李沐
tensorflow的tensor没有reshape,必须tf.reshape(x,(3,4)) torch牛
tensorflow.random没有randn,得用normal
torch.tensor 对应 tf.constant + tf.Variable + tf.tensors
torch.arange() == tf.range()
查看变量:torch 比较简洁,但tensorflow可能方便点
torch tensor可直接修改 ;TensorFlow中的constant是不可变的,也不能被赋值。 TensorFlow中的Variables是支持赋值的可变容器。 请记住,TensorFlow中的梯度不会通过Variable反向传播。
中间结果即使是tensor,也能打印
为了区分需要计算梯度信息的张量和不需计算梯度信息的张量,TF设置一种专门的数据类型用于支持梯度信息的记录:tf.Variable。
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
x0*x0#也不行
# Not a variable
x3 = tf.constant(3.0, name='x3')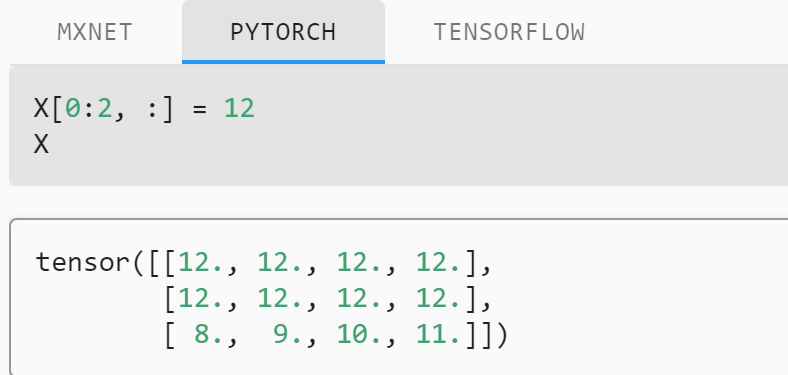
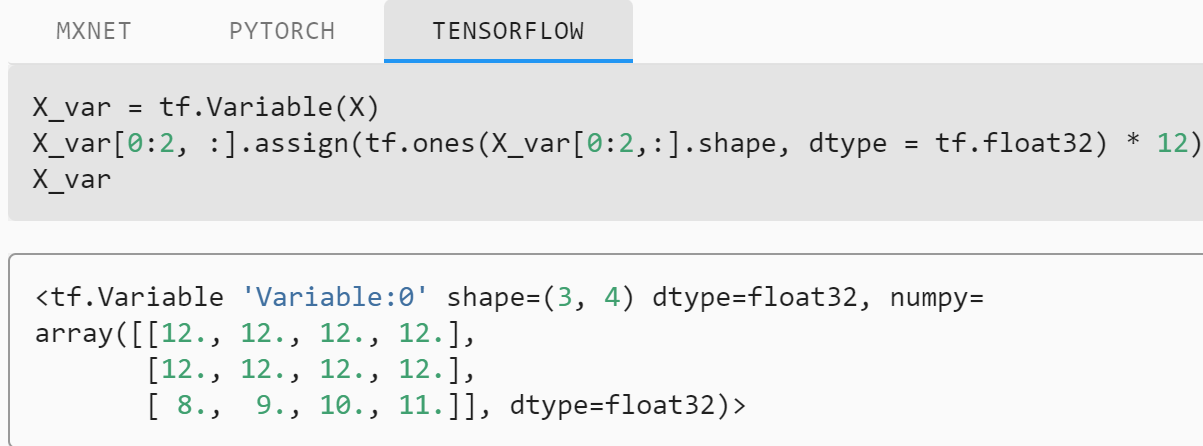
如果不用assign,那就会从variable变成tensor
都提供 ~_like()提供同shape,都有.shape,都能用python的len()查看第0维
torch 切片就是原地操作 tf里assign能存参数,无明显原地操作法 torch的_inplace方法,不占用额外的内存

pytorch的tensor(array)不共享内存,as_tensor和from_numpy共享,就地操作也共享。
tensorflow 转换后的结果不共享内存。 这个小的不便实际上是非常重要的:当你在CPU或GPU上执行操作的时候, 如果Python的NumPy包也希望使用相同的内存块执行其他操作,你不希望停下计算来等它。
Linear
torch里var.T == tf里tf.transpose(var)
torch可以.clone,复制内存,tf 不行我擦,tf的成员变量真少,都是tf.xxx
torch: x.sum(axis = 0) tf: tf.reduce_sum(x,axis = 0) ==当然,torch也有torch.sum()这些操作==
torch: x.numel() tf:tf.shape(x).numpy()
都用xx.norm(var)
torch.mv ==tf.linalg.matvec(A, x) torch.mm == tf.matmul torch.dot == tf.tensordot
In [1]: [[]] * 3
Out[1]: [[], [], []]
plt.rcParams['figure.figsize'] = figsize #可以设置相当多的属性
axes.grid()#网格化
axes = axes if axes else d2l.plt.gca() #get current axes
plt.cla() 方法清除当前坐标轴,plt.clf() 方法清除当前图形,plt.close() 方法关闭整个窗口。隐式计算图 vs 显式计算图:https://zh-v2.d2l.ai/chapter_preliminaries/autograd.html
u = y.detach u = tf.stop_gradient(y)
torch同一个计算图好像不能连续算两遍。tensorflow用的是磁带tf.GradientTape记录梯度,梯度不累加而是覆盖。
tensorflow也有trainable = true,如果是False,冻结的层在训练期间不会更新(无论是使用 fit() 进行训练,还是使用依赖于 trainable_weights 来应用梯度更新的任何自定义循环进行训练时)
由于tensorflow的梯度得另外存储,如dw, db = g.gradient(l, [w, b]),所以得在训练中存好了,交给优化算法读取并更新。
而torch直接在优化算法中用grad就能得到。但是torch在优化算法中要注意设置不进行梯度运算,并清零这一batch的梯度。
读取数据集
#布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据
#torch
from torch.utils import data
def load_array(data_arrays, batch_size, is_train=True): #@save
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays) #这次的数据是tensor格式,数据集用TensorDataset构造
return data.DataLoader(dataset, batch_size, shuffle=is_train) #这个应该是通用的,改dataset就好。其实是True
batch_size = 10
data_iter = load_array((features, labels), batch_size) #迭代器的最终形式是dataloader
----------------------------------------------------------------------------------------------
#tensorflow
def load_array(data_arrays, batch_size, is_train=True): #@save
"""构造一个TensorFlow数据迭代器"""
dataset = tf.data.Dataset.from_tensor_slices(data_arrays)
if is_train:
dataset = dataset.shuffle(buffer_size=1000)
dataset = dataset.batch(batch_size) #tensorflow没有loader的设定,都在数据集自定的实现上操作
return dataset
batch_size = 10
data_iter = load_array((features, labels), batch_size)#迭代器的最后形式就是dataset
next(iter(data_iter))pytorch的网络是确定的,没有输入之前,就能直接访问各层的参数,并直接修改;tensorflow能指定每层的初始化方法,但只有在我们第一次尝试通过网络传递数据时才会进行真正的初始化。 请注意,因为参数还没有初始化,所以我们不能访问或操作它们。
initializer = tf.initializers.RandomNormal(stddev=0.01)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(1, kernel_initializer=initializer))loss = nn.MSELoss() vs loss = tf.keras.losses.MeanSquaredError()
trainer = torch.optim.SGD(net.parameters(), lr=0.03) vstrainer = tf.keras.optimizers.SGD(learning_rate=0.03)
在每个epoch打印损失:向损失函数输入初始数据集和labels,而非训练用的shuffle过的数据。
经典训练
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
loss = nn.MSELoss()
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
------------------------------------------------------------------------------------------------
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(1))
