致大量的负样本
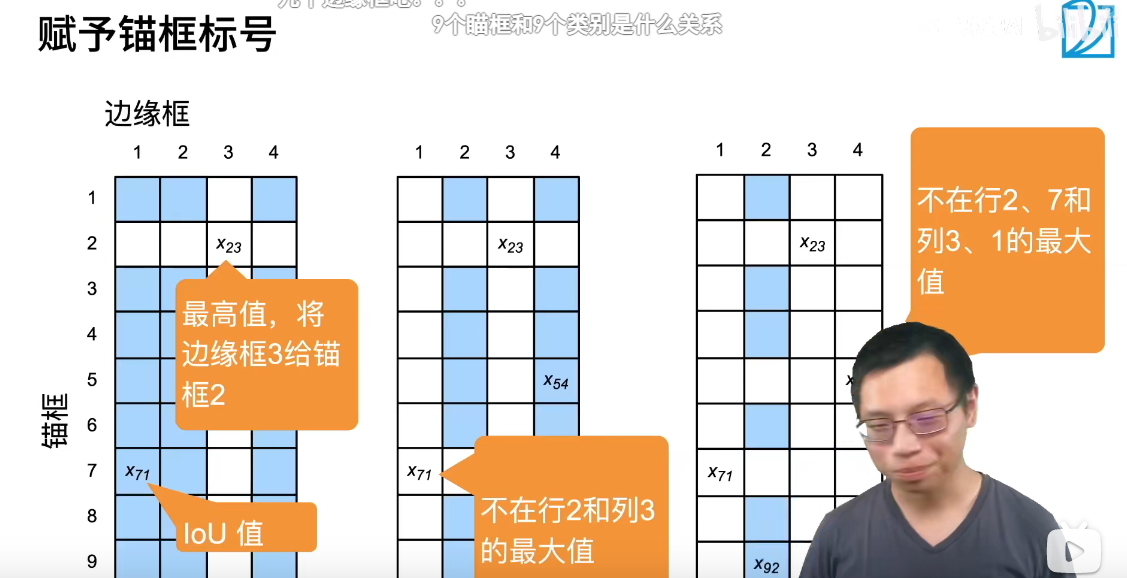
这种赋予标号的方法👆是一种常用做法。这样每个边缘框都分到一个锚框。其他都是负样本。(具体模型可能有不同方法)
NMS用于预测时去掉冗余。常用的是每一类内部处理,当然也有全部拿到一起处理的
由于锚框的引入,算法复杂度远远大于图像分类。实现起来麻烦的要死。
经典方法
R-CNN是奠基性工作 SSD YOLO 【都是基于锚框的,非锚框的工作比较新】
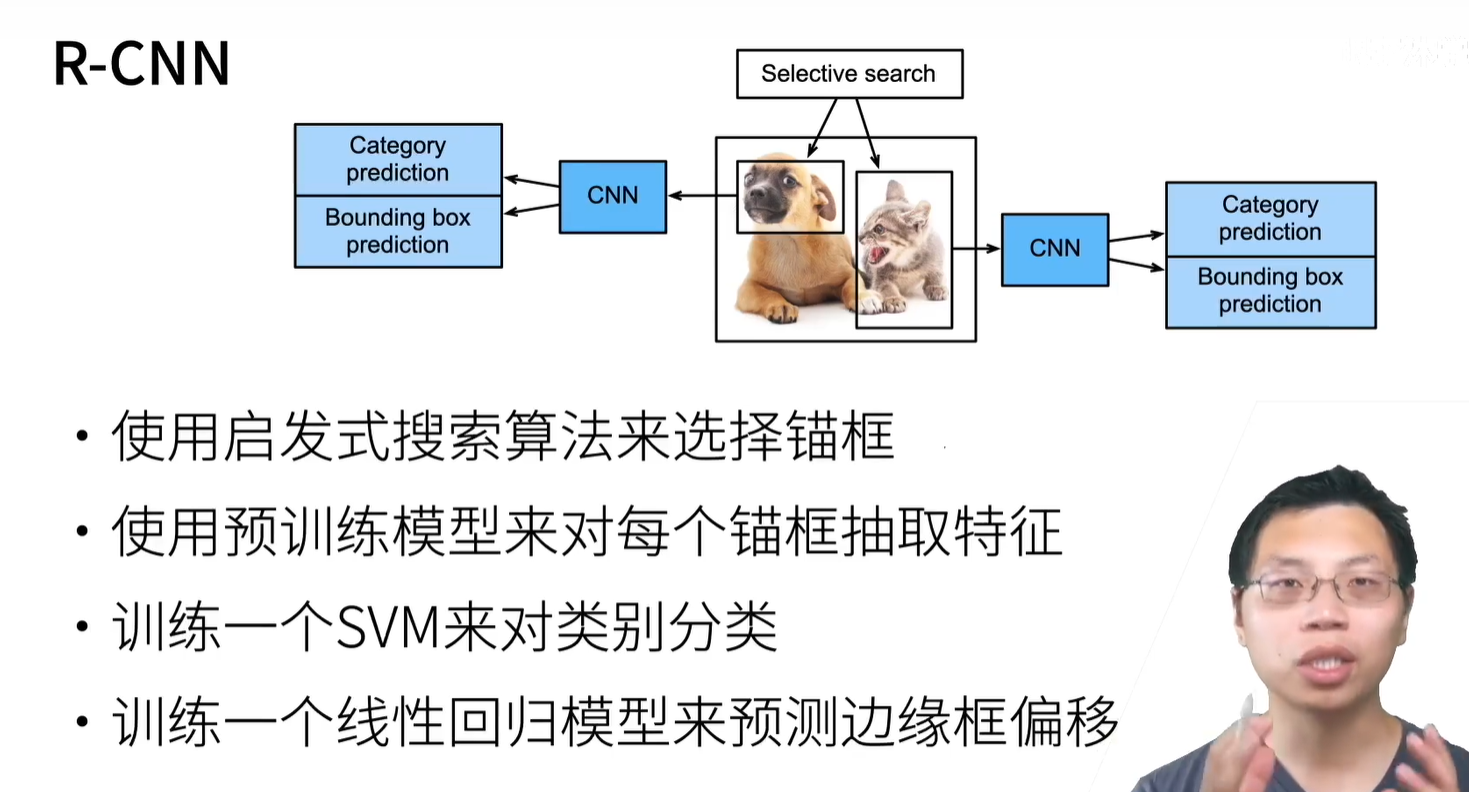
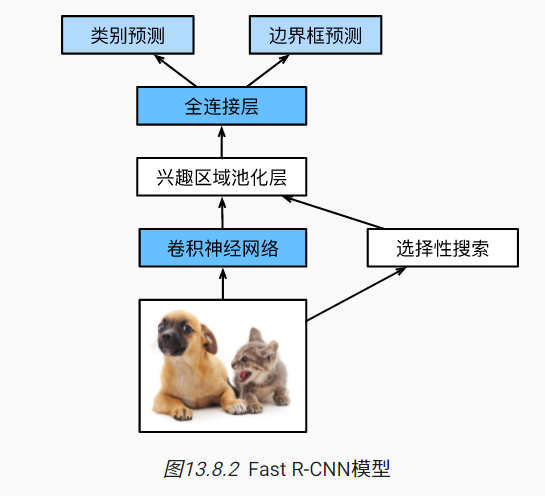
R-CNN(速度很慢)包括以下四个步骤:
- 对输入图像使用选择性搜索来选取多个高质量的提议区域 [Uijlings et al., 2013]。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框。
- 选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征。
- 将每个提议区域的特征连同其标注的类别作为一个样本。训练多个SVM对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别。
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。 由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。Fast R-CNN [Girshick, 2015]对R-CNN的主要改进之一,是仅在整张图象上执行卷积神经网络的前向传播。
- 与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是各个提议区域。此外,这个网络通常会参与训练。设输入为一张图像,将卷积神经网络的输出的形状记为$1×c×h_1×w_1$。
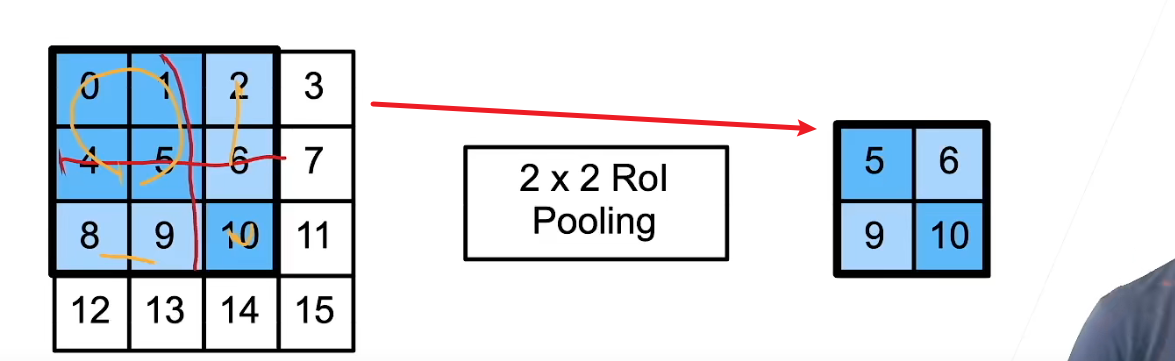
- 假设选择性搜索生成了n个提议区域。这些形状各异的提议区域在卷积神经网络的输出上分别标出了形状各异的兴趣区域。然后,这些感兴趣的区域需要进一步抽取出形状相同的特征(比如指定高度h2和宽度w2),以便于连结后输出。为了实现这一目标,Fast R-CNN引入了兴趣区域汇聚层(RoI pooling):将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征,形状为n×c×h2×w2。
- 通过全连接层将输出形状变换为n×d,其中超参数d取决于模型设计。
- 预测n个提议区域中每个区域的类别和边界框。更具体地说,在预测类别和边界框时,将全连接层的输出分别转换为形状为n×q(q是类别的数量)的输出和形状为n×4的输出。其中预测类别时使用softmax回归。
ROI:
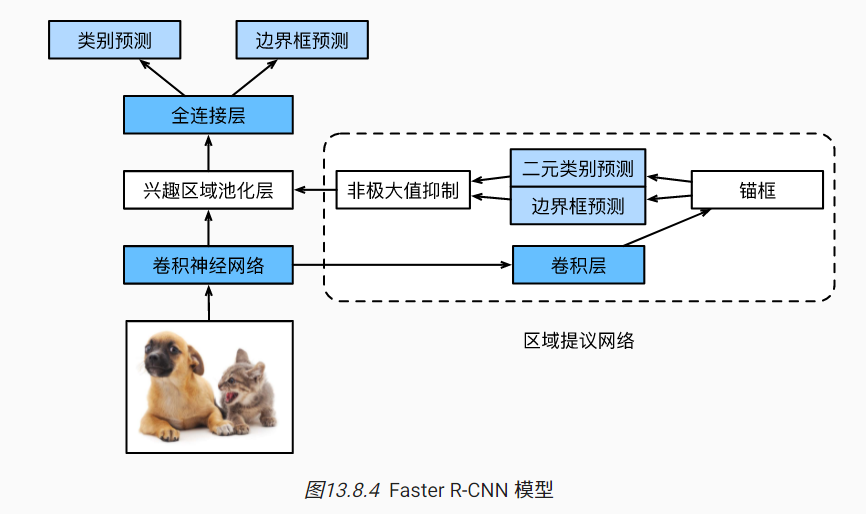
Faster R-CNN [Ren et al., 2015]提出将选择性搜索替换为区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。模型的其余部分保持不变。【先做个大概的预测,再做精准的预测】
区域提议网络的计算步骤如下:
- 使用填充为1的3×3的卷积层变换卷积神经网络的输出,并将输出通道数记为c。这样,卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为c的新特征。
- 以特征图的每个像素为中心,生成多个不同大小和宽高比的锚框并标注它们。
- 使用锚框中心单元长度为c的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
- 使用非极大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
【但是即使是Faster,也还是挺慢的】
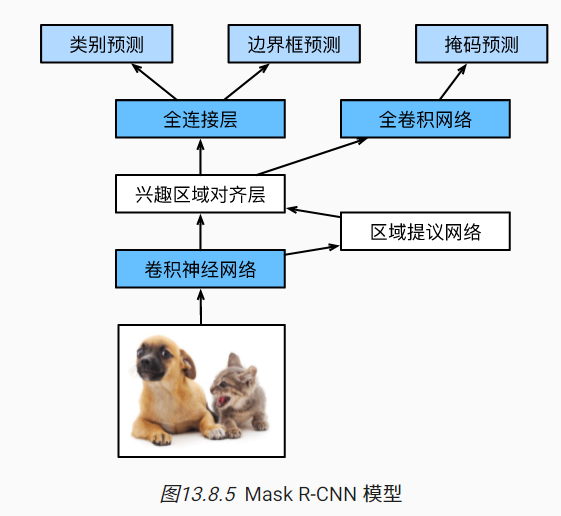
Mask R-CNN用于标注了像素级位置的情况,其他不变,双线性插值。ROI pooling换成ROI align,可以切像素,然后加权算。便于像素级别预测。在无人车领域用的比较多
这一系列,处理速度慢,精度高,内存占用高 目标检测比图片分类贵很多。
现在SSD(Single Shot MultiBox Detector)用的不那么多
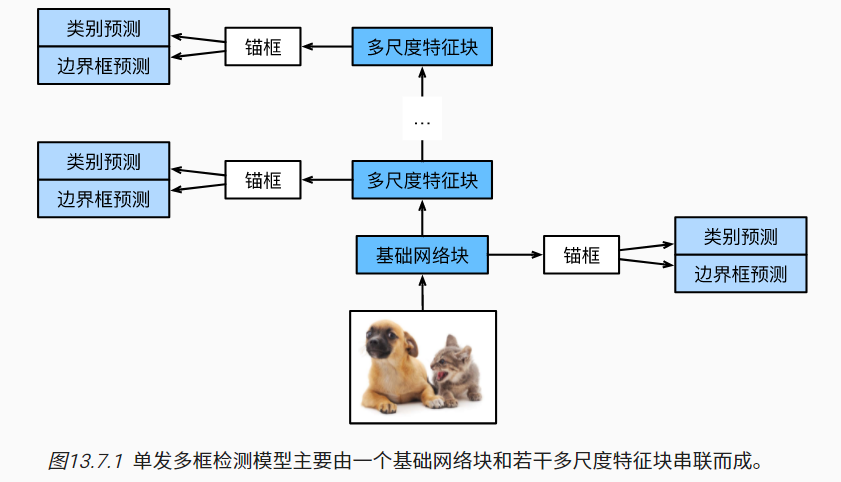
常用ResNet
可以设计基础网络,使它输出的高和宽较大。 这样一来,基于该特征图生成的锚框数量较多,可以用来检测尺寸较小的目标。
接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),特征图中每个单元在输入图像上的感受野变得更广阔。
速度比较快,精度比较低。单神经网络,一次过。
SSD没有人继续做细节更新,但实现十分简单,启发了后续工作。而且可以用python,之前的R-CNN用python实现都难。
多尺度
更低维度的空间分辨率较高,但是更局部;更高维度的空间分辨率较低,但是看到全局。
在不同的stage都做目标检测,这就是多尺度
You Only Look Once
追求速度
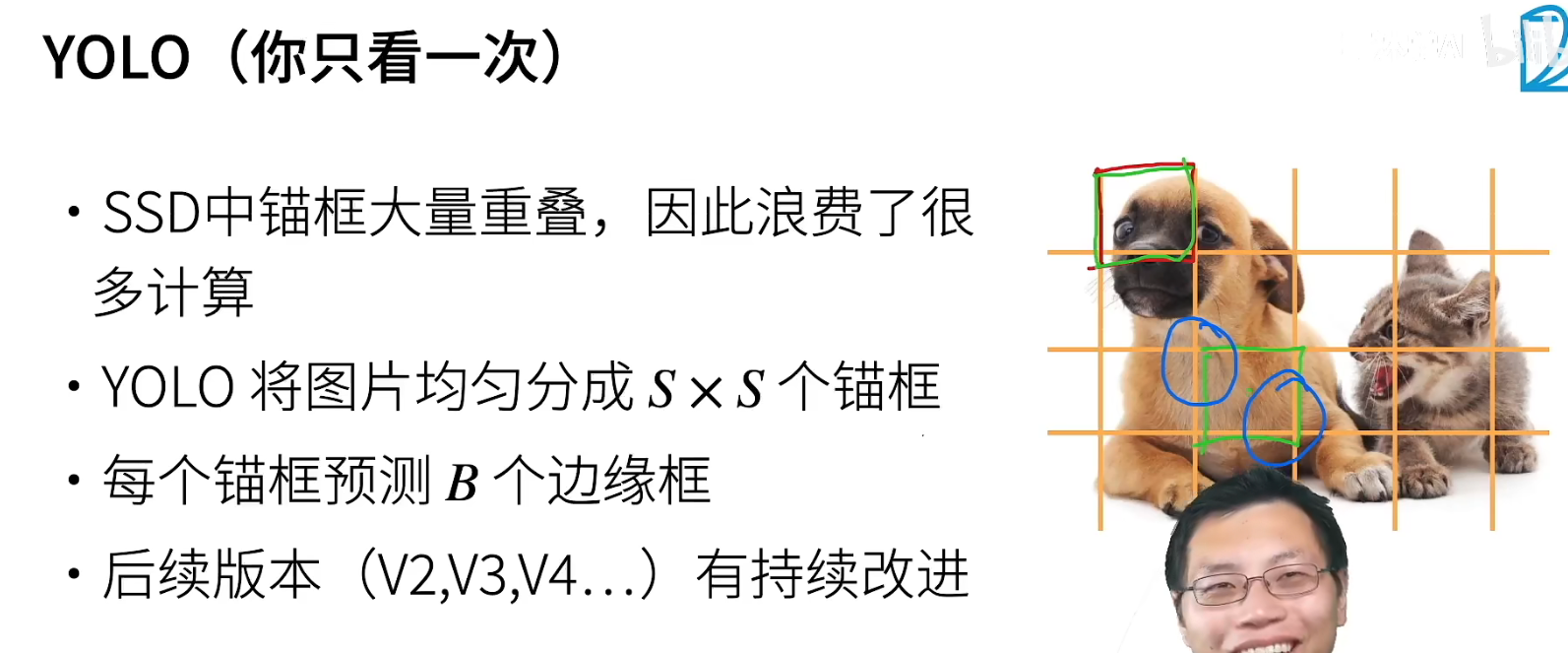
为了防止一个框中有多个物体时被漏掉,每个锚框预测B个。。
YOLO v3时,作者跑路了,然后由他的合作者接手了。加入了聚类算法,统计你数据集中检测物体的大小规律,生成针对的锚框
李沐:YOLO v3算是特别差的论文哈哈
非锚框的技术目前的发展也很迅速,什么基于像素的预测什么的(FCN)
YOLO 系列相对于RCNN精度差了一些,但是速度提高到了和SSD类似的地步(5、6倍)
对于OCR这种识别的物体特别小的,一般选择分辨率很高的图片,用R-CNN(精度较高)处理。
车牌识别已经很成熟了。
卷积、激活函数、池化组合。。。更像一门计算机语言
Attention更关注全局,CNN关注局部,这些被沐神比作流派:joy: 。。。哎老中医了,也没有好的总结。
NMS在GPU很难跑,一堆iteration比来比去。
当特征图的长宽比较小时,size一般比较大,反之比较小。
特别大的图片,SSD不那么适合。还是RCNN分开两次比较合适,或者YOLO,不管多大,锚框都不会很多。
多个loss加权相加,可以先画出来看看,然后拉到一个数量级上。
NMS的实现有许多加速的细节,不过那都是cuda干的事情了
目标检测的fine tuning一般是用图片分类的CNN模型,而cls_predict 和bbox_predict 都是随机初始化的。
pytorch也实现了,不过内部是调用的C++的代码。
嵌入式最好用YOLO。
很难公平的比较两个不一样的架构谁好谁坏,因为里面有很多tricks,最后表现的是整体的精度。最后就变成你喜欢哪个用哪个。
语义分割
常见的数据格式是VOC和COCO
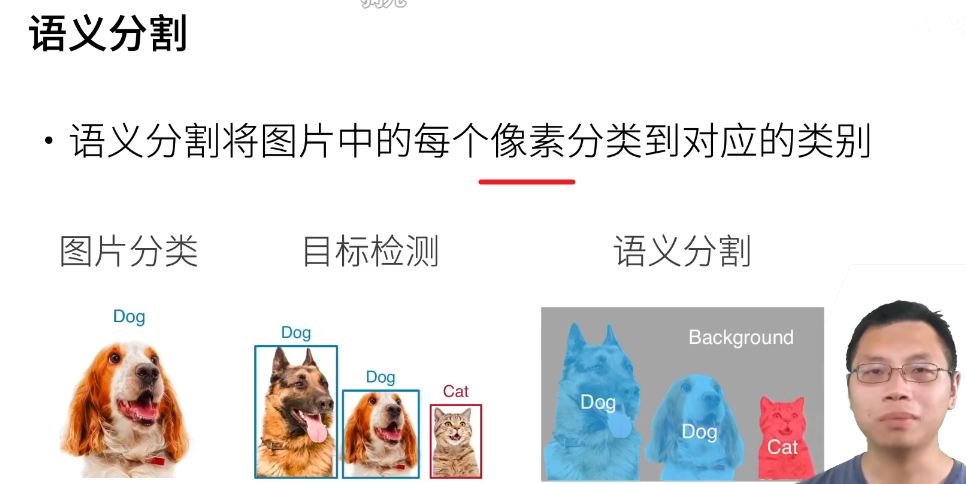
历史久远了,比如聚类,把像素聚在一起,给一个label。
语义分割属于有监督学习。应用:背景虚化、路面分割。
还有一个实例分割,不仅分割类,还检测每个实例,相当于是目标检测的进阶版。
(数据集很贵,因为很难标,所以相对数据集不大,但是无人车挺多,因为大家都不缺钱。)
更精细的语义分割,比如狗的头、身体什么的,可能存在二义性的问题,有个技术叫关键点识别。
假设目标框旋转,可以画一个大框圈出来(图像处理也有提到)
人是个比较简单的物体,做起来的难点是人的光照,形状是很容易做语义分割的。这一块能找到很好pretrained的model
3D做语义分割反而会简单很多?三维卷积
自动驾驶有几十、上百个模型一起作用,语义分割主要做路面分割,目标检测(3d)主要测前车和行人和距离、速度。
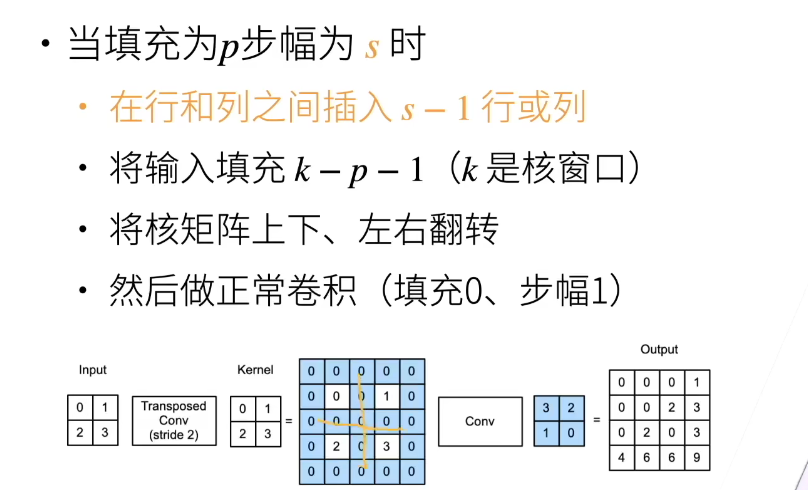
转置卷据
一般卷积不会增大输入的高宽、太大的padding是不可取的,转置卷积可以。
对于语义分割,如果高宽一直减小,最后就做不了像素级别的输出了。

