实用机器学习——课程:【20课时】关注DS的方方面面,很实际
Coentents
Machine Learning topics that matter but are often skipped
• Data: collection, preprocessing, features, dataset shift, non-iid. data (非独立同分布)
• Model training: model selection, model tuning, transfer learning, distillation, multimodality, scalability
• Deployment: efficiency, serving, fairness

数据获取
PREFACE
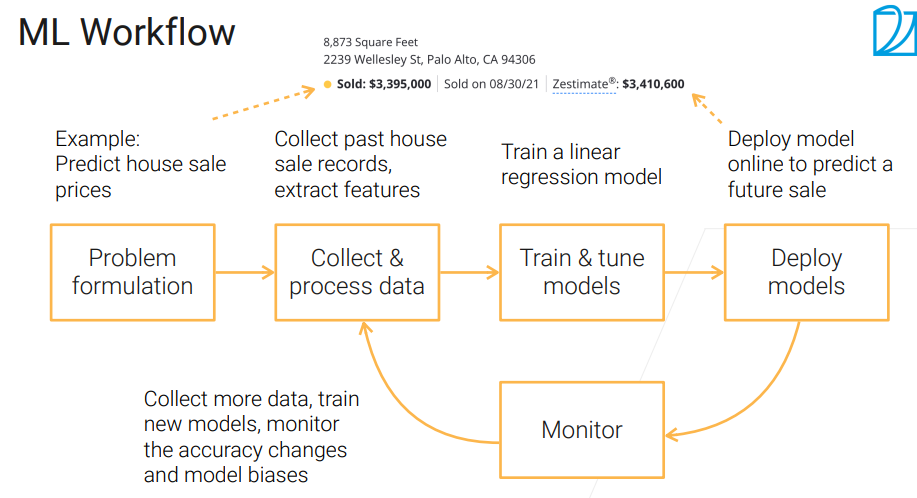
可以先训练简单的模型,比如五六十年的线性回归,用来测试数据的好坏!部署不是结束,这是个不断迭代的过程。
算法本身不会不公,但数据会有偏差。蒸馏是指,将模型提炼出易于部署的,较小较快的数据。

首先要关注自己公司的核心业务,把他做好,可能运气好会碰到简单问题,但也可能是无人车之类的复杂问题:
我们不缺数据,但是非常缺高质量的数据。最近七八年,模型的复杂度呈指数增长,越来越贵,越需要越来越多的数据。
当前一些行业中ML的应用:

场景分工:沐神说现在行业还很缺data scientists,这门课主要关注的就是Data science 职业规划👇

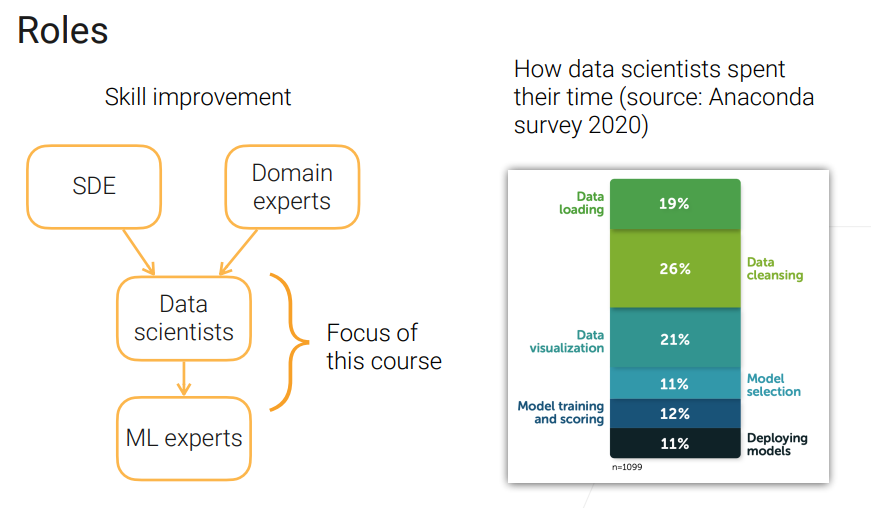
领域专家还要提出建议,将机器学习用在合适的地方,因为这是一件很贵的事情。
SDE有很多活要干,包括管理计算资源,能够有序的训练模型整个集群并加以管理(什么定时训练,还有负载均衡),pipeline,还有可能部署很多不同版本的新老模型、实验模型,异常模型上线、下线。
==数据科学家==有一点“全栈的味道”,什么都要干,看上图右边,获取、clean、可视化、选择、训练、部署。【区别大数据开发者】
ML专家根据业务对模型的要求,专门定制化、优化模型,包括很多模型的预训练数据都是学术上的数据集,要做出对应修改,还有比如蒸馏数据模型以使得模型的规模符合要求。 还可能负责领域研究,写论文
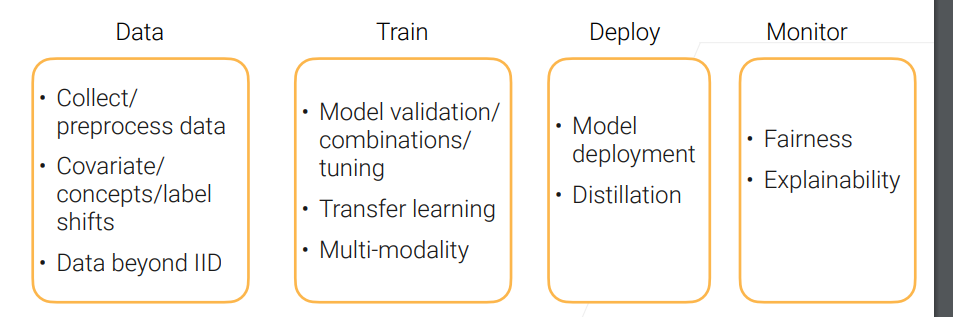
data的协变量、概念、标签都会发生变化,而且还有许多不是假设中独立同分布的情况。
训练会讲模型怎么做验证,怎么做融合,调超参数。还有最近兴起的:从不同数据源获得type(文本、图片)的数据糅合起来做个大模型
部署,蒸馏 监控,公平性,可解释性(理解模型在干什么)
数据获取
当你成功把业务定义为ML问题后,第一步就是看你有没有足够多的数据,这部分是讲没有的:
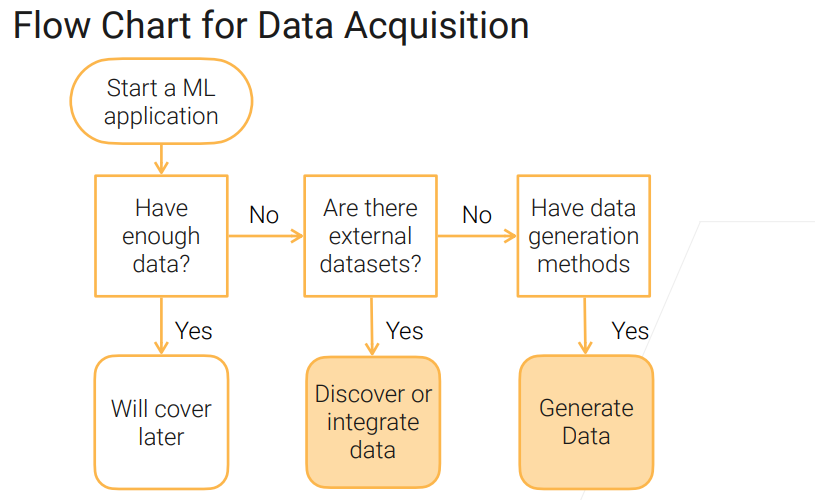
- 如果你有办法找到数据,那就找数据,然后融合你有的数据
- 否则就看你有没有数据生成的办法来生成数据了
Discover
根据不同的用途,你要找的数据也不一样,数据集 $\neq$ 数据,做产品很可能没有数据集用,就需要自己收集,要注意的是收集的数据能够覆盖到场景的方方面面