initializer = tf.initializers.RandomNormal(stddev=0.01)
net.add(tf.keras.layers.Dense(1, kernel_initializer=initializer))
loss = tf.keras.losses.MeanSquaredError()
trainer = tf.keras.optimizers.SGD(learning_rate=0.03)
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
with tf.GradientTape() as tape:
l = loss(net(X, training=True), y)
grads = tape.gradient(l, net.trainable_variables)#参数传递也挺方便的
trainer.apply_gradients(zip(grads, net.trainable_variables))
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')Softmax
%matplotlib inline
from IPython import display
display.set_matplotlib_formats('svg') #用更高精度的svg图片torchvision包 包含了目前流行的数据集,模型结构和常用的图片转换工具。
torchvision.datasets中包含了MNIST等6个?数据集
torchvision.transform里有许多处理图片的方法、工具。
torchvision.modelsy偶很多预训练模块。
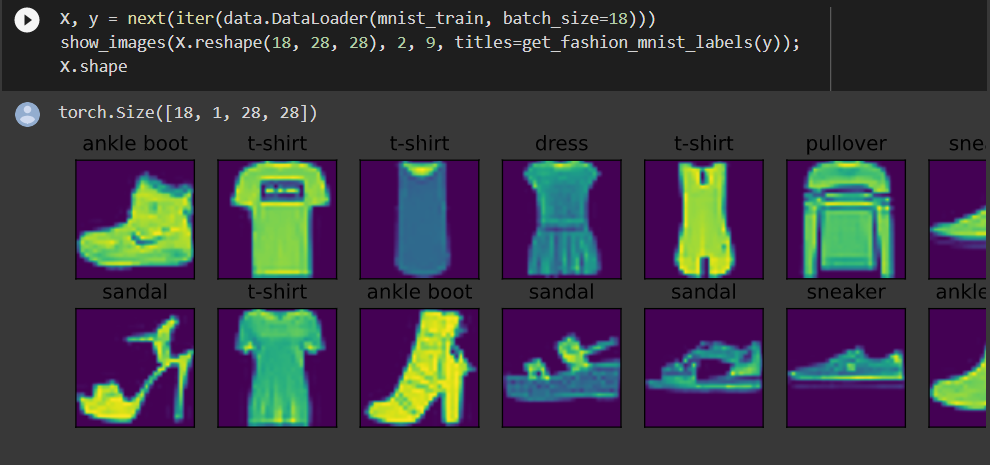
得到的mnist_train可以直接用来做dataset那个参数,X的shape是(batch,channels,height,width)
num_workers参数用来指定用几个进程读数据。

测试读入简单的tensor,4进程没问题,果然还是和内存有关。
imshow函数接收的图片格式:
X变量存储图像,可以是浮点型数组、unit8数组以及PIL图像,如果其为数组,则需满足一下形状:
(1) MN 此时数组必须为浮点型,其中值为该坐标的灰度;
(2) MN*3 RGB(浮点型或者unit8类型)
(3) MN*4 RGBA(浮点型或者unit8类型)
可视化样本
def get_fashion_mnist_labels(labels): #@save
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize) #这个'_'就很离谱
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):#沐神常用操作了。
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes读取数据集
果然,不同的框架内置的数据集,组织方式也不一样啊。还有这俩框架的处理数据策略果然差挺远。
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))#先resize,再tosensor!!!!:star
trans = transforms.Compose(trans) #torch对数据集的处理主要用transform实现
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break
torch.Size([32, 1, 64, 64]) torch.float32 torch.Size([32]) torch.int64
-----------------------------------------------------------------------------
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
mnist_train, mnist_test = tf.keras.datasets.fashion_mnist.load_data()
# 将所有数字除以255,使所有像素值介于0和1之间,在最后添加一个批处理维度,
# 并将标签转换为int32。
process = lambda X, y: (tf.expand_dims(X, axis=3) / 255,
tf.cast(y, dtype='int32'))
resize_fn = lambda X, y: (
tf.image.resize_with_pad(X, resize, resize) if resize else X, y) #函数里要同时处理所有吗
return (
tf.data.Dataset.from_tensor_slices(process(*mnist_train)).batch(
batch_size).shuffle(len(mnist_train[0])).map(resize_fn),
tf.data.Dataset.from_tensor_slices(process(*mnist_test)).batch(
batch_size).map(resize_fn)) #标签不用shuffle
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break
(32, 64, 64, 1) <dtype: 'float32'> (32,) <dtype: 'int32'>pytorch model.train() model.eval()【适用dev set和test】主要区别在BN和dropout
y_hat.type(y.dtype) vs tf.cast(y_hat, y.dtype)
交叉熵nn.CrossEntropyLoss(reduction='none') vs tf.losses.sparse_categorical_crossentropy()
nn的损失函数有reduction参数共有三种选项’elementwise_mean’,’sum’和’none’。
‘elementwise_mean’为默认情况,表明对N个样本的loss进行求平均之后返回;
‘sum’指对n个样本的loss求和;
‘none’表示直接返回n分样本的loss,是一个向量
3.6里,有很牛的Animator和Accumulator,实现了很多nb代码。
还是直接去看吧https://zh-v2.d2l.ai/chapter_linear-networks/softmax-regression-scratch.html
求准确率:float(布尔代数)类的行为,👇实现列表每项更新,但是其实可以用向量化来处理。
不要把numpy的多维和dataframe的行列弄混了。。。
X_train = torch.cat([X_train, X_part], 0)def add(self, *args): self.data = [a + float(b) for a, b in zip(self.data, args)]花哨索引:传入多个列表,每个列表代表相应维度的坐标,想想都方便欸。
MLP
torch.relu(x)/sigmoid/tan vs tf.nn.relu(x)/sigmoid/tan
torch的backward函数:如果参数retain_graph=true,就会每次运行时重新生成图。也就是说,每次 backward() 时,默认会把整个计算图free掉。一般情况下是每次迭代,只需一次 forward() 和一次 backward() , 前向运算forward() 和反向传播backward()是成对存在的,一般一次backward()也是够用的。
但是不排除,由于自定义loss等的复杂性,需要一次forward(),多个不同loss的backward()来累积同一个网络的grad来更新参数。
还有一个grad_tensor参数(第一个默认),一般和要求梯度的tensor大小一致,用来指定权重,暂时没用上。
Relu的简单实现:lambda x:torch.max(x,torch.zeros_like(x))