这里的填充指的是输出结果的外围被视为填充,所以去掉。
卷积是为了识别local的模式,转置有点难以理解哈哈哈,可以说是特征放大?
转置卷积只还原了形状,并没有还原输出的那个值。
再谈形状:

FCN 全连接卷积神经网络时深度学习做语义分割的奠基性工作。
所以现在用的不多。但是思想比较简单
全卷积网络先使用卷积神经网络抽取图像特征,然后通过1×1卷积层将通道数变换为类别个数,最后在 13.10节中通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。模型输出与输入图像的高和宽相同,且最终输出通道包含了该空间位置像素的类别预测。
最后一层前加一个1x1卷积层把通道个数减一减,方便运算,这个操作舍弃精度追求速度。
一般,用来放大的转置卷积层的初始化采用双线性插值,效果上相当于把图片放大了两倍。
UNet用了更多的层,还有许多其他工作。
风格迁移
没有什么商业价值,大家也就玩一玩。GAN的商业价值虽然在提升,但仍然整体不大
滤波器能改变照片的颜色风格,从而使风景照更加锐利或者令人像更加美白。但一个滤波器通常只能改变照片的某个方面。如果要照片达到理想中的风格,你可能需要尝试大量不同的组合。这个过程的复杂程度不亚于模型调参。
同样讲的是奠基性的工作,基于CNN
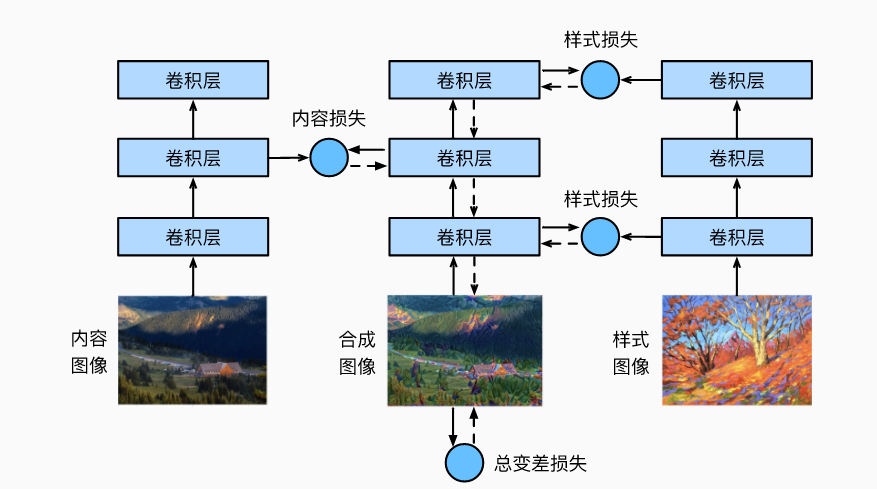
越靠近输入层,越容易抽取图像的细节信息;反之,则越容易抽取图像的全局信息。
为了避免合成图像过多保留内容图像的细节,我们选择VGG较靠近输出的层,即内容层,来输出图像的内容特征。 我们还从VGG中选择不同层的输出来匹配局部和全局的风格,这些图层也称为风格层。
style_layers, content_layers = [0, 5, 10, 19, 28], [25]
用统计信息来表征风格,那么各阶统计量的差异可用来衡量loss【统计直方图包含高阶信息,Gram和协方差有两阶】
假设该输出的样本数为1,通道数为c,高和宽分别为h和w,我们可以将此输出转换为矩阵X,其有c行和hw列。 这个矩阵可以被看作是由c个长度为hw的向量x1,…,xc组合而成的。其中向量$x_i$代表了通道i上的风格特征。
在这些向量的格拉姆矩阵XX⊤∈Rc×c中,i行j列的元素xij即向量xi和xj的内积。它表达了通道i和通道j上风格特征的相关性。我们用这样的格拉姆矩阵来表达风格层输出的风格。 需要注意的是,当hw的值较大时,格拉姆矩阵中的元素容易出现较大的值。 此外,格拉姆矩阵的高和宽皆为通道数c。 为了让风格损失不受这些值的大小影响,格拉姆矩阵除以矩阵中元素的个数,即chw
全变分去噪(total variation denoising) 假设xi,j表示坐标(i,j)处的像素值,降低全变分损失
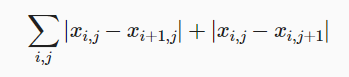
能够尽可能使邻近的像素值相似。
格拉姆矩阵可以看做feature之间的偏心协方差矩阵(即没有减去均值的协方差矩阵),在feature map中,每个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字代表一个特征的强度,而Gram计算的实际上是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等。
风格转移的损失函数是内容损失、风格损失和总变化损失的加权和。 通过调节这些权重超参数,我们可以权衡合成图像在保留内容、迁移风格以及去噪三方面的相对重要性。
在风格迁移中,合成的图像是训练期间唯一需要更新的变量。因此,我们可以定义一个简单的模型SynthesizedImage,并将合成的图像视为模型参数。模型的前向传播只需返回模型参数即可。
可以初始化为风格图片或内容图片。
训练大图片的小技巧:先把原图片缩小,训练一下,再放大继续训练,甚至切割分别训练
后来用GAN来做这个事情,不用每次都训练
Kaggle
第一次
房价预测:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
直观地说,我们标准化数据有两个原因: 首先,它方便优化。 其次,因为我们不知道哪些特征是相关的, 所以我们不想让惩罚分配给一个特征的系数比分配给其他任何特征的系数更大。
pandas的dataframe,如果索引中不用切片用单个数字,此时选的是列,方便却容易混淆。
torch.clamp(input, min, max, out=None) → Tensor
| min, if x_i < min
y_i = | x_i, if min <= x_i <= max
| max, if x_i > max如果预测的值的范围很大,RMSE 会被一些大的值主导。这样即使你很多小的值预测准了,但是有一个非常大的值预测的不准确,RMSE 就会很大。 相应的,如果另外一个比较差的算法对这一个大的值准确一些,但是很多小的值都有偏差,可能 RMSE 会比前一个小。先取 log 再求 RMSE(就是),可以稍微解决这个问题。RMSE 一般对于固定的平均分布的预测值才合理。
框架的延后初始化(defers initialization), 即直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小。
在以后,当使用卷积神经网络时, 由于输入维度(即图像的分辨率)将影响每个后续层的维数, 有了该技术将更加方便。 现在我们在编写代码时无须知道维度是什么就可以设置参数, 这种能力可以大大简化定义和修改模型的任务。 接下来,我们将更深入地研究初始化机制。
如果【数据区间比较大,且全为正数】,可以用log,再做均值初始化可以压缩到很好的区间。
在设备(CPU、GPU和其他机器)之间传输数据比计算慢得多。 这也使得并行化变得更加困难,因为我们必须等待数据被发送(或者接收), 然后才能继续进行更多的操作。 这就是为什么拷贝操作要格外小心。
CPU,GPU注意降温,不要超过80
把GPU的性能留给前向、反向运算,前面的操作在CPU完成。
GPU使用60%都已经不算低了。CNN可能更高,容易dao80-90%
Adam对初始学习率相对不敏感。
𝐾折交叉验证往往对多次测试具有相当的稳定性。 然而,如果我们尝试了不合理的超参数,我们可能会发现验证效果不再代表真正的误差。
较少的过拟合可能表明现有数据可以支撑一个更强大的模型, 较大的过拟合可能意味着我们可以通过正则化技术来获益。
可以用少量的数据找到超参数的大致范围,然后在整个数据集上跑几轮找到精确的。
automl真的可能取代20%的调参,但是这还是得学习。80%:分析哪些数据对目标有用,搜集数据,清理数据。。。
你的价值体现在automl不能做的,你要做的更好,学习的知识是指数增长的。
世界变得很快,得要学会理论和实践的范式和能力。
当你调到一个比较好的参数点时,可以上下修改一下,如果结果剧烈波动,可能就调在了噪音上,泛化性不好。
李沐:实际中调参其实没有那么重要(竞赛除外),精度还可以就行,因为数据在不断变化。
随时思考,如何成长——李沐的梯度下降
第二次
树叶分类:https://www.kaggle.com/c/classify-leaves/data
少量高质量数据,可能有个百倍的换算。
所以不建议过度调参,这可能会overfit到目前的数据,实际场景中你可能会有越来越多的数据。(除非竞赛)
w = w-lr*w.grad 这样按照python的,左边是一个新的变量,没有attach gradient,梯度计算出问题。
机器学习老中医,深度学习炼丹哈哈哈哈哈。
第三次
cifar-10图像识别:https://www.kaggle.com/c/cifar-10
torchvision的更新没那么快,但是也不错。
#读了一个csv文件
def read_csv_labels(fname):
"""读取fname来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
lines = f.readlines()[1:]# 跳过文件头行(列名)
tokens = [l.rstrip().split(',') for l in lines]#每行是一个列表
return dict(((name, label) for name, label in tokens))#转换成一个字典以供方便使用
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
#{'1': 'frog', '2': 'truck', '3': 'truck',....}这里使用的是最简单的图片数据集组织格式,也就是imagefolder这个iterator,因此需要我们提前分好数据。
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
def reorg_train_valid(data_dir, labels, valid_ratio):
"""将验证集从原始的训练集中拆分出来"""
# 训练数据集中样本最少的类别中的样本数,这个Counter好用
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的样本数
n_valid_per_label = max(1, math.floor(n * valid_ratio))
label_count = {}
for train_file in os.listdir(os.path.join(data_dir, 'train')):
label = labels[train_file.split('.')[0]]#获得文件名对应的标签
fname = os.path.join(data_dir, 'train', train_file)#获得路径
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label))
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label))
label_count[label] = label_count.get(label, 0) + 1
else:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label))
return n_valid_per_label
def reorg_test(data_dir):
"""在预测期间整理测试集,以方便读取"""
for test_file in os.listdir(os.path.join(data_dir, 'test')):
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test',
'unknown'))
#scheduler是对学习率的调整,沐神说比较好的是cos,👇这个用的挺多。
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
在完成一个迭代的训练后要加上 scheduler.step()
#重新训练,将pred放到cpu上,以及编制索引提交
net, preds = get_net(), []
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)
for X, _ in test_iter:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
df.to_csv('submission.csv', index=False)沐神:这其实是一个比较蠢的办法,因为copy了一大坨图片两次,数据如果多一点那就是很大量的复制,浪费空间和时间。在实际中通常自己写个classdata (没听清)iterator,而图片不需要动。
但如果图片数量不大,其实挺推荐,因为简单,而且方便鼠标点进去自己查看,很多框架都支持这样的组织方式。
lr-decay会让你的精度提高一些比如0.7->0.75,但不会有非常显著的提升
SGD本身就做了很强的正则,有很多噪音在里面,所以很稳定。
第四次
ImageNet-Dog分类:https://www.kaggle.com/c/dog-breed-identification
学术数据集注重的是通用性,业务注重客户关注的实用性。
#冻结参数,以及Sequential的使用特性。
def get_net(devices):
finetune_net = nn.Sequential()#这应该是定义了lei
finetune_net.features = torchvision.models.resnet34(pretrained=True)
# 定义一个新的输出网络,共有120个输出类别
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),
nn.ReLU(),
nn.Linear(256, 120))
# 将模型参数分配给用于计算的CPU或GPU
finetune_net = finetune_net.to(devices[0])
# 冻结参数
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
#train里面也要改
trainer = torch.optim.SGD((param for param in net.parameters()
if param.requires_grad), lr=lr,
momentum=0.9, weight_decay=wd)
#经典evaluate
def evaluate_loss(data_iter, net, devices):
l_sum, n = 0.0, 0
for features, labels in data_iter:
features, labels = features.to(devices[0]), labels.to(devices[0])
outputs = net(features)
l = loss(outputs, labels)
l_sum += l.sum()
n += labels.numel()
return (l_sum / n).to('cpu')这次输出用的是softmax(题目要求的输出格式),这样可以研究top-5,即正确样本在不在预测前五里。
一般对于十分复杂,类别非常多的数据集(标号长得一样),大家更关心top-5.
老中医的丹方:先resize到256,再中心剪裁到224.
专家调参是非线性,靠手气哈哈,一般效率比机器调参要高一些。但还是得比较成本。
从长远趋势来看,最后肯定是机器自动调参的。
目前你还是可以练练调参,是个手艺活,能加深理解。没有特别好的系统学习方案,慢慢积累
trick不是长久的。
Recurrent
到目前为止我们默认数据都来自于某种分布, 并且所有样本都是独立同分布的 (independently and identically distributed,i.i.d.)。 然而,大多数的数据并非如此。 例如,文章中的单词是按顺序写的,如果顺序被随机地重排,就很难理解文章原始的意思。
两种方案:
- 通常做马尔可夫假设的自回归,仅关注定长的过去信息,可用之前的技术实现。
- 潜变量自回归,研究两个模型,如何根据上一个输入$x_{t-1}$和之前的时序信息$h_{t-1}$得到现在的时序信息$h_t$,以及如何用现在的$h_t$加上上一个输入$x_{t-1}$得到最新的预测$x_t$(这里引出了因果推理 casual - inference)
第一种方案沐神用MLP做了演示,给定四个输入,看看不同步数的预测:
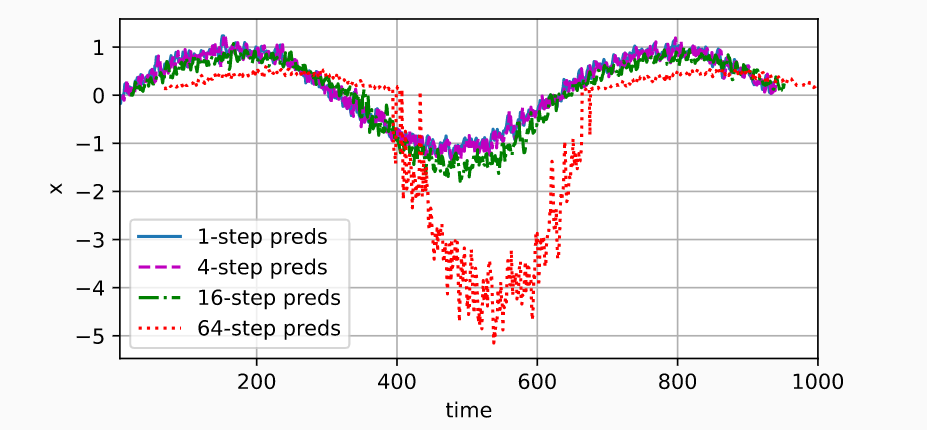
可以看到,即使是简单的函数(sinx),预测未来也很难。事实是由于错误的累积
隐变量是个真实存在的东西,只是没有被观察到。潜变量包括了隐变量,但也可能真的不存在,比如聚类的类信息,是现实不存在的,怎么改进sensor都观察不到。
$\tau$的选择,有一些平滑的衰减方法。因果分析最近在统计界和机器学习界都挺火的。
RNN也能记住所有的序列,而且比MLP更强大,但这不见得是一件很好的事情
可以把时序信息,看作是一维的信息量,1-D卷积也能用,效果不见得比RNN差
中文分词是非常不容易的哈哈,曾经NLP里中文分词也是一大块。比较好的开源有jieba
文本预处理
一篇文章可以被简单地看作是一串单词序列,甚至是一串字符序列。 现实中的文档集合可能会包含数十亿个单词。
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元(如单词和字符)。词元(token)是文本的基本单位
- 建立一个词表(vocab),将拆分的词元映射到数字索引。
我们先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)。 然后根据每个唯一词元的出现频率,为其分配一个数字索引。 很少出现的词元通常被移除,这可以降低复杂性。
另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“”。 我们可以选择增加一个列表,用于保存那些被保留的词元, 例如:填充词元(“ ”); 序列开始词元(“ ”); 序列结束词元(“ ”)。 - 将文本转换为数字索引序列,方便模型操作。
训练集和测试时用的vocab必须是同一个。
文本序列
语言模型(language model)的目标是估计序列的联合概率 P(x1,x2,…,xT)
例如,只需要一次抽取一个词元xt∼P(xt∣xt−1,…,x1),一个理想的语言模型就能够基于模型本身生成自然文本。
从这样的模型中提取的文本 都将作为自然语言(例如,英语文本)来传递。 只需要基于前面的对话片断中的文本, 就足以生成一个有意义的对话。 显然,我们离设计出这样的系统还很遥远, 因为它需要“理解”文本,而不仅仅是生成语法合理的内容。

尽管如此,语言模型依然是非常有用的。

训练数据集中,词的概率可以根据给定词的相对词频来计算。一种(稍稍不太精确的)方法是统计单词“deep”在数据集中的出现次数, 然后将其除以整个语料库中的单词总数。 这种方法效果不错,特别是对于频繁出现的单词。
但对于稍长的单词对,以及不常见的单词,情况将会变得很糟,即使 用了拉普拉斯平滑。该模型仅简单统计看到的单词的频率,想根据上下文调整这类模型其实是相当困难的。 最后,长单词序列大部分是没出现过的, 因此一个模型如果只是简单地统计先前“看到”的单词序列频率, 那么模型面对这种问题肯定是表现不佳的。

比如二元语法,1000个词,那就存1000*1000个可能性。。。这会带来内存的问题,但是计算复杂度直接降为$O(t)$
二元和三元用的还是非常多的!!一般语料库几十G….几百G【因为满足👇,节省了很多内存】
词频特征:
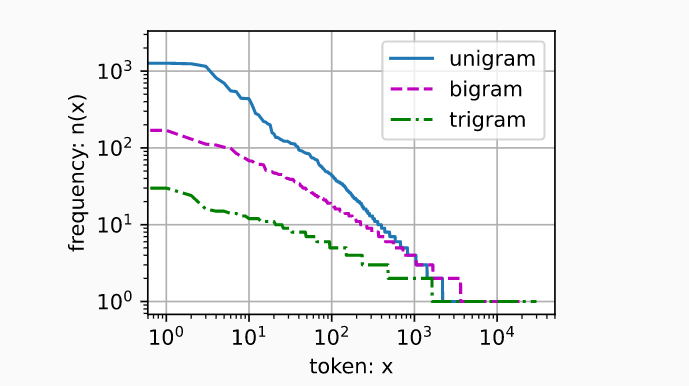

词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构, 这些结构给了我们应用模型的希望。
很多n元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。 作为代替,我们将使用基于深度学习的模型 RNN
sequence sample 的时间跨度T取决于对一句话建模还是一段话建模。16,32,64,128都有,再长也能到512,我肯定到不了。不是每个模型都能支撑那么大的,取决于模型复杂的,还有一些线上的参数。
【一个发现:batch中的数据是并行的,在RNN有了显式体现,顺序分区时,每个batch的第一个序列是连续的,第一个和第二个和其他则没有关系,有点离谱】
RNN
输出发生在观察之前。
困惑度👇:一个更好的语言模型应该能让我们更准确地预测下一个词元。 因此,它应该允许我们在压缩序列时花费更少的比特。


这里的g是所有层的梯度放在一起。通过这样做,我们知道梯度范数永远不会超过θ, 并且更新后的梯度完全与g的原始方向对齐。
它还有一个值得拥有的副作用, 即限制任何给定的小批量数据(以及其中任何给定的样本)对参数向量的影响, 这赋予了模型一定程度的稳定性。 梯度裁剪提供了一个快速修复梯度爆炸的方法, 虽然它并不能完全解决问题,但它是众多有效的技术之一。
困惑度的最好的理解是“下一个词元的实际选择数的调和平均数”。这使得不同长度的文档的性能具有了可比性。 我们看看一些案例:
- 在最好的情况下,模型总是完美地估计标签词元的概率为1。 在这种情况下,模型的困惑度为1。
- 在最坏的情况下,模型总是预测标签词元的概率为0。 在这种情况下,困惑度是正无穷大。
- 在基线上,该模型的预测是词表的所有可用词元上的均匀分布。 在这种情况下,困惑度等于词表中唯一词元的数量。 事实上,如果我们在没有任何压缩的情况下存储序列, 这将是我们能做的最好的编码方式。 因此,这种方式提供了一个重要的下限, 而任何实际模型都必须超越这个下限。
transformer出来以后NLP这块飞速进步,现在各大厂家在刷transomer的pretrained模型。
多模态:发现transfomer既能做image也能做文本,用一个大模型直接一起搞了。
视频tracking是一个非常成熟的领域,做的非常好了,不需要太多RNN的东西,倒是那些小波滤波器用的比较多
一般RNN的序列都是随机取,RNN不足以记住太长的序列,一般100以内。这个样本撑不起来单词
高频字符低采样是?
完全计算
这样的计算非常缓慢,并且可能会发生梯度爆炸, 因为初始条件的微小变化就可能会对结果产生巨大的影响。 也就是说,我们可以观察到类似于蝴蝶效应的现象, 即初始条件的很小变化就会导致结果发生不成比例的变化。 这对于我们想要估计的模型而言是非常不可取的。 毕竟,我们正在寻找的是能够很好地泛化高稳定性模型的估计器。 因此,在实践中,这种方法几乎从未使用过。
截断时间步
这会带来真实梯度的近似, 只需将求和终止为∂ht−τ/∂wh。 在实践中,这种方式工作得很好。 它通常被称为截断的通过时间反向传播 [Jaeger, 2002]。 这样做导致该模型主要侧重于短期影响,而不是长期影响。 这在现实中是可取的,因为它会将估计值偏向更简单和更稳定的模型。
虽然随机截断在理论上具有吸引力, 但很可能是由于多种因素在实践中并不比常规截断更好。 首先,在对过去若干个时间步经过反向传播后, 观测结果足以捕获实际的依赖关系。 其次,增加的方差抵消了时间步数越多梯度越精确的事实。 第三,我们真正想要的是只有短范围交互的模型。 因此,模型需要的正是截断的通过时间反向传播方法所具备的轻度正则化效果。
反向传播
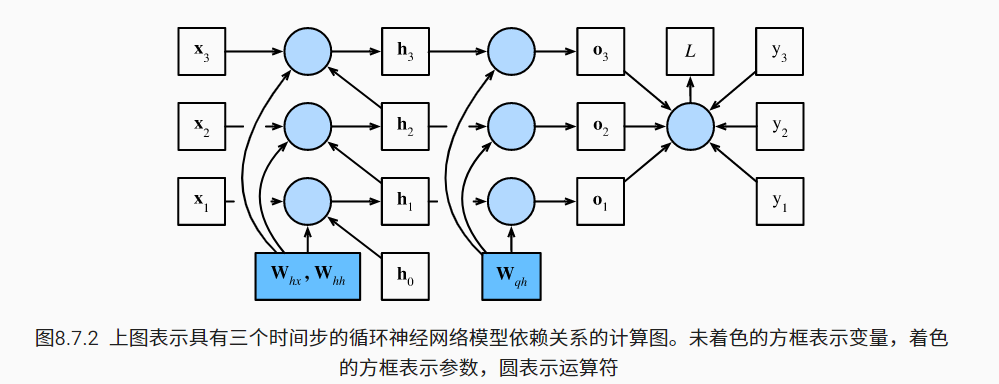
该例子👇,激活函数实用恒等映射。