数据集
• MNIST: digits written by employees of the US Census Bureau 【有个叫Fashion-Mnist的】
• ImageNet: millions of images from image search engines
• AudioSet: YouTube sound clips for sound classification
• LibriSpeech: 1000 hours of English speech from audiobook
• Kinetics: YouTube videos clips for human actions classification
• KITTI: traffic scenarios recorded by cameras and other sensors
• Amazon Review: customer reviews and from Amazon online shopping
• SQuAD: question-answer pairs derived from Wikipedia
More at https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research
Find Datasets
• Paperswithcodes Datasets: academic datasets with leaderboard 常用学术界的数据集都有,而且可以看到各论文在DS上精度
• Kaggle Datasets: ML datasets uploaded by data scientists 非常多,层次不齐(用户可上传)
• Google Dataset search: search datasets in the Web 搜索引擎
• Various toolkits datasets: tensorflow, huggingface 工具自带的,比如torch的 hugging face专注文本的transformers
• Various conference/company ML competitions 一般竞赛数据集质量高,而且应用比较新。(还有奖金)
• Open Data on AWS: 100+ large-scale raw data 非常大,P级别
• Data lakes in your own organization 公司的数据堆砌
三种数据集:学术、竞赛、原始(处理后可能只剩下一丢丢)
Data integration——数据库的tabel join 过程,合并许多表到同一。 缺失数据处理、去掉语义重复值。
Data curation can be a big projection involving multiple teams.——Processing pipeline, storage, legal issue, privacy
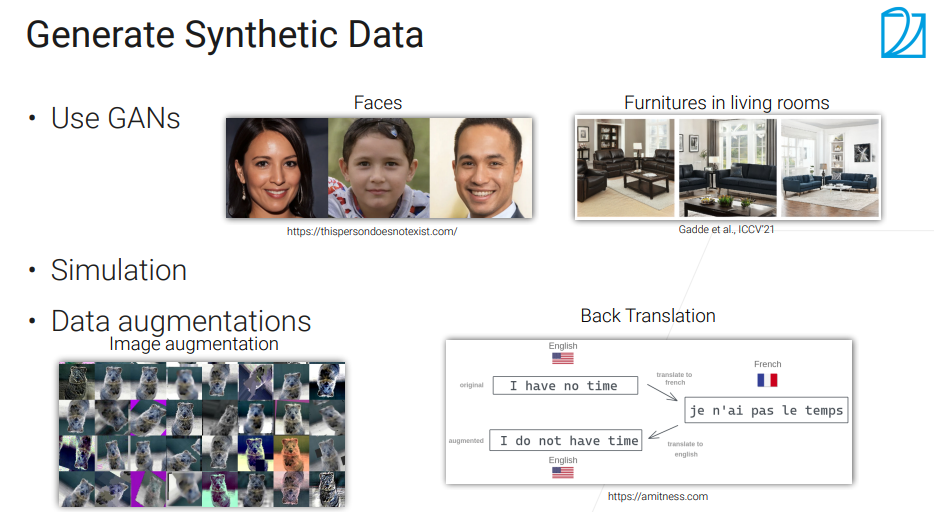
GAN生成、图像增强、文本来回翻译哈哈
工业上的产品就不要过于看重经典学术数据集的效果,还是得看实际。
网页抓取
$\neq$ 爬取
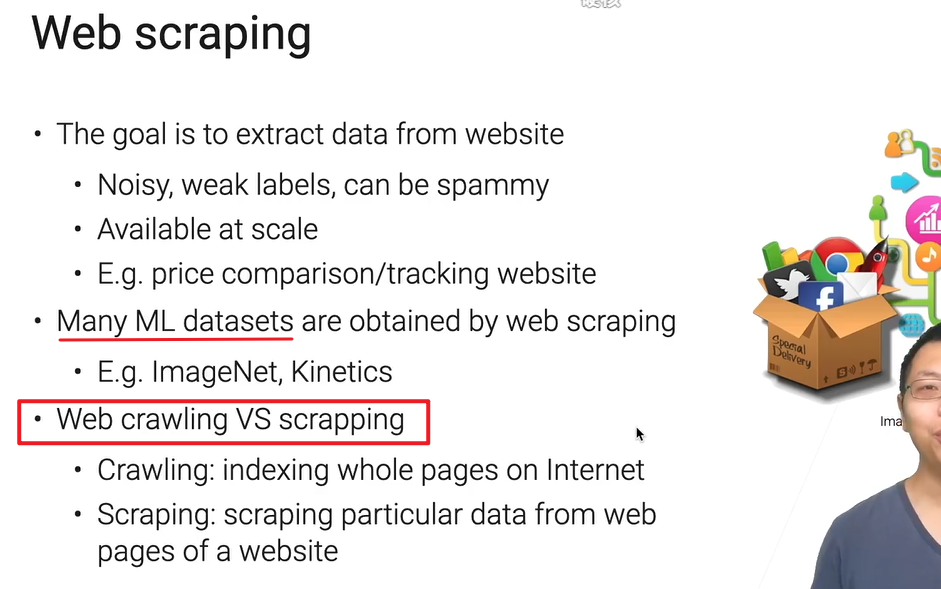
我们只关心网页里面的某些数据,爬是指感兴趣的网页都整个弄下来存好,抓取是只提取感兴趣的,可能变成table。
尽量假装成真人,整的跟攻防一样。
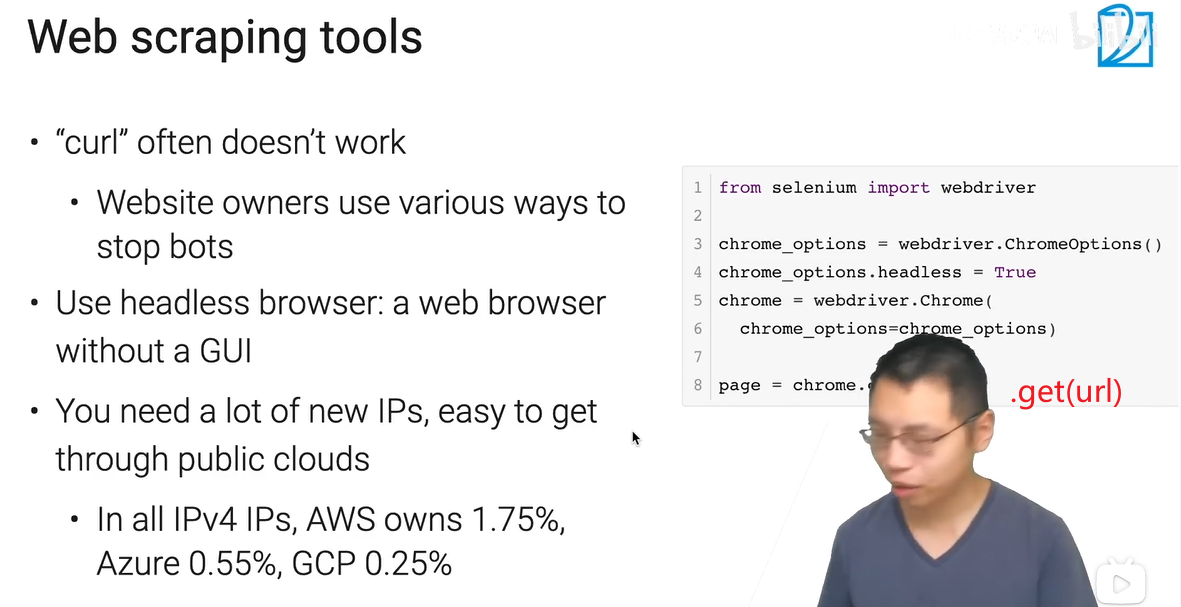
整下页面,页面解析,例子:
获得id列表后,依次替换url的部分内容,遍历访问一堆房子页面,要自己去看网页结构,找到信息在哪。
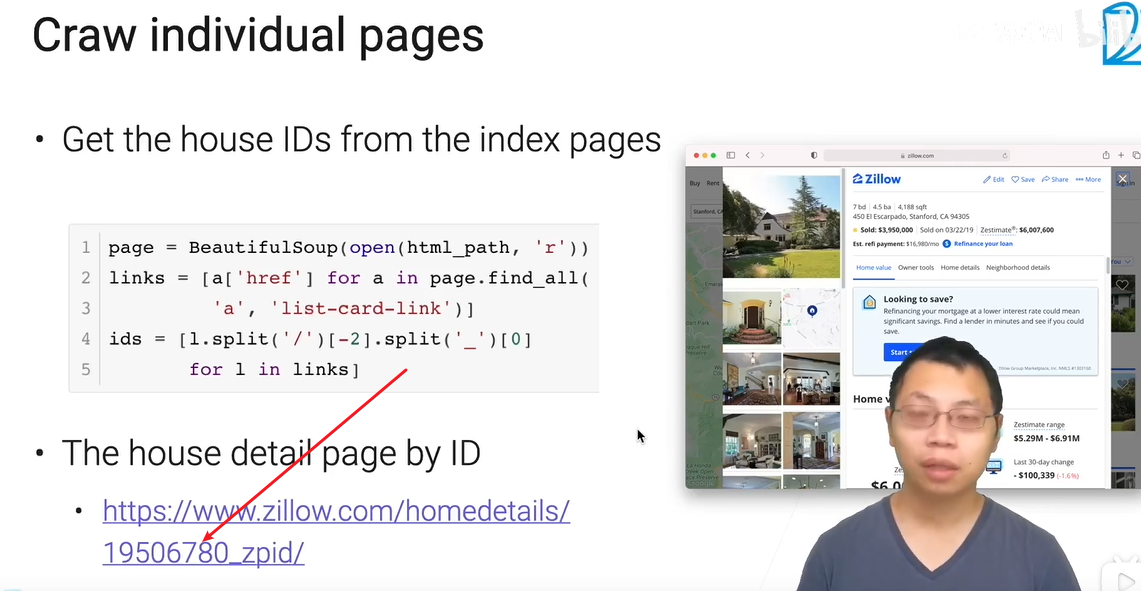
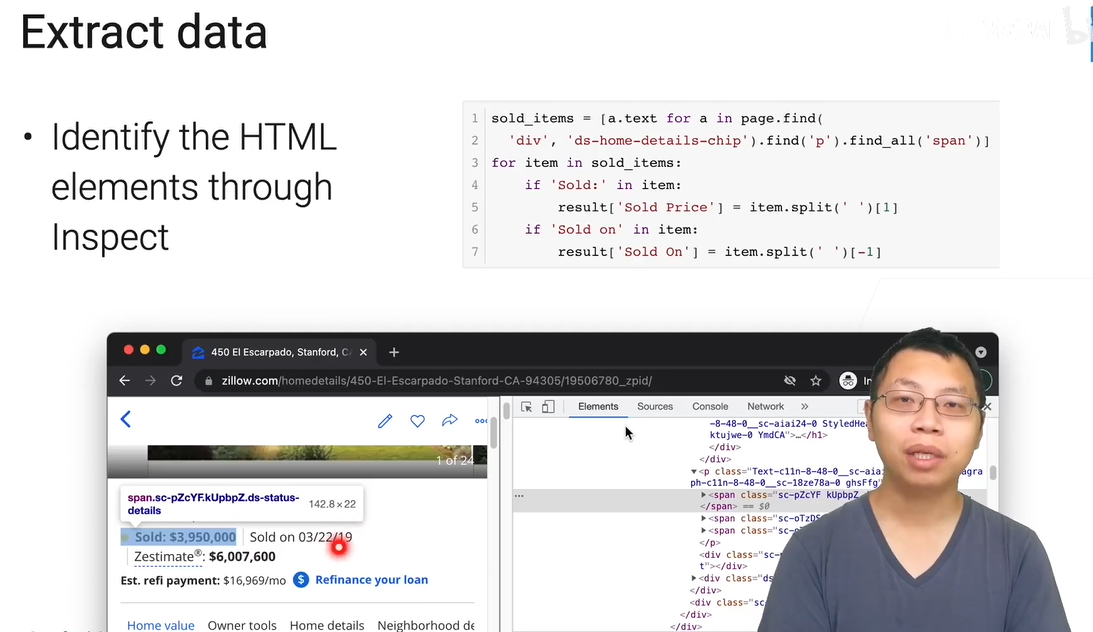
属于是重复劳动力,有一些自动化工具做。
成本
用云主要有点需求的是内存,开几个chrome挺耗内存的(2G差不多够用),CPU和网络带宽最低级就好,基本用不满的。

被banned了,重启机器可以得到一个新的IP,然后继续爬。
除了文本,图片也是需要的,之前提到的multi-modality,就能利用多维数据【成本翻了很多倍】
基本思路:通过正则表达式获得所有id,然后构建url列表,随后遍历抓取。
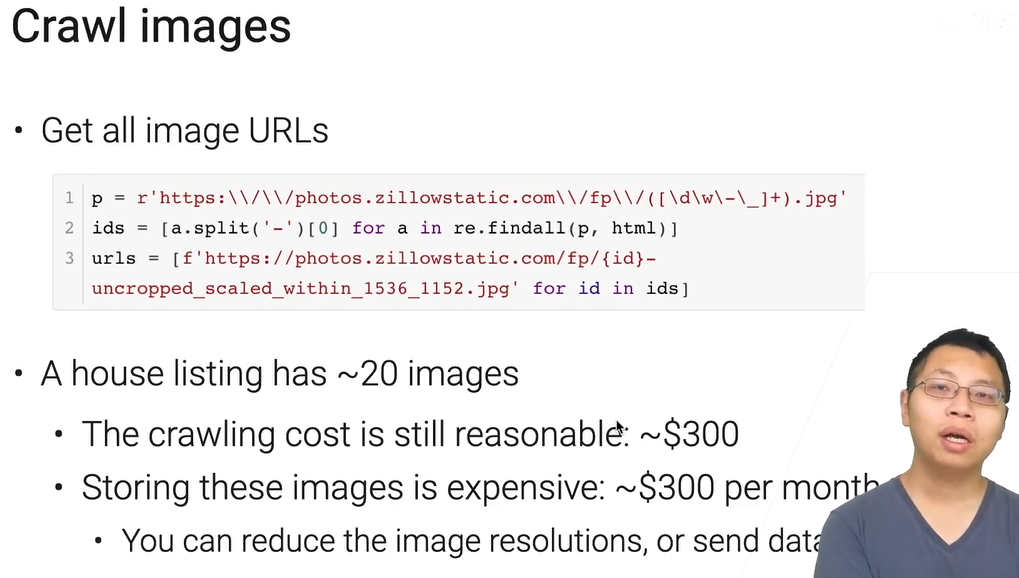
主要开销在存储(如果存云端),你可以减少图片尺寸或慢慢传回来,后续会介绍其他方法。
法律考虑
爬取行为本身不犯法,但是要注意版权、敏感隐私信息什么的,把有版权的数据存在本地是违法的。(还有robots)

尤其是如果你爬取不是个人做分析,而是用于公司盈利,可以咨询公司的法律部门和律师。
如果按照沐神刚才说的一堆云实例来爬,100G 1个T可能也就几十块钱。
数据标注
当你有了足够数据后,你有几个选项,提高标注、数据或模型,本节讲标注。
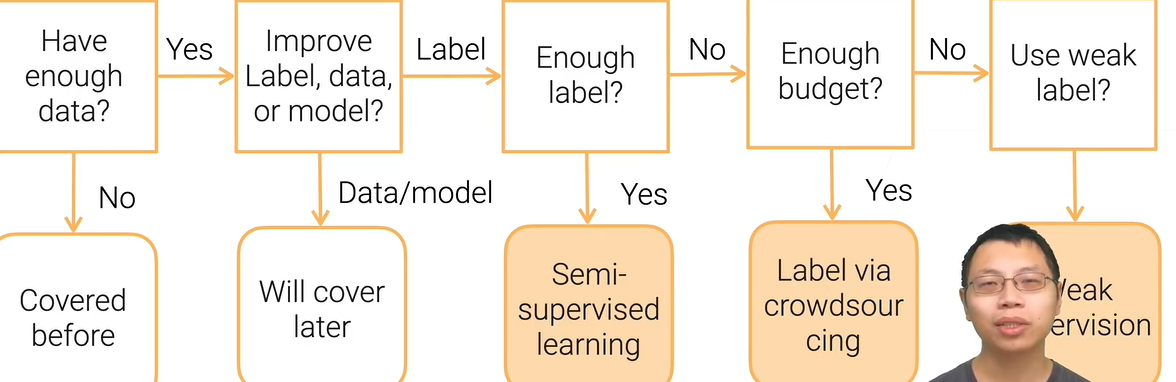
又没钱标注又不够,就得用弱监督学习 weak supervision。
半监督学习
第三个流形假设,可能数据具有内在结构,复杂性只分布在几个维度,远远比你看到的要低。
scenario 设想