#关于维度,W是(input,output),计算时是matmul(X,W) input是X的特征维数,X的第0维是batch
#这里有个处理,就是reshape来适配一下维度。即`torch.matmul(X.reshape((-1, W.shape[0])), W) + b`
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
------------------------------------------------------------------------------
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
------------------------------------------------------------------------------
net = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(10)])#tensorflow只用改输出,比torch赢一筹。当它们被分配为模块属性时,它们会自动添加到其参数列表中,并将出现在例如
parameters()迭代器中。分配张量没有这样的效果。这是因为人们可能想要在模型中缓存一些临时状态,例如 RNN 的最后一个隐藏状态。如果没有这样的类
Parameter,这些临时人员也会被注册。torch.tensor([1,2,3],requires_grad=True)的区别,这个只是将参数变成可训练的,并没有绑定在module的parameter列表中。
用在自定义块里。nn自带的网络的w,b都是parameter
#权重衰减
。。。。
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd}, #这是给第一层weight指定
{"params":net[0].bias}], lr=lr)
trainer = torch.optim.SGD(net.parameters(),lr = lr,weight_decay = 0.01)#多层
。。。。
def train_concise(wd):
。。。。
net.add(tf.keras.layers.Dense(
1, kernel_regularizer=tf.keras.regularizers.l2(wd)))#L2正则化放在这
net.build(input_shape=(1, num_inputs))#这算是指定输入参数吗。
。。。。
--------------------------------------------------------------------------------
#dropout
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
net = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
# 在第一个全连接层之后添加一个dropout层
tf.keras.layers.Dropout(dropout1),torch.clamp() vs tf.clip_by_value()
Kaggle示例 里好多可学的例子
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].fillna(0)
#DataFrame.dtypes 是 每一列的类型tf里还有个``tf.Constant tf好像把会降维的加了个reduce_`前缀,便于区分,其实还是挺不错的。
使用tf.constant函数创建的随机权重参数在训练期间不会更新(即为常量参数)
DIY
tensorflow如果不命名层/块的名字,那命名是按深度遍历的。
自定义块其实就是自定义很多layer,然后调用__call__,在forward/call函数编写传播过程
还是看看原文吧,比如net.add_models('name',block)这些东西
# 我们需要给共享层一个名称,以便可以引用它的参数
# tf.keras的表现有点不同。它会自动删除重复层。
shared = nn.Linear(8, 8)
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(),
shared, nn.ReLU(),
shared, nn.ReLU(),
nn.Linear(8, 1))
net(X)
#确保相同
print(net[2].weight.data[0] == net[4].weight.data[0])
print(net)
print(*[(name, param.shape) for name, param in net.named_parameters()])#列出不重复的的
print(*[(name, param.shape) for name, param in net.state_dict().items()])#列出所有的(这是个OrdictedDict)
--------------------------------------------------------------------------------
tensor([True, True, True, True, True, True, True, True])
Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=8, bias=True)
(3): ReLU()
(4): Linear(in_features=8, out_features=8, bias=True)
(5): ReLU()
(6): Linear(in_features=8, out_features=1, bias=True)
)
('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([8, 8])) ('2.bias', torch.Size([8])) ('6.weight', torch.Size([1, 8])) ('6.bias', torch.Size([1]))
('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([8, 8])) ('2.bias', torch.Size([8])) ('4.weight', torch.Size([8, 8])) ('4.bias', torch.Size([8])) ('6.weight', torch.Size([1, 8])) ('6.bias', torch.Size([1])) #share的层中,named_parameters不会count repeated的与Variable不同,parameter默认require_grad=True,当我们创建一个model时,parameter会自动累加到Parameter 列表中。
for param in net.parameters():
print(type(param.data), param.size())torch里用net[2].state_dict(),以Ordicted-dict组织 参数叫weight 和 bias
因为是字典,可以用 net.state_dict()['2.bias'].data来组织
也可以net.named_parameters(),与dict.item结构类似。
print(net)可以展示所有递归的结构
PyTorch的nn.init模块提供了多种预置初始化方法。用net.apply(initializer)
#内置初始化
def xavier(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
#nn.init.normal_(m.weight, mean=0, std=0.01)
#nn.init.zeros_(m.bias)
#nn.init.constant_(m.weight, 42)
#加上一些别的就是自定义了。比如m.weight.data *= m.weight.data.abs() >= 5