 此处可见一斑,出现了W的$T-i$次幂,容易发生数据不稳定
此处可见一斑,出现了W的$T-i$次幂,容易发生数据不稳定
Modern
梯度异常在实践中的意义:
- 我们可能会遇到这样的情况:早期观测值对预测所有未来观测值具有非常重要的意义。 考虑一个极端情况,其中第一个观测值包含一个校验和, 目标是在序列的末尾辨别校验和是否正确。 在这种情况下,第一个词元的影响至关重要。 我们希望有某些机制能够在一个记忆元里存储重要的早期信息。 如果没有这样的机制,我们将不得不给这个观测值指定一个非常大的梯度, 因为它会影响所有后续的观测值。
- 我们可能会遇到这样的情况:一些词元没有相关的观测值。 例如,在对网页内容进行情感分析时, 可能有一些辅助HTML代码与网页传达的情绪无关。 我们希望有一些机制来跳过隐状态表示中的此类词元。
- 我们可能会遇到这样的情况:序列的各个部分之间存在逻辑中断。 例如,书的章节之间可能会有过渡存在, 或者证券的熊市和牛市之间可能会有过渡存在。 在这种情况下,最好有一种方法来重置我们的内部状态表示。
GRU
门控循环单元与普通的循环神经网络之间的关键区别在于: 后者支持隐状态的门控。 这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。
重置门(reset gate)和更新门(update gate)。 我们把它们设计成(0,1)(0,1)区间中的向量, 这样我们就可以进行凸组合。
- Reset 是看要不要reset旧状态;有助于捕获序列中的短期依赖关系。允许我们控制“可能还想记住”的过去状态的数量;
- Update是看目前的状态要不要用候选的隐状态update,还是不变。有助于捕获序列中的长期依赖关系。更新门将允许我们控制新状态中有多少是旧状态的副本。用tanh作激活函数是当时relu还没出来哈哈
虽然矩阵乘法比RNN多三倍,但性能没有降低太多,可以通过大量并行打高GPU
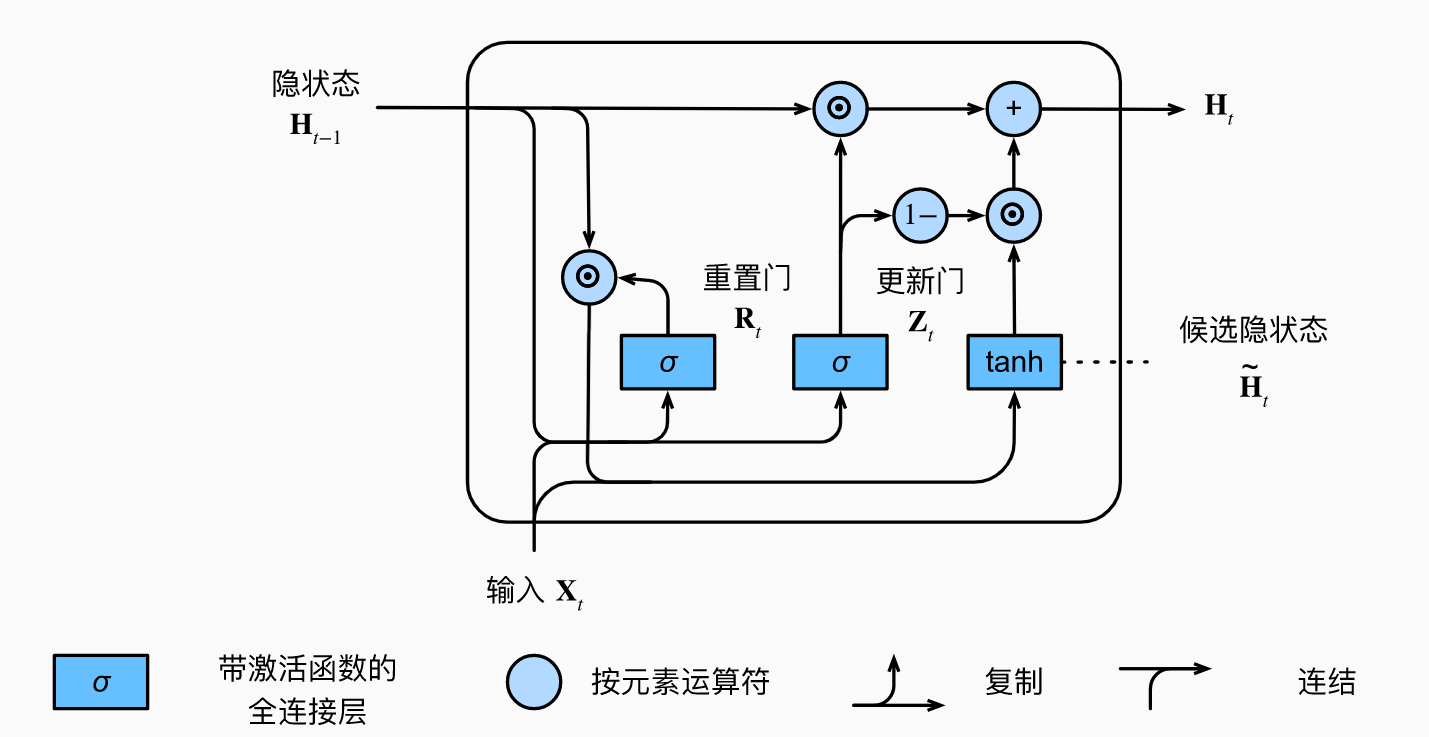 $$
\begin{split}\begin{aligned}
\mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1} \mathbf{W}_{hr} + \mathbf{b}_r),\\
\mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{t-1} \mathbf{W}_{hz} + \mathbf{b}_z),\\
\tilde{\mathbf{H}}_t = \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h),\\
\mathbf{H}_t = \mathbf{Z}_t \odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t.
\end{aligned}\end{split}\\
$$
$$
\begin{split}\begin{aligned}
\mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1} \mathbf{W}_{hr} + \mathbf{b}_r),\\
\mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{t-1} \mathbf{W}_{hz} + \mathbf{b}_z),\\
\tilde{\mathbf{H}}_t = \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h),\\
\mathbf{H}_t = \mathbf{Z}_t \odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t.
\end{aligned}\end{split}\\
$$
LSTM
Hinton和LSTM作者一直有矛盾
LSTM的很多设计,其实大家也不知道为什么,那就不纠结了,反正效果挺好的。
深度循环神经网络使用多个隐藏层来获得更多非线性信息。
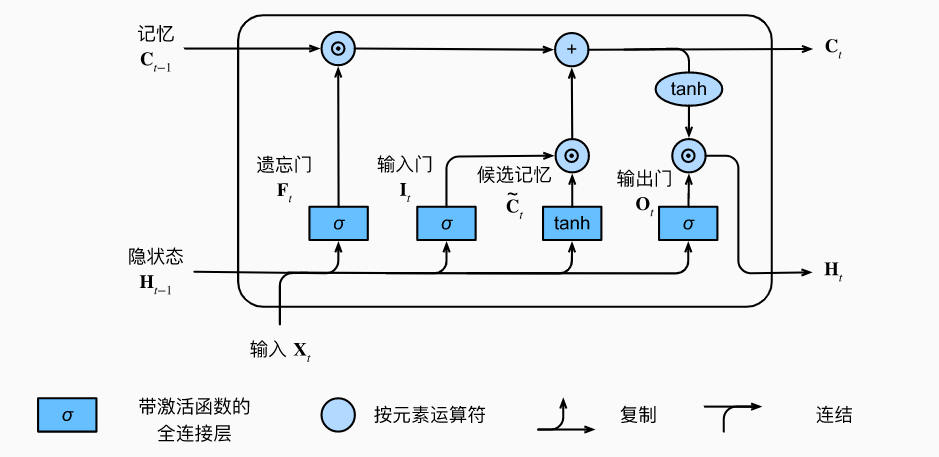
输入门$I_t$控制采用多少来自候选记忆元的新数据, 而遗忘门$F_t$控制保留多少过去的 记忆元
所以LSTM有两个隐变量:记忆元和隐状态
$$
\begin{split}\begin{aligned}
\mathbf{I}t &= \sigma(\mathbf{X}t \mathbf{W}{xi} + \mathbf{H}{t-1} \mathbf{W}_{hi} + \mathbf{b}i),\
\mathbf{F}t &= \sigma(\mathbf{X}t \mathbf{W}{xf} + \mathbf{H}{t-1} \mathbf{W}{hf} + \mathbf{b}f),\
\mathbf{O}t &= \sigma(\mathbf{X}t \mathbf{W}{xo} + \mathbf{H}{t-1} \mathbf{W}{ho} + \mathbf{b}o),\
\tilde{\mathbf{C}}t = \text{tanh}(\mathbf{X}t \mathbf{W}{xc} + \mathbf{H}{t-1} \mathbf{W}{hc} + \mathbf{b}_c),\
\mathbf{C}_t = \mathbf{F}t \odot \mathbf{C}{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t\
\mathbf{H}_t = \mathbf{O}_t \odot \tanh(\mathbf{C}_t).
\end{aligned}\end{split}
$$
上面$C_t$范围可以做的比较大,没有数值限制,所以再用一次tanh化到正负一间保证H一直在正负一。
RNN GRU LSTM,其实区别就在于怎么更新隐状态H
文本远远多于图片,也是目前的主流交互方式,NLP整体找工作很好找,比如文本分类、tag,summarization
但是文本翻译已经很成熟了。
RNN pro
深度RNN
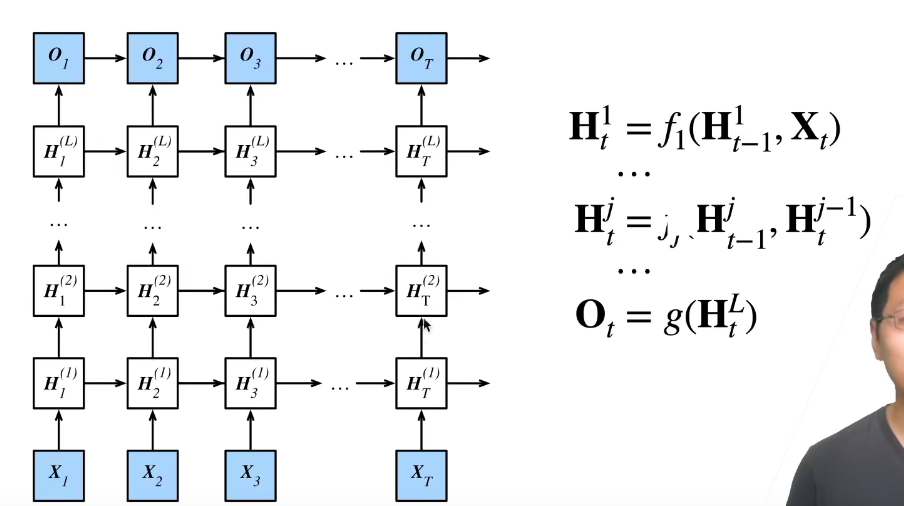
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)加个num_layers就行了
双向RNN
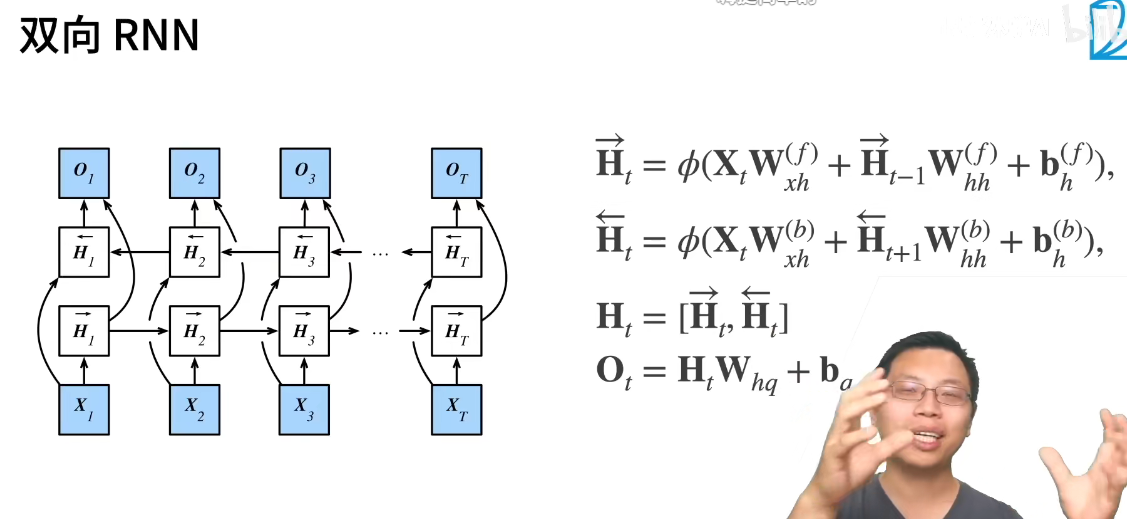
双向RNN非常不适合做推理,几乎不能预测下一个词,因为要同时看到上下文。
所以主要应用是对句子做特征提取。比如语音等你一句话说完,翻译后来回扫一扫确认语义给你。
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
正向和反向没有权重这一说,是用concat连在一起的平级参数。
编码器和解码器
机器翻译
语言模型是自然语言处理的关键, 而机器翻译是语言模型最成功的基准测试。 因为机器翻译正是将输入序列转换成输出序列的 序列转换模型(sequence transduction)的核心问题。 序列转换模型在各类现代人工智能应用中发挥着至关重要的作用
机器翻译(machine translation)指的是 将序列从一种语言自动翻译成另一种语言。在使用神经网络进行端到端学习的兴起之前, 统计学方法在这一领域一直占据主导地位。
神经网络机器翻译方法,强调的是端到端的学习。
在机器翻译中,我们更喜欢单词级词元化 (最先进的模型可能使用更高级的词元化技术)其中每个词元要么是一个词,要么是一个标点符号。
机器翻译数据集由语言对组成, 因此我们可以分别为源语言和目标语言构建两个词表。 使用单词级词元化时,词表大小将明显大于使用字符级词元化时的词表大小。
为了缓解这一问题,这里我们将出现次数少于2次的低频率词元 视为相同的未知(“”)词元。
除此之外,我们还指定了额外的特定词元, 例如在小批量时用于将序列填充到相同长度的填充词元(“”), 以及序列的开始词元(“ ”)和结束词元(“ ”)。 这些特殊词元在自然语言处理任务中比较常用。 语言模型中的序列样本都有一个固定的长度, 无论这个样本是一个句子的一部分还是跨越了多个句子的一个片断。 这个固定长度是由 8.3节中的