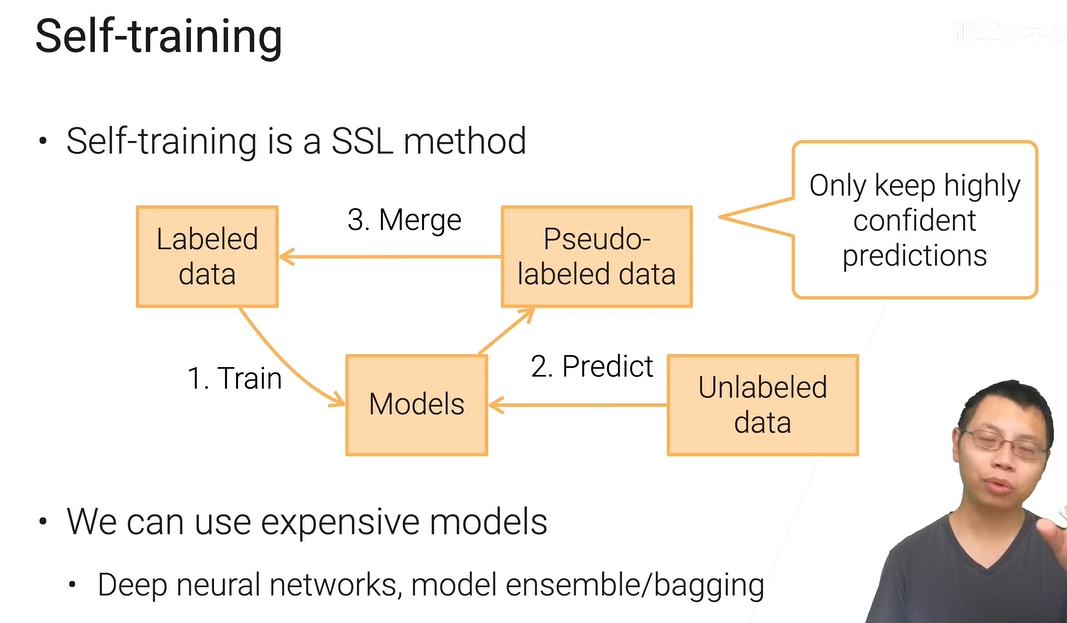
自-训练——SSL的一种实现方法
由于不用线上部署,可以在本地选择模型复杂度更高,更贵的模型进行训练【deeper、ensemble】【不计成本、只要精度】。
当然,在右边“keep highly confident predictions”这就能整出各种算法。
众包——有钱人的选择
现在作为愈加广泛的选择,座的人越来越多了,成本也越来越低,【真的有数据标注村这种东西吗】

减少任务复杂度,能更容易找到更多的人做,价格也更便宜。
因为是人做的,质量会参差不齐,你得来做质量控制,或者找公司。

标注公司会帮你设计好这些,但是得加钱~
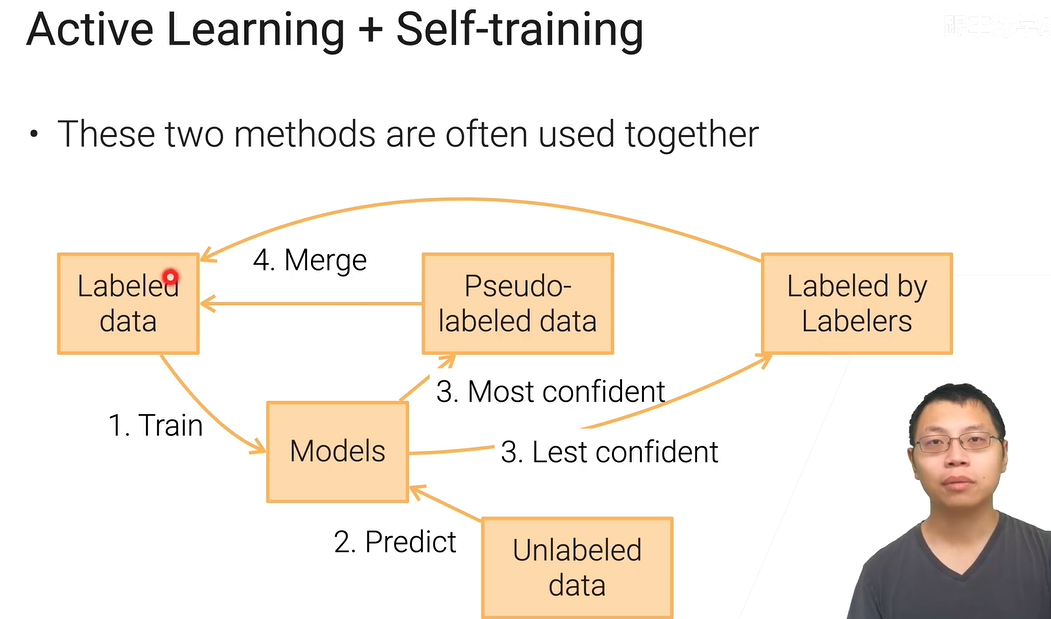
主动学习
结合了半监督学习的假设(少量已标号)和众包,最大化利用人的帮助。训练出模型,吐出不确定的,再训练新的,不断迭代。
同样可以选择比较贵的模型,比如练多个模型投票

混用
高级啊
质量控制
挺麻烦的事,因为不是找的真正专家来做,有可能故意,有可能你的任务他没看懂,反正可能性很多。还有标的不好的。

还有对标注工进行评估,筛掉部分。
Weak Supervision
半自动生成标号,比人标的差一点,但是还不错,够训练模型。
启发式学习,通过数据编程,把你对数据的认知转换为一些限制,然后
还有使用各大公司AI产品标号,然后聚合
数据预处理
探索性数据分析
只做了一小些分析,类似EDA,一般做完以后有很多块,可以share 给大家
本节slide:https://c.d2l.ai/stanford-cs329p/_static/notebooks/cs329p_notebook_eda.slides.html#/2
notebook:https://colab.research.google.com/drive/1zzuFXZQ0djOLZOzdQ4GNlZO-dZjdgTsv#scrollTo=ol9CO2GAzZnN
pandas基本是首选,数据要是几百G可选用别的框架更快,也可采样以后用pandas
matplotlib和十几年前matlab的用法比较像,seaborn在此基础上提供了更多的画法
svg分辨率高一点,不然默认分辨率属实是有点低。
推荐:文本默认存成一个zip压缩文件,现代工具可以直接读取使用:data = pd.read_csv('house_sales.zip')
当然图片这种就没什么用,已经做了很好的压缩。使用feather格式,它比 CSV 读取速度更快,但使用更多磁盘空间。
data = pd.read_csv('house_sales.zip', dtype='unicode')
data.to_feather('house_sales.ftr')
data = pd.read_feather('house_sales.ftr')data.drop(....,inplace = True) 如果只用跑一次,直接操作内存可以省点内存。(只能跑一次xs)
要check它的数据的types,一般object就是pandas识别不了,或者不能转过去的类型,数据类型转换也是清洗的一部分。
#把代码列在这。
data = pd.read_csv('house_sales.zip')
data.shape
data.head()
#保留缺失值小于30%的列
null_sum = data.isnull().sum()
data.drop(columns=data.columns[null_sum > len(data) * 0.3], inplace=True)
data.dtypes
#清理金钱列表,转成float类型,pandas的place自带正则表达式实现
currency = ['Sold Price', 'Listed Price', 'Tax assessed value', 'Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]', '', regex=True).replace(
r'^\s*$', np.nan, regex=True).astype(float)
#清洗占地面积列表,转成同一单位的float
areas = ['Total interior livable area', 'Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True #check字符串
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','', regex=True).astype(float)
col[acres] *= 43560
data[c] = col
data.describe()#基本统计值,从中能看出数据的很多问题,比如看极值,然后看一下这些统计值符不符合正常逻辑。
#通过筛选看看你认为异常的有多少。
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal]
sum(abnormal)
#画个直方图看看分布,一般对价格取个log,画的图视觉效果好,不会太奇怪,因为钱分布差距很大
#插一句,沐神说再几千-几万那有个小峰值,可能是把出租的数据误爬了。
ax = sns.histplot(np.log10(data['Sold Price']))
ax.set_xlim([3, 8])
ax.set_xticks(range(3, 9))
ax.set_xticklabels(['%.0e'%a for a in 10**ax.get_xticks()]);
#看一下房子有多少种类,后面的基本都是噪音,要后续清理的,比如同一种但多个名字。
data['Type'].value_counts()[0:20]
#画一个种类-价格的密度分布图(指定kind为‘kde’),然后可以看到房子的类别显然和价格是挂钩的
types = data['Type'].isin(['SingleFamily', 'Condo', 'MultiFamily', 'Townhouse'])
sns.displot(pd.DataFrame({'Sold Price':np.log10(data[types]['Sold Price']),
'Type':data[types]['Type']}),
x='Sold Price', hue='Type', kind='kde');
#观察种类-房子均价的箱型图,这种方法能比较好的观察不同分布的对比。
data['Price per living sqft'] = data['Sold Price'] / data['Total interior livable area']
ax = sns.boxplot(x='Type', y='Price per living sqft', data=data[types], fliersize=0) #相当于x = d['Type']
ax.set_ylim([0, 2000]);
#同样,查看地域对房子均价的影响,通过邮政编码划分地域。
d = data[data['Zip'].isin(data['Zip'].value_counts()[:20].keys())]
ax = sns.boxplot(x='Zip', y='Price per living sqft', data=d, fliersize=0)
ax.set_ylim([0, 2000])
ax.set_xticklabels(ax.get_xticklabels(), rotation=90);
#查看相关系数矩阵!!!
_, ax = plt.subplots(figsize=(6,6))
columns = ['Sold Price', 'Listed Price', 'Annual tax amount', 'Price per living sqft', 'Elementary School Score', 'High School Score']
sns.heatmap(data[columns].corr(),annot=True,cmap='RdYlGn', ax=ax);亲自实验的小补充:一定要设好图的范围,不然可能一片空白
数据清理
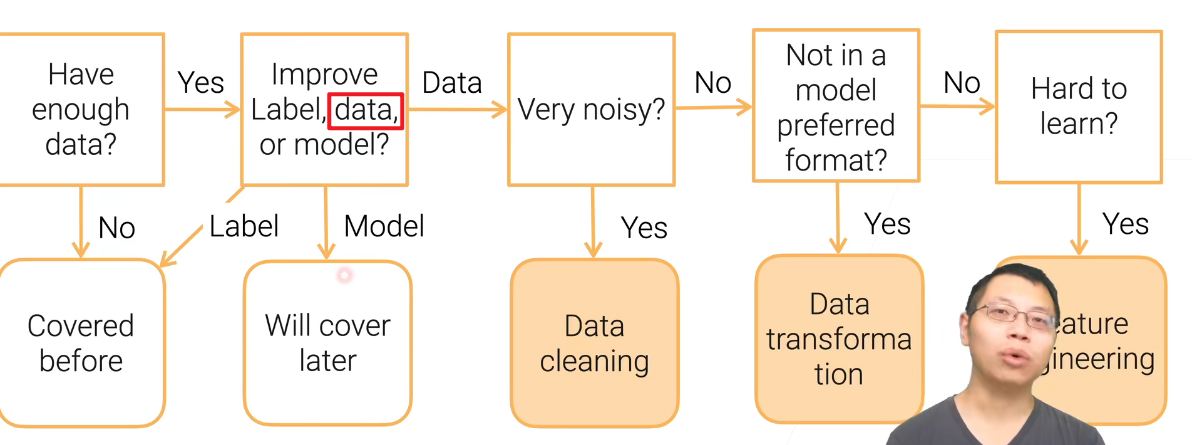
如果数据不干净,讲座数据清理;如果数据比较干净,但是不是你想要的格式,叫做数据变换;如果都没问题,但是对于模型训练比较困难,那就做特征提取。
数据的错误
无可避免,比如异常值,缺失值,还有语义上错误的数据,一般机器学习模型都对脏数据有一定的抵抗性,但你的模型不可避免地有精度的下降,以及拟合到错误分布的后果:用错误的数据训练出模型,用户使用后给你带了错误的反馈,如此迭代,错误累积。
工业上的问题就是:你没法获得如同学术数据集那样纯净的数据,也就没有一个比较好的性能参照,你不知道你清理了数据以后,到底会不会有很好的提升。

一般的错误有:
数值越界,违反规则,违反模式(语法)