net[0].apply(xavier)
----------------------------------------------------------------------------------
tf里用.layers[]/.weights[]索引,参数叫kernel和bias 列表组织
参数类型不是tensor,用 tf.convert_to_tensor()可以转换成tensor
也可以net.get_weights() 得到参数列表,但没有名字
net.summary()只会展示最上层的,不会显示内部结构。
TensorFlow在根模块和keras.initializers模块中提供了各种初始化方法。通过各层的kernel_initializer和bias_initializer指定
#自定义初始化
class MyInit(tf.keras.initializers.Initializer):
def __call__(self, shape, dtype=None):
data=tf.random.uniform(shape, -10, 10, dtype=dtype)
factor=(tf.abs(data) >= 5)
factor=tf.cast(factor, tf.float32)#tensorflow不同数据类型不能直接做计算
return data * factor#自定义层,那就要定义参数,实现前向传播
#该层需要输入参数:in_units和units,分别表示输入数和输出数。
class MyLinear(nn.Module):
def __init__(self, in_units, units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)
--------------------------------------------------------------------------
#tensorflow仅仅接收输出参数
class MyDense(tf.keras.Model):
def __init__(self, units):
super().__init__()
self.units = units
def build(self, X_shape):#需要单独用build函数设定参数
self.weight = self.add_weight(name='weight',
shape=[X_shape[-1], self.units],
initializer=tf.random_normal_initializer())
self.bias = self.add_weight(
name='bias', shape=[self.units],
initializer=tf.zeros_initializer())
def call(self, X):
linear = tf.matmul(X, self.weight) + self.bias
return tf.nn.relu(linear)对于一般数据结构:torch自带load和save,tf得用np的,还要指定.npy后缀。但是模型存储都类似:
torch.save(net.state_dict(), 'mlp.params')
clone = MLP()
clone.load_state_dict(torch.load('mlp.params'))#这个两步,先load再加载。也有写model.pt的
---------------------------------------------------------
net.save_weights('mlp.params')
clone = MLP()
clone.load_weights('mlp.params')tensorflow什么都用层次封装,太麻烦了
GPU
x.device 查看在哪个设备上,通用
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices = [torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
X = torch.ones((2,1),device = try_gpu(1))
Y = X.cuda(2)#copy副本到第三个GPU上,如果调用1,则不会复制新内存,返回本身。
net = nn.Sequential(nn.Linear(3, 1))
#为神经网络指定设备
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())#单GPU
#多GPU
#train_batch的那个函数,计算损失的时候是串行的代码结构,此处依赖框架本身看能否在背后之行为并行操作。
#GPU不变快有很多的原因,可能是data读起来就贼慢(可以用for loop遍历一遍数据看看时间)
#还有可能没有打满GPU,通常做法是batch size到n倍(n个GPU),但是这样精度会变低,可以调大一点learning rate
# 在多个GPU上设置模型
net = nn.DataParallel(net, device_ids=devices).to(devices[0])#网络放到0号上
for X, y in train_iter:
trainer.zero_grad()
X, y = X.to(devices[0]), y.to(devices[0])
l = loss(net(X), y)
l.backward()
trainer.step()
#pytorch中,网络被Dataparallel“包装”后,在前向过程会把输入tensor自动分配到每个显卡上。
#而Dataparallel使用的是master-slave的数据并行模式,主卡默认为0号GPU,所以在进网络之前,只要移到GPU[0]就可以了。
------------------------------------------------------------------------------------------------
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if len(tf.config.experimental.list_physical_devices('GPU')) >= i + 1:
return tf.device(f'/GPU:{i}')
return tf.device('/CPU:0')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
num_gpus = len(tf.config.experimental.list_physical_devices('GPU'))
devices = [tf.device(f'/GPU:{i}') for i in range(num_gpus)]
return devices if devices else [tf.device('/CPU:0')]
with try_gpu(1):
X = tf.ones((2, 3))
with try_gpu():
Y = X #相当于设置一个环境来操作,此处把X copy到0号GPU
#为神经网络指定设备
strategy = tf.distribute.MirroredStrategy()#多GPU
device_name = device._device_name#单GPU
strategy = tf.distribute.OneDeviceStrategy(device_name)
with strategy.scope():
net = tf.keras.models.Sequential([
tf.keras.layers.Dense(1)])Conv
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
28x28输进去在flatten会变成16*5*5,这个输入要计算就非常离谱。
#技巧——用单位输入确定输出
X = torch.randn(1, 1, 224, 224)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