num_steps(时间步数或词元数量)参数指定的。
为了提高计算效率,我们仍然可以通过截断(truncation)和 填充(padding)方式实现一次只处理一个小批量的文本序列。 假设同一个小批量中的每个序列都应该具有相同的长度num_steps, 那么如果文本序列的词元数目少于num_steps时, 我们将继续在其末尾添加特定的“”词元, 直到其长度达到 num_steps; 反之,我们将截断文本序列时,只取其前num_steps个词元, 并且丢弃剩余的词元。这样,每个文本序列将具有相同的长度, 以便以相同形状的小批量进行加载。我们将特定的“
”词元添加到所有序列的末尾, 用于表示序列的结束。 当模型通过一个词元接一个词元地生成序列进行预测时, 生成的“ ”词元说明完成了序列输出工作。 此外,我们还记录了每个文本序列的长度, 统计长度时排除了填充词元, 在稍后将要介绍的一些模型会需要这个长度信息。
:star2:
最近几年影响比较深的对模型的抽象。
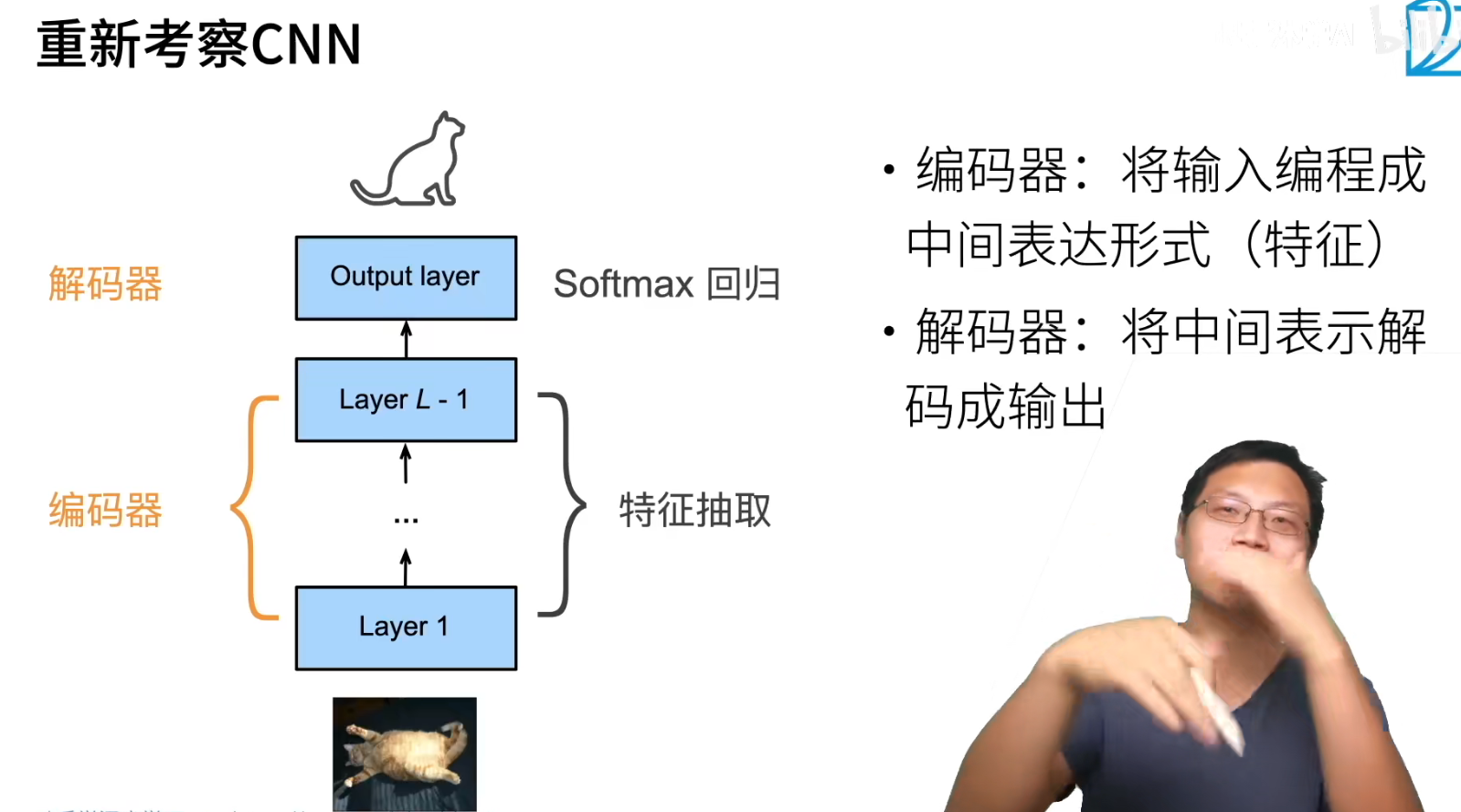
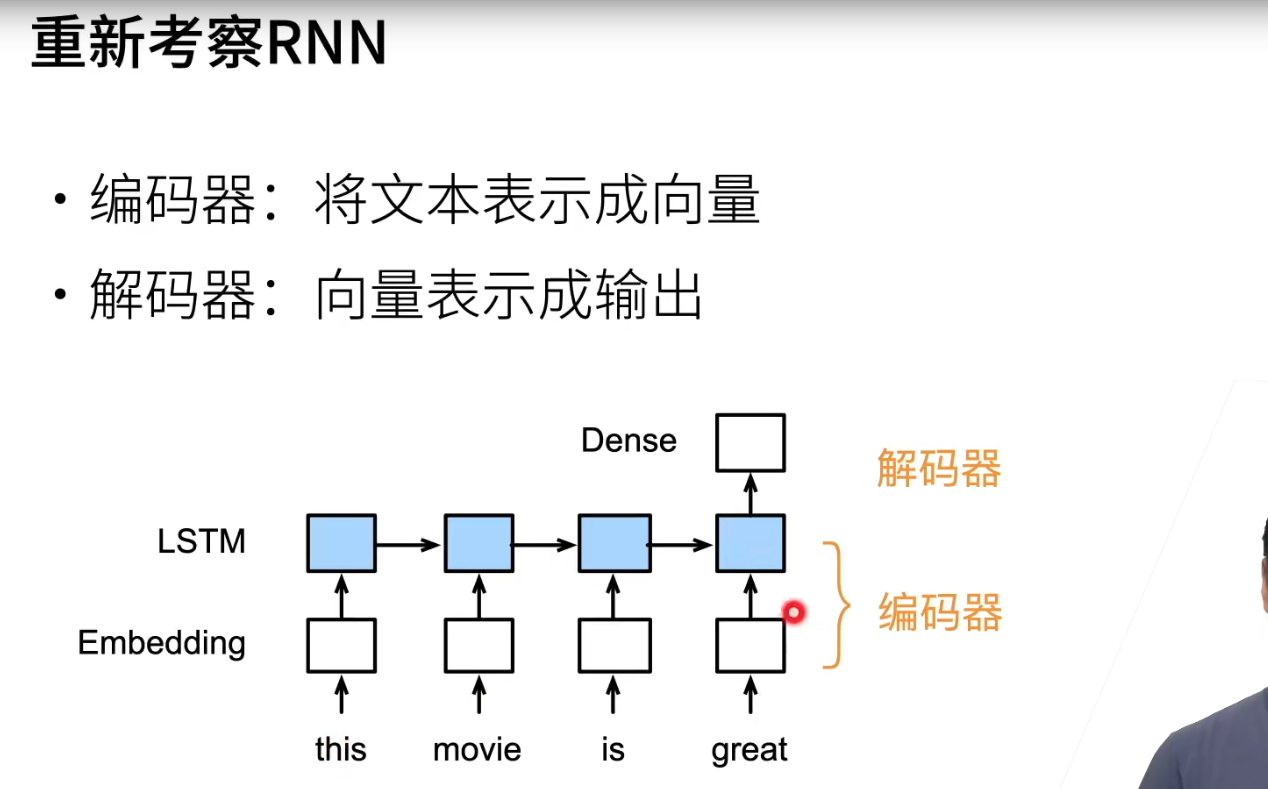
设计一个包含两个主要组件的架构:
第一个组件是一个编码器(encoder): 它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。【注意,实现的时候,encoder的输出enc_ouputs就是RNN的输出,在decoder的初始化中,将这个转成编码后的状态。】 编码器通过选定的函数$q$, 将所有时间步的隐状态转换为==上下文变量$c$==。后文用的上下文变量是最后时间步的最后一层的隐状态。
第二个组件是解码器(decoder): 它将固定形状的编码状态映射到长度可变的序列。 在每个时间步都会将输入 (例如:在前一时间步生成的词元)和编码后的状态 映射成当前时间步的输出词元。【后文中,在seq2seq里,encoder的output被扔掉,最后的state用来初始化decoder;在attention中,就用上了output】
这被称为编码器-解码器(encoder-decoder)架构。编码器的输出用于生成编码状态, 这个状态又被解码器作为其输入的一部分。
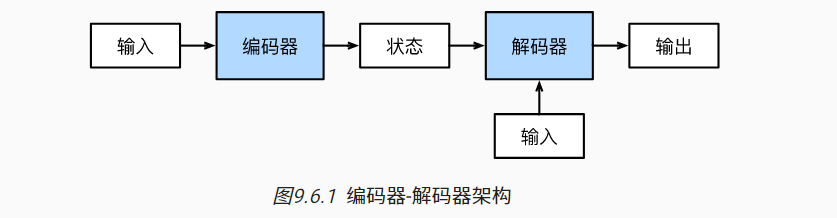
序列到序列学习(seq2seq)
遵循编码器-解码器架构的设计原则, 循环神经网络编码器使用长度可变的序列作为输入, 将其转换为固定形状的隐状态。 换言之,输入序列的信息被编码到循环神经网络编码器的隐状态中。
为了连续生成输出序列的词元, 独立的循环神经网络解码器是基于输入序列的编码信息 和输出序列已经看见的或者生成的词元来预测下一个词元。
训练decoder时,知道真正的输出,所以预测错了某个,还是拿正确的输入到下一个。【强制教学】
预测的时候,得把源句子tokenize后丢进encoder和decoder转一圈,依次取输出的值,state喂到下一个去,区别是decoder阶段,是拿你当前的预测输入到下一个去。
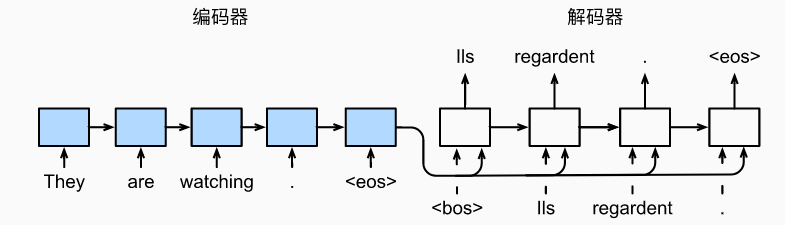
两个特定的设计: 首先,特定的“
在其他一些设计中 [Cho et al., 2014b], 如 图9.7.1所示, 编码器最终的隐状态在每一个时间步都作为解码器的输入序列的一部分。
最终架构如下:
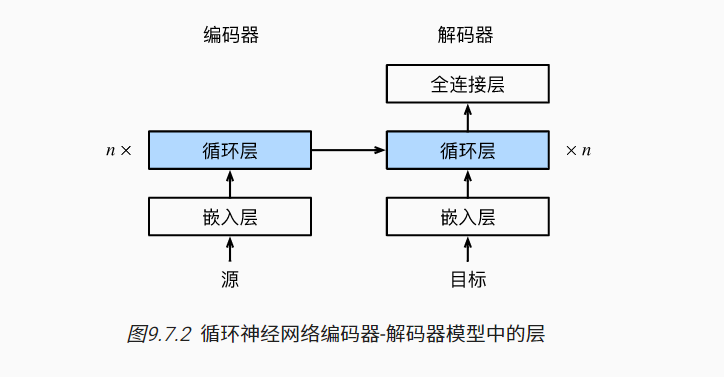
嵌入层(embedding layer) 来获得输入序列中每个词元的特征向量。 嵌入层的权重是一个矩阵, 其行数等于输入词表的大小(
vocab_size), 其列数等于特征向量的维度(embed_size)。 对于任意输入词元的索引i, 嵌入层获取权重矩阵的第i行(从0开始)以返回其特征向量。维度保持不变,只是把索引变成了索引对应的特征向量,1维变成embed_size维
评价标准
预测的句子可能和实际句子长度不同,如何衡量。
BLEU(bilingual evaluation understudy) 最先是用于评估机器翻译的结果, 但现在它已经被广泛用于测量许多应用的输出序列的质量。 原则上说,对于预测序列中的任意n元语法(n-grams), BLEU的评估都是这个n元语法是否出现在标签序列中。
$$
\exp\left(\min\left(0, 1 - \frac{\mathrm{len}{\text{label}}}{\mathrm{len}{\text{pred}}}\right)\right) \prod_{n=1}^k p_n^{1/2^n},
$$
1-xxx那项是惩罚过短的预测;最后$p_n$的幂是给长匹配更高的权重。
最好的结果是1。
word2vec已经没什么人用了,都用BERT。
seq2seq可以用纯transformer实现,但是潮流而已,说不定到时候RNN又更好了。
束搜索
贪心搜索是效率最高的,但是可能不是最优的。穷举在计算上不可行。beam search是折中。
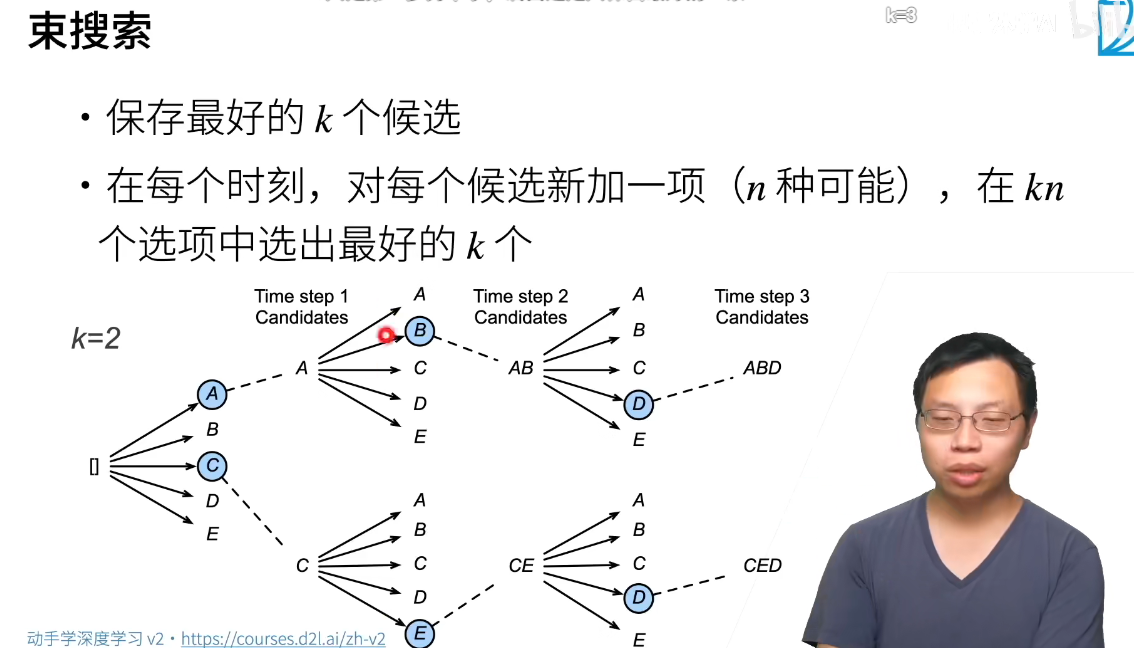
除了第一步,后续还是贪心。 它有一个超参数,名为束宽(beam size)k。 在时间步1,我们选择具有最高条件概率的k个词元。 这k个词元将分别是k个候选输出序列的第一个词元。 在随后的每个时间步,基于上一时间步的k个候选输出序列, 我们将继续从k|Y|个可能的选择中 挑出具有最高条件概率的k个候选输出序列。
我们会得到六个候选输出序列: (1)A;(2)C;(3)A,B;(4)C,E;(5)A,B,D;(6)C,E,D。
我们选择其中条件概率乘积最高的序列作为输出序列,但是得惩罚长序列,取log转成负的,免得只选短的,这也是权衡。
$$
\frac{1}{L^\alpha} \log P(y_1, \ldots, y_{L}\mid \mathbf{c}) = \frac{1}{L^\alpha} \sum_{t’=1}^L \log P(y_{t’} \mid y_1, \ldots, y_{t’-1}, \mathbf{c}),
$$
L是最终候选序列的长度, α通常设置为0.75。
Attention
注意⼒机制解决了困扰统计学⼀个多世纪的问题:如何在不增加可学习参数的情况下增加系统的记忆和复杂性。
研究⼈员通过使⽤只能被视为可学习的指针结构,找到了⼀个优雅的解决⽅案。不需要记住整个⽂本序列(例如⽤于固定维度表⽰中的机器翻译),所有需要存储的都是指向翻译过程的中间状态的指针(查询)。这⼤⼤提⾼了⻓序列的准确性,因为模型在开始⽣成新序列之前不再需要记住整个序列。
概念
意识的聚集和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感兴趣的物体,例如猎物和天敌。 只关注一小部分信息的能力对进化更加有意义
双组件(two-component)框架
非自主性提示(非随意)是基于环境中物体的突出性和易见性。不由自主地引起人们的注意。【卷积、全连接、池化】
自主性提示(随意)去辅助选择时,受试者的主观意愿推动,选择的力量也就更强大。
自主性提示称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(Attention Pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。 在注意力机制中,这些感官输入被称为值(value)。 更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。设计注意力汇聚, 以便给定的查询(自主性提示)可以与键(非自主性提示)进行匹配, 这将引导得出最匹配的值(感官输入)。
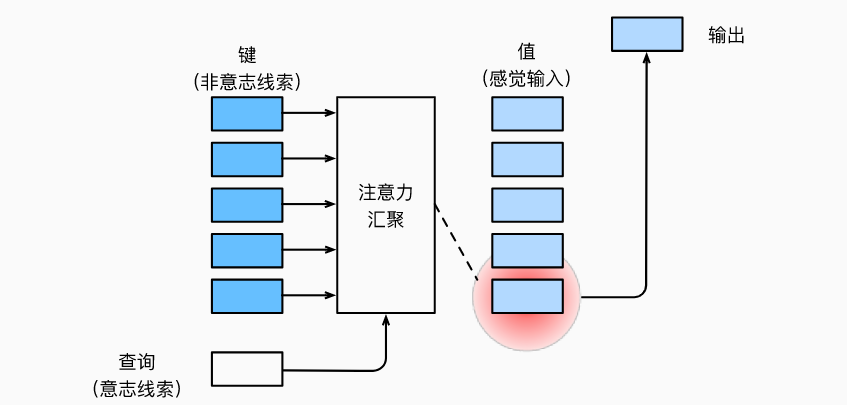
理解键值对的思想。注意力机制的设计有许多替代方案。 例如,我们可以设计一个不可微的注意力模型, 该模型可以使用强化学习方法 [Mnih et al., 2014]进行训练。
注意力汇聚
Nadaraya-Watson 核回归
历史的这个高斯核回归是一种不错的注意力汇聚方式。
思想:如果一个键xi越是接近给定的查询x, 那么分配给这个键对应值yi的注意力权重就会越大, 也就“获得了更多的注意力”。