不同错误举例:
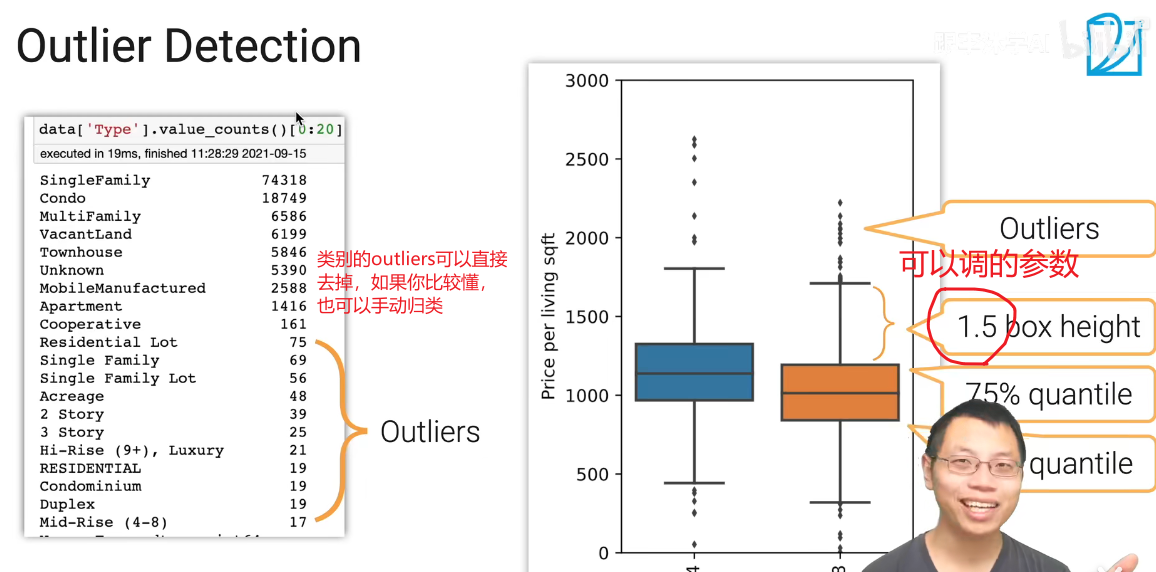
可以设计很多规则,如果不满足,要么编写fix的逻辑,要么直接去掉。
这是个迭代的过程,一边看数据,一边总结规则。


这俩都是比较一般的迭代过程,基本不用手写,有很多工具提供了不错的GUI界面,可以供使用。沐神推荐:
OpenRefine——开源桌面应用程序,用于清除数据并将其转换为其他格式,该活动通常称为数据整理。
Trifacta Wrangler——专为分析师设计,用于探索、转换和丰富原始数据为干净和结构化的格式。
当然每个工具都有局限性,必要时组合多个工具进行清理。
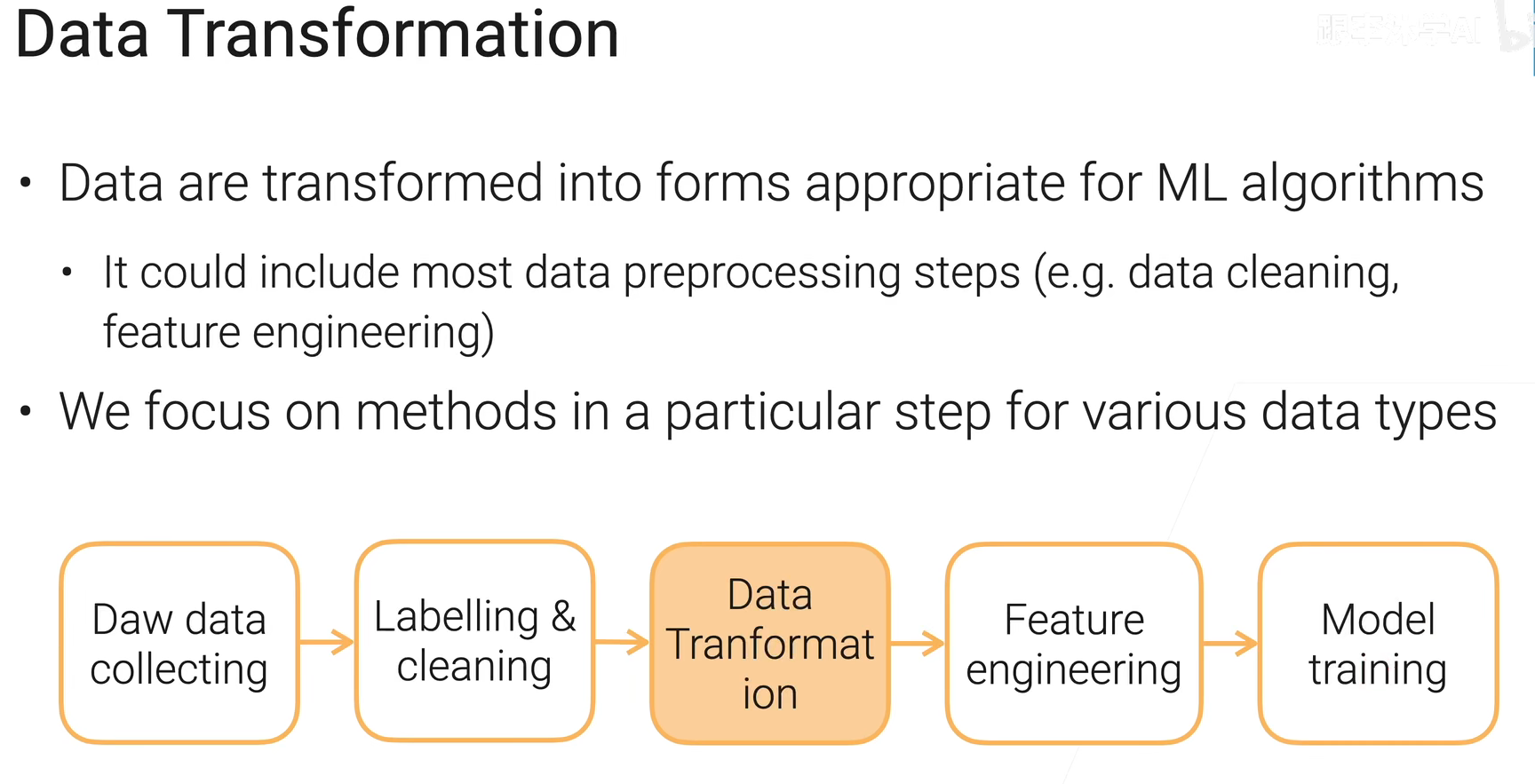
数据变换
变换指的是,变换成机器学习算法能用的合适的数据类型。
沐神:一般来说广义的数据变形基本可以包括数据预处理的所有步骤,当然我们这里关注狭义的,也就是👇:
实数值
机器学习是数值敏感的,如果不经过数值范围的调整,很容易遇上梯度爆炸和消失的问题,而且在没有先验知识的条件下,数值之间的不均衡就好像赋予了一些不公平的权重。
Z-score的效果是很不错的。
Log也很好,而且log上面的加减还能等价原始数值的乘除(这相当于是关注百分比的关系而不是绝对值得关系),当更关注误差的相对值而不是绝对值时尤其有用(比如money,之前那个房价问题),通常用于比较大而且分布较广的正数。

图片数据
机器学习其实对低分辨率的图片做的还是挺好的(毕竟不像人是看个全局,ML都是一个一个像素看的),所以resize成比较小的尺寸,或者把中间的一块抠出来(知道边上是背景)这种既能节省存储空间,又能快速读取的方法是十分可取的。

前辈们通过教训明白,下采样确实会带来精度的下降(顺便提醒了我们一番debug的艰难),所以得权衡。
image whitening:图片中很多的像素取值没什么用,可以通过降维的方法,减小像素取值
图片放在一个一个文件里读的自然慢,如果都放在一个文件里然后指定特殊的格式那肯定就会快一些
视频
一般都是截取视频中你感兴趣的片段进行存储、训练。

权衡:视频提供比图片好很多的压缩,但是代价是读取效率(包括解码以及视频算法常用的采样)就会变得很低。
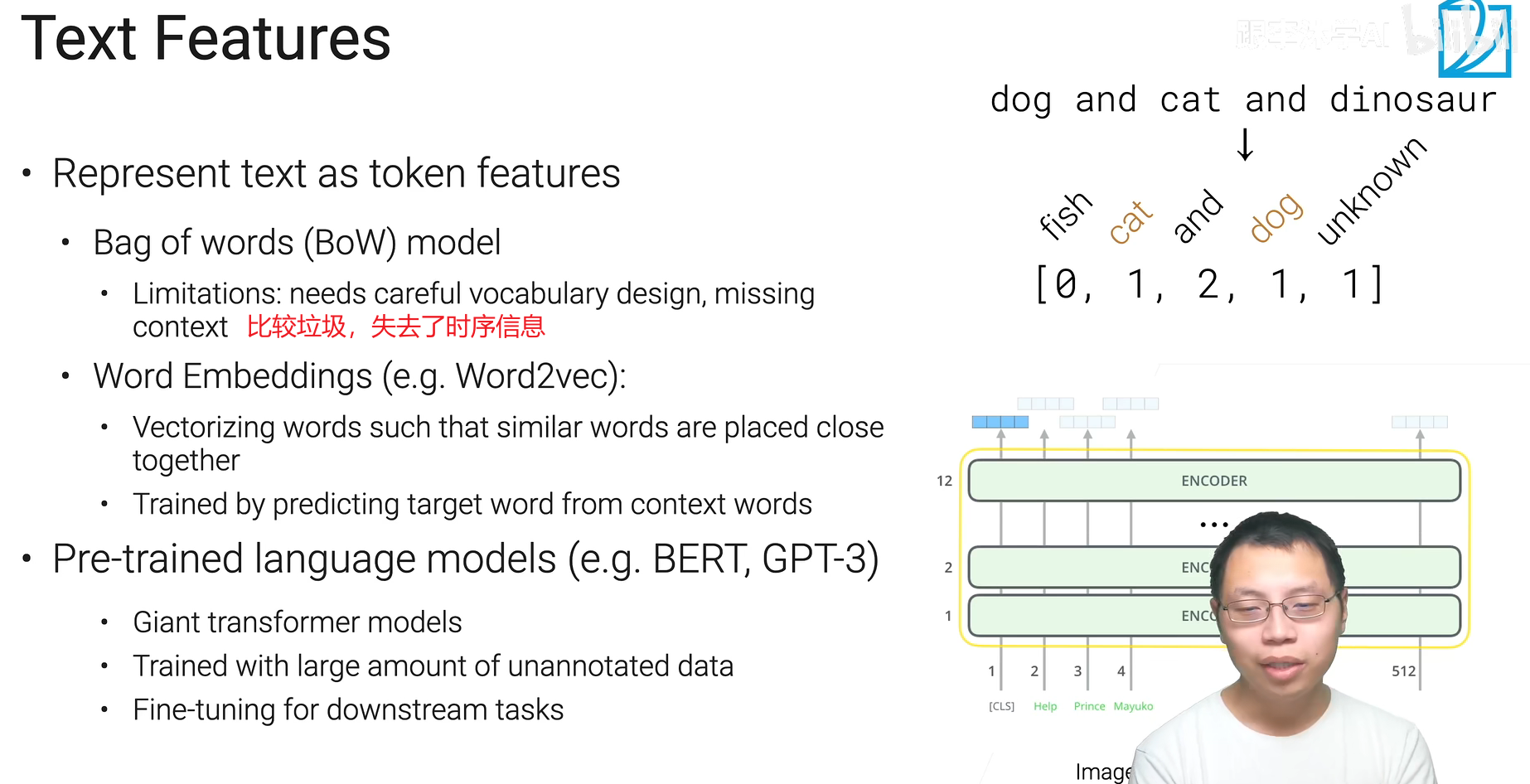
文本

lemmatization——词形还原,上图中系动词的代换是语法化,后面车那个是词根化。
词元化:词、字符、还有最近新起的子词(subwords)子词可以用来处理很大的数据集,生成一个相对较小的字典处理许多生僻词。