X = tf.random.uniform((1, 224, 224, 1))
for layer in net().layers:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = tf.keras.layers.Conv2D(1, (1, 2), use_bias=False)
def net():
return tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=5, activation='sigmoid',
padding='same'),
tf.keras.layers.AvgPool2D(pool_size=2, strides=2),
tf.keras.layers.Conv2D(filters=16, kernel_size=5,
activation='sigmoid'),
tf.keras.layers.AvgPool2D(pool_size=2, strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation='sigmoid'),#tensorflow就很舒服
tf.keras.layers.Dense(84, activation='sigmoid'),
tf.keras.layers.Dense(10)])$(\frac{n+2p-f}{s}+1)\times (\frac{n+2p-f}{s}+1)$ 不是整数就向下取整
pytorch训练结构和animator使用
不过tensorflow的训练是用自定义的回调函数配合net.fit()指定在每个epoch开始和结束时发生的事。
两个train结构,十分有==参考价值==:https://zh-v2.d2l.ai/chapter_convolutional-neural-networks/lenet.html
tensorflow一般流程,定义->net.build->net.compile->net.fit->net.evaluate
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
Modern
VGG块中,每个卷积层(数量是超参数)的输出都是一样的,而且(n-3+2)/1+1 = n,所以不改变大小,只在池化层减半然后通道翻倍。组织结构值得借鉴:
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
#tensorflow不需要in_channels,padding可以使用预设的same
def vgg_block(num_convs, num_channels):
blk = tf.keras.models.Sequential()
for _ in range(num_convs):
blk.add(tf.keras.layers.Conv2D(num_channels,kernel_size=3,
padding='same',activation='relu'))
blk.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))
return blk
--------------------------------------------------------------------------
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))#五个块
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels#这一步:star
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)NiN——设计上借鉴了Alex_Net
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),#这个有默认顺序的。
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),nn.Dropout(0.5),#这有个Dropout
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),#输出通道数10为类别数。
nn.AdaptiveAvgPool2d((1, 1)),#(1,1)是高宽消到1
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
#Output:
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])GoogLeNet 抄参数:https://zh-v2.d2l.ai/chapter_convolutional-modern/googlenet.html
批量规范化层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范化)中的功能不同。 在训练过程中,我们无法得知使用整个数据集来估计平均值和方差,所以只能根据每个小批次的平均值和方差不断训练模型。 而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和方差。
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var,因为不是parameters,得手动弄。
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9) #得注意eps的值,可能会造成影响,不同框架也不一样。
return Y
-----------------------------------------------------------------
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
tf.keras.layers.Dense(120),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('sigmoid'),class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
#结构
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))#b1减半了两次,这里就不减半
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))CV
目标检测
#Augmentation
d2l.set_figsize()
img = pil.Image.open('../img/cat1.jpg')
plt.imshow(img);
transforms.RandomHorizontalFlip(img)#水平翻转
transforms.RandomVerticalFlip()#垂直
transforms.RandomRotation(45)(img)
transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2))#最终大小,像素范围,宽高比
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)#亮度、对比度、饱和度、色调
transforms.RandomCrop(size=(200, 200))#随机裁剪
transforms.CenterCrop(size=(200, 200))#中心裁剪
transforms.Resize(size=(100, 50))
#更多的https://blog.csdn.net/comway_Li/article/details/96138551
train_augs = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
test_augs =transforms.Compose([
transforms.ToTensor()])
dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,transform=augs, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers= 4)
#模仿👇就能在线生成多张啦
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]Fine tuning
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#如果选择的模型里有BatchNormalization,就不用这个
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),#随机裁剪成224,
#👆默认值scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333)
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256), #测试时大小标准化。
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)#还能直接拿到输入输出shape,直接print改结构
nn.init.xavier_uniform_(finetune_net.fc.weight);
#注意最后的fc层在optim中设置10倍的学习率。
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group: #单独改learning_rate
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)这一块基本都是用C++、cuda实现,不然效率太低,而且会有大量的tricks,小细节太多
所以尽量用别人已经成熟的包。
# 输入参数boxes可以是长度为4的张量,也可以是形状为(,4)的二维张量,其中是边界框的数量。
set_index方法,可以使用现有列设置单索引和复合索引 https://www.cnblogs.com/cgmcoding/p/13691142.html
reset_index,重置DataFrame的索引,并使用默认索引。如果DataFrame具有MultiIndex,则此方法可以删除一个或多个级别
遍历 https://www.delftstack.com/zh/howto/python-pandas/how-to-iterate-through-rows-of-a-dataframe-in-pandas/
tensor.unsqueeze(dim)#插入维度
#一次next返回一个batch[0]==图像,batch[1]==labels
labels的shape==[batch_size,num_box,5]#5是[种类,左上x,y,右下x,y]/也有可能是左上+高宽
imgs = (batch[0][0:10].permute(0, 2, 3, 1))#把通道维挪到最后,牛啊
#返回的锚框变量Y的形状是(批量大小,锚框的数量,4) 很丧心病狂,但是大家都用这个方法。(我没看懂它的生成)
torch/np.meshgrid()函数常用于生成二维网格,比如图像的坐标点。
torch.stack是在新维度堆叠
torch.repeat是复制后拼接,torch.repeat_interleave是直接复制 https://blog.csdn.net/weixin_42516475/article/details/117199456
把我看傻了:https://zh-v2.d2l.ai/chapter_computer-vision/anchor.html 太难理解了这数据。

SSD
设目标类别的数量为q。这样一来,锚框有q+1个类别,其中0类是背景。
特征图的高和宽是h和w,每个单元生成a个锚框,共需对hwa个锚框进行分类。
使用全连接层作为输出,很容易导致模型参数过多。 回忆 7.3节一节介绍的使用卷积层的通道来输出类别预测的方法, 单发多框检测采用同样的方法来降低模型复杂度。输出通道数为$a(q+1)$,其中索引为$i(q+1)+j(0≤j≤q)$的通道代表了索引为$i$的锚框有关类别索引为$j$的预测
#类别预测层
def cls_predictor(num_inputs, num_anchors, num_classes):
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
#边界框预测层
def bbox_predictor(num_inputs, num_anchors):
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)把通道、高和宽全部合并,就可以不用为每个分辨率单独配置loss啥的,计算十分方便高效。
损失函数用L1,因为可能偏差特别大
语义分割
要实现RGB和VOC的相互map其实用python实现是比较慢的
#@save
def voc_rand_crop(feature, label, height, width):
"""随机裁剪特征和标签图像"""一定得同步
rect = torchvision.transforms.RandomCrop.get_params(
feature, (height, width))#返回bounding box
feature = torchvision.transforms.functional.crop(feature, *rect)#按照框去crop
label = torchvision.transforms.functional.crop(label, *rect)#同样的操作得对label执行
return feature, label
imgs = []
for _ in range(n):
imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300)
imgs = [img.permute(1, 2, 0) for img in imgs]#一般画的时候得把channel放到最后。
d2l.show_images(imgs[::2] + imgs[1::2], 2, n);
-------------------------------------------------------------
VOCS数据集的图片大小很多不一致的。
#resize是个问题,很多像素是由插值得到的,但是label不能插值
#所以图片分割都用crop size,然后移除掉尺寸小于随机裁剪所指定的输出尺寸的图像
# 打印第一个小批量的形状会发现:与图像分类或目标检测不同,这里的标签是一个三维数组。
feature:torch.Size([64, 3, 320, 480])
label:torch.Size([64, 320, 480]),loss的时候要连续两次.mean(1)Recurrent
def read_time_machine(): #@save
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
lines = read_time_machine()
#token词元是文本的基本单位 如果字符串是token,还得学词是怎么构成的
def tokenize(lines, token='word'): #@save
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
#将训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)。 然后根据每个唯一词元的出现频率,为其分配一个数字索引。
class Vocab: #@save
"""文本词表"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序
counter = count_corpus(tokens)#预处理一下,能输入多种结构
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# 未知词元的索引为0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}#字典解析!!!???