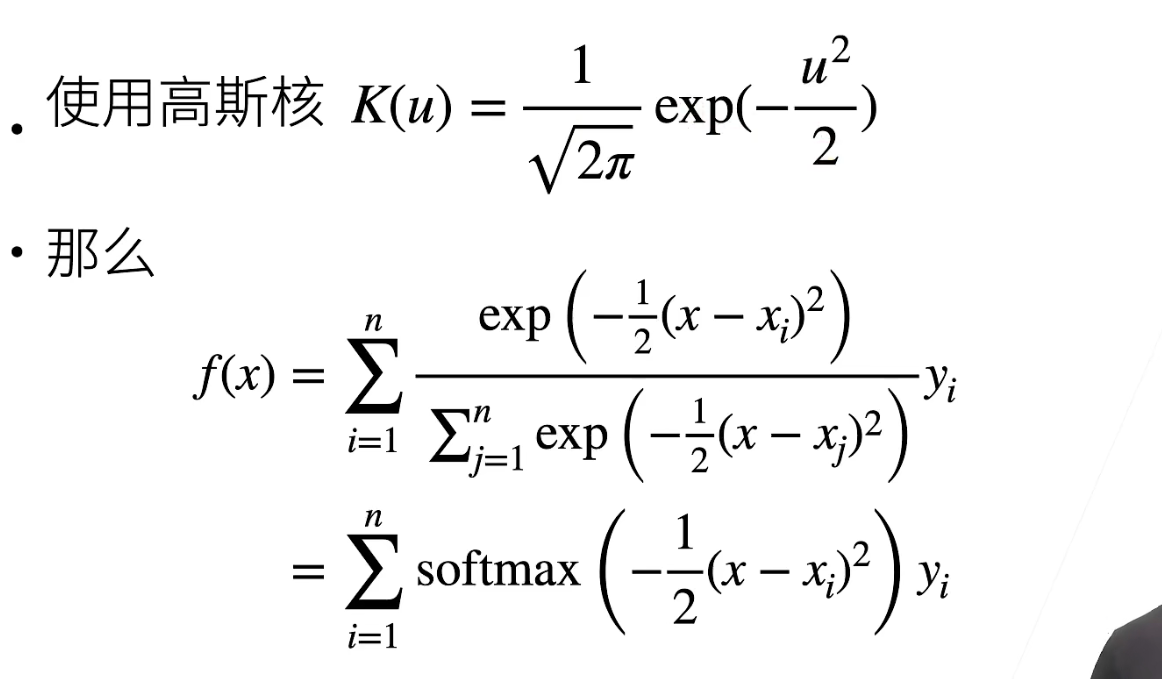
如果要参数化,就加入w:
w可以控制你最终的曲线的平滑程度,不那么平滑有利于拟合。
在带参数的注意力汇聚模型中, 任何一个训练样本的输入都会和除自己以外的所有训练样本的“键-值”对进行计算, 从而得到其对应的预测输出。
查询和键之间的交互形成了注意力汇聚, 注意力汇聚有选择地聚合了值(感官输入)以生成最终的输出。