特征工程
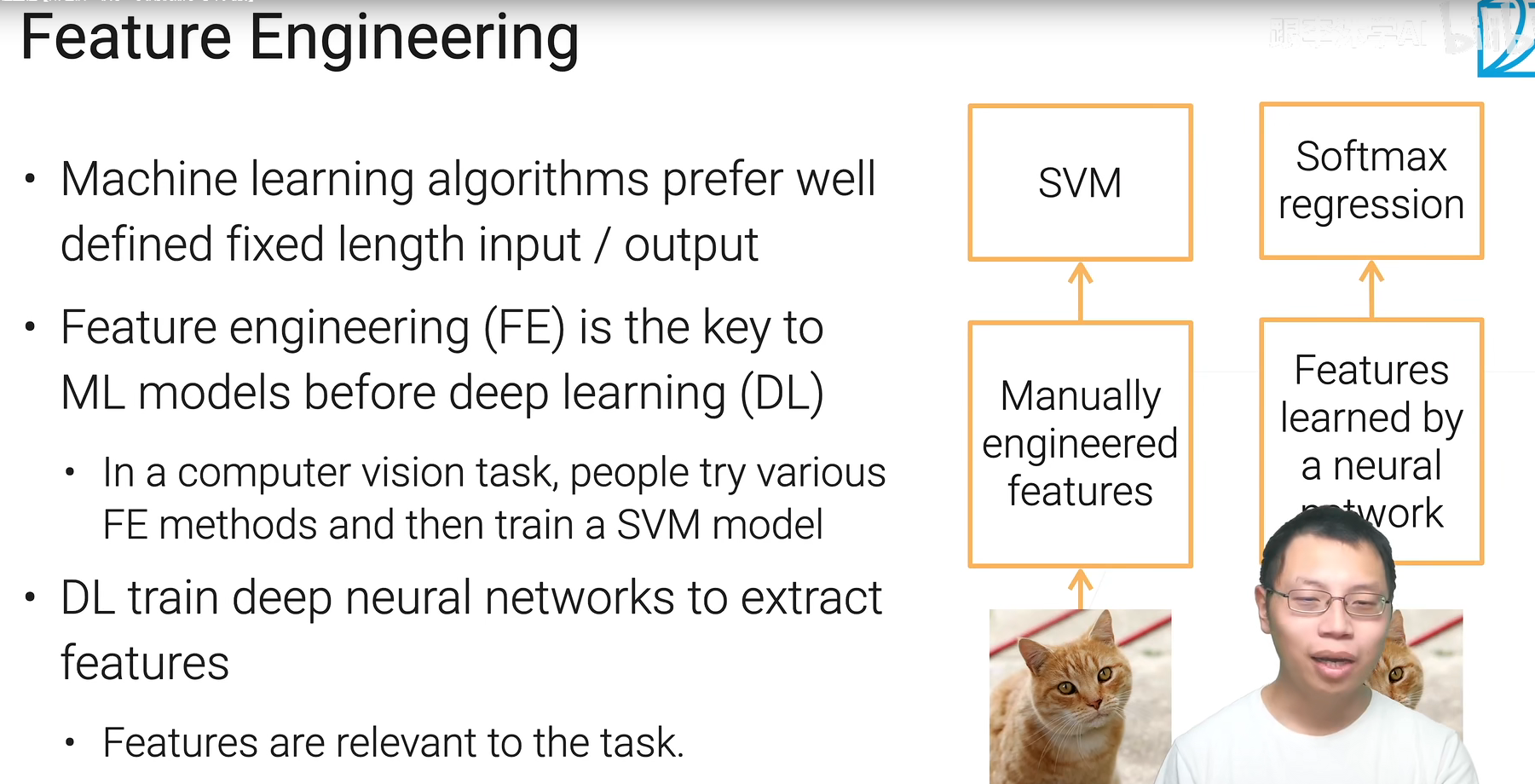
深度学习其实没有改变大的流程,而是用不同结构的神经网络(按照需求设计,比如transformer)来替换掉人工抽取这个过程。
所以特征抽取和最后的线性层(模型)是一起学习的。

你的特征要让机器知道说有区分度,比如天按照工作日和周末区分就会知道人的表现会很不一样,但要是拿星期几来区分就徒增难度
图片现在已经基本用不到手动,都用预训练的深度学习模型来整了

总结
如果你获取不了数据,而且生成都困难,那可能说明你这个问题不那么适合机器学习,因此就不要挣扎啦。长期迭代👇:
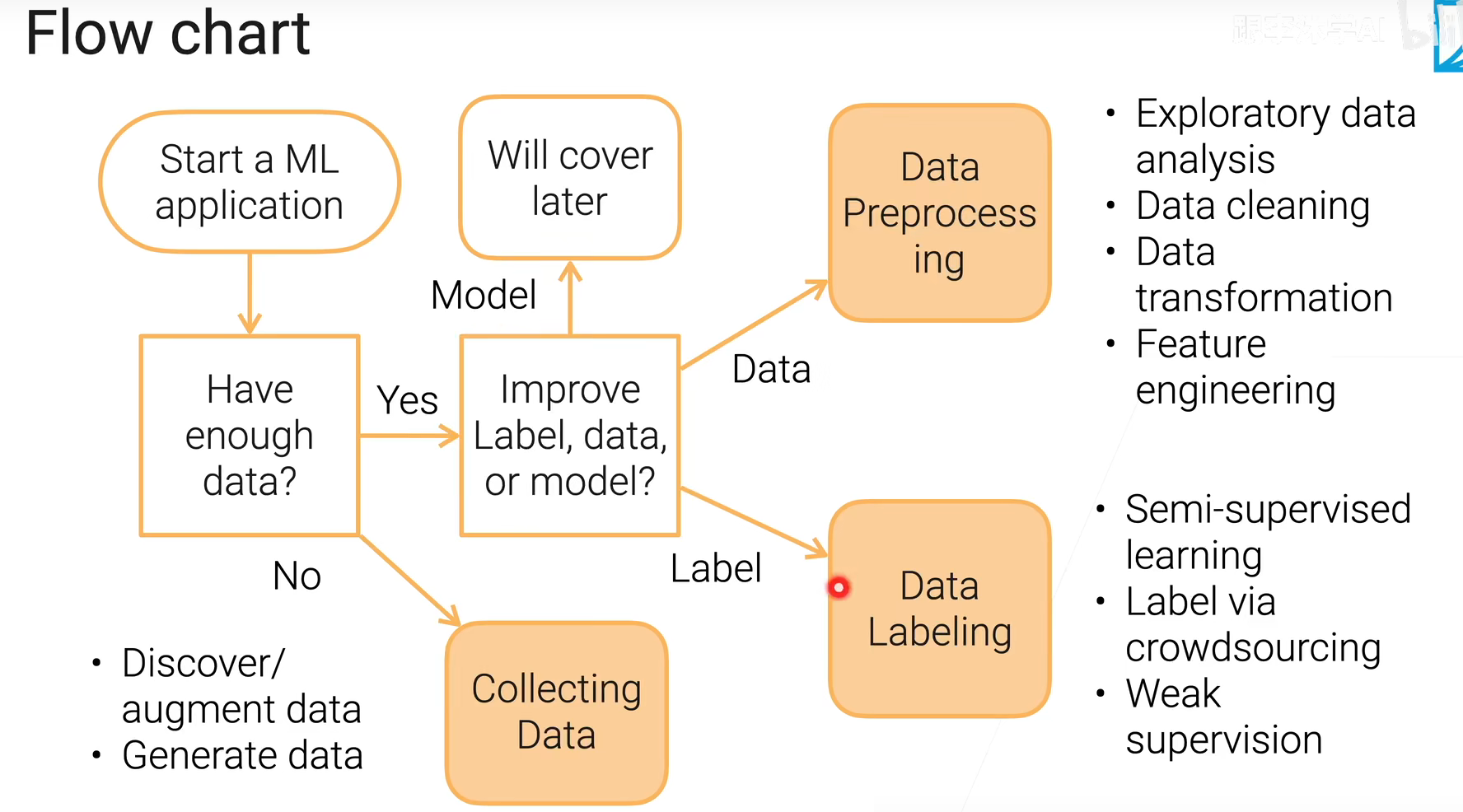
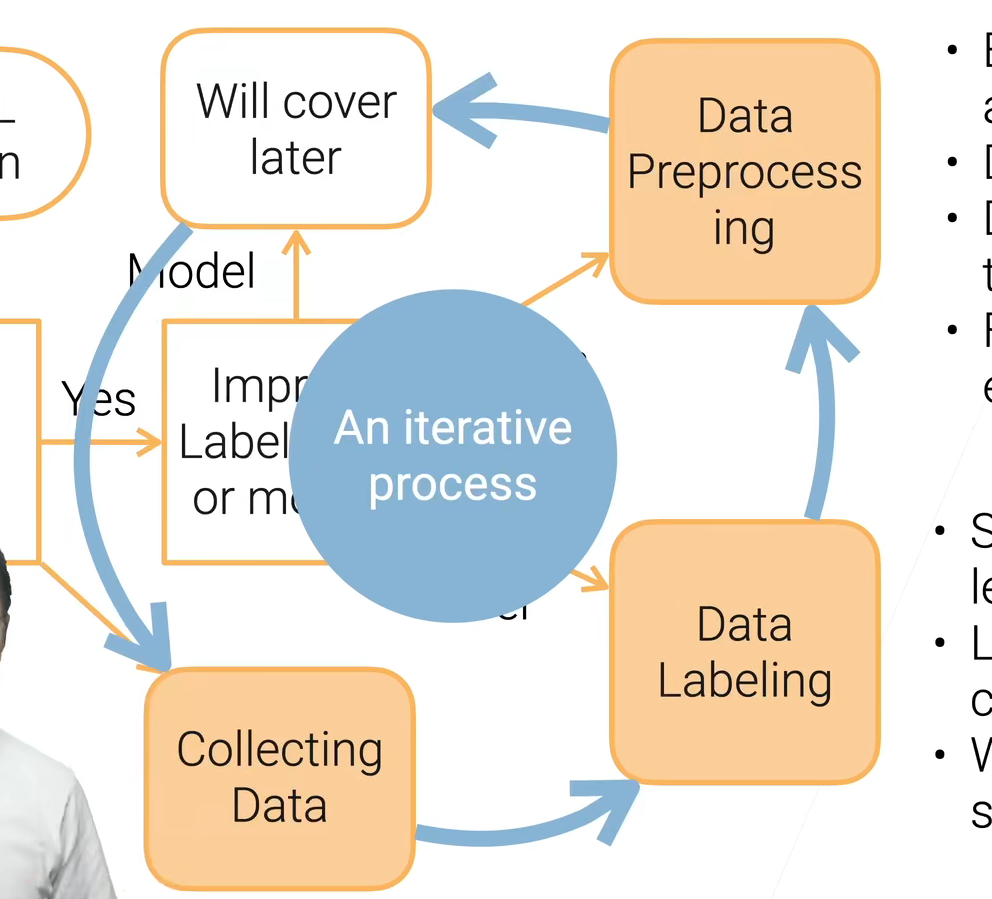
但是这个滚雪球的过程你要随时监控做得够不够好,有没有走弯路。后续会讲

数据也要做版本处理,不仅仅是模型,数据也要做到版本回滚之类的操作。
还有数据的安全、用户的隐私这些东西,都在数据科学家的考虑范畴指内。
机器学习
自监督学习,标号是直接从数据里面生成的。比如word2vec、BERT
监督学习中的 Pretrain - Finetune 流程:我们首先从大量的有标签数据上进行训练,得到预训练的模型,然后对于新的下游任务(Downstream task),我们将学习到的参数进行迁移,在新的有标签任务上进行「微调」,从而得到一个能适应新任务的网络。
自监督的 Pretrain - Finetune 流程:首先从大量的无标签数据中通过 pretext 来训练网络,得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。所以自监督学习的能力主要由下游任务的性能来体现。
监督学习目前还是工业界最主流的任务。

目前主要的监督学习分类
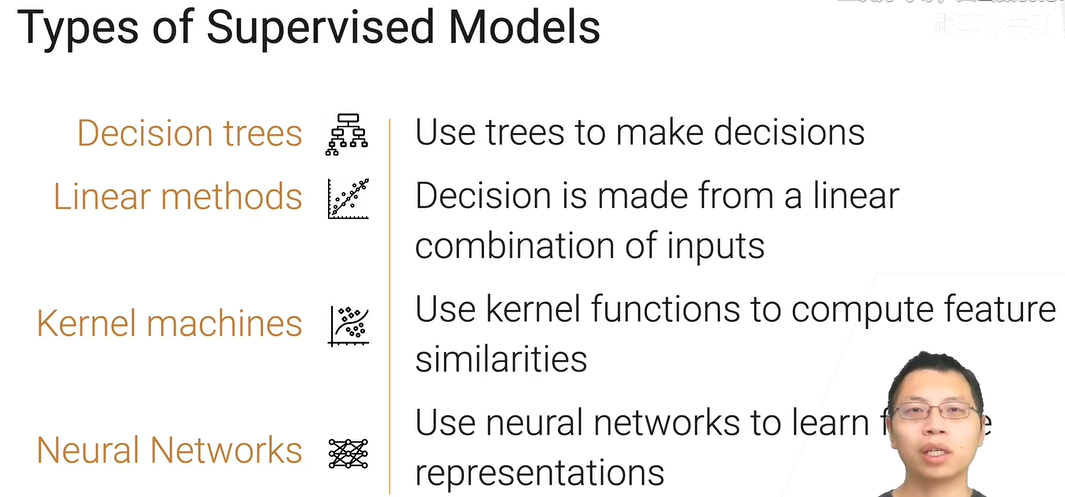
决策树
工业界可能用的最多的,而且结果还不错,不太需要调参,一般是第一选择,给你个对任务的直觉。
由于可解释,比较敏感的行业比如保险、银行业大量使用,经常需要解释。
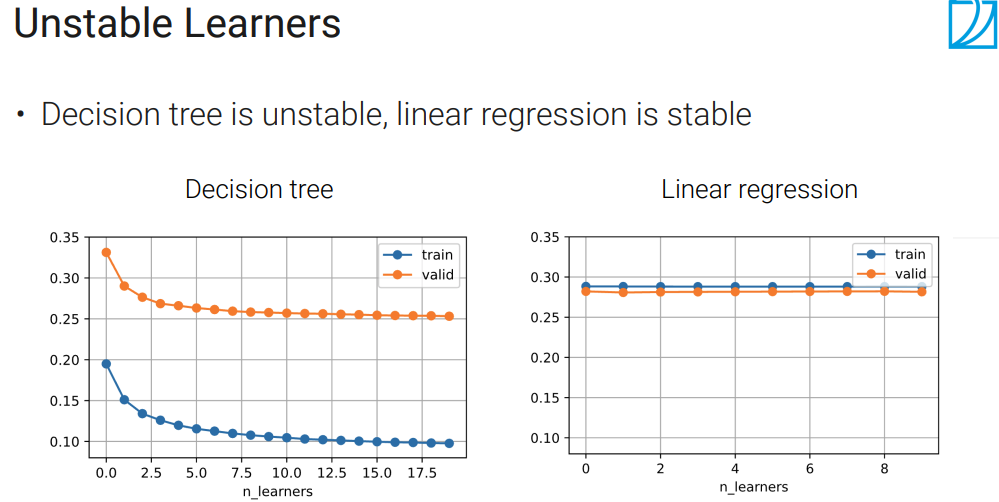
模型非常不稳定,容易收到数据噪声的影响。过拟合(可用剪枝),从上到下判断,难以并行,性能低。