#把读到的加进去,太cool了这代码。
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):#定义后能用索引来变换
if not isinstance(tokens, (list, tuple)):#单个token
return self.token_to_idx.get(tokens, self.unk)#如果没找到就返回未知——‘0’
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens): #@save
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表,如果是元组就不展平,比如zip弄出的二元组列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]#神马神奇操作!!!
return collections.Counter(tokens)
#整合
def load_corpus_time_machine(max_tokens=-1): #@save
"""返回时光机器数据集的词元索引列表和词表"""
lines = read_time_machine()
tokens = tokenize(lines, 'words')
vocab = Vocab(tokens)
# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,
# 所以将所有文本行展平到一个列表中
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab
corpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)#n元语法实现
tokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]#语料库,为了简便处理成单列表
vocab = d2l.Vocab(corpus)
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
bigram_vocab.token_freqs[:10]
trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
trigram_vocab.token_freqs[:10]
#读取长序列数据,不能总像之前一样读取整个进来,当序列变得太长而不能被模型一次性全部处理时, 我们可能希望拆分这样的序列方便模型读取。而且之前那种方式,数据冗余很大,一个数据点可能被用到了好几次。
#我们可以从随机偏移量开始划分序列, 以同时获得覆盖性(coverage)和随机性(randomness)。 下面,我们将描述如何实现随机采样(random sampling)和 顺序分区(sequential partitioning)策略。
#参数batch_size指定了每个小批量中子序列样本的数目, 参数num_steps是每个子序列中预定义的时间步数。
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 算出子序列的个数(去尾),减去1,是因为我们需要考虑标签(比子序列偏移一个序列)
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
#每个batch可以读进多少个子序列。没处理好,最后丢掉了几个子序列。。
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch] #最多预测t个长度。
yield torch.tensor(X), torch.tensor(Y)
#如果是连续的可以拿到更多的空间信息,允许我们做出更长的序列出来,这代码太强了
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
#划分直接以batch_size为单位,batch里的子序列逻辑相连。算出最终取多少个tokens
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
class SeqDataLoader: #@save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
def load_data_time_machine(batch_size, num_steps, #@save
use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocabRNN
深层:lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)其实就是加了个num_layer
双向:lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
#我们每次采样的小批量数据形状是二维张量: (批量大小,时间步数)。
#one_hot函数将这样一个小批量数据转换成三维张量, 张量的最后一个维度等于词表大小(len(vocab))。
X = torch.arange(10).reshape((2, 5))
F.one_hot(X.T, 28).shape —— torch.Size([5, 2, 28])
#我们经常转换输入的维度,以便获得形状为 (时间步数,批量大小,词表大小)的输出。 这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。
def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
#简洁实现
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
state = torch.zeros((1, batch_size, num_hiddens))#隐藏层数,批量大小,隐藏单元数
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state) #Y的shape和X是一样的;state_new和state是一样的
#RNN的输入输出https://blog.csdn.net/Fantine_Deng/article/details/111356280
#@save
#rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层。
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)#input的shape:(num_steps, batch_size, len(vocab))
X = X.to(torch.float32)
Y, state = self.rnn(X, state)#y的shape:(时间步数,批量大小,隐藏单元数)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# output形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)//lstm_layer = nn.LSTM(num_inputs, num_hiddens)
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)#最后一个是隐藏层数
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
----------------------------------------------------------------------
gru_cell = tf.keras.layers.GRUCell(num_hiddens,
kernel_initializer='glorot_uniform')
gru_layer = tf.keras.layers.RNN(gru_cell, time_major=True,
return_sequences=True, return_state=True)
device_name = d2l.try_gpu()._device_name
strategy = tf.distribute.OneDeviceStrategy(device_name)
with strategy.scope():
model = d2l.RNNModel(gru_layer, vocab_size=len(vocab))
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, strategy)#RNN的训练
#当使用顺序分区时, 我们只在每个迭代周期的开始位置初始化隐状态。 由于下一个小批量数据中的第个子序列样本 与当前第个子序列样本相邻, 因此当前小批量数据最后一个样本的隐状态, 将用于初始化下一个小批量数据第一个样本的隐状态。 这样,存储在隐状态中的序列的历史信息 可以在一个迭代周期内流经相邻的子序列。 然而,在任何一点隐状态的计算, 都依赖于同一迭代周期中前面所有的小批量数据, 这使得梯度计算变得复杂。 为了降低计算量,在处理任何一个小批量数据之前, 我们先分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。
#当使用随机抽样时,因为每个样本都是在一个随机位置抽样的, 因此需要为每个迭代周期重新初始化隐状态
#@save
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):
"""训练网络一个迭代周期(定义见第8章)"""
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和,词元数量
for X, Y in train_iter:
if state is None or use_random_iter:
# 在第一次迭代或使用随机抽样时初始化state
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
# state对于nn.GRU是个张量(即不参与更新)
state.detach_()
else:
# state对于nn.LSTM或对于我们从零开始实现的模型是个张量
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
else:
l.backward()
grad_clipping(net, 1)
# 因为已经调用了mean函数
updater(batch_size=1)
metric.add(l * y.numel(), y.numel())