评分函数
将高斯核指数里面的部分($-\frac{1}{2}(x-x_i)^2$)视为注意力评分函数(attention scoring function), 简称评分函数
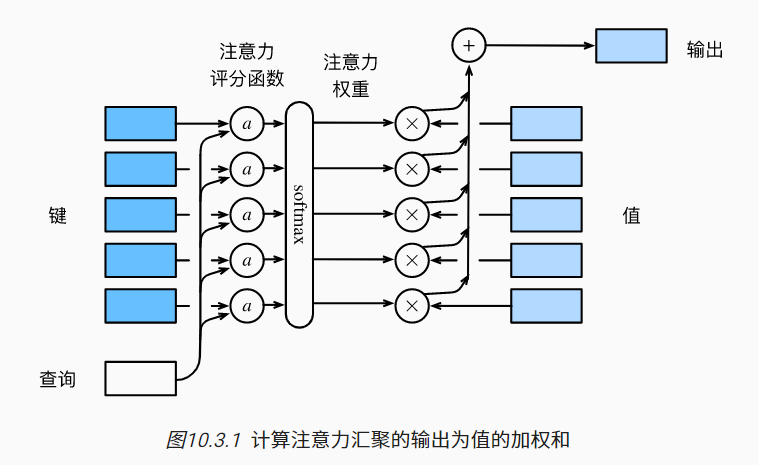
查询q和键$k_i$的注意力权重(标量) 是通过注意力评分函数a 将两个向量映射成标量, 再经过softmax运算得到的
$$
\alpha(\mathbf{q}, \mathbf{k}_i) = \mathrm{softmax}(a(\mathbf{q}, \mathbf{k}_i)) = \frac{\exp(a(\mathbf{q}, \mathbf{k}i))}{\sum{j=1}^m \exp(a(\mathbf{q}, \mathbf{k}_j))} \in \mathbb{R}.
$$
拓展到多维,则query、key、value可以有不同的shape,关键是a怎么设计

两种常见分数计算(多维):
相同长度,计算效率更高,缩放点积注意力,直接做内积然后除以向量长度的开方【好处是不用学习任何东西,唯一超参数是dropout】

任意长度,加性注意力,合并起来进入一个单输出单隐藏层的MLP:

注意力分数是query和key的相似度,注意力权重是分数的softmax结果,normalize过的
masked_softmax是根据语义来的,比如根据前面的预测,那后面的输入就不考虑。
把这套方法用在不同领域其实就是 如何定义、设置query、key、value的过程,不同的领域中形式会大不相同。
例子seq2seq
seq2seq(序列到序列可不局限于文本)还可用于语音和文字之间的转换,chatbot之类的。
我们经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。
如果不是所有输入词元都相关,模型将仅对齐(或参与)输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现的。
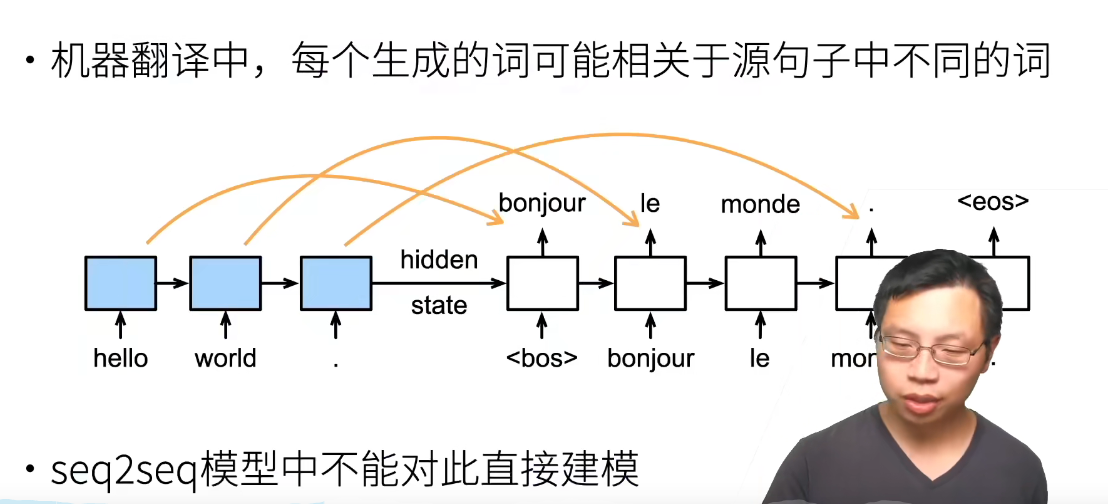
基于字母的一些语言,(英语、法语)什么的,大概率是词一一对应的。
因此希望在翻译时能更关注对应位置的词,而不是像之前一样只输入一个最后的隐状态。
Bahdanau注意力的架构(对比):