提高稳定性👇
随机森林一定要随机,两种随机性:bagging(样本)、特征

boosting,有很多种,这里讲的是gradient的boosting
和recnet思想十分类似,顺序而不是独立的训练新的树来弥补差距。因此随机森林是投票或平均,这里是求和。
之所以叫gradient。。。是因为计算的残差相当于是对均方根误差不断做梯度下降。

线性模型
之所以损失函数不用MSE用softmax+交叉熵,是因为MSE还要求你不正确的类的mse缩到够小,增加了额外的学习成本,而不是像softmax一样,只关心概率最大的类是正确的类就行。
模型
本节指的是衡量最终已经训练好后的模型的好坏,只跟你的超参数和采样的数据有关
我们要选用好一点的数据采样方法和好一点的超参数使模型泛化性更强。
评估指标
一个模型的评估往往要通过多个指标来实现,而不是仅仅一个最简单的loss函数来实现。

看一个例子:展现广告
虽然这是支持很多互联网公司的一个重要业务,但其实也就是个二分类问题。【愿意/不愿意点击】

常见的用于分类问题的指标:accuracy、precision、recall、F1
• Accuracy: # correct predictions / # examples
• Precision: # True positive / # (True positive + False positive)
• Recall: # True positive / # Positive examples • Be careful of division by 0
• F1: the harmonic mean of precision and recall: 2pr/(p + r)
很多时候广告更关心的是区分度,优化用户体验,什么的,广告领域常用的指标有个叫做AUC、ROC,如下图:
0.5是完全随即预测,0是完全预测反了,1是理论最好的情况。
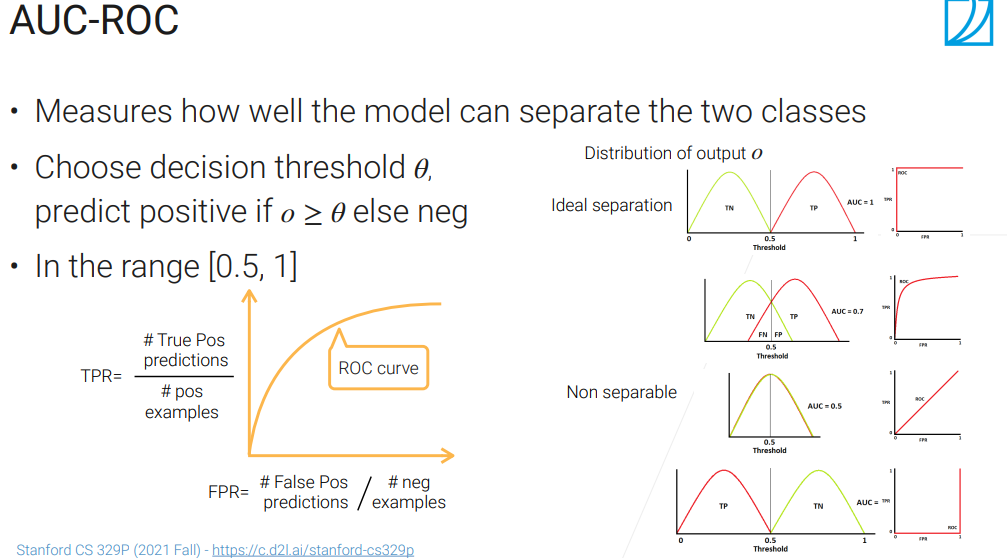
当然还有很多商业上的指标:

权衡:
对于一个模型,我们最关注的就是AUC,但是如果我们一味的提升AUC,就会harm很多商业指标。
没有什么太好的方法,最好还是你训练出一个模型,实际部署到线上关注一下你这些商业指标的变化。达标上线,不行就继续换模型
所以很多时候,不能光看论文、课程里提到的模型的指标,还得去关注商业指标。
模型验证
通常我们会用一个测试数据集上测量的误差近似模型的泛化误差。
我的评价是,不如吴恩达。。


模型融合
Bagging

class Bagging:
def __init__(self, base_learner, n_learners):
self.learners = [clone(base_learner) for _ in range(n_learners)]
def fit(self, X, y):
for learner in self.learners:
examples = np.random.choice(
np.arange(len(X)), int(len(X)), replace=True)
learner.fit(X.iloc[examples, :], y.iloc[examples])
def predict(self, X):
preds = [learner.predict(X) for learner in self.learners]
return np.array(preds).mean(axis=0)如果用决策树做base-learner,那就是随机森林,里面还有个随机采样特征,此处未实现。
主要降低方差而不是偏差,改善了不稳定性,如果模型比较stable,基本没啥效果。

决策树就很适合bagging
Boosting
这个是降低偏差用的

就是在当前基础上,把训练不好的地方再拿出来,训练一个新的模型把它做好点,然后一直迭代下去。
AdaBoost是一个十分经典的,理论上也十分透彻的一个算法。 【李航的书上面有】
这里和之前那章讲的一样,还是gradient boosting

学习率如果调成1,非常容易过拟合。其实,学习一个$h_t$就是去拟合当前负梯度的方向,跟梯度下降基本是一样的。
当然此处用的是做回归的时候MSE的loss,其他问题的loss会不一样,理解意思就好。
class GradientBoosting:
def __init__(self, base_learner, n_learners, learning_rate):
self.learners = [clone(base_learner) for _ in range(n_learners)]
self.lr = learning_rate
def fit(self, X, y):
residual = y.copy()
for learner in self.learners:
learner.fit(X, residual)
residual -= self.lr * learner.predict(X)
def predict(self,X):
preds = [learner.predict(X) for learner in self.learners]
return np.array(preds).sum(axis=0) * self.lr看起来这代码还挺简单的。

决策树算不得一个“弱模型”,但你可以限制最大深度,或者采样一些列来手动削弱它【让过拟合不那么严重】。
可以看到(左图)并没有过拟合(模型比较弱),随着n的增加,偏差在下降。当然学习率也要调好,不能太高。
但是毕竟是顺序训练,比较吃亏。大家都用的是:XGBoost或lightGBM,算的快一点。
Stacking
刷榜利器
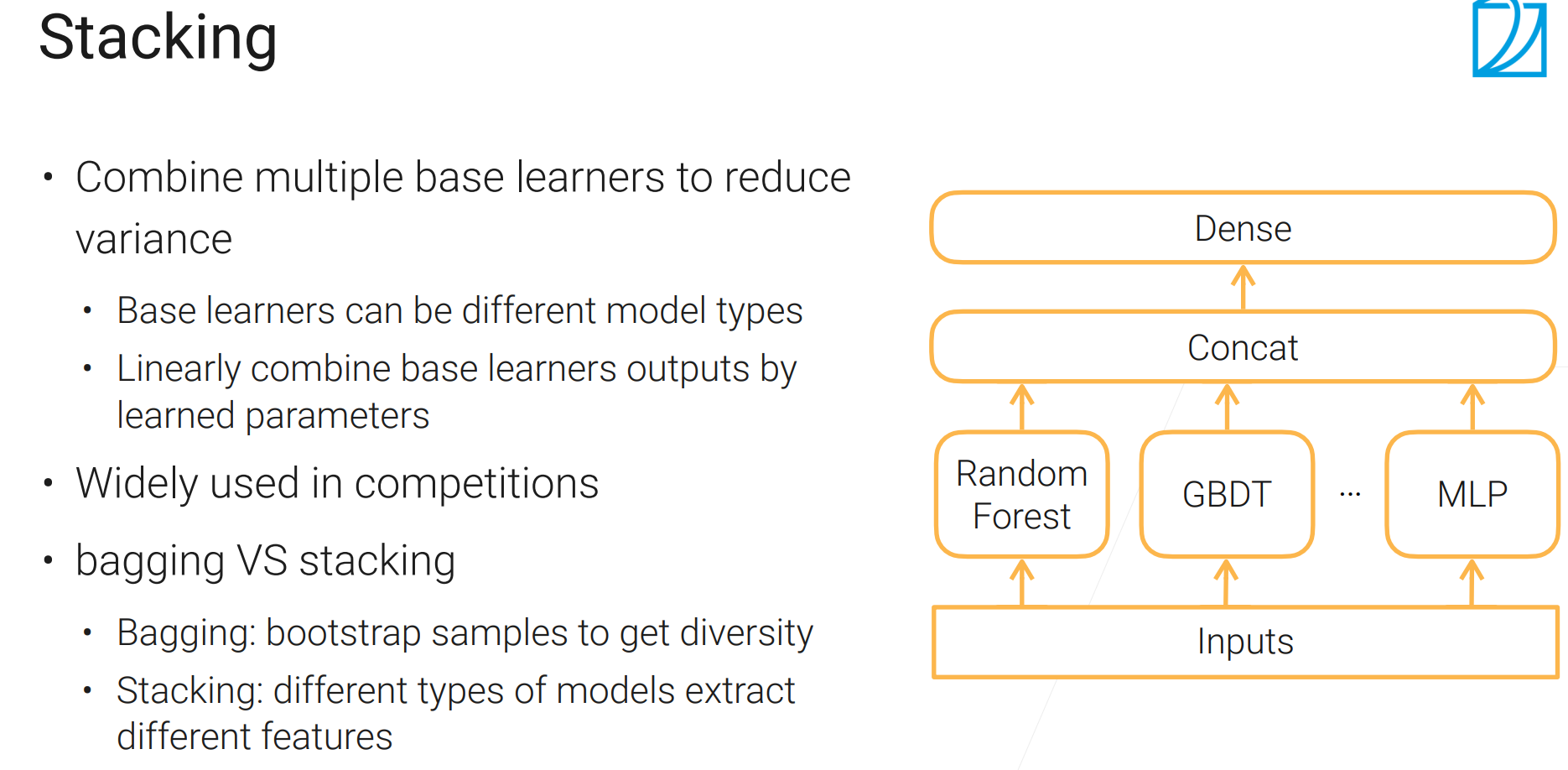
bagging采样不同的数据训练同样的模型;stacking用同样的数据训练不同的模型
根据模型的不一样,特征提取可能有不同的选择。
如果某个模型加进来不能提升精度,或者特别贵,那就可能不考虑加咯。
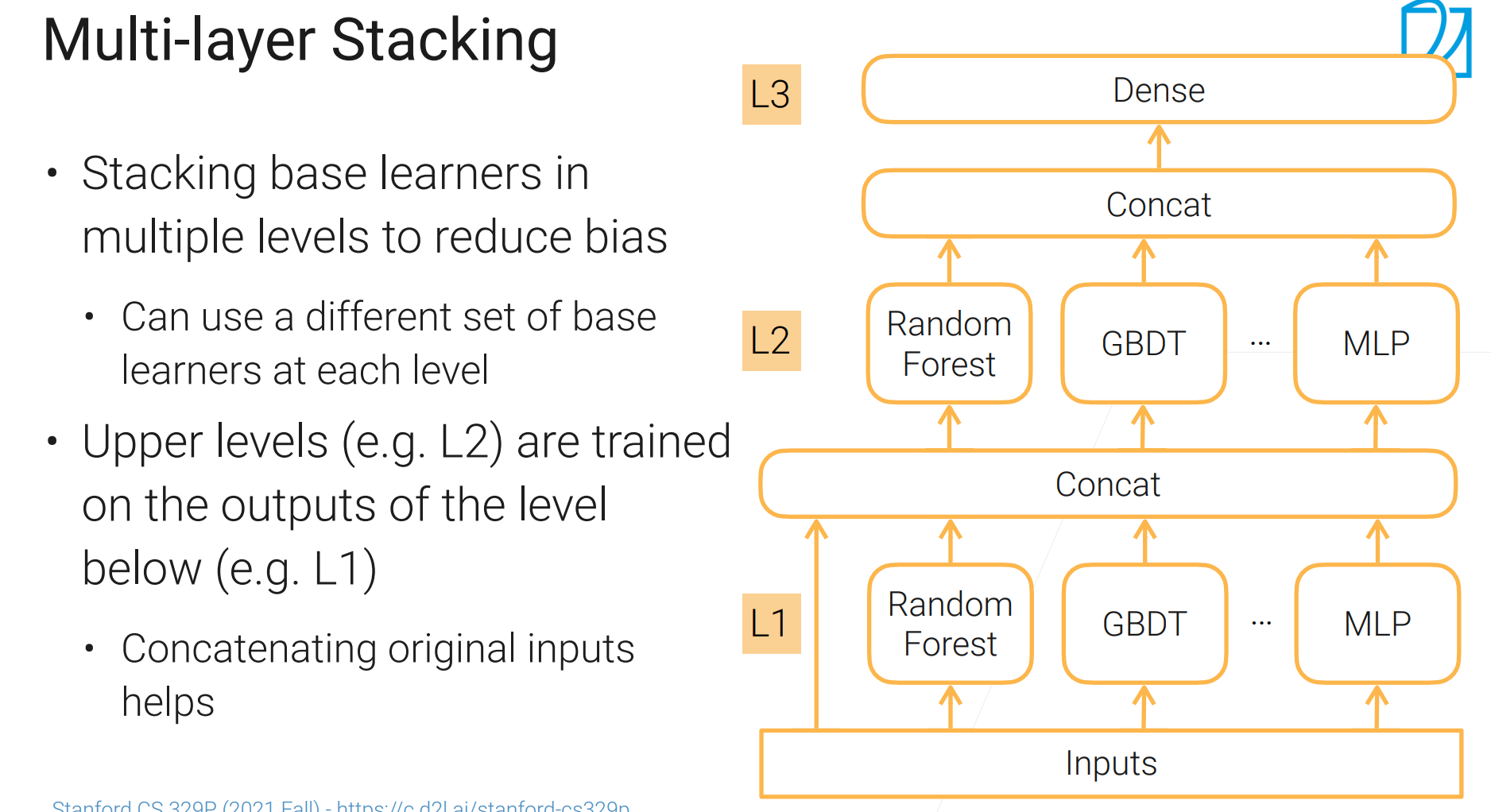
本来主要降低方差,引入多层以降低偏差。多层的stacking非常容易过拟合,相当于同一份数据训练多次。
需要很多手段避免过拟合:
如果每层用一部分数据,这样有点亏,也可以k折