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,
use_random_iter=False):
"""训练模型(定义见第8章)"""
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
# 初始化
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)
# 训练和预测
for epoch in range(num_epochs):
ppl, speed = train_epoch_ch8(
net, train_iter, loss, updater, device, use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))机器翻译和
编码器-解码器
#机器翻译的数据集是由源语言和目标语言的文本序列对组成的。 因此,我们需要一种完全不同的方法来预处理机器翻译数据集, 而不是复用语言模型的预处理程序。
def preprocess_nmt(text):
"""预处理“英语-法语”数据集"""
def no_space(char, prev_char):#空格的好处是切词的时候能把标点切成一个词
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格,对utf-8的半角空格什么的都换成空格。
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
#机器翻译中,我们更喜欢单词级词元化 (最先进的模型可能使用更高级的词元化技术)每个词元要么是一个词,要么是一个标点符号。
def tokenize_nmt(text, num_examples=None):
"""词元化“英语-法语”数据数据集"""
source, target = [], []
for i, line in enumerate(text.split('\n')):#换行符分样本
if num_examples and i > num_examples:
break
parts = line.split('\t')#制表符分语言
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
还是看原文吧:https://zh-v2.d2l.ai/chapter_recurrent-modern/machine-translation-and-dataset.html
#编码器和解码器,NotImplementedError有点cool,shi'pe
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):#用于将编码器的输出(enc_outputs)转换为编码后的状态。
raise NotImplementedError
def forward(self, X, state):#X是额外的输入
raise NotImplementedError
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
#在前向传播中,编码器的输出用于生成编码状态, 这个状态又被解码器作为其输入的一部分。
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)seq to seq太难了,看原文吧:https://zh-v2.d2l.ai/chapter_recurrent-modern/seq2seq.html
#decoder最后
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)#相当于对每个时间步,都加了一个c初始化
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super().forward(
pred.permute(0, 2, 1), label)#pytorch要求把那个softmax处理的那个维度放中间,可能for 效率
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_lossAttention
#带批量矩阵乘法
X = torch.ones((2, 1, 4))
Y = torch.ones((2, 4, 6))
torch.bmm(X, Y).shape == torch.Size([2, 1, 6])
#torch的rand函数和sort函数
n_train = 50 # 训练样本数
x_train, origin_seq = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本
x_train
tensor([0.0840, 0.1345, 0.3510, 0.5656, 0.8183, 0.9208, 1.1907, 1.3527, 1.4449,
1.5247, 1.5696, 1.7349, 1.8324, 1.8558, 1.8864, 1.9879, 2.0112, 2.0115,
2.0157, 2.1903, 2.2141, 2.2400, 2.3800, 2.4314, 2.5796, 2.6966, 2.7665,
2.8231, 2.9374, 3.0170, 3.0468, 3.1662, 3.2001, 3.2120, 3.2182, 3.2420,
3.5141, 3.5614, 3.5880, 3.6311, 3.7026, 3.8288, 4.3208, 4.3390, 4.5670,
4.6363, 4.6682, 4.7314, 4.7663, 4.9927])
origin_seq
tensor([ 8, 46, 24, 0, 6, 16, 25, 12, 13, 21, 17, 15, 30, 3, 19, 45, 31, 1,
23, 10, 48, 33, 44, 18, 35, 47, 22, 39, 5, 49, 28, 14, 7, 9, 29, 38,
37, 41, 43, 42, 36, 32, 2, 27, 40, 4, 26, 20, 34, 11])形状详见10.3加性注意力。
#查询、键和值的形状为(批量大小,数量(如n个q),特征大小),经过转换后👇
#queries的形状:(batch_size,查询的个数,1,num_hidden)
#key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
#queires和key被处理成scores 形状:(batch_size,查询的个数,“键-值”对的个数)
#values的形状:(batch_size,“键-值”对的个数,值的维度)
#返回的结果是torch.bmm(scores,values) scores还得经历掩码softmax和dropout,输出的形状为(批量大小,查询的步数,值的维度)李宏毅
HW1
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {
'seed': 5201314, # Your seed number, you can pick your lucky number. :)
'select_all': True, # Whether to use all features.
'valid_ratio': 0.2, # validation_size = train_size * valid_ratio
'n_epochs': 3000, # Number of epochs.
'batch_size': 256,
'learning_rate': 1e-5,
'early_stop': 400, # If model has not improved for this many consecutive epochs, stop training.
'save_path': './models/model.ckpt' # Your model will be saved here.
}
#tensorboard
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("runs2")
writer = SummaryWriter(comment="this_is_ex_version")#只能用默认的runs,会在子文件夹名字后面加comment
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter,new_style=False)#会分一个Loss区,里面俩张图
writer.add_scalar('Loss/test', np.random.random(), n_iter,new_style=False)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
writer.close()
------------------------
writer = SummaryWriter()#默认runs/
r = 5
for i in range(100):#会生成ab_sinx/xcosx/tanx三个文件夹,会划到ab区的一张图里
writer.add_scalars('ab', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()
%load_ext tensorboard
%tensorboard --logdir=路径,如果打开了没有子文件夹的文件夹,event名字是'.
#直方图、等例子直接查文档吧:https://pytorch.org/docs/stable/tensorboard.html
for i in range(10):
x = np.random.random(1000)#生成1000个随机数
writer.add_histogram('distribution centers', x + i, i)
import csv
from tqdm import tqdm
def save_pred(preds, file):
''' Save predictions to specified file '''
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
model = My_Model(input_dim=x_train.shape[1]).to(device)
model.load_state_dict(torch.load(config['save_path']))
preds = predict(test_loader, model, device)
save_pred(preds, 'pred.csv') 