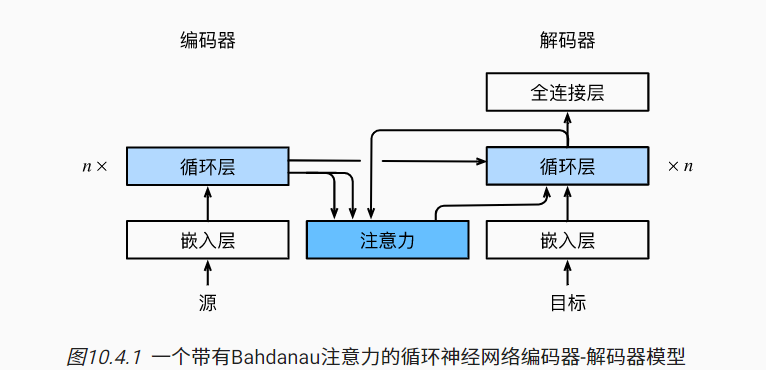
- 编码器对每个词的输出同时作为Key和Value,本身作为值,而又与查询“比较距离”,参与权重计算。
- 解码器RNN对上一个词的预测作为query,比方说上个预测的词是Hello,作为query拿到编码器中对key进行匹配,找到Hello附近的那一圈词,分配更高的注意力权重。【用RNN输出而不是embedding输入是因为RNN的输出在一个语义空间里】
- 注意力的输出替代了上下文c,与embedding的输入合并进入解码器的RNN层
其他的和之前的seq2seq没差别。
自注意力
【是不是因为query和key长度一样,所以都是用内积而不是加性注意力】
它指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。Q=K=V。只需要在Source处进行对应的矩阵操作,用不到Target中的信息。

attention和self attention 其具体计算过程是一样的,只是计算对象发生了变化而已。
我们经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。 那么怎么用注意力机制对序列进行编码呢
有了注意力机制之后,我们将词元序列输入注意力池化中, 以便同一组词元同时充当查询、键和值。 具体来说,每个查询都会关注所有的键-值对并生成一个注意力输出。
由于查询、键和值来自同一组输入,因此被称为 自注意力(self-attention)
自注意力机制相对注意力机制而言,减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
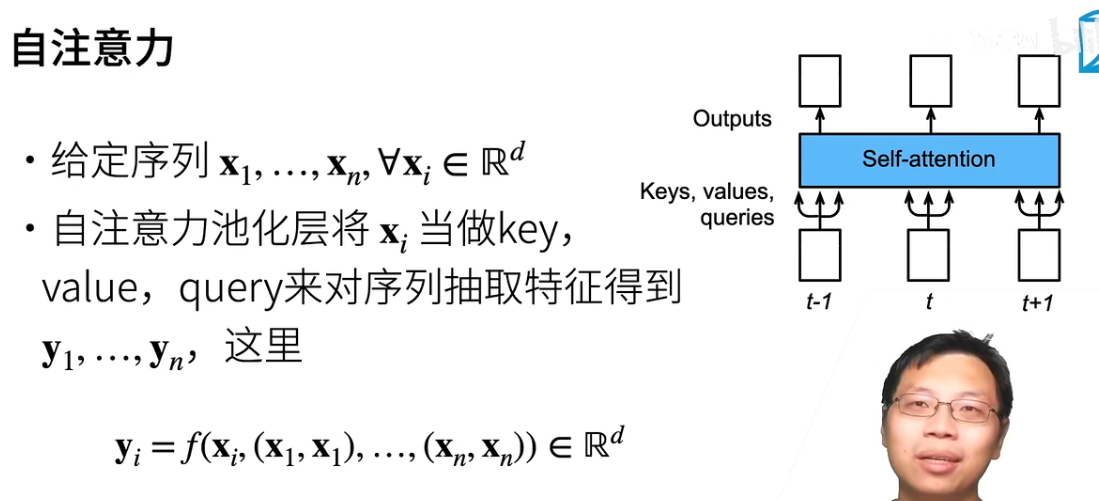
其中$f$就是之前讨论过的注意力汇聚(也可称为池化)函数
序列长度是n,输入和输出的通道数量都是d,CNN里的k是卷积核大小。
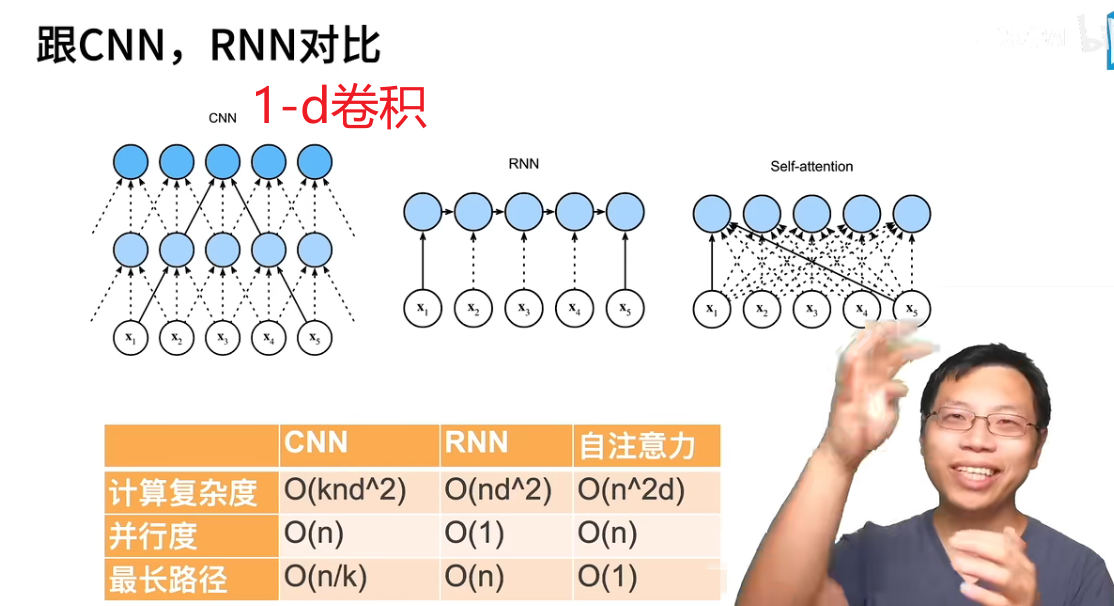
并行度是说你的输出可以并行地接着运算,有利于GPU发挥实力。顺序操作会妨碍并行计算,而任意的序列位置组合之间的路径越短,则能更轻松地学习序列中的远距离依赖关系。
RNN路径长,无法并行,有些针对RNN的修改增加了计算量,但也增加了并行度,结果时间可能并没有增加。路径长说明前面的词元要传递信息给最后的词元要跨越很长的距离,这样不便于长期记忆,但是对整个序列的记忆比较好,擅长序列性的。
自注意力,在序列比较长时,计算量是指数增长的,因为每次都要回去看一整个序列。相对的,其并行度就非常好,所以像TPU这种大型矩阵乘法的硬件,支持的就非常好。还有在比较长的序列时,路径永远为1,可以轻松抓取很远的信息。所以抛开计算,自注意力很适合处理长文本。
所以基于注意力的算起来特别贵。比CNN贵多了,可能会达到几千个GPU一起算。
位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作,因此失去了位置信息 。(输入随便打乱位置,最终输出的位置跟随变化,但是内容没有影响。)
解决方法:为了使用序列的顺序信息,我们在输入表示中添加 位置编码(positional encoding)来注入绝对的或相对的位置信息。
有意思的是,它不是把信息加到模型里,这会有各种问题(比如RNN那种,并行度一下就低了),而是加到了输入里。
行号$i$,列号$j$

在位置嵌入矩阵P中, 行代表词元在序列中的位置,列代表位置编码的不同维度。 在下面的例子中,我们可以看到位置嵌入矩阵的第6列和第7列的频率高于第8列和第9列。 第6列和第7列之间的偏移量(第8列和第9列相同)是由于正弦函数和余弦函数的交替。
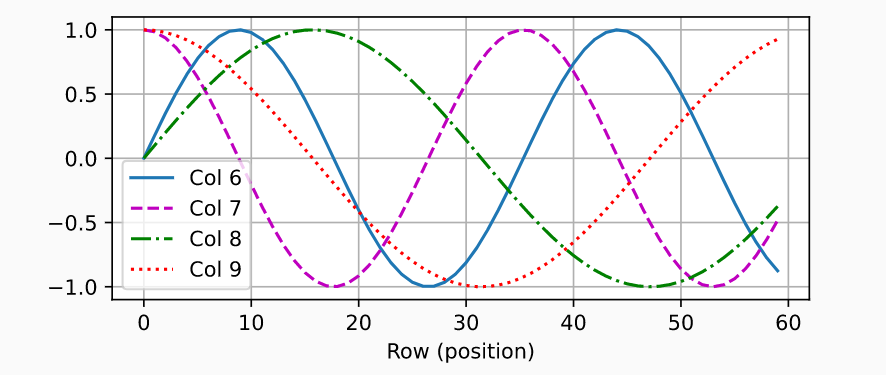
所以,相当于对每个样本、维度加上一点不一样的值,让模型去分辨这个细微的东西来学到时序,挺奇怪的。
好处是不改变模型,也不改变数据大小,坏处是你的模型可能认不出来:joy:
沿着编码维度单调降低的频率与绝对位置信息的关系(大致理解):
通过计算机的二进制编码解释,例子中维度是3维,每个数字、每两个数字和每四个数字上的比特值 在第一个最低位、第二个最低位和第三个最低位上分别交替。 然后前面的维度频率慢,后面的维度频率快(第一维01010101)由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
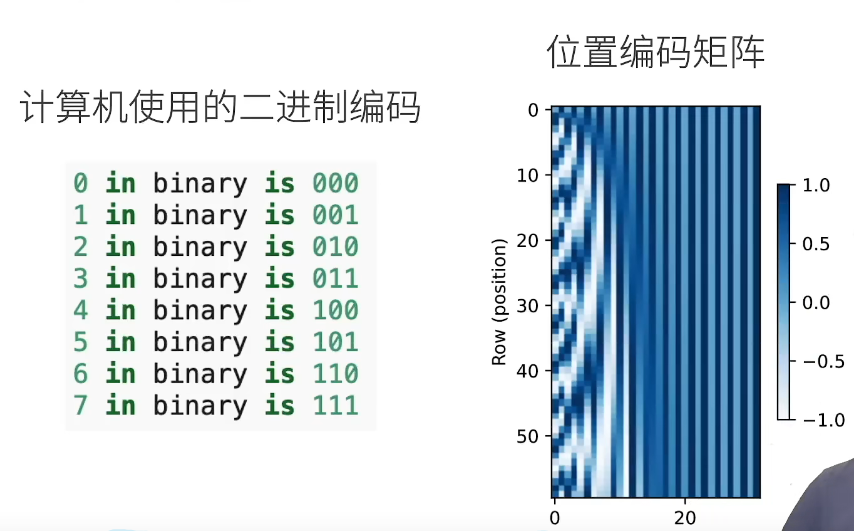
之所以使用sin、cos函数,是因为这样编码的是相对位置信息。投影矩阵和你的i也就是样本位置无关,但是和你的维度有关。对于任何确定的位置偏移δ,位置i+δ处 的位置编码可以线性投影位置i处的位置编码来表示。
因为我们学的都是这个w,所以他会学到相对的信息,而不是绝对的信息


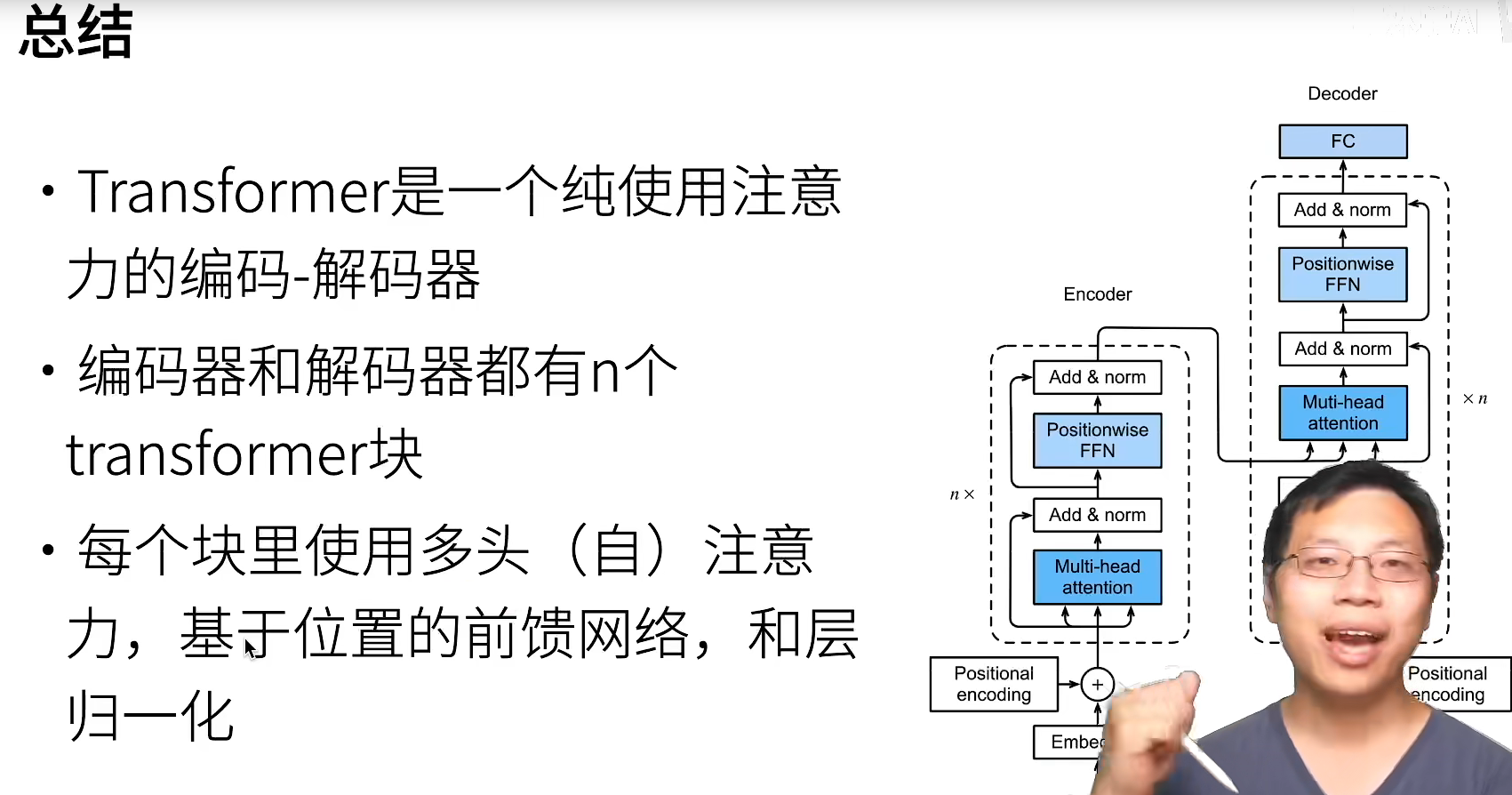
Transformer
transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层 [Vaswani et al., 2017]。尽管transformer最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学中,例如语言、视觉、语音和强化学习领域。
从transformer开始,取名越来越fancy了,包括bert什么的。
基于编码器-解码器架构来处理序列对。
但跟使用注意力的seq2seq不同,transformer是纯基于注意力的。
Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。
在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。每个子层都采用了残差连接(residual connection)。在transformer中,对于序列中任何位置的任何输入x∈Rd,都要求满足sublayer(x)∈Rd,以便残差连接满足x+sublayer(x)∈Rd。在残差连接的加法计算之后,紧接着应用层规范化(layer normalization)。
因此,输入序列对应的每个位置,transformer编码器都将输出一个d维表示向量。Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。
在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。
在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。【还有一种decoder是NAT(Non-autoregressive),李宏毅有介绍】
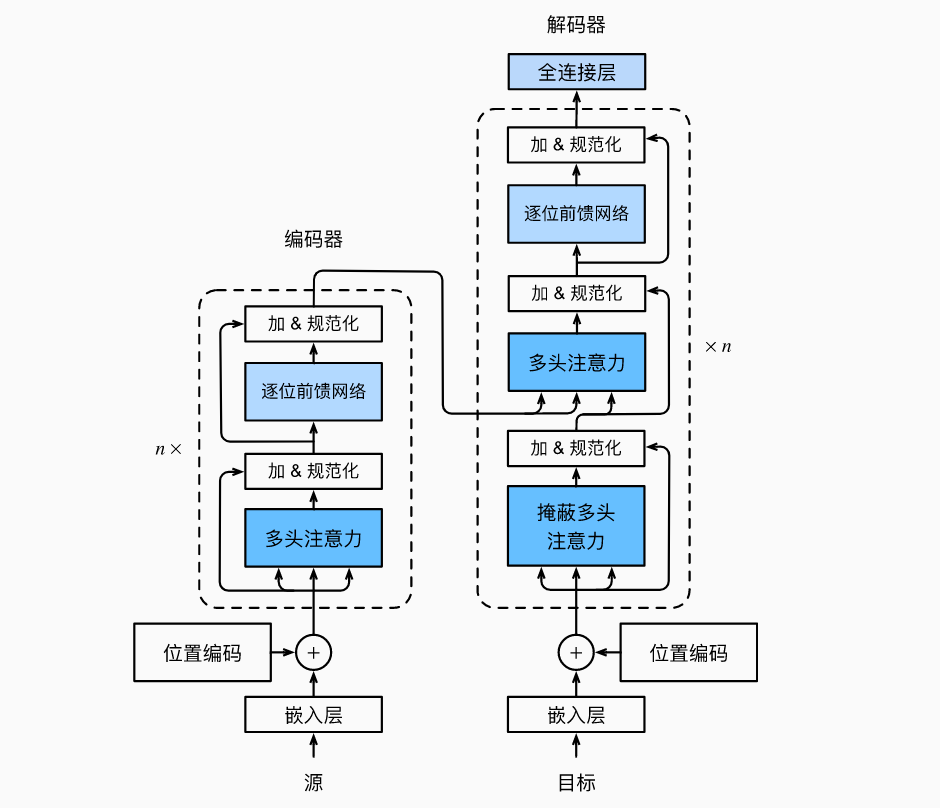
编码器和解码器的第一个蓝块(注意力块)是self-attension,但是解码器上面那个是普通的attention用来接收编码器的输出。
多头注意力
当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系。(例如,短距离依赖和长距离依赖关系)
因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
我们可以用独立学习得到的h组不同的 线性投影(linear projections)来变换查询、键和值。 然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。
首先通过全连接层,把你映射到(可能低一点的)dimension,对于输出的n个注意力,在特征维度concat起来,再用一个$W_o$变换
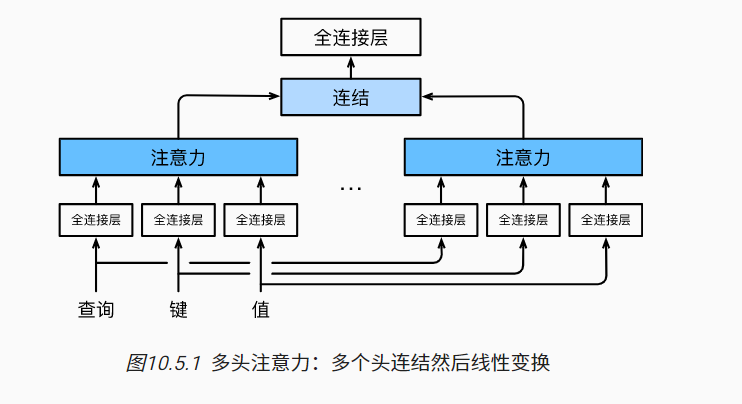