由于每个模型都在没有参与训练的$1/k$数据上预测,然后把结果交给下一层,减缓了过拟合。但是还有一定程度。
更昂贵的降低过拟合:重复1,2步骤n次,每次把验证集的输出并成大小一致的数据集,取平均。。。进一步降低偏差。
每个小模型训练$k*n$次
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label=label).fit(train, num_stack_levels=1, num_bag_folds=5)
调参
benchmark选择高质量工具包的初始参数,或者论文里的参数,当然论文里的参数一般绑定了某个数据集,但是有时候通用性不错。

记得李宏毅的优化:Adam对超参数不那么敏感,容易调一些;SGD对超参数敏感,难调,但是调好了效果更好。
管理好你的调参日志:

TensorBoard 和 weights&bias 比较好的工具
环境:xs,李沐吐槽python很多库只管加兼容性,不考虑旧代码的可维护性,python本身也是如此。
代码、随机种子:如果随机性给你的结果抖动比较大,那可能出了问题,可能是数据、dropout、某些库带来的随机性。【可以ensembling、bagging】
总的来说复现实验也是很麻烦的事情

自动调参,可能比人来调参的成本低。
超参数优化(HPO)、神经网络架构搜索(NAS)
HPO
搜索空间

每加一个参数的几个选项,昂贵程度指数上涨。但也不能太小,不然搜的结果不行。
因此你要根据经验选择比较合适的初始区间。
• HPO algorithms: Black-box or Multi-fidelity
• Black-box: treats a training job as a black-box in HPO: • Completes the training process for each trial
• Multi-fidelity: modifies the training job to speed up the search
• Train on subsampled datasets
• Reduce model size (e.g less #layers, #channels)
• Stop bad configuration earlier
关心的是超参数之间的重要程度排序,这个时候并不是在选具体参数数值,只要排序就好了
如果你不知道任务细节,而且任务不太大,也能用黑盒来算。
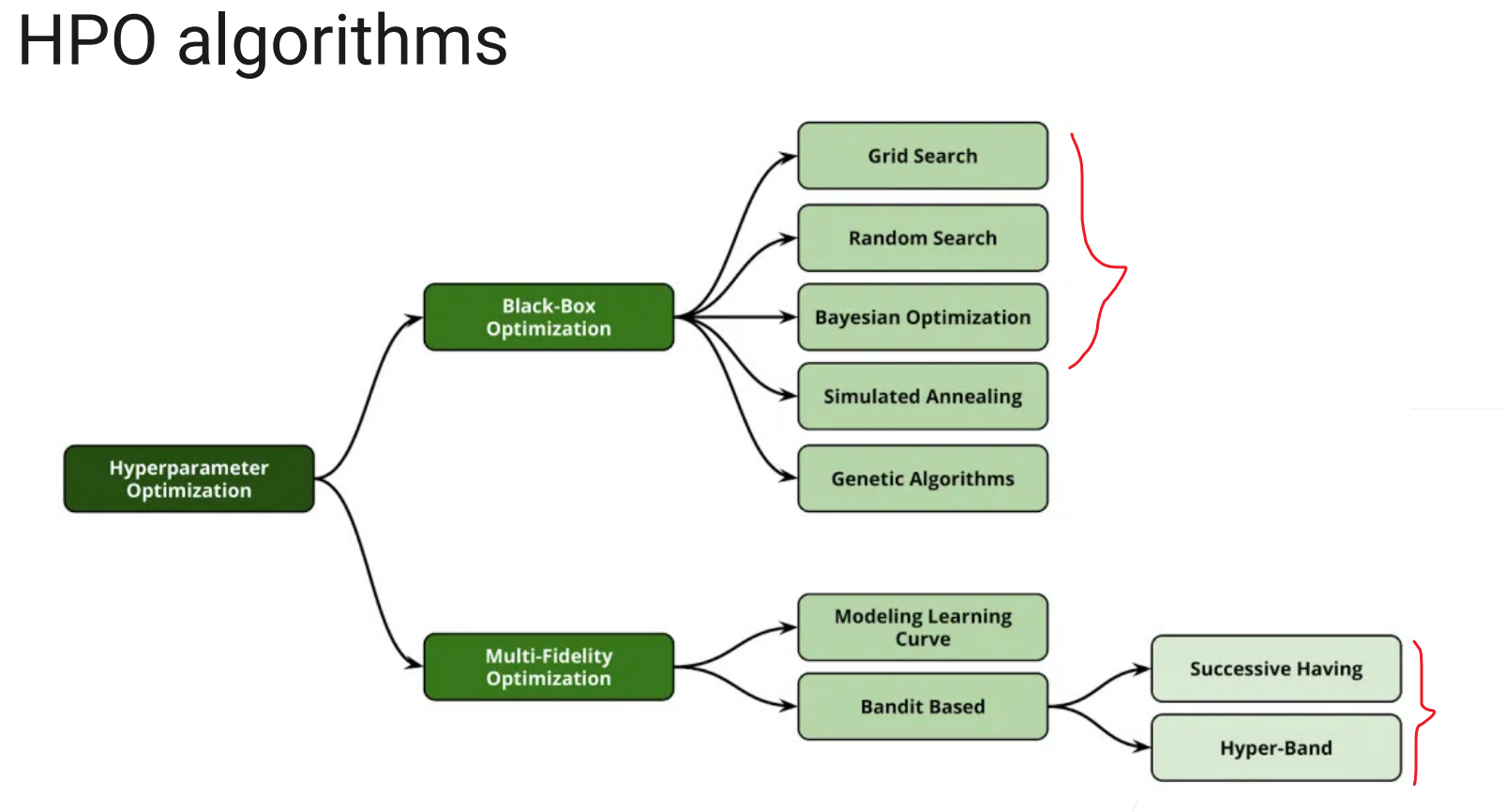
模拟退火和遗传可见《最优化导论》
Grid Search:穷举搜索,有可能顺序没选好,训半天提升不大,最后猛涨。
Random Search:随机搜索,非常有效,没甚么idea就用这个,一般是用完现有资源,比如有两台机子,能跑一晚上,就先跑完看结果;或者看目前最好的结果,如果一段时间都没有变化,或变化不大就可以停了,因为是随机算法,后续再暴涨概率不大。