不过,比如在解码器对序列中的一个元素输出时,不应该考虑该元素后面的元素,可以通过掩码来实现。(也就是计算$x_i$输出时,假装当前序列长度为$i$)
基于位置的前馈网络
说白了还是一个全连接,(batch_size,序列的长度,dimension)

模型应该与n(序列长度)无关,可以处理任意长度的,所以不能处理成一个特征。
对序列中的每个元素($x_i$是长度为dimension的向量)作用两个全连接层(输出了又换回来)。
FFN的作用应该就是提供更多的非线性和学习能力。草,我懂了,其实就是一个跟维度n无关的全连接。
Add & norm
add就是加上一个残差连接。norm是层归一化,但是不能用之前说的那个batch normalization,因为序列长度n会变。
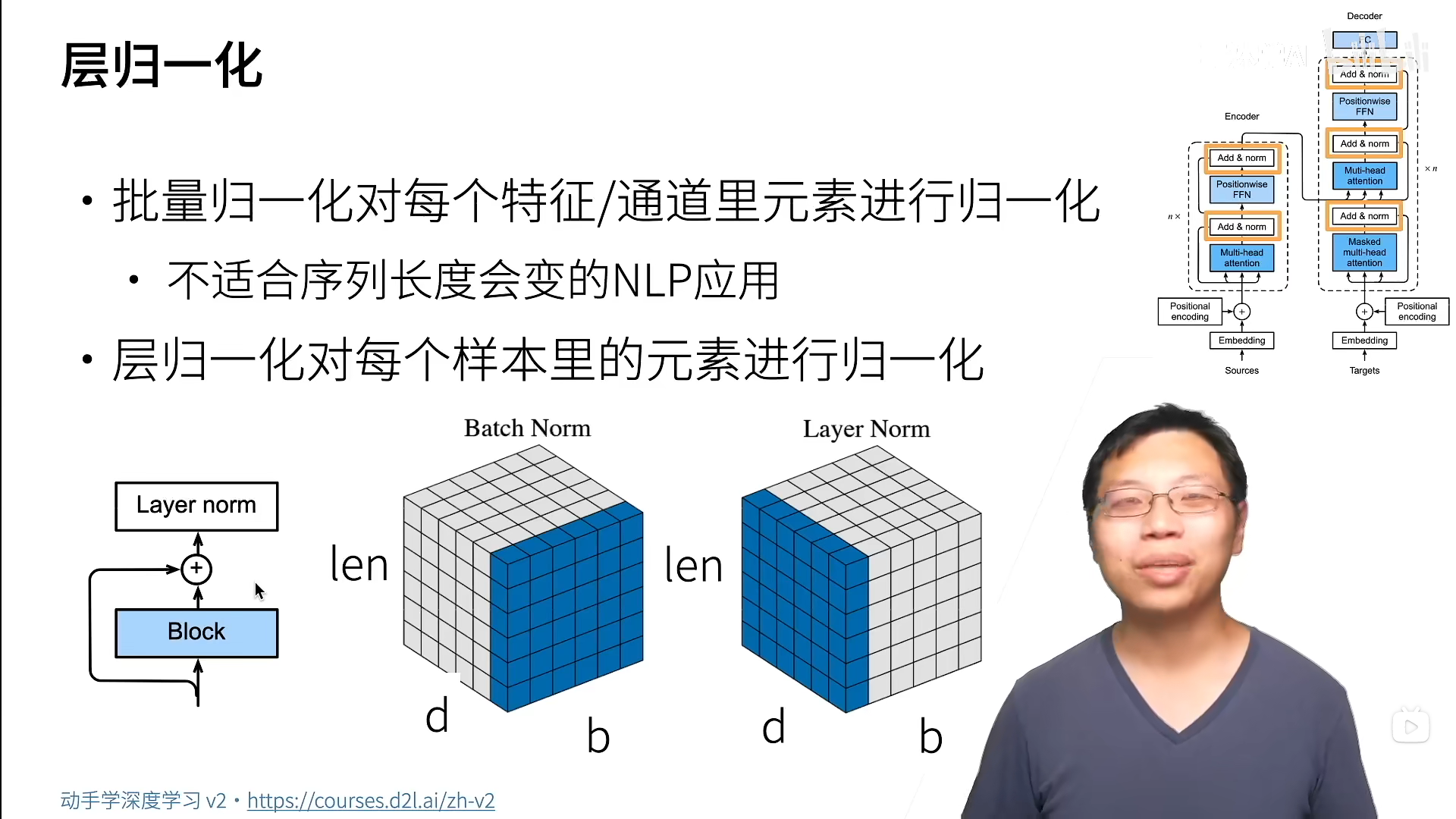
可见,batch norm是选每个(通道内的)所有batch的元素进行归一化。
Layer是一个batch内部,自己把多个特征的元素一起归一化。这样稳定性,不会因为n而发生很大变化。
信息传递
编码器和解码器的第一个蓝块(注意力块)是self-attension,但是解码器上面那个是普通的attention用来接收编码器的输出。

编码器和解码器的输出因此一般都是一样的,一是为了简单,二是为了对称。
预测
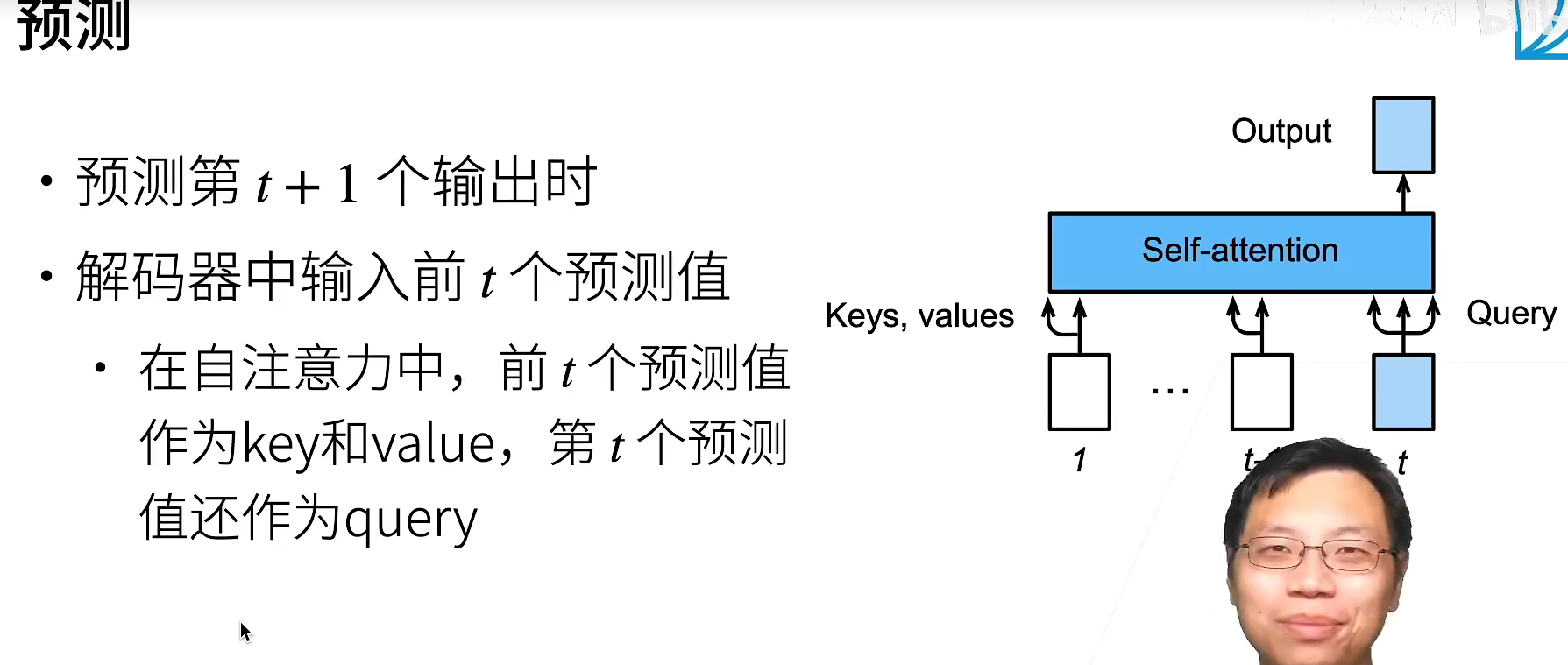
预测的时候就不再像训练的时候并行的了,需要一个个顺序的预测,因为要用到之前的预测值。
transformer本身还好,只是bert那些鬼东西难算。
BERT

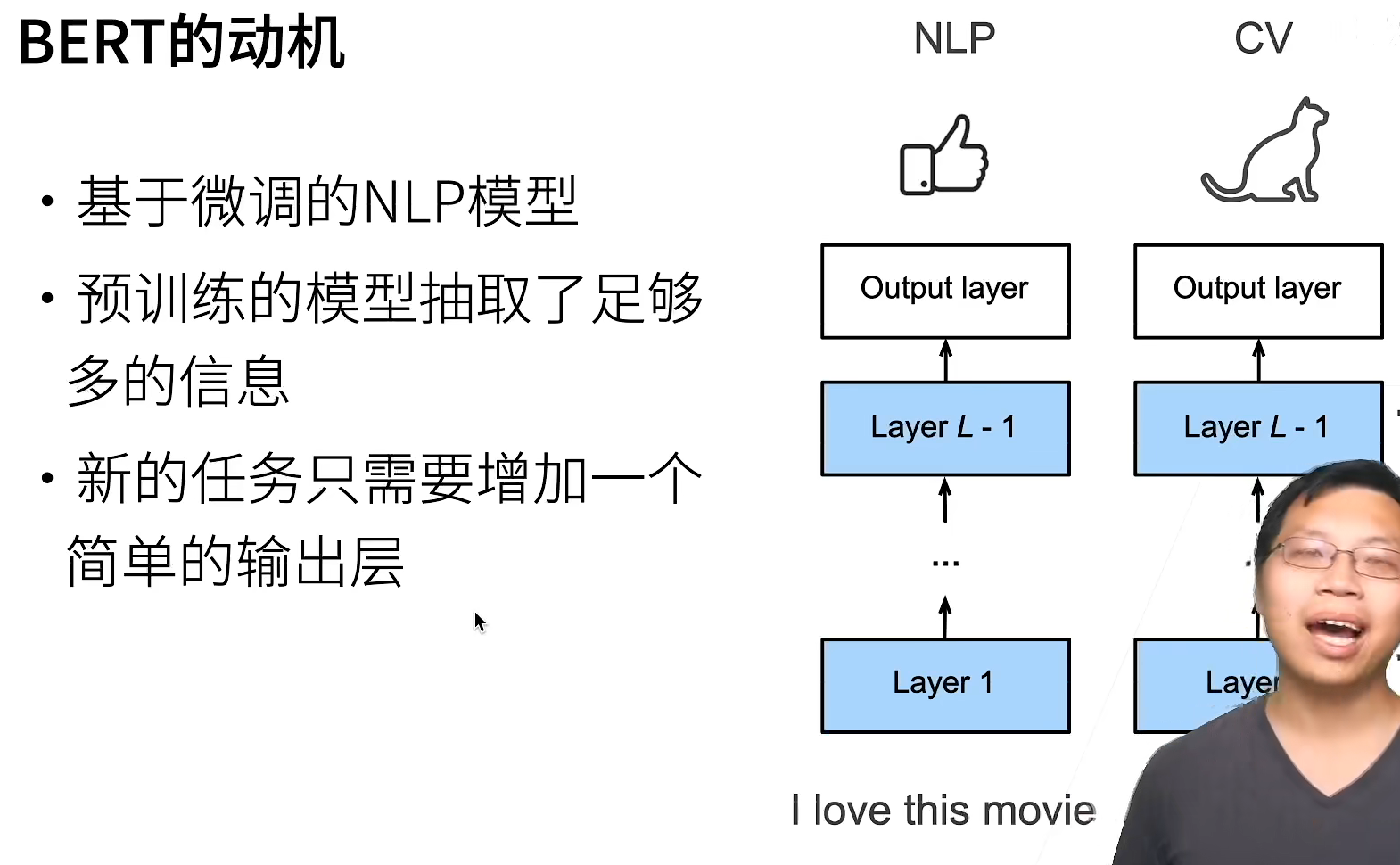
原本输入分src和tar,分别进encoder和decoder,现在只剩encoder,就要修改修改。


encoder是双向的,可以看到前和后,抽取比较好的特征。



 机器学习和深度学习提取的特征不太一样,不一定深度学习提取的就是最好的(跟数据量和模型都有关),是互补关系。
机器学习和深度学习提取的特征不太一样,不一定深度学习提取的就是最好的(跟数据量和模型都有关),是互补关系。
代码不是都和数学原理有关,还有很多tricks。现实生活中tabula数据比图片用的yao多。