for _ in range(n):
config = random_select(search_space)
train_and_eval(config)
return best_result贝叶斯优化,目前还在快速发展,暂时用的不多。
如下图例子:横轴是搜索空间,纵轴是目标函数。怎么感觉插值能用在这
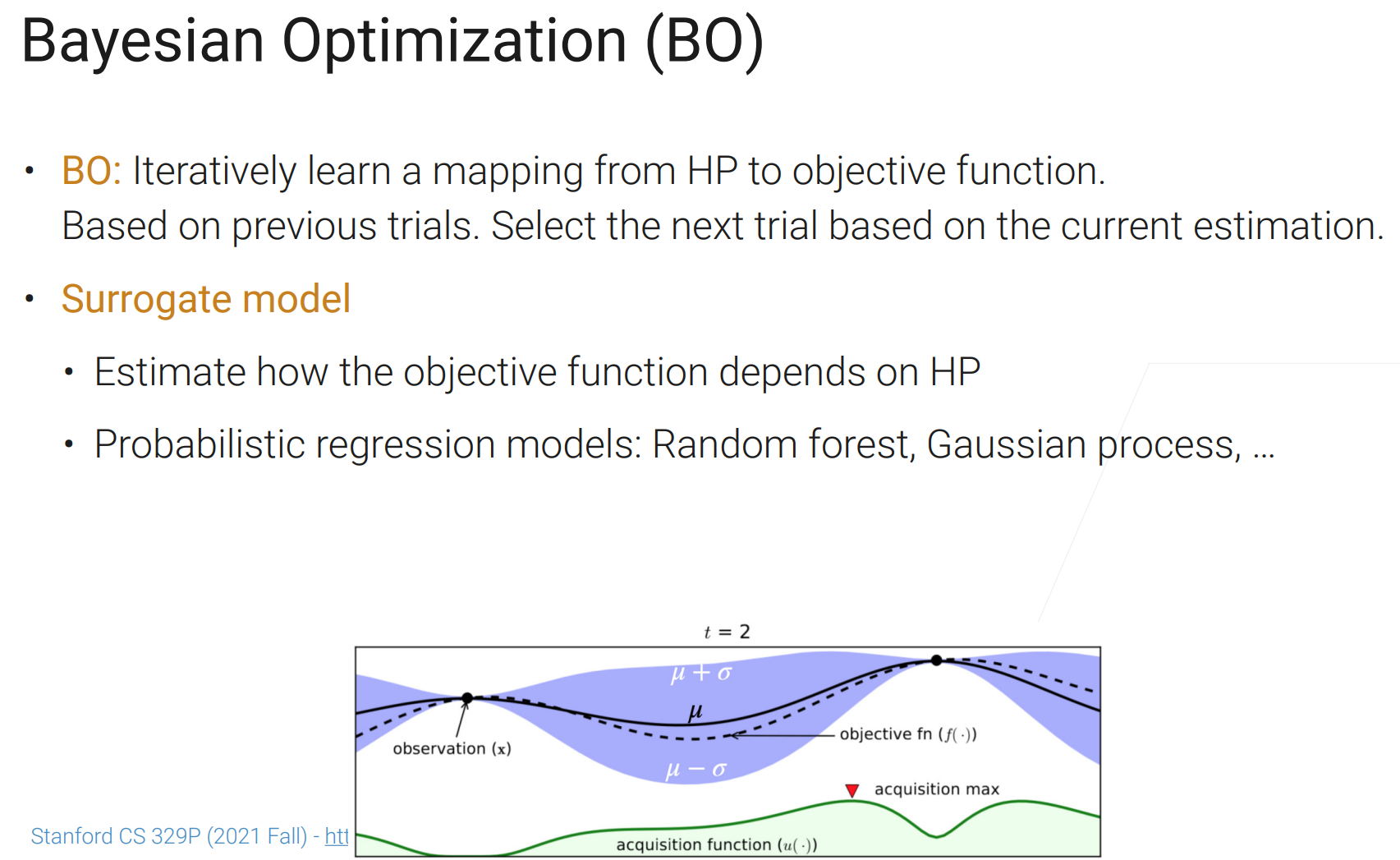
获取函数会选取:不那么置信而且预测效果可能比较好的点作为下个采样点。
权衡探索和开发,找新的最优点,或在已有比较好的点附近看一看;其实很多ML算法(特别是迭代式的)都是这两者的权衡。
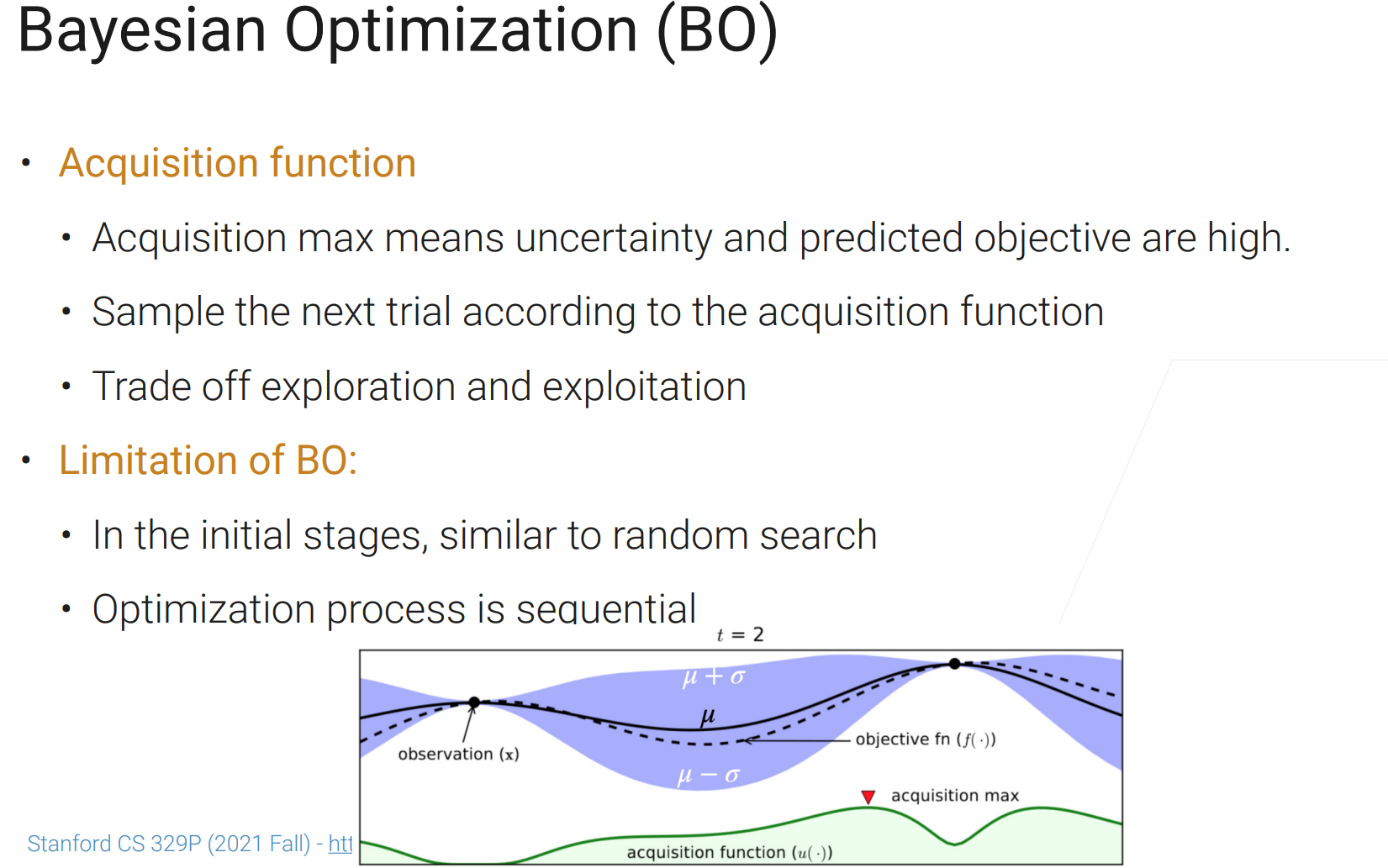
刚开始接近随机搜索,而且这个过程是串行的,随即搜索是并行的。
现实生活中,大家还是用的随即搜索多一点。
Successive Halving(连续减半)
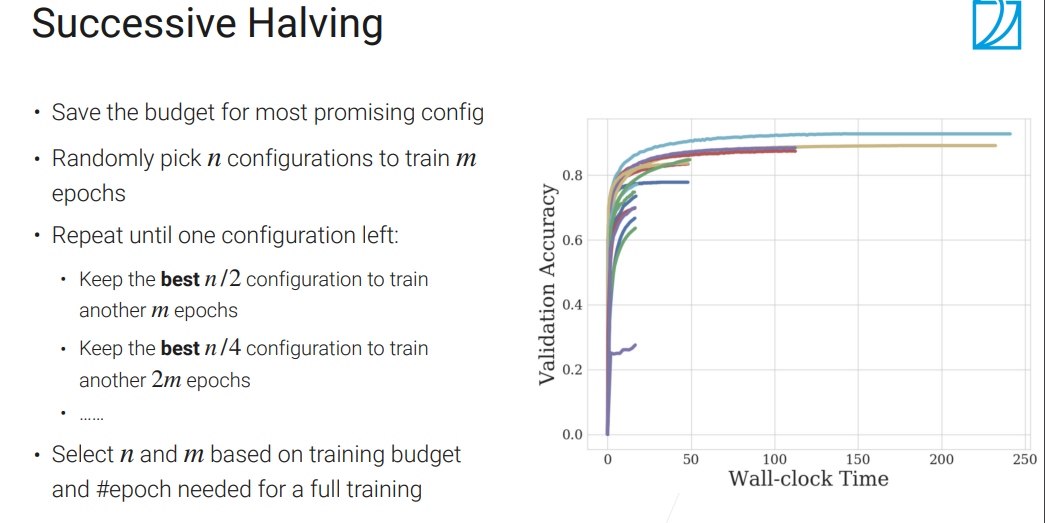
通常n取大一点,比如100;m取小一点,比如1或2.
把更多的资源分配给更有潜力的!但是问题是n和m不太好取!
Hyperband
真正的在实际中用得比较多的算法,可以尝试!
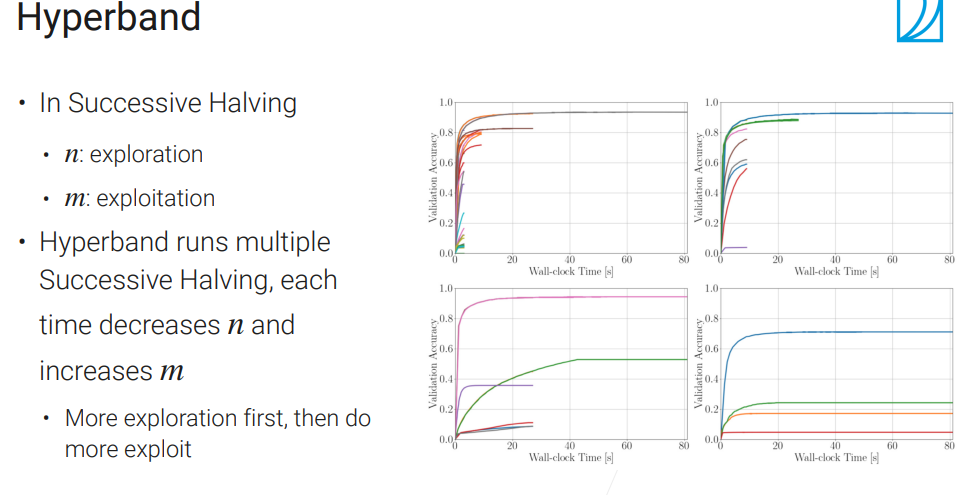
这样子,对n和m的取值就不那么敏感。
还有更多的其他思路的Multi-fidelity HPO。
总有一些超参数,不管放到哪里结果都不错,可以去kaggle看比赛第一第二、或者论文里的超参数,都是你抄我我抄你。
如果你能找到,那超参数其实是一件很简单的事情!
NAS
Neural Architecture Search
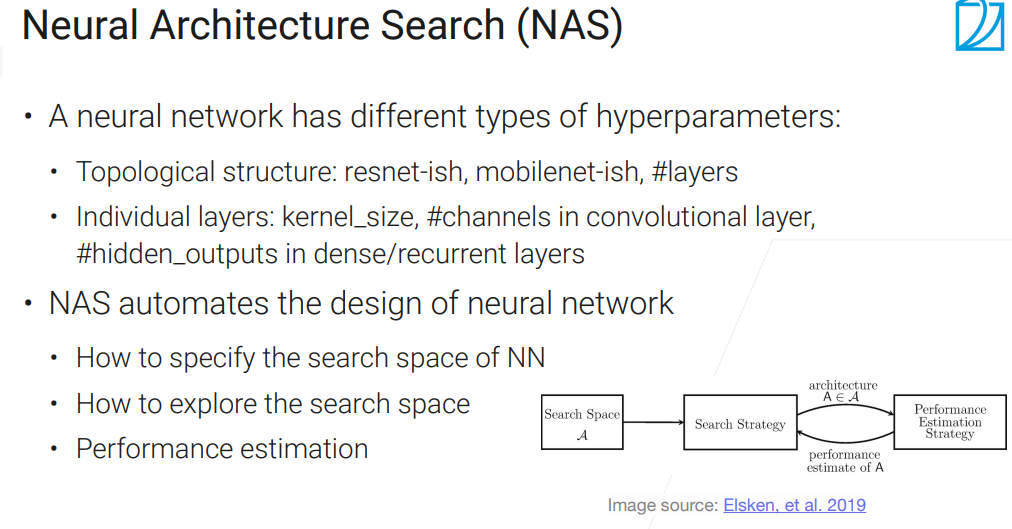
最开始的work使用RL来整的,RL炼起来虽然强大,但是巨贵。
后面有一些工作来加速,后来有个工作叫做one-shot,是一种方法

通过学习,决定哪条路比较好,有点注意力机制的味道👇,后续还有很多工作进行改进。
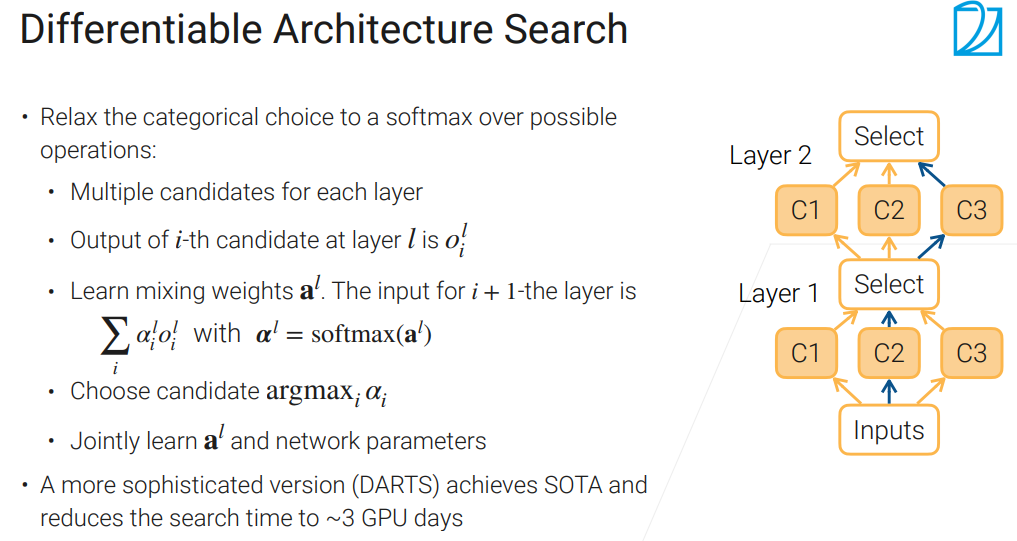
Efficient Net的思想是,调结构不要一个一个调,要一起联动着调。比如之前说的,网络变深,通道就变长。
最终只用调整一个参数,也就是下文的$\phi$(与模型复杂度有关)

最终结果很棒,这是大家发现的一个简单但是实用的方法!
NAS目前还在快速发展,有几个研究重点:
比如:你搜出来的东西是不是“可解释的”,搜出来效果特别好但是长得很奇怪,大家也不知道咋用

移动设备上的模型,得权衡精度、延迟、功耗等等。
Deep Network Tuning
讲深度神经网络里一些共用的设计模式!
。。。批量和层归一化。残差连接。注意力机制。
(未完待续,等李沐老师继续更新!)



